基于深度強化學習的和聲自動生成算法
2024-10-18 00:00:00劉至洋劉維莎冉黎瓊徐康鐳蔣宇河李慶喬少杰
無線電通信技術 2024年5期





摘 要:機器自動作曲是人工智能和作曲理論結合的交叉研究領域。自動作曲算法旨在輔助使用者進行音樂創作,幫助使用者減少工作量或是提供靈感。面對當代音樂創作需求,現有的自動作曲方法無法有效表達音樂特征,生成的和聲缺乏音樂結構,無法滿足當代音樂創作多樣性的要求。針對上述不足,提出了一種基于深度強化學習(DeepReinforcement Learning,DRL)與和聲量化的和聲自動生成(Automatic Harmony Generation Algorithm Based on DRL,AHG-DRL)算法。AHG-DRL 使用和聲量化方法對音樂進行編碼,使編碼后的音樂具備更加全面的音樂特征;使用基于逆強化學習(Inverse Reinforcement Learning,IRL)與DRL 的和聲生成算法擴大音樂創作的搜索空間,同時使生成的音樂具備功能性。實驗結果表明,所提和聲自動生成算法可以生成滿足創作需求和符合作曲規則的音樂,與其他和聲生成算法相比,生成的和聲種類更加復雜多樣,在客觀評價指標上更接近真實值。
關鍵詞:和聲量化;深度強化學習;自動作曲;預訓練;逆強化學習
0 引言
在音樂理論中,當兩個音的頻率比為3 ∶2或2 ∶1時,呈現出的聽覺感受相對協和,分別對應音程中的純五度音程和純八度音程。音樂家會根據不同的音程,即不同的頻率比帶來的聽感,將音程劃分成協和音程、不完全協和音程以及不協和音程3 類,然后基于音程設計復調音樂以及和聲[1-2]。近年來,音樂家們開始主動探索音樂中的數學知識,將音樂和數學聯系起來,得出了許多和數學有關的音樂理論分析[3-4],如將代數、拓撲和范疇論引入音樂學中[5],或是研究音樂中的物理規律[6]。上述研究為探究音樂的本質提供了新思路,為自動作曲提供了更適用的音樂理論基礎。
自動作曲是人工智能和作曲理論相結合的產物,較好的自動作曲算法應當在符合使用者創作需求的同時,具有更多的色彩性[7],自動作曲算法的質量主要由以下3 個因素決定:① 自動作曲算法采用的音樂理論;② 自動作曲算法采用的計算機算法;③ 計算機算法與音樂理論的適配程度。
目前已經有通過算法實現音樂創作的研究,如將音樂的生成當作序列問題,利用馬爾可夫鏈生成音樂[8]或利用深度神經網絡將音樂中的節奏、旋律、織體等,作為特征向量輸入進神經網絡進行訓練[9-10]并生成新的音樂。上述方法仍存在音樂特征的缺失問題,或是音樂理論基礎無法滿足當代音樂的需要。近期研究[11]表明,音樂的量化能為自動作曲帶來全新的思路并加深人工智能和音樂之間的聯系。
基于音樂量化的思想,本文進行自動作曲的研究,首先,建立和聲數據集,該數據集包括2 000 條不低于6 個和弦的和聲;然后,根據音程的關系將和聲從橫向和縱向(即和弦與和弦之間的連接)兩個角度進行量化;最后,設計實現了一種基于深度強化學習(Deep Reinforcement Learning,DRL)與和聲量化的和聲自動生成算法(Automatic Harmony GenerationAlgorithm Based on DRL,AHGDRL)。AHGDRL 的主要貢獻如下:
① 能夠生成不同風格類型和聲,使生成的和聲更符合當代創作需要;
② 提出新型的和聲編碼方法,使訓練所使用的數據具備更加全面的音樂特征;
③ 提出一種基于逆強化學習(Inverse Reinforcement Learning,IRL)的預訓練和聲生成模型的算法,能夠生成全方位模仿專家的決策,讓生成的和聲具備一定的音樂功能性;
④ 從客觀與主觀兩個角度進行樣本評估,證明了本文所提算法的實用性和有效性。
1 背景知識及相關工作
1. 1 和弦與和聲
和弦是指兩個以上的音按一定音程關系組合形成的一組音,而和聲則是由若干個和弦按照一定規律組合而成。和聲作為現在音樂的重要組成要素之一,不僅推動了音樂作品的發展,還加強了音樂的表現力[12]。和聲能夠使旋律擁有豐富的色彩并且每個旋律在不同的和聲配置下都會擁有不同的感情色彩。和聲的發展是一個不斷演變和創新的過程,從中世紀的多聲部音樂構成和聲的雛形,到現在各式各樣復雜的高疊和弦[13],和聲的結構變得越來越復雜,產生了越來越多有關和聲分析的方法[14-16]。
構成和聲與和弦的最小單位是音程,如果將和聲與和弦看作是音程的排列組合,那么對和聲與和弦的分析就會轉變成對音程的分析。欣德米特[17]在《欣德米特作曲技法》中對和聲提出了全新的思路:沒有把調性以及由該調性產生的和弦當作構建音樂的基礎,而是以音程和音程構建的和弦為主導構成一種新調。僅需確定不同和聲的緊張度,而和聲的緊張度由音程所對應的數值決定的。如果音程所對應的數值不同,那么由其構成的和弦或和聲也必定不相同。量化和弦與和聲便成了優化自動作曲算法亟待解決的任務。
1. 2 IRL
IRL 是一種模仿學習方法,旨在從觀察到的專家策略πE 中提出獎勵函數。基于IRL 的方法通過兩個反復交替的過程實現:第一個階段使用專家數據來推斷一個隱藏的獎勵;第二個階段基于第一個階段的結果學習一個模仿策略[18]。
1. 3 DRL
在很多情況下,強化學習任務所面臨的狀態空間是連續的,存在無窮多個狀態,需要借助深度神經網絡強大的映射能力來構造一個Q 函數,DRL 中的Q 函數的輸入通常是某種狀態,輸出包含了所有可能動作所對應的價值。Q 函數的引入讓智能體在復雜的環境中通過與環境的交互完成自主地學習最優的行為策略[19]。
在自動作曲領域,Smith 等[20]利用強化學習以及領域知識進行旋律的創作,并模仿巴赫作品旋律進行自動作曲音樂創作。Dadman 等[21]將強化學習作為學習方法,將人類用戶作為音樂專家,以促進智能體對音樂特征的學習。
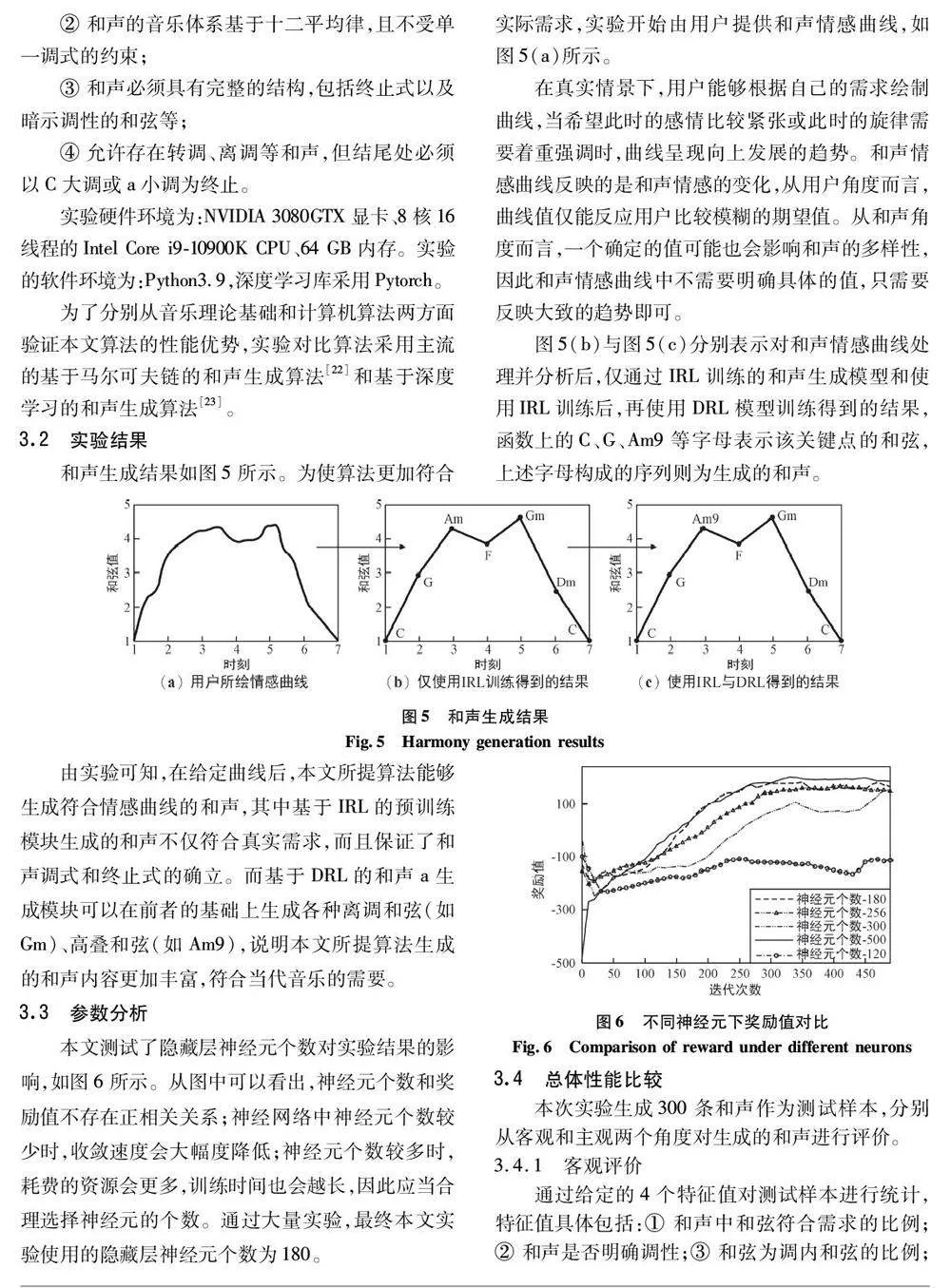
和聲量化后的狀態空間是連續的,而建立在離散空間上的強化學習算法無法存儲連續的價值函數。因此,本文使用DRL 構造和聲生成模型并使用神經網絡對價值函數擬合,生成符合作曲規則的音樂。
