石油工程科研項目立項人工智能評審場景設計及技術路徑
2024-10-28 00:00:00劉沙楊超王宣戰楊志國
石油工程建設 2024年5期
摘" " 要:在黨中央“科技自立自強”發展戰略的號召下,中國石油集團積極推進各業務領域的科研工作,激發了各單位的創新活力,同時帶來了科研項目立項評審管理成本的激增問題。傳統的人工審查科研項目立項方式存在工作量大、效率低、主觀性強的缺點。依托人工智能技術發展現狀,結合石油工程科研項目立項創新性評審業務特點,設計科研立項智能審查應用場景,包括立項材料自動審閱、文獻資料自動搜索、評價指標自動打分、審查結論自動生成等,同時分析了技術實現路徑及面臨的挑戰。
關鍵詞:人工智能評審;石油工程;科研立項;創新性
Scenario design and technical path for artificial intelligence review in petroleum engineering research project
LIU Sha1, YANG Chao2, WANG Xuanzhan1, YANG Zhiguo1
1.Kunlun Digital Technology Corporation Limited, Beijing 100040, China
2.China Petroleum Technical Service Corporation Limited, Beijing 100007, China
Abstract:Under the guidance of the concept of “independence and self-reliance in science and technology” proposed by the CPC, CNPC has been promoting scientific research in all business areas. It has stimulated the innovation vitality of all units but also has brought about a sharp increase in the management cost of scientific research project approval review. The traditional manual review method gives a heavy workload and has low efficiency and strong subjectivity. Based on the development status of artificial intelligence and the review characteristics of the innovation of scientific research projects on petroleum engineering, this paper designs an application scenario for intelligent review of scientific research projects, including automatic review of project approval materials, automatic search of literature, automatic scoring of evaluation indicators, and automatic generation of review conclusions, etc. At the same time, it analyzes the technical implementation path and challenges faced in this method.
Keywords:artificial intelligence review; petroleum engineering; scientific research project approval; innovation
DOI:10.3969/j.issn.1001-2206.2024.05.016
2021年5月28日,習近平總書記發表了《加快建設科技強國,實現高水平科技自立自強》的重要講話[1],中國石油天然氣集團有限公司(簡稱中國石油)積極響應這一號召,加大了科技創新力度和投入,近年來,各級單位科研課題立項申報積極踴躍,激增的立項評審工作量與有限的評審專家資源之間的矛盾凸顯。傳統的人工審查方式存在耗時長、效率低、主觀性強等問題,已難以滿足科技管理工作降本增效、高質量發展的迫切需求。近年來,人工智能技術(AI,Artificial Intelligence)的發展,特別是自然語言處理、機器學習等技術的歷史性突破,使得人工智能技術在科研課題立項評審領域的應用成為可能。
1" " 現狀及問題
在當今國際競爭愈發激烈、科技快速發展的背景下,準確把控科研方向對于減少科研經費浪費、提高科研成果收益率至關重要。科研立項創新性和先進性指標審查是把控科研方向的核心環節[2],然而傳統的課題立項評審方式存在難以解決的問題,主要體現在以下三個方面。
1)人工檢索查重耗時長,審查效率低。在與課題相關的國內外研究現狀對比分析過程中,評審專家需要在各大國內外文獻數據庫開展多輪文獻檢索,人工篩選出相關度較高的文獻及專利并逐一瀏覽分析,再對比全文內容后得出相關度結論,這些工作耗費大量時間和精力。近年來,專家資源的增長速度遠低于新增科研課題增長速度,導致評審專家人均工作強度逐年增大。以中國石油下屬分公司中國石油集團油田技術服務有限公司(簡稱中油技服)為例,2022年共受理科研立項申請100余項,立項項目形式內部審查專家僅有3人,人均年審查項目數量約33項,按照每人每天5~6項課題的審核速率,需要大約一個星期才能完成,在立項評審階段通常有時效性要求,評審專家需要在短時間內審閱和分析大量資料,這給科研管理人員提出了極大挑戰,同時高工作強度易造成工作疲勞,進而影響評審質量[3]。
2)評審質量受制于評審專家能力水平。課題的創新性和先進性評審對專家專業素質的要求極高,評審專家需要對相關技術領域的國內外最新研究保持高敏感度,具備豐富的理論及實踐經驗。在科技快速發展的今天,科技前沿技術不斷迭代更新,對評審專家的知識更新速度也提出了更高要求。然而,當某一技術領域存在專家資源不足甚至空白的情況下,科研課題研究方向的創新性評審結果的準確性也將受到影響,可能導致并不具備創新性的課題卻被準予立項[4]。
3)當前的科研管理系統中自動化立項審查方式存在一些局限性。中國石油一直在不斷探索和推進科技管理信息化、數字化、智能化發展,自建科技管理平臺經過三代發展,在數據收集、資源共享、信息統計方面取得了顯著成果,但在數據智能處理方面仍有很大提升空間。新版科技管理平臺已實現對申請立項的科研項目名稱進行自動查重,與數據庫中已有文獻標題進行相似度對比,并列出相似論文標題、論文類型、作者、來源、發表時間等信息。然而,該系統仍無法對文獻資料全文進行檢索,也無法提取關鍵信息進行對比展示,全文內容對比分析仍需要人工方式干預。對于課題創新性水平評估,真正有參考價值的信息主要體現在課題材料,以及對標文獻的研究目標、技術路線和預期成果等詳情描述中,因此,僅憑標題相似度的評估結果無法客觀反映課題的創新性水平,也不能作為課題創新性指標評審的權威依據。綜上所述,科研課題立項創新性評審工作面臨著工作量大、效率低、質量難以保證等難題和痛點,亟需進一步探索實現基于大數據的人工智能評審技術,以實現創新性智能審查的新突破。
2" " 科研項目立項創新性評審工作流程
為實現科研立項創新性智能審查,首先需要了解傳統人工進行科研立項創新性審查工作的流程和關鍵控制點,然后逐項研究各個環節和控制點的人工智能技術方案。
傳統的科研立項創新性人工審查工作主要包括以下3個步驟。
1)立項材料分析及預期成果關鍵詞提取。評審專家需對立項申報材料進行全面、細致地審閱,準確識別和理解項目涉及的專業領域、研究方向、相關技術參數和預期成果等關鍵信息,不斷提取、凝練主要關鍵詞,形成關鍵詞組合,為文獻檢索做好前期準備。
2)在科研成果數據庫查驗是否已存在相關技術成果。評審專家結合自己在此技術領域的知識及經驗,通過企業內部科研成果數據庫及國內外知名數據庫,如中國知網學術期刊網、萬方數據庫、維普數據庫、中國知識產權局專利檢索數據庫、Springer、Engineering Village、Web of science等進行關鍵詞組合檢索,人工識別匹配度較高的文獻資料進行全文閱讀及分析,了解國內外相關技術的最新研究成果。
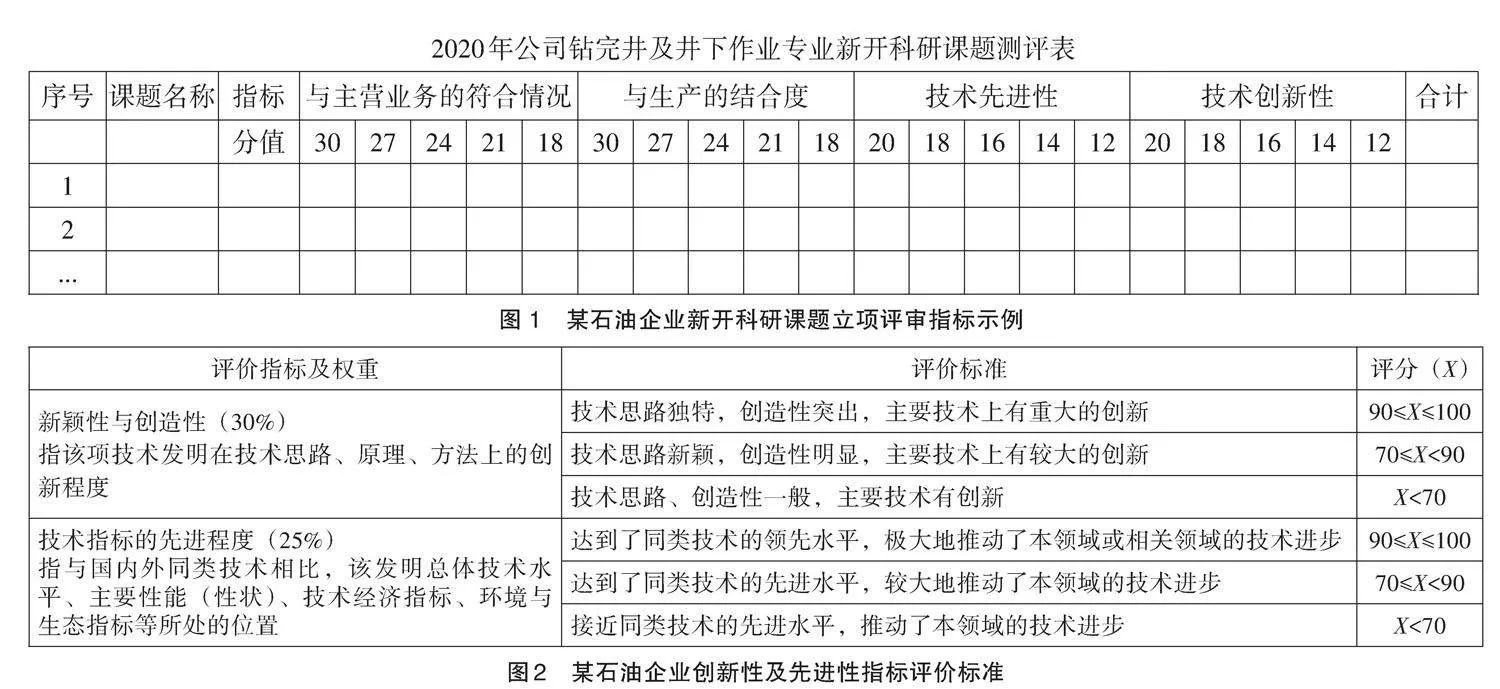
3)立項課題技術成果與數據庫查驗結果進行指標對比。評審專家將申報材料中的技術目標和研究內容與國內外技術現狀進行對比,完成相似度及差異性分析,評判材料的創新性程度,并結合具體的評價標準對立項材料進行評分。具體的創新性、先進性評價指標可參考圖1、圖2。
3" " 人工智能評審場景設計及技術路徑
根據前述科研立項創新性審查流程,結合當前人工智能技術的發展現狀,設計科研項目立項創新性人工智能評審的應用場景及技術路徑。
3.1" " 系統自動讀取立項材料關鍵信息
傳統的信息檢索功能已經能夠實現對單一或組合關鍵詞進行精確或模糊匹配檢索,并列出涵蓋關鍵詞的相關結果數據。但結果的準確性高度依賴于人工輸入關鍵詞的準確性,因此需要人工干預以確保關鍵詞質量。例如,在中國知網總庫搜索“抗高溫鉆井液”關鍵詞,會檢索到667條結果,如果要進一步判斷抗高溫具體溫度限值,則需要更為精準的關鍵詞輸入,審核專家必須反復篩選、調整更為聚焦、貼切的關鍵詞,進行多輪檢索查詢,這無疑將耗費大量的時間和精力。而借助人工智能技術,可替代人工識別關鍵詞的環節,實現系統自動識別關鍵信息。
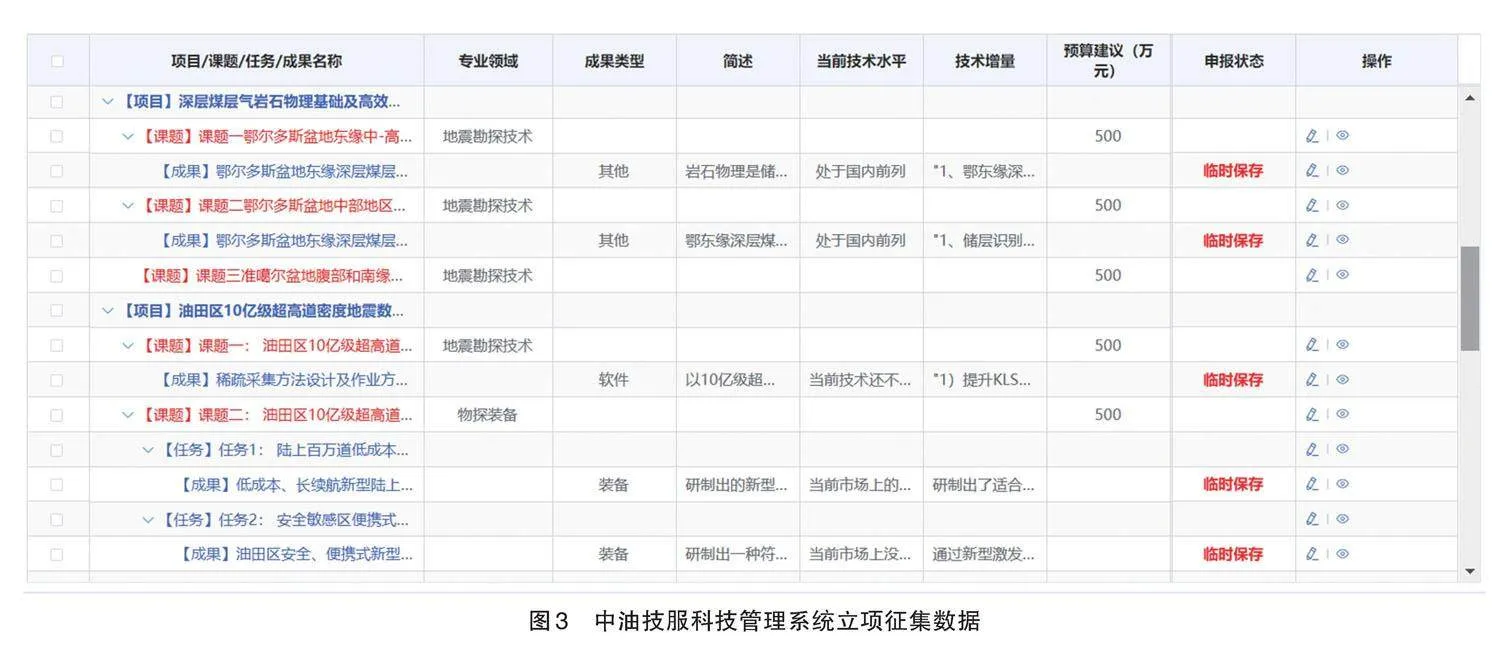
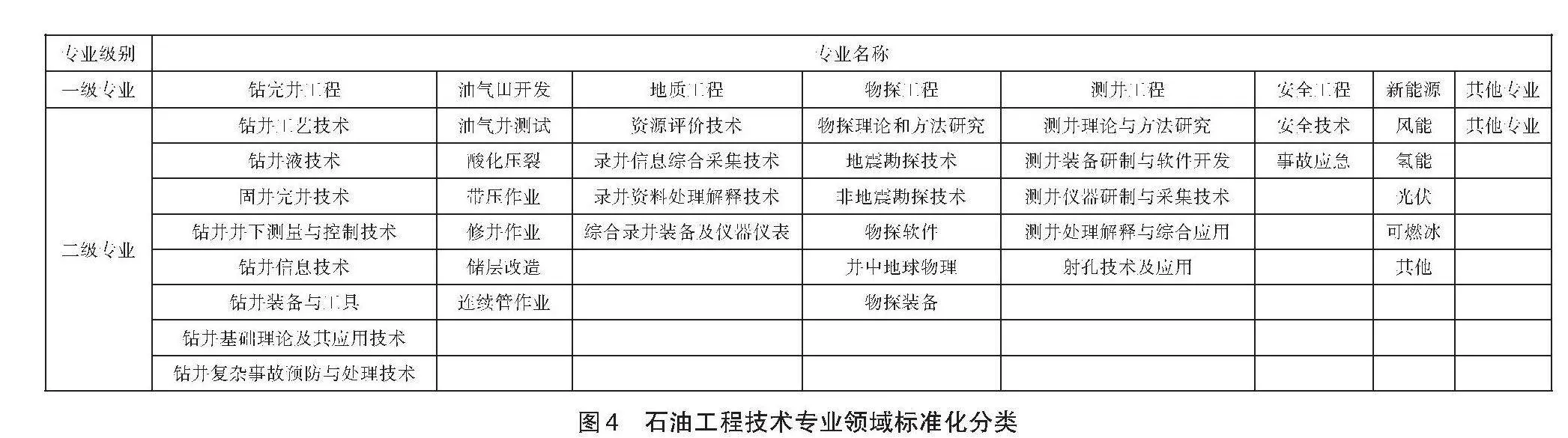
通過優化設計立項申報功能數據模型,將業務數據盡可能結構化、標準化錄入,形成核心數據模型(見圖3)。同時,將可標準化填報的數據項以數據編碼形式內置到系統中,如課題專業領域標準化分類(見圖4)、預期成果類型等數據,填報人可通過選項方式錄入,系統直接將其識別為關鍵詞;而對于暫不能標準化錄入的數據,如項目名稱、課題名稱、任務名稱、預期成果名稱、成果簡述及技術增量等文本數據,則需借助自然語言處理技術實現關鍵詞自動提取。自然語言處理技術使計算機可以理解人類語言并能夠進行閱讀和書寫,其實現主要得益于深度學習算法和機器學習算法,使得計算機可以對文本數據進行系統分析,提取關鍵信息以幫助用戶處理大量數據[5]。通過以上技術,計算機可以理解立項材料文本數據的語義,提取關鍵詞并建立關鍵詞組合。
為了實現自動提取文本數據關鍵詞的目標,必須首先建立石油工程技術專業大模型。根據《華爾街見聞》2023年5月24日的報道,一些擁有用戶數據積累的中小型企業,在醫療、金融、教育、繪畫等領域已開始利用國內外大模型作為“底座”,訓練適合自身需求的垂類模型[3]。舉例來說,百度的文心千帆作為一個“AI大模型底座”,目前正與各行業中信息化和技術普及程度較高的企業進行共同測試和研發,如金融、能源、泛互聯網等行業[6]。
成功訓練大模型的先決條件包括高質量的數據積累、充足的硬件及強大的算力支撐,以及對自身行業模型訓練和微調的能力。
在數據方面,石油工程技術科研立項創新性評價所需的數據來源主要有三個方面:中油技服科技管理系統數據庫、互聯網主流國際和國內期刊文獻服務平臺,以及國家知識產權局專利檢索及分析系統。中油技服科技管理系統數據庫結構化存儲了生產需求、項目名稱、研究內容、技術增量(創新點)及預期成果等數據,逐步構建科研項目數據庫;互聯網主流期刊文獻數據庫及國家知識產權專利數據庫通過購買數據或獲取數據庫訪問權限等方式,獲得高質量的原始數據。
在硬件及算力方面,中油技服科技管理系統建設依托中國石油自建的數據中心,具備支撐行業模型訓練的基礎設施條件,且小模型訓練對于算力需求較低,而大模型訓練則需要大量算力支持。根據趨動科技聯合創始人兼CTO" 陳飛博士于2023年11月在數據中心標準大會上的主題演講《從小模型到大模型——AI時代下的數據中心建設》,大模型訓練需要搭載2 000多個英偉達A100高端顯卡,訓練時間從一個月到幾個月不等,其算力消耗較大。然而,基于開源大模型微調要求的資源消耗較少,可通過量化、剪枝等技術手段將大模型裁剪,從而顯著降低算力需求,甚至可以使用單卡完成微調[7]。
在石油工程技術行業模型訓練方面,中國石油信息化承建單位昆侖數智有限責任公司已經開展相關研發工作。其通過本地化部署Llama、Baichuan、ChatGLM等開源大模型,并調用百度文心一言、訊飛星火等商用大模型相關服務接口,結合工程技術專業數據模型,構建適用于石油工程技術科研立項評審應用場景的專屬模型。
3.2" " 系統自動生成查新報告
在自動提取立項材料的關鍵信息后,系統采用關鍵詞組合模型算法模擬人工查詢方式,對本地科研項目數據庫、中國知網、維普網、專利網等平臺數據進行自動篩選和分級分類,篩選結果中的數據借助光學字符識別技術(OCR,Optical Character Recognition)進行全文掃描和文本提取,并通過語義對比技術和自然語言處理技術,根據其對語義的理解,尋找全文或部分相似的內容,以及主要含義相同但文字發生變動的文本[8],系統針對立項材料中的生產需求、研究目標、研究內容、技術增量(創新點)以及預期成果描述等進行相似度計算,生成客觀準確的查新報告,供評審專家進一步快速對比分析。系統可以代替專業查新機構和人工方式進行查新的工作,并能自動生成查新報告,提高查新效率,縮短立項評審周期。
3.3" " 系統自動量化打分
若要實現系統自動量化打分,需要將創新性、先進性指標評分標準進行量化,拆分為可識別和可度量的數據項。當前,中油技服立項評審指標設置現狀如圖1、圖2所示,由于立項課題類型和研究內容千差萬別,尚無針對不同細分專業領域的創新性和先進性評價標準量化指標,僅有粗略分值段設置,人工通過定性分析方法在評分區間內給出相應得分。建議結合查新報告中相似度計算結果,設定“相似度”閾值,相似度數值越低,對應的創新性和先進性得分越高。
4" " 人工智能技術應用面臨的挑戰
4.1" " 模型訓練需要大量成本投入
1)數據采購成本。以中國知網數據庫采購報價為例,合作方式為將知網數據庫復制到企業本地數據庫,費用包括首次購買費及年度更新費,根據需求的不同,費用范圍從幾十萬到幾百萬不等。
2)人工成本。AI領域的人才包括AI算法工程師、開發工程師、數據分析師、AI產品經理、測試工程師等。由于AI人才緊缺且供不應求,其薪資也水漲船高。根據獵聘網2024年2月最新數據查詢,全國AI工程師月均薪資為27 095元,其中北京、上海、深圳、杭州等一線城市AI工程師月平均薪資均達到3萬元以上[9]。
4.2" " 數據質量風險
人工智能的深度應用需要防范一系列潛在風險隱患,例如訓練模型的語料庫和數據庫本身質量欠佳,以及缺乏高質量的開源文獻資料,這可能導致模型訓練進展緩慢,訓練結果差強人意甚至存在歪曲誤導的可能。根據《IT之家》2023年8月8日的報道,美國普渡大學的研究發現,美國人工智能研究公司OpenAI開發的人工智能聊天機器人ChatGPT在回答軟件編程問題時,錯誤率超過50%。其研究報告的結論稱:盡管ChatGPT的回答語言風格流暢,但其中52%的回答是錯誤的,77%的回答過于冗長。只有當回答中的錯誤很明顯時,參與者才能識別出來,否則他們容易被ChatGPT的友好、權威和細致的語言風格所誤導[10]。因此,需要采取必要措施保證數據質量,如加強本地內部數據的治理和清洗工作,并積極與優質文獻供應商尋求合作來獲取高質量數據。
4.3" " 信息安全風險
近年來,國際社會的信息戰愈演愈烈,這對各國有企事業單位的信息安全工作提出了更高的要求。在實現AI智能模型訓練過程中,不可避免地需要與互聯網優質數據資源進行互動,這就要求企業局域網進一步提升信息安全保護級別,以確保局域網與互聯網之間的數據交互安全,防止可能存在的攻擊、滲透,避免造成商業機密、個人隱私數據泄漏甚至遭黑客勒索的風險,這些風險給企業信息安全保障工作帶來了更多挑戰。
5" " 結束語
綜上所述,在可預見的人工智能應用場景中,利用人工智能技術實現立項信息自動讀取、對標數據庫進行自動檢索關聯數據并進行相似度計算、自動生成查新報告,以及自動進行創新性和先進性指標量化評分等。但也必須認識到這些場景實現過程中可能面臨的挑戰,在有效控制成本和風險的前提下,充分利用人工智能產品高效的數據處理能力開展智能產品的研發,使其更好地勝任評審專家智能助手的角色,幫助評審專家分擔海量材料瀏覽、信息提取、資料查詢及對比分析工作,可為評審專家進一步開展立項研判提供參考依據。
參考文獻
[1]" 習近平. 加快建設科技強國,實現高水平科技自立自強[J]. 求知,2022(5):4-9.
[2]" 劉泓葦,劉江華,陳忠平. 科研課題的立題與信息檢索[J]. 醫學信息,2009,22(9):1 758-1 760.
[3]" 樊俊. 中法科研項目立項評審機制比較研究——以法國國家科研署項目和國家重點研發計劃為例[J]. 科學管理研究,2019,37(1):106-109.
[4]" 寧輝東. 工業制造企業的科研項目立項管理研究[J]. 財經界,2020(4):55-56.
[5]" 付晨. 基于人工智能技術的項目文檔規范性審核技術研究[J]. 電子技術與軟件工程,2019(14):250.
[6]" 于惠如. 國內大模型迎來中場戰事[Z]. 全天候科技,2023-05-24.
[7]" 星林科技. 從小模型到大模型——AI時代下的數據中心建設[EB/OL]. 脈脈. (2024-01-03)[2024-03-05].
[8]" 馬曉華. 基于自然語言處理技術的IT治理審計方法研究[J]. 財會通訊,2021(1):144-148.
[9]" 獵聘網. AI工程師薪資待遇[EB/OL].[2024-03-05]. https://www.liepin.com/zpaigongchengshi/xinzi/
[10] IT之家. 研究發現:ChatGPT回答編程問題的錯誤率超過50%[EB/OL].(2023-08-08)[2024-03-05].https://tech.ifeng.com/c/8S50jukVn0Y.
作者簡介:
劉" " 沙(1985—),女,河北涿州人,工程師,2008年畢業于燕山大學里仁學院法學專業,現從事石油工程信息系統方案設計、項目管理方面的工作。Email:liusha@cnpc.com.cn
收稿日期:2024-06-18
