智能駕駛人工智能芯片的計算性能測試研究
2024-10-24 00:00:00趙瑞夏顯召吳海文等
標準科學 2024年10期
關鍵詞:智能駕駛,人工智能芯片,測試評價,計算性能,芯片選型
DOI編碼:10.3969/j.issn.1674-5698.2024.10.011
0 引言
近年來,隨著我國智能汽車產業發展加速,智能駕駛、智能座艙系統的裝車率逐漸提升,計算芯片已成為支撐汽車智能化的關鍵部件。針對不同應用場景、不同智能化等級,如何選取與之匹配的計算芯片成為行業關注的熱點問題,但現階段計算芯片的性能測評并未實現行業普遍共識。當前尚未有研究可為行業提供標準化、公開、客觀的汽車人工智能(Artificial Intelligence,AI)計算芯片性能測試方法。
為有效探究并解決汽車AI芯片的計算能力測試問題,本文以應用于智能駕駛系統的汽車AI芯片為主要研究對象,對AI芯片測評的研究現狀開展分析,并面向智能駕駛實際應用,提出了一套普適性較高的汽車AI芯片的計算能力測試方法。本文使用該方法對芯片產品進行測試驗證,并對不同芯片的測試結果進行對比分析。該方法的應用可為企業選擇智能駕駛汽車AI芯片提供性能方面的參考,解決當前汽車AI芯片缺失計算能力測試評價方法的問題,具有重要的研究意義和實際應用意義。
1 智能駕駛AI芯片
1.1 AI芯片發展現狀
智能駕駛是AI芯片應用的典型代表。算法、計算能力和大數據是推動智能駕駛汽車崛起的三大要素。這三者必須平衡完美發展,智能駕駛汽車才可能取得良好的發展前景。計算能力是AI的基礎,也是智能駕駛復雜數據處理的關鍵。近年來,由于智能汽車產業的發展,汽車需要處理的數據量呈現爆發式增長,傳統的計算架構越來越難以支撐深度學習的海量并行計算需求。因此,AI芯片的技術研發成為研究熱門。應用研究方面,國外巨頭如:NVIDIA、Google、IBM等國際巨頭推出新品,國內地平線、華為、黑芝麻等企業也紛紛布局汽車AI芯片產業,中國AI芯片技術取得了重大的發展[1]。
按照設計架構,AI芯片主要分為GPU、FPGA、ASIC,當前市場上主流應用的AI芯片是GPU。就適用范圍而言,GPU為通用型芯片,ASIC為專用型芯片,而FPGA是屬于兩者之間的半定制化類芯片。綜合來看,3種AI芯片各有優劣,GPU運算速率快,通用性較強,開發難度相對較低,預計在目前及未來一段時間都將占據主流地位;ASIC的用量有限,可能難以形成規模化應用;FPGA的量產成本高,與GPU相比開發門檻高。因此目前ASIC與FPGA在AI芯片市場的占比皆不高[2]。
1.2 AI芯片算力
算力是特定場景下對芯片計算能力評價的重要維度。算力大小代表芯片數字化信息處理能力的強弱。自動駕駛場景需要標量、矢量、矩陣3者結合的異構算力,通常可以將算力的綜合評價分為兩方面,即A I算力和C PU算力。A I算力是A I處理器在特定場景下提供的矢量和矩陣計算能力,也是智能駕駛領域熱點的研究方向。A I 算力常用的單位是TOPS(Tera Operations Per Second)或T FLOP S(Tera Floating-point operations persecond),1TOPS代表 AI處理器每秒可進行一萬億次(1012)定點操作,1TFLOPS 分別代表 AI 處理器每秒可進行一萬億次(1012)浮點操作。CPU算力是CPU主要提供的標量算力。CPU算力常用的單位是 DMIPS(Dhrystone Million Instructions executedPer Second),其含義為每秒鐘執行基準測試程序Dhrystone 的次數除以1757[2]。
智能駕駛技術的發展極大地提升了其對于芯片算力增長的需求。據統計,當前L2、L3級別自動駕駛計算量已分別達到10TOPS和60TOPS,預計L4級別算力可能會超過100TOPS[3]。大算力的AI芯片可支撐自動駕駛汽車海量的代碼運算,為自動駕駛的發展提供保障。然而,在智能駕駛汽車實際應用場景下,AI芯片的最大計算能力并不能達到理論算力值,無法單純通過產品宣稱的理論算力判斷不同產品的真實計算性能。因此,建立能夠有效地反映汽車AI芯片計算能力的測試指標,并通過實際測試體現計算能力,是具有重大意義的研究工作。
2 AI芯片計算能力測試研究現狀
2.1 測試基準
A I芯片的計算性能測評通過基準測試程序實現,當前國內外對于通用的AI芯片性能測試方法已有一定的研究成果和實際應用。AI芯片的性能測試主要依靠使用基準測試集,運行所需神經網絡來進行。當前常用的AI芯片基準測試集包括AI benchmark、MLPerf、AIIA DNN benchmark等。此外,眾多研究機構開發了面向不同維度的基準測試集,如:Fathom(哈佛大學)、DeepSpeech(百度)、N PU b ench(中國科學院)以及A I Per f(清華大學)等,可實現特質化的測試功能。A Ibenchmark[4]是瑞士蘇黎世聯邦理工學院開發的專門用于評估AI芯片性能的基準測試集,涵蓋了多方面的AI性能,包括計算速度測試;MLPerf[5]是用于測量和提升機器學習軟硬件性能的通用基準,包括各個領域的子項,如:圖像分類、識別、翻譯、語音識別等,測量不同神經網絡訓練和推理所需的時間和速度;AIIA DNN benchmark[6]是由中國AI產業發展聯盟開發的基準測試集,綜合5大維度評估AI芯片性能,并根據算力單價比和芯片利用率,反映加速卡性價比與軟硬件及存儲系統的整體能力。
2.2 測評標準
當前,國內已有多個AI芯片測評標準完成指定并發布。中國信息通信研究院起草的行業標準《人工智能芯片基準測試評估方法》[7]于2021年8月發布,標準里規定了AI芯片計算性能基準測試框架、評測指標及評估方法,主要包括基本信息披露和技術測試;中國電子技術標準化研究院起草的團體標準《人工智能芯片 面向云側的深度學習芯片測試指標與測試方法》[8]《人工智能芯片 面向邊緣側的深度學習芯片測試指標與測試方法》[9]《人工智能芯片 面向端側的深度學習芯片測試指標與測試方法》[10]均于2020年10月發布,3項標準分別規定了對云側、邊緣側、端側深度學習芯片進行計算性能測試的測試指標、測試方法和要求。
2.3 存在的問題
雖然國內外已經形成多項AI芯片計算性能測試基準或測試標準,但在汽車智能駕駛領域,這些基準或標準并不能完全適用。汽車企業無法通過適用的測試方案驗證不同產品的計算性能表現。因此,建立更加適用于智能駕駛領域的測試方案,形成直觀、清晰、可對比的測試結果對于AI芯片選型參考具有重要的意義。
3 測試方法論
基于上述研究基礎及存在的問題,本文提出了一套測試方法論,包含測試模型選取和測試方案實施要求兩部分內容。算法模型和AI芯片都是智能駕駛不同應用場景的運算基礎,本文將綜合研究AI芯片搭載算法模型的計算性能表現。
3.1 測試模型選取
3.1.1 選取原則為保證測試的一致性并形成具有可比性的測試結果,測試模型需基于以下3方面進行選取。
(1)測試模型
為公版、開源模型,其來源方為行業廣泛共識且權威性較高的科學機構,獲取渠道為原始發布渠道或者具備行業普遍共識的官方渠道,以保證測試過程中使用的測試模型具備一致性,避免不同獲取渠道導致的模型信息差異;
(2)同一測試公版模型的版本一致,若測試模型經過了后處理,則需要明確處理方式和目的,保證同一測試公版模型的一致性和穩定性;
(3)模型需基于汽車計算芯片常用應用場景選取,以提升測試結果的實際應用意義。
3.1.2 選擇過程
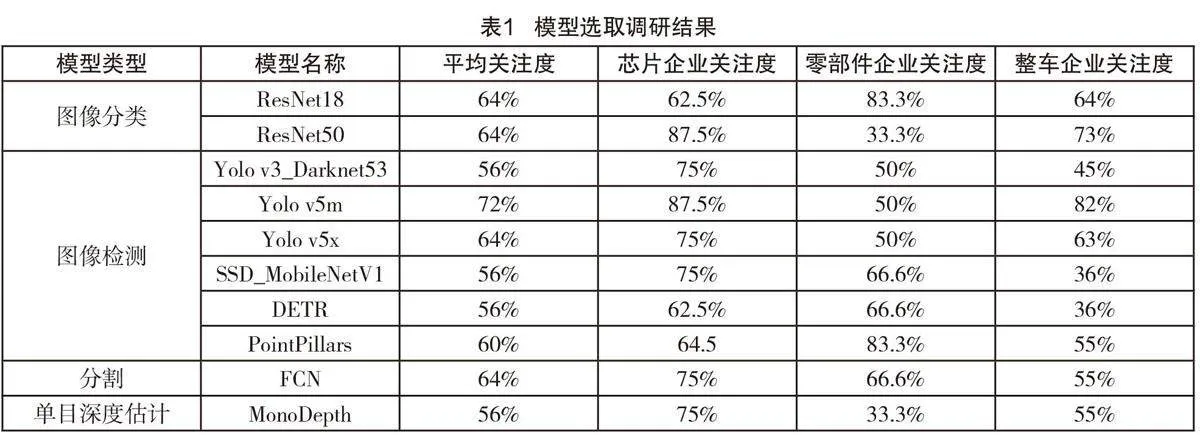
本文選擇的模型經面向行業廣泛調研后得出,調研對象包括整車企業、零部件企業、算法企業、芯片企業及測試機構等29家單位。調研內容包含汽車計算芯片常用應用場景、關注的性能指標、當前常用的模型列表及數據集列表,主要調研結果如表1所示。根據調研結果,選取企業選擇率超過50%的模型作為測試模型候選列表。
3.2 測試方案
3.2.1性能指標
根據智能駕駛應用需求,分析計算芯片應用場景,確定對應的性能指標和測試方法。經分析,算法模型作為支撐計算芯片完成計算任務的關鍵,基于不同應用場景,需適配不同的算法模型。芯片支持算法模型的數量決定計算芯片是否可適配多種任務類型,各算法模型對應的計算速度決定是否可以滿足大量數據的任務處理需求,這里以幀率(每秒處理的圖像數量)作為AI芯片計算能力體現的關鍵指標。
3.2.2 測試方案
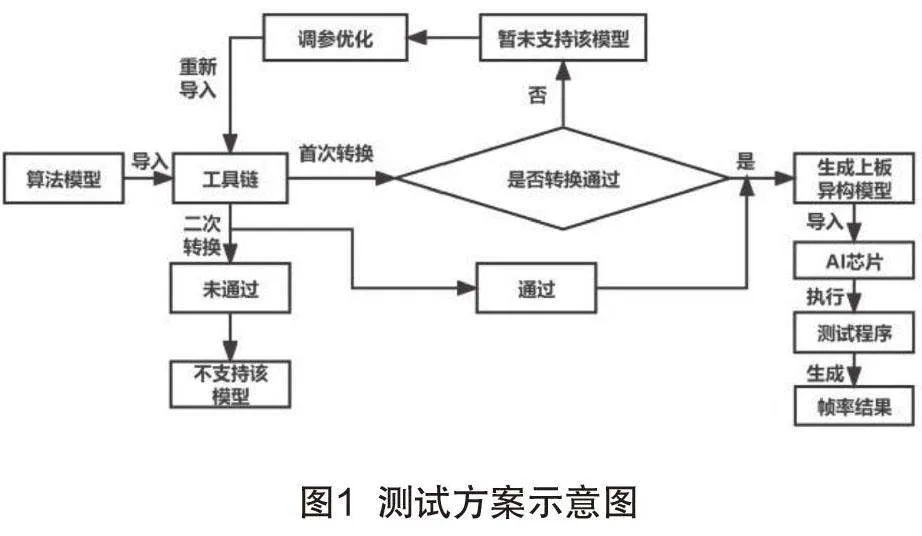
A I芯片的使用既需要芯片硬件性能作為基礎,也需要軟件為芯片基于應用場景的開發提供支撐,因此本文制定了工具鏈、芯片及算法模型這種軟硬結合的測試方案。計算芯片適配算法模型需要綜合考慮工具鏈的模型轉換能力和計算芯片硬件的計算能力,因此,本測試方案將計算芯片與其配套工具鏈作為整體進行評估,充分反應計算芯片的軟硬件結合綜合性能。本測試方案依托算法模型,打造更貼近于實際應用的性能指標和測試方法,如圖1所示。
3.2.3 測試項目說明
本文測試項目包括模型兼容性測試和幀率及時延測試。模型兼容性測試:通過芯片和工具鏈是否支持batch 1的公版模型轉換,判斷工具鏈的公版模型覆蓋度,即芯片產品對于算法模型的兼容性,記錄轉換通過和不通過的模型數量,根據通過模型數量和測試模型總數量的比值大小判斷產品的兼容性高低程度。
幀率及時延測試:在進行幀率測試時根據測試要求對應設置不同batch參數,根據不同模型大小設置size參數值,生成板上可運行的異構模型,按照測試要求設置測試參數如:線程數,優化模式等,調用測試程序執行測試。Batch值是一次訓練所選取的樣本數,同時可以反映芯片和工具鏈的能力,batch數值的不同會影響幀率,一般會將batch數值設置為batch1、batch2、batch4、batch8等多種參數,記錄不同batch測試結果,利用batch1的幀率值取倒數計算時延,并將最佳測試結果對應的測試設置記錄,作為該產品最優性能的詳細體現。
4 測試結果
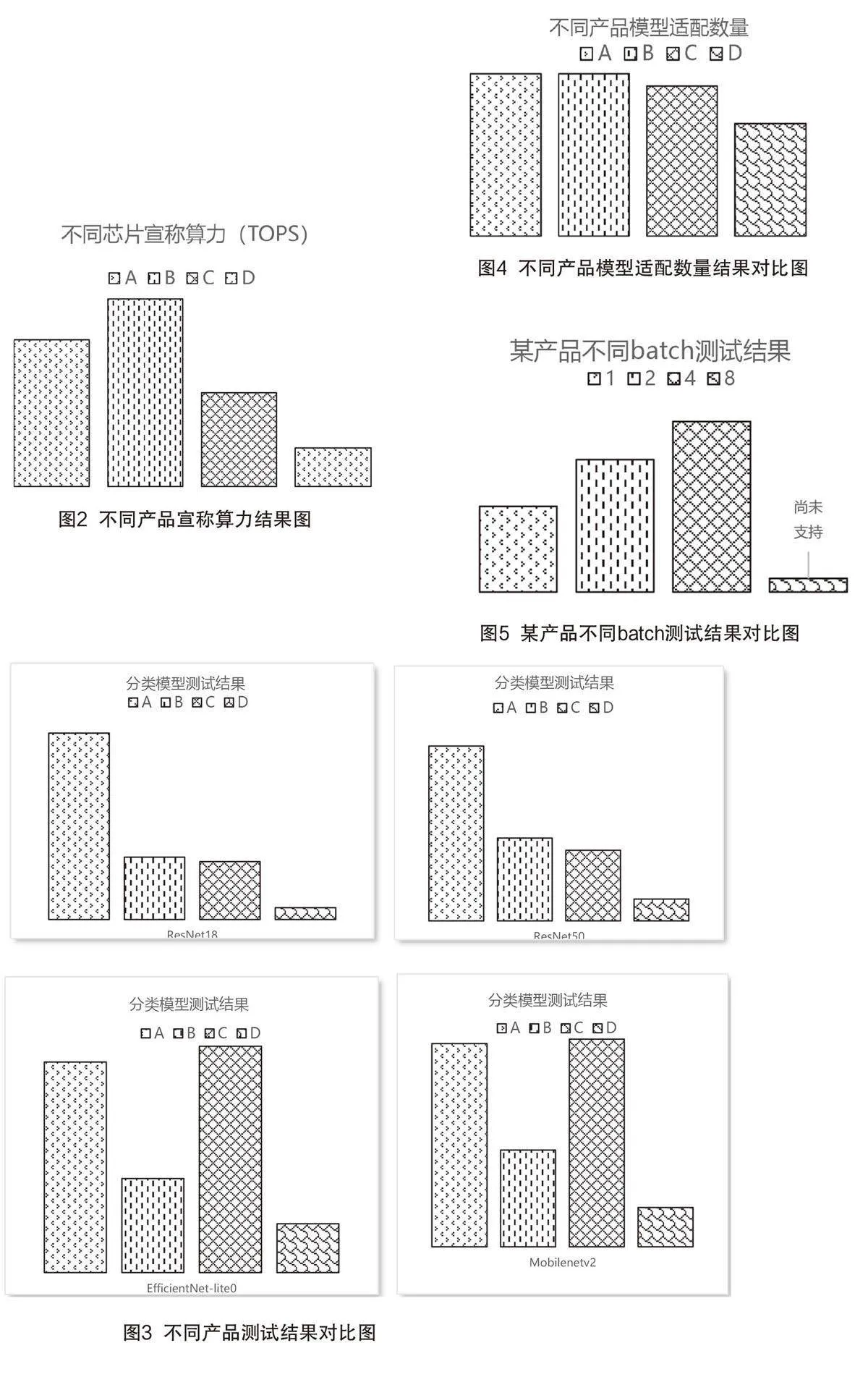
依據測試方案,通過摸底實驗已經取得國內外多款芯片測試結果,包含國內外的4款智能駕駛汽車AI芯片產品,以A、B、C、D代表,如圖2所示。
通過測試,本文也得出一些結論,首先是根據部分模型幀率測試結果可以看出,不同產品宣稱算力與實際計算測試結果并無正相關,如圖2中C產品算力與A相比差很多,但圖3中C產品的模型EfficientNet-lite0和MobileNetV2測試結果卻比A更好,因此可以得出,基于模型的幀率測試可以更真實地反映產品的計算能力;其次,根據測試結果也可以看出,不同產品的模型覆蓋數量即產品的兼容性存在差異,單一產品不同輸入樣本數量(batch)測試結果也存在較大差異,分別如圖4和5所示。
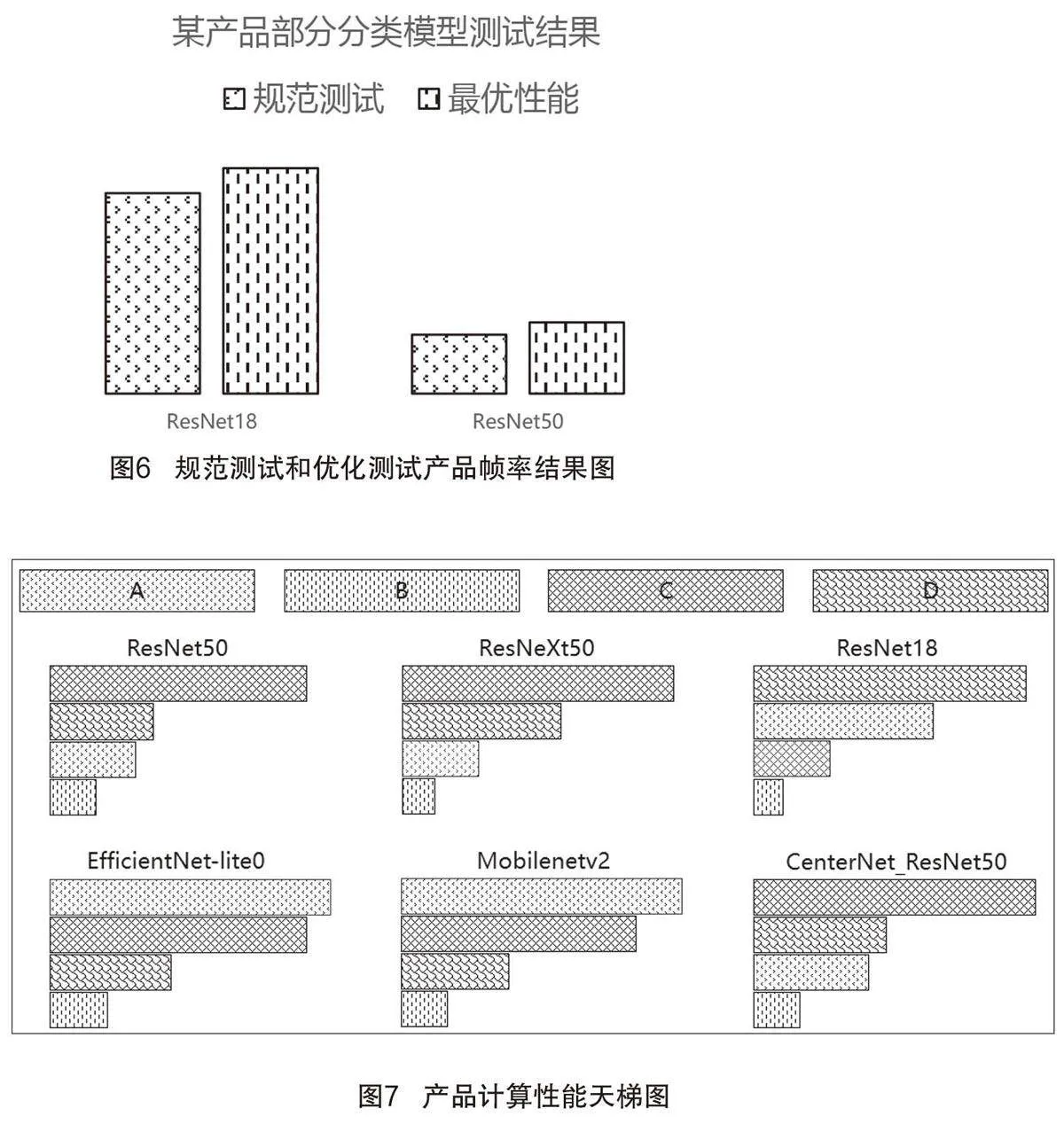
在測試過程中,除了對模型轉換batch參數、模型si ze等參數進行規定設置,還通過設置不同線程、不同計算核、不同優化模式等參數實現對不同產品的優化測試,獲得最優性能,如圖6所示。將最優性能與規范測試性能對比,既可展示企業產品的綜合性能,又可展現產品計算能力的優化空間水平。通過測試也得出,不同公版模型的渠道、版本等對測試結果影響較大。因此,測試的開展應保證輸入模型屬性的一致性,保證測試結果的對比性。
根據測試結果,我們形成了同一模型、統一測試條件下不同產品的幀率結果“天梯圖”,如圖7所示。該圖直觀呈現不同模型下各產品性能的排名情況,為汽車行業相關企業提供清晰的選型參考。
5 結論
本文基于對現有通用AI芯片性能測試的研究成果分析,提出了適用于智能網聯汽車領域,針對智能駕駛應用的AI計算芯片性能測試方法。本文基于行業調研結果選取多個性能測試模型,對多款汽車AI芯片進行測試,驗證測試方法對不同芯片產品的適用性。對測試結果進行深入分析,測試結果可提供兩方面的選型參考,(1)功能性驗證,評估工具鏈支持公版模型的數量和轉換能力,評估產品的通用性能力;(2)性能驗證,對不同產品的幀率測試結果進行對比驗證,評估產品的性能高低。本文提出的測試方法可用于汽車AI芯片計算性能的測試評價,并可以根據應用需求選取不同測試模型進行測試,測試結果具有可比性和一致性,可為企業進行芯片選型提供重要參考。在后續研究中可探索面向智能座艙應用場景的常用測試模型和測試方法。
