
多智能體強化學習在多域無人作戰任務規劃中的應用
2024-10-30 00:00:00牛雙誠黃海明
無人機 2024年8期
隨著軍事需求的拓展和技術進步的推動,現代戰爭呈現出明顯的無人化趨勢。作為高效費比、攻防兼備的新裝備,無人系統將在未來作戰中發揮越來越重要的作用,承擔多種作戰任務,不斷創新部隊戰術和裝備體系。
目前,以無人機為代表的大量多域無人系統已進入部隊服役,無人車、無人艇、無人潛航器也正在被加緊論證和研制,多域無人作戰力量體系正在加速形成。但是,當前無人系統存在自主性低,在作戰中嚴重依賴地面人員的指揮控制,快速響應、自主決策能力弱等突出問題。同時,各類無人系統之間基本不具備協同作戰能力,缺乏有效可靠的實時任務規劃手段,難以發揮體系作戰優勢。多域無人作戰任務規劃研究迫在眉睫。
多智能體強化學習概述
作為一種先進機器學習技術,強化學習在多域無人作戰任務規劃中展現出巨大的應用潛力。特別是無人機,通過與環境持續交互學習,能夠優化自身行為策略,以應對復雜多變的任務場景。多智能體強化學習(Multi-agent Reinforcement Learning,MARL)是多種智能體運用強化學習前沿技術,不斷與環境交互、不斷試錯來解決多種智能體序列決策問題。它不需要事先知曉外部環境的物理模型,避免了基于專家經驗、繁瑣的人工規則設計,具有很強的通用性。目前,DQN、PPO、QMIX、MAAC、A2C、PSRO、PipelinePSRO、MADDPG等多智能體強化學習算法相繼問世,并在星際爭霸、谷歌足球等人工智能(AI)游戲中得到成功驗證。多智能體強化學習理論的成功應用為多域無人作戰任務規劃開辟了一條新路徑。
強化學習(Reinforcement Learning,RL)是機器學習的一個重要分支,其本質是智能體在與環境交互的過程中不斷學習策略,以實現最大化回報或特定目標。與監督學習不同的是,強化學習并不指導智能體如何產生正確的動作,只對動作好壞做出評價,并根據反饋信號修正動作選擇和策略。因此,強化學習的回報函數所需的信息量較少且易于設計,更適合解決較為復雜的規劃與決策問題。
當強化學習在多個領域的應用取得巨大成功后,工程技術人員將研究目標轉向了多智能體領域,并展開大量研究,直接催生了多智能體強化學習理論。多智能體強化學習是一套解決多個智能體協同完成任務的方法集,也是智能體與環境不斷交互來學習最優策略的方法,遵循隨機博弈過程。當前,隨著多智能體強化學習理論的持續深入發展,適用不同領域的眾多智能架構及算法應運而生,并逐步在軍事等領域體現了較高應用價值。
多智能體強化學習在任務規劃中的應用
當以星際爭霸為代表的實時戰略游戲應用多智能體強化學習算法時,經常采用這種方法:游戲中的雙方作戰單元被抽象為智能體,通過全局設定,智能體之間建立合作、競爭等關系,而多智fd778edc55a4afeaa7eaa955ed9454f4能體強化學習算法以勝利為目標設計獎勵函數。這種方法非常適合在軍事作戰運籌與任務規劃領域中應用。隨著智能化戰爭時代的到來,聯合全域作戰、分布式作戰等新作戰樣式將顛覆現有戰爭形態。未來,觀察—判斷—決策—行動(OODA)作戰環中的作戰單元正在由有人系統轉為無人系統集群,而對抗也從單智能體間的對抗轉向了協同作戰的異構智能體集群對抗,感知、認知、行為發展正在推動未來指控體系邁向新臺階。
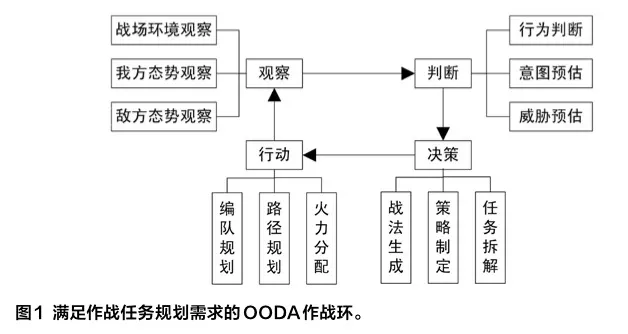
OODA作戰環是美國空軍傳奇人物博伊德提出的一種以觀察、判斷、決策、行動循環來描述作戰對抗的軍事理論。基于對作戰諸要素的理解與思辨,軍方在軍事對抗中如何從全局、局部、作戰任務、裝備、技術等不同主線出發,構建能達到作戰目標的OODA作戰環,是不同層級軍事對抗制勝之鑰。從作戰運籌學的角度出發,作戰任務作為核心要素,存在于OODA作戰環構建的全過程。本文以OODA作戰環中的子作戰任務規劃需求為主線,構建OODA作戰環。
OODA作戰環中的作戰任務規劃包含諸多子任務規劃。下面選取威脅預估、策略制定、路徑規劃、火力分配四個子任務規劃進行簡要分析。
威脅預估
威脅預估是判斷環節任務規劃的重點工作。依據敵我雙方的兵力部署、裝備性能、敵方攻擊意圖和我方作戰策略,多智能體強化學習機制采用定量分析方法對敵方威脅等級進行評估。快速多變的現代戰場要求指揮員必須具備更快的超前反應能力和更強的作戰指揮能力,從戰場上海量多源信息中實時分析和評估目標威脅等級,從而盡可能提前制定對抗敵方作戰行動的決策,而不是在敵方行動后再做出決策。這種超前決策行動更適合復雜、多變、突發性強的未來作戰場景,能發揮非常重要的作用。提高戰場制勝能力的關鍵舉措是,己方及時準確評估敵方目標威脅等級,并根據己方作戰方案和作戰系統性能,提前規劃科學合理的火力分配方案,提前制定打擊決策。
策略制定
策略制定是決策環節任務規劃的核心工作。隨著戰爭向信息化、智能化方向發展,軍方越來越需要智能規劃與決策系統來輔助指揮員進行作戰規劃和指揮。智能規劃與決策系統消除了人的主觀因素影響,具有自我學習、修正、推理和決策能力,顯著提高了作戰任務規劃的準確性和實時性,提升了情報分析、輔助決策和指揮控制能力。
美國國防預研局“深綠”計劃采用計算機仿真技術與深度強化學習技術來推演不同作戰方案可能產生的結果,通過預估敵方行動,智能系統縮短了美軍制訂作戰計劃的時間,輔助指揮員快速做出正確決策。
深腦(DeepMind)公司開發的強化學習決策系統在多種戰略任務執行過程中可以達到與人類匹敵的效果,甚至在某些特定場景下超越了人類智慧,為作戰任務規劃提供了解決方案。
路徑規劃
在行動環節,作戰單元路徑規劃是任務規劃的基石。路徑規劃可分為全局路徑規劃和局部路徑規劃。與其他路徑規劃算法相比,強化學習具有一個重要優勢,它不依賴環境建模,不需要環境先驗知識,只需發出獎勵信號,智能體便采用試錯的方式,與周圍環境不斷交互,最終找出最優策略。強化學習方法將傳感器收集的外界環境數據映射到執行器,從而使智能體對外界環境變化做出快速響應,實現自主路徑規劃。該方法具有實時、快速和魯棒性強的優點。此外,模仿強化學習、強化互學習以及部分基于模型的強化學習方法可以有效利用機理模型等先驗信息,提升采樣樣本的利用效率,從而大大提升規劃效率與準確率。
火力分配
火力分配是行動環節任務規劃的最終工作。基于威脅預估和目標排序,己方對裝備打擊敵方目標的方式做出決策。在作戰場景中,敵我雙方裝備具有多樣性、對抗性和不確定性等特征,而矩陣對策法、優勢函數法、優化指向向量法等傳統火力分配方法難以快速準確完成最優火力分配。智能體利用基于強化學習的火力分配方法,能夠感知自身所處的戰場環境,并通過獎勵反饋,自適應外部環境,從而構建更加準確合理的戰場火力分配模型。現有算法將作戰火力分配建模抽象為整數規劃問題,并采用中心化或去中心化的傳統優化算法進行求解。
綜上分析,以作戰任務規劃為主線,戰略、戰術目標被分解,諸多作戰環節中的二級任務、三級任務形成邊界模糊、拓展性強的作戰任務空間。在時空驅動和事件觸發下,任務規劃方法按照因果邏輯規則,朝著序列化、柵格化方向發展,而OODA作戰環持續迭代,成為OODA作戰網,諸多復雜作戰體系相應出現。多智能體強化學習算法可以利用激勵反饋機理、集中式架構、分布式架構等,完成作戰任務規劃中的輔助感知與決策,從而提升體系作戰效能。
總結
在未來智能化、信息化作戰背景下,軍方將對多域無人作戰體系進行仿真,在任務規劃中應用多智能體強化學習技術。在指揮控制和情報保障無縫銜接的基礎上,基于最新態勢和目標,完成超實時仿真分析與效能評估,預測戰爭走勢,透視戰場未來變化。同時,在作戰過程中,實現作戰資源動態、靈活配置,不斷優化調整作戰行動方案。
