基于全局頻域池化的行為識別算法
2024-11-04 00:00:00賈志超張海超張闖顏蒙蒙儲金祺顏之岳
計算機應用研究 2024年9期



摘 要:目前基于3D-ConvNet的行為識別算法普遍使用全局平均池化(global average pooling,GAP)壓縮特征信息,但會產生信息損失、信息冗余和網絡過擬合等問題。為了解決上述問題,更好地保留卷積層提取到的高級語義信息,提出了基于全局頻域池化(global frequency domain pooling,GFDP)的行為識別算法。首先,根據離散余弦變換(discrete cosine transform,DCT)看出,GAP是頻域中特征分解的一種特例,從而引入更多頻率分量增加特征通道間的特異性,減少信息壓縮后的信息冗余。其次,為了更好地抑制過擬合問題,引入卷積層的批標準化策略,并將其拓展在以ERB(efficient residual block)-Res3D為骨架的行為識別模型的全連接層以優化數據分布。最后,將該方法在UCF101數據集上進行驗證。結果表明,模型計算量為3.5 GFlops,參數量為7.4 M,最終的識別準確率在ERB-Res3D模型的基礎上提升了3.9%,在原始Res3D模型基礎上提升了17.4%,高效實現了更加準確的行為識別結果。
關鍵詞:3D-ConvNet; 人體行為識別; 全局平均池化; 離散余弦變換
中圖分類號:TP319 文獻標志碼:A
文章編號:1001-3695(2024)09-042-2867-07
doi:10.19734/j.issn.1001-3695.2023.11.0596
Action recognition algorithm based on global frequency domain pooling
Jia Zhichao1, Zhang Haichao1, Zhang Chuang1,2, Yan Mengmeng1, Chu Jinqi1, Yan Zhiyue1
(1.College of Electronic & Information Engineering, Nanjing University of Information Science & Technology, Nanjing 210044, China; 2.Jiangsu Key Laboratory of Meteorological Observation & Information Processing, Nanjing 210044, China)
Abstract:The current 3D-ConvNet-based action recognition algorithms generally use GAP to compress feature information. However, it leads to issues of information loss, redundancy, and network overfitting. To address these issues and enhance the retention of high-level semantic information extracted by the convolutional layer, this paper proposed an action recognition algorithm based on GFDP. Firstly, DCT shows that GAP is a special case of feature decomposition in the frequency domain. Therefore, the algorithm introduced more frequency components to increase the specificity between feature channels and reduce the information redundancy after information compression. Secondly, to better suppress the overfitting problem, the algorithm introduced the batch normalization strategy to the convolutional layer and extended it to the fully connected layer of the action recognition model with ERB-Res3D as the skeleton to optimize the data distribution. Finally, this paper verified the proposed method on the UCF101 dataset. The results reveals that the model’s computational load is 3.5 GFlops, with 7.4 million para-meters. The final recognition accuracy improved by 3.9% based on the ERB-Res3D model and 17.4% based on the original Res3D model. This improvement effectively achieves more accurate behavior recognition results.
Key words:3D-ConvNet; human action recognition; global average pooling; discrete cosine transform
0 引言
隨著智能手機、便攜式設備的普及,以及短視頻APP的蓬勃發展,每個人都可以成為短視頻的生產者。視頻的內容包含人們生活的方方面面,其中以人為中心,旨在分析出視頻中人與人、人與物互動時表現出的動作類別的技術,被稱為人體行為識別(HAR)技術。HAR是利用模式識別技術進行視頻理解的重要研究方向[1~3],在智能安防、人機交互、智慧教育等領域都有著重要的應用[4~6]。
近年來,基于深度學習的行為識別方法層出不窮,其中主流的方法大致可以分為三類,即基于Two-Stream[7]的行為識別方法、基于RNN[8]的行為識別方法和基于3D-ConvNet[9]的行為識別方法。現在,有的研究依舊使用光流來描述視頻中的運動信息[10, 11],但這對計算和存儲要求較高,不利于數據集大規模的訓練和部署,因此3D-ConvNet開始作為建模視頻中時間信息的重要手段。在基于3D-ConvNet的行為識別方法中,諸如Res3D[12]、I3D[13]、R(2+1)D[14]、TSM[15]等眾多算法模型大都以ResNet[16]為基礎骨架,而ResNet在卷積層向全連接層過渡時,采用全局平均池化對最末層卷積輸出的特征圖進行信息壓縮,只保留一個均值表示該通道特征圖所蘊涵的高級語義信息。這種做法雖然實現了較大程度的信息壓縮,減少了后續全連接層的參數量和浮點運算量,但當不同通道的特征圖均值相同時,原本表示不同特征信息的特征圖就會表達出相同的語義,使得壓縮后的均值特征缺乏多樣性,從而產生信息損失和信息冗余的問題[17]。
離散余弦變換作為有損壓縮的核心成員之一,在深度學習領域中具有廣泛的應用。研究者們發現將數據轉換至頻域,以頻域視角重新思考數據的處理流程,通過引入更多的頻率分量來充分利用網絡中的數據信息,能夠對CNN模型的性能有很好的改善效果。其中,李長海[18]以數據預處理為切入點,認為常見的預處理主要針對RGB圖像進行數據增強、歸一化等,單一的RGB圖像表達的時空特征有限,因此李長海利用DCT將空域中的RGB圖像數據變換到頻域,并作為CNN的輸入來提取頻域特征,再與原RGB圖像為輸入的時域通道提取的時空特征相融合,豐富模型的特征信息,進而提高模型性能。Qin等人[19]提出了FcaNet,在注意力機制中以頻域視角重視全局平均池化,通過引入多個頻率分量來充分利用CNN提取到的特征信息,彌補GAP造成的特征損失,最終在ImageNet、COCO等圖像分類任務中表現出了較好的效果。Yang等人[20]基于DCT卷積,提出了CDF-Net,能夠有效提取和融合輸入樣本的頻域和空間特征。Yu等人[21]在不壓縮信道的情況下,將頻域信息與空間信息相結合,提出了一種基于頻空域轉換的服裝分類網絡,該算法有效地提高了服裝分類的準確率。
針對上述GAP中存在的特征損失問題,以及研究者們在頻域視角里對人體行為特征提取尚未深入研究,本文提出了一種基于全局頻域池化的人體行為識別算法。一方面,通過離散余弦變換分析了全局平均池化出現信息損失和信息冗余問題的原因是全局平均池化在壓縮特征信息時只保留了最低頻率分量而沒有考慮其他頻率分量帶來的影響,本文通過引入多個低頻分量提出了全局頻域池化方法,來豐富算法模型降采樣后特征信息的多樣性。另一方面,引入卷積層的批標準化策略并拓展至全連接輸出層,降低了模型過擬合的風險。最終在UCF101數據集上進行消融實驗,驗證全局頻域池化對模型的性能具有提升效果。
1 方法
1.1 全局平均池化的頻域分析
為了能夠將時域中的GAP映射在頻域中,本文采用在圖像處理領域經常使用的離散余弦正變換DCT-Ⅱ和反變換DCT-Ⅲ,其中二維DCT表達式為
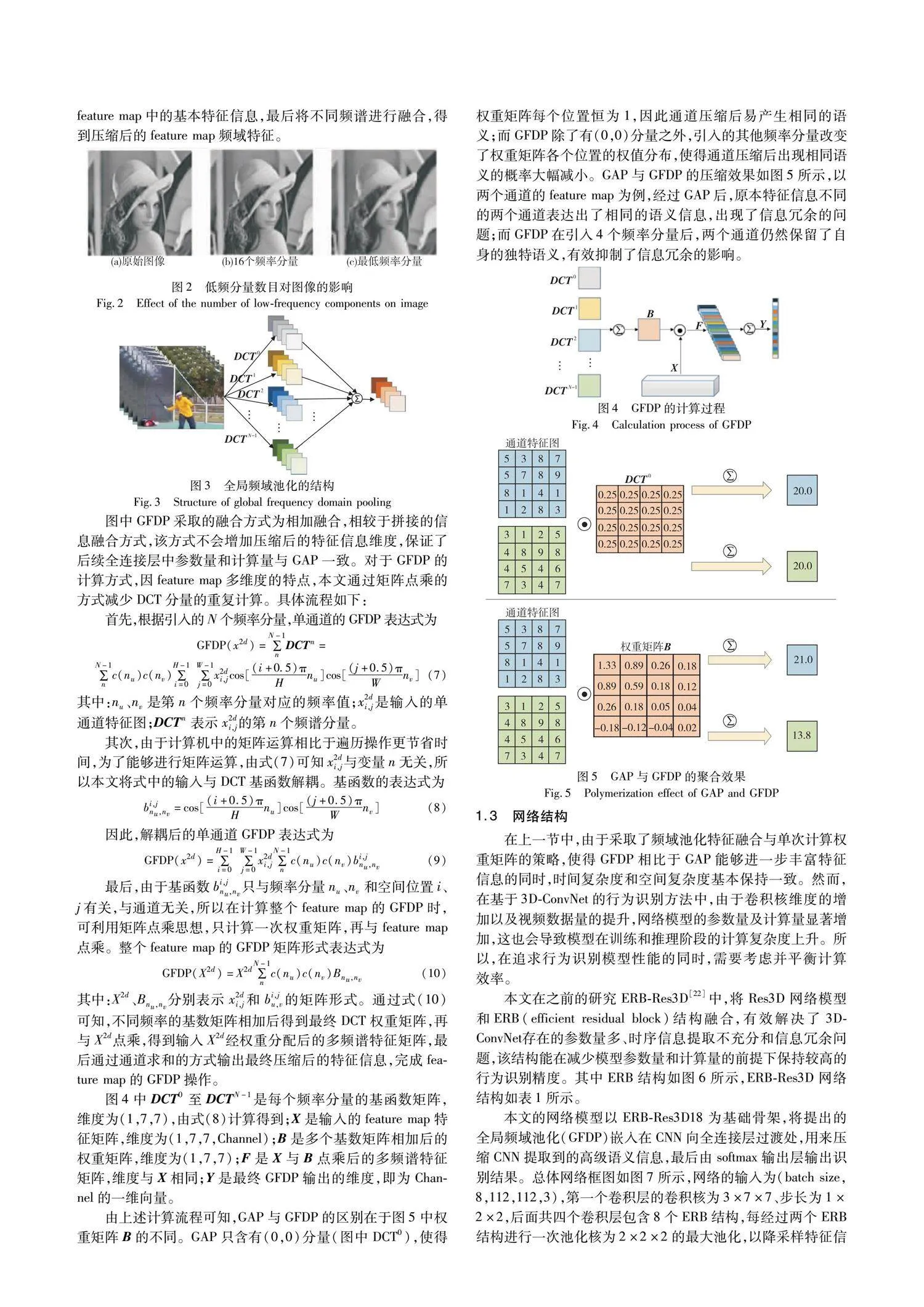
由上述計算流程可知,GAP與GFDP的區別在于圖5中權重矩陣B的不同。GAP只含有(0,0)分量(圖中DCT0),使得權重矩陣每個位置恒為1,因此通道壓縮后易產生相同的語義;而GFDP除了有(0,0)分量之外,引入的其他頻率分量改變了權重矩陣各個位置的權值分布,使得通道壓縮后出現相同語義的概率大幅減小。GAP與GFDP的壓縮效果如圖5所示,以兩個通道的feature map為例,經過GAP后,原本特征信息不同的兩個通道表達出了相同的語義信息,出現了信息冗余的問題;而GFDP在引入4個頻率分量后,兩個通道仍然保留了自身的獨特語義,有效抑制了信息冗余的影響。
1.3 網絡結構
在上一節中,由于采取了頻域池化特征融合與單次計算權重矩陣的策略,使得GFDP相比于GAP能夠進一步豐富特征信息的同時,時間復雜度和空間復雜度基本保持一致。然而,在基于3D-ConvNet的行為識別方法中,由于卷積核維度的增加以及視頻數據量的提升,網絡模型的參數量及計算量顯著增加,這也會導致模型在訓練和推理階段的計算復雜度上升。所以,在追求行為識別模型性能的同時,需要考慮并平衡計算效率。
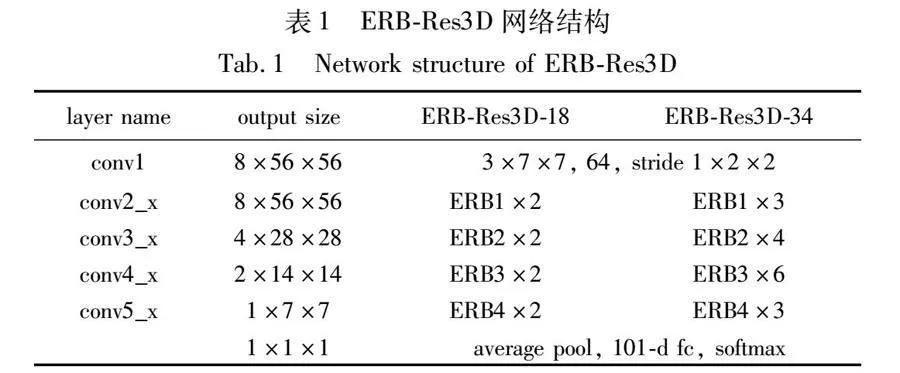
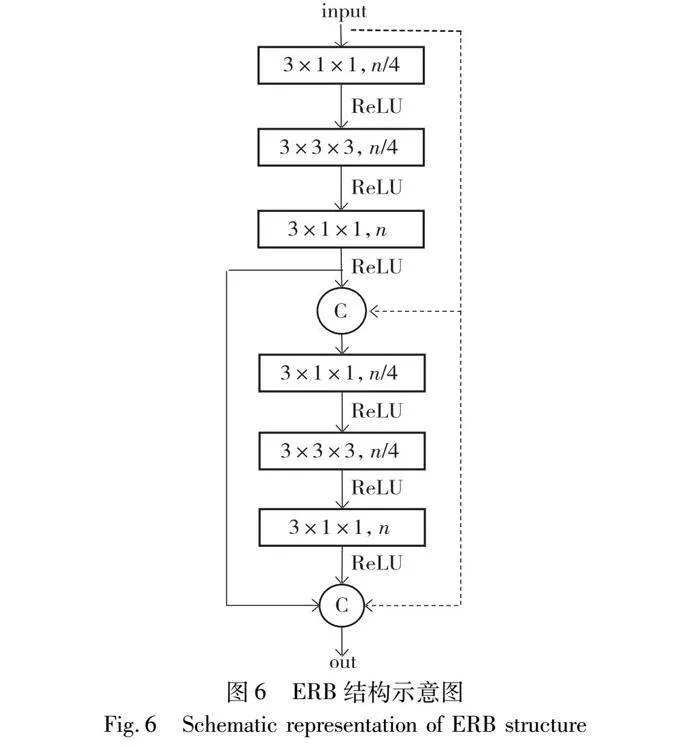
本文在之前的研究ERB-Res3D[22]中,將Res3D網絡模型和ERB(efficient residual block)結構融合,有效解決了3D-ConvNet存在的參數量多、時序信息提取不充分和信息冗余問題,該結構能在減少模型參數量和計算量的前提下保持較高的行為識別精度。其中ERB結構如圖6所示,ERB-Res3D網絡結構如表1所示。
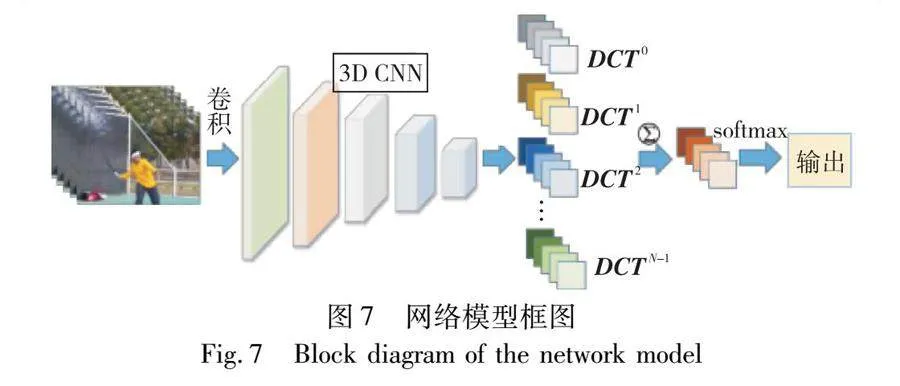
本文的網絡模型以ERB-Res3D18為基礎骨架,將提出的全局頻域池化(GFDP)嵌入在CNN向全連接層過渡處,用來壓縮CNN提取到的高級語義信息,最后由softmax輸出層輸出識別結果。總體網絡框圖如圖7所示,網絡的輸入為(batch size,8,112,112,3),第一個卷積層的卷積核為3×7×7、步長為1×2×2,后面共四個卷積層包含8個ERB結構,每經過兩個ERB結構進行一次池化核為2×2×2的最大池化,以降采樣特征信息,最終最后一個ERB的輸出維度為(batch size,1,7,7,1536),然后由GFDP壓縮每個通道的特征信息,使得全連接層的輸入維度為(batch size,1536),最后由softmax函數輸出識別結果。同時為了使網絡模型更好地適應每個batch size的輸入數據,本文在所有卷積層和全連接層后都加入了批標準化(BN)來標準化數據。
2 實驗與分析
2.1 數據集
本文選用UCF101行為識別數據集[23]進行實驗驗證。該數據集中的視頻主要從You Tube中獲取。行為類別涉及人與物體交互、單純的肢體動作、人與人交互、演奏樂器、體育運動五個方面,共包含101類行為動作。每類動作被分為25組,每組包含一個動作的4~7個視頻,共13 320個視頻,總計時長約有27 h。數據集部分行為實示例如圖8所示。
對于UCF101數據集的劃分,官網有3種訓練集和測試集的劃分策略。本文選擇split01方法進行劃分,其中訓練集共有9 537個視頻序列,約占數據集總量的70%,測試集共有3 783個視頻序列,約占數據集總量的30%。實驗時先通過訓練集訓練模型參數,最后用訓練好的模型在測試集上的識別精度作為最終的實驗結果。
2.2 實驗設置
2.2.1 實驗環境
本文在Intel CoreTM I5-9400F,NVIDIA GeForce GTX 1600 SUPER(6 GB),2.9 GHz CPU、64位Windows 10操作系統上進行實驗,采用Python語言編程,TensorFlow-Slim輕量級庫搭建神經網絡模型。
2.2.2 超參數設置
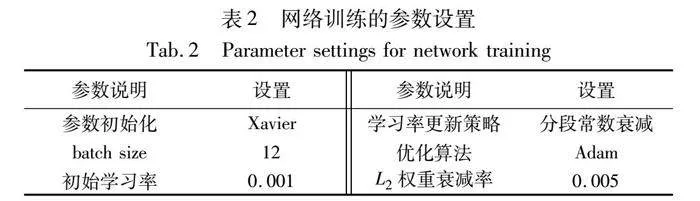
訓練階段,使用Xavier方法[24]初始化網絡參數,采用小批量數據(mini-batch)進行訓練,根據顯卡性能batch大小設置為12。學習率的調整采用分段常數衰減策略,前50個epoch設置為0.001,之后每20個epoch衰減為原來1/10,直至網絡收斂;反向傳播時,采用交叉熵損失函數衡量網絡損失,使用Adam優化算法[25]更新模型參數,采用L2正則化和BN[26]兩種策略防止網絡出現過擬合。網絡訓練的參數設置如表2所示。
測試階段,首先等間隔地抽取測試集中一段視頻的8幀圖像,并采用中心剪裁的方式處理抽取到的圖像序列作為網絡輸入,然后通過前向傳播輸出101個行為分類得分,最終取得分最高的類別為預測結果。
2.3 消融實驗
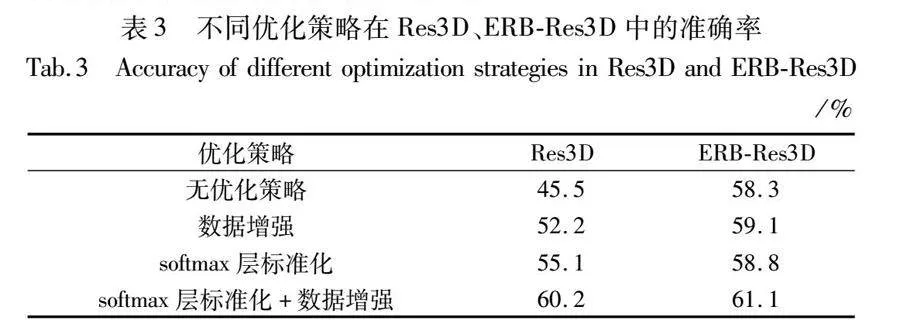
在對Res3D網絡進行改進時,本文采取了一系列的優化手段,有引入的數據增強、ERB模塊以及softmax層標準化,也有本文設計的全局頻域池化。為了充分驗證四個策略,無論是單獨使用還是結合使用都對模型的性能有提升效果,本文先沿用最初的GAP操作,以UCF101為基準數據集,按照官方提供的split01劃分訓練集和測試集,通過數據增強、softmax層標準化在原始Res3D模型和ERB-Res3D模型上的表現,驗證除全局頻域池化之外的三個優化策略的有效性(對于全局頻域池化對模型的影響將在下一節探索)。不同的優化策略在兩個模型中的準確率如表3所示。
首先按列分析,從表中數據可知,數據增強、softmax層標準化單獨使用時,無論是在Res3D模型中還是ERB-Res3D模型中,識別準確率都高于無優化策略時的模型,而且當兩種策略結合使用時,對識別準確率會有進一步的提升。但對于不同模型,兩者單獨使用時雖都有明顯的效果,但提升的幅度卻因模型而異。其中在Res3D模型中,softmax層標準化提升的準確率比數據增強高了2.9%,表明在Res3D中softmax層標準化發揮的作用更大;在ERB-Res3D模型中,數據增強提升的準確率只比softmax層標準化高了0.3%,兩者相差無幾,表明在該模型中兩種策略都發揮了自身該有的作用。
其次按行分析,對于數據增強和輸出層標準化兩種優化策略,無論是不使用、單獨使用還是結合使用,ERB-Res3D都表現出了比Res3D更好的性能,這再次印證了ERB模塊對模型性能的提升效果。但是逐行分析可知,在無優化策略時,相較于Res3D的準確率,ERB-Res3D有12.8%的提升;單獨使用數據增強和softmax層標準化時分別有6.9%、3.7%的提升,兩者共同使用時有0.9%的提升,準確率提升的幅度隨著優化策略的增加而減弱,表明ERB模塊在過擬合較嚴重的網絡中能表現出更好的效果,體現了ERB隱含的解決過擬合的能力,而且當數據量充足、網絡不存在過擬合問題時,ERB也可減少模型的參數量和浮點運算量,實現輕量化。
最后,綜合分析表中數據,以Res3D模型無優化策略為基準,當數據增強、softmax層標準化和ERB三種策略單獨使用時,準確率分別為52.2%、55.1%和58.3%,相較于基準的45.5%都有不同程度的提升,表明三種策略都對模型性能的提升有效,而且當三種策略共同使用時,準確率達到了61.1%,在所有方案中表現出了最好的效果。因此在接下來的實驗中,將以三種策略共同使用時的Res3D模型為基礎骨架,探索全局頻域池化中不同類型和不同數量的頻率分量對識別結果的影響。
2.4 頻率分量的選擇實驗
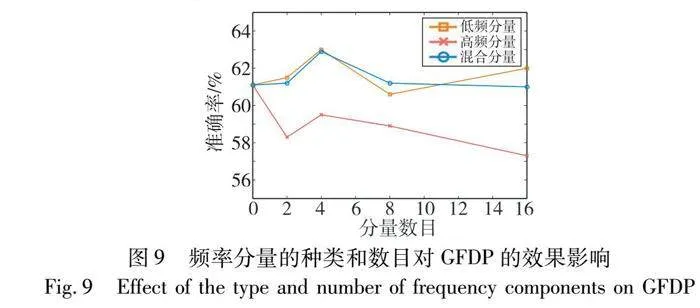
從圖1中圖像在頻域中的頻譜分布可知,低頻分量蘊涵了絕大部分圖像信息,因此理論上,當全局頻域池化引入有限低頻分量時,feature map壓縮后的特征信息更豐富,進而更能提升模型的性能。為了驗證低頻分量在全局頻域池化中的效果,本節設置實驗,從低頻分量、高頻分量以及混合分量(低頻、高頻混合)三類頻率分量出發,觀察引入不同數目的分量時模型的識別準確率,驗證低頻分量對全局頻域池化的有效性,同時探究分量數目對全局頻域池化的影響。
對于引入的頻率分量數目,因Res3D最終輸出的單通道特征圖維度是(1,7,7),所以在頻域中共有49個頻率分量,本次實驗通過分別引入1、2、4、8、16個頻率分量來觀察全局頻域池化對模型性能的影響,最終確定合適的頻率分量數目,實驗結果如圖9所示。首先,對于分量的類型,低頻分量和混合分量明顯比高頻分量表現的效果要好,且低頻分量效果整體更佳,表明模型對低頻分量蘊涵的特征信息更加敏感。當引入高頻分量時,模型與引入1個分量(GAP)相比,識別準確率不升反降,表明高頻分量雖然也包含特征圖的相關信息,但并不適合模型性能的提升,所以應盡量減少高頻分量的引入;其次,對于引入的分量數目,從圖中可以看出引入2個或者8個分量的準確率相近,當引入4個分量時,無論低頻分量還是高頻分量、混合分量,都在該類型分量中表現最好,表明引入分量的多少,并非與模型表現出的效果呈正比,選擇合適數目的分量才能實現最佳的識別效果。
2.5 與其他行為識別方法比較
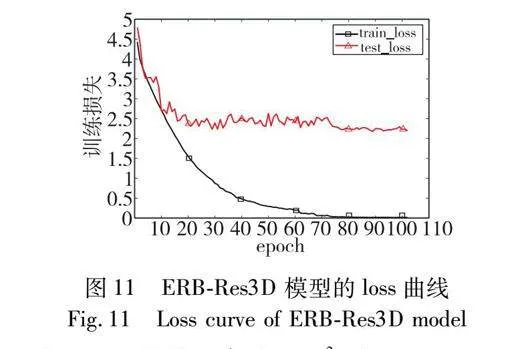
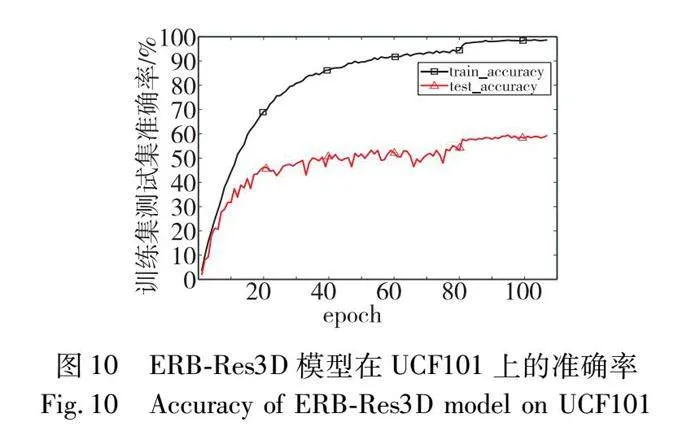
經上述的消融實驗和頻率選擇實驗,本文以ERB-Res3D模型為基礎骨架,選擇引入4個低頻分量的全局頻域池化和softmax層標準化為最終的行為識別模型。首先,模型的識別準確率和loss曲線如圖10和11所示。
前80個epoch的學習率為10-3,在0~20 epoch中訓練集和測試集的準確率上升幅度較大,但在21~80 epoch中訓練集準確率和損失值變化較為平緩,且呈現出緩慢上升的趨勢,測試集的準確率和損失值振蕩明顯,表明模型不穩定;在80 epoch之后學習率為10-4,無論是訓練集還是測試集,準確率和loss值均在開始時有較大幅度的變化,之后振蕩幅度逐漸趨于平緩,模型逐漸穩定。最終訓練集和測試集的準確率分別保持在99.6%和62.3%左右,且loss值分別在0.01和2.22上下浮動。
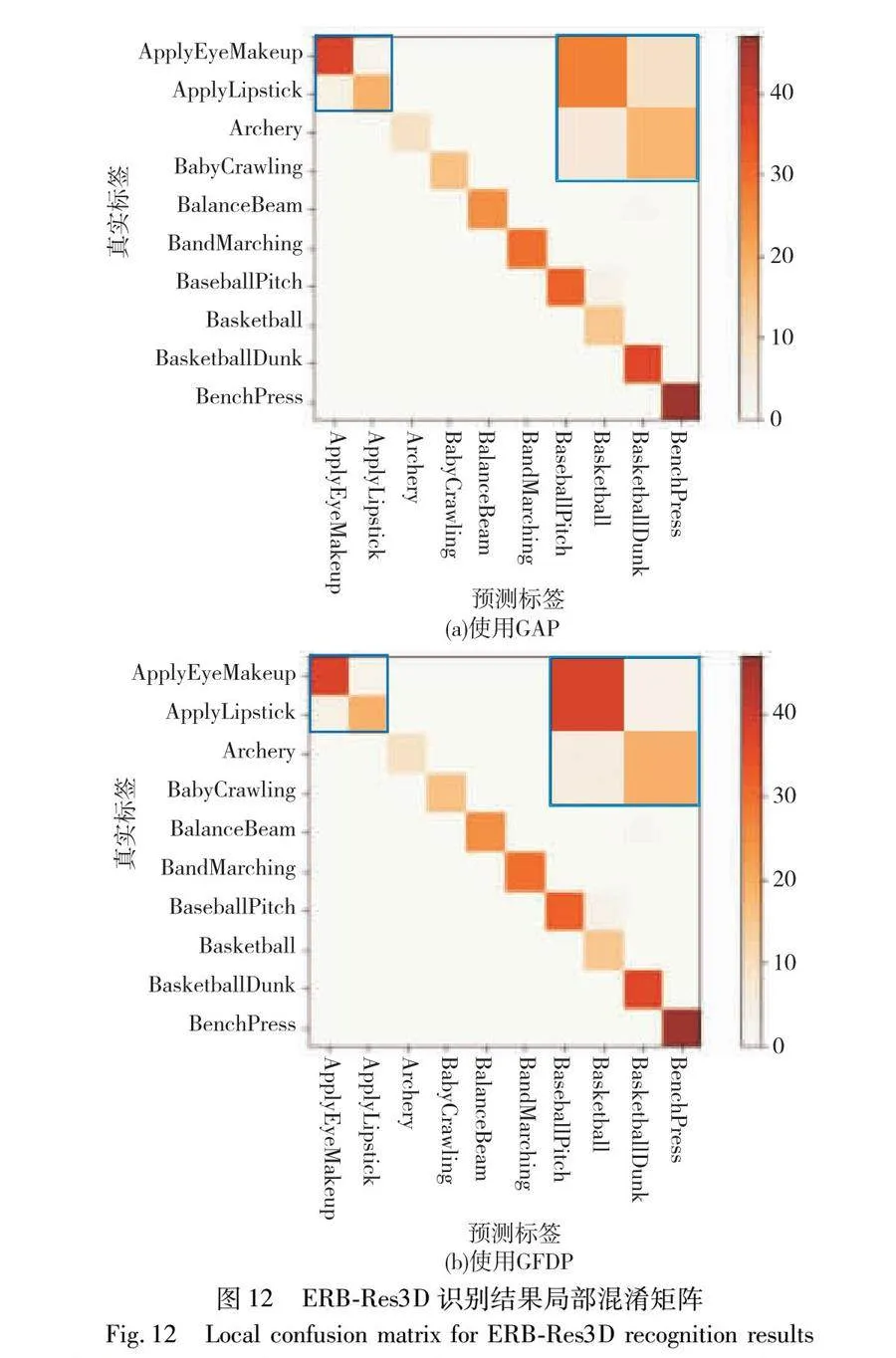
其次,為了方便觀察模型對不同類別的識別精度,本文將ERB-Res3D模型不使用GFDP和使用GFDP時,在UCF101測試集上的預測結果分別繪制成混淆矩陣,如圖12所示。
圖12為ERB-Res3D在UCF101數據集前10種類別的識別結果局部混淆矩陣,橫坐標為模型預測的行為標簽,縱坐標為真實行為標簽。通常情況下,當預測標簽與真實標簽相同即為識別正確,在混淆矩陣中為對角線的位置。從圖中可以看出,對于大部分行為類別,ERB-Res3D模型識別正確的樣本個數遠大于識別錯誤的樣本個數(圖中顏色越深,表示數值越大),但也存在少部分行為識別誤差較大。
為了更好地證明GFDP的有效性,對比圖12(a)與(b),可以看出本文模型在對角線位置上的色度更深,表明識別正確的數量更多。特別是左上角中動作存在相似性的apply eye makeup(化眼妝)和apply lipstick(涂口紅)兩類行為,本文模型預測結果基本集中在正確位置(對角線),而ERB-Res3D模型會有一定的概率錯誤地識別兩類行為。圖13為ERB-Res3D識別結果具體樣本案例,在同一樣本案例下,使用GFDP能夠準確識別出原先識別錯誤的視頻樣本,表明本文模型在區分相似行為時能夠表現出更高的魯棒性。
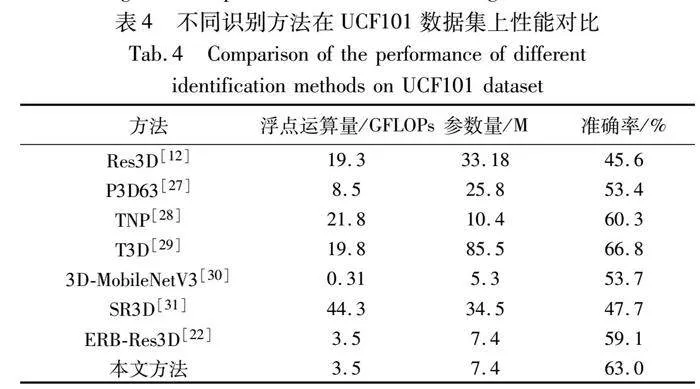
最后,為了驗證所提模型的優勢,將本文模型與當下流行的行為識別方法分別在浮點運算量、模型參數量和識別準確率三個性能指標上進行比較,其結果如表4所示。
從計算量和浮點運算量上分析,相比于ERB-Res3D方法,本文方法參數量并沒有增加,浮點運算量上增加了DCT變換帶來的計算量,由于數值較小可基本忽略,所以在這兩個性能指標上與ERB-Res3D方法對比其他行為識別方法的分析相同。從表4中可以看出,本文方法最后的浮點運算量對比基準模型Res3D下降了81%,而參數量也降低了77%,可以直觀地看出模型具有很好的輕量化效果。
對表中數據綜合分析可知,本文方法的識別準確率對比ERB-Res3D方法提高了3.9%,對比基準模型Res3D提高了17.4%;T3D的準確率最高,比本文方法高了3.8%,但浮點運算量和參數量卻是本文的5.7倍和11.6倍;3D-MobileNetV3的計算量和浮點運算量最低,但準確率比本文方法低了9.6%。結果表明,本文方法在維持計算量和浮點運算量的基礎上,提升了模型的識別準確率,使模型表現出了更高的性能。
3 結束語
針對3D-ConvNet中全局平均池化存在的信息損失和信息冗余問題,為了更好地保留卷積層提取到的高級語義信息,本文提出了一種基于全局頻域池化的人體行為/D6pyHNKQwWeQ25dqRQ9LmGV4pd8R7KUwKUK17s8Rhg=識別算法。一方面,由離散余弦變換分析了全局平均池化出現信息損失和信息冗余問題的原因是全局平均池化在壓縮特征信息時只保留了最低頻率分量而沒有考慮其他頻率分量帶來的影響,并通過引入多個低頻分量提出了全局頻域池化方法,來豐富算法模型降采樣后特征信息的多樣性。另一方面,引入卷積層的批標準化策略并拓展至全連接輸出層,降低了模型過擬合的風險。在相關數據集上的消融實驗可以看出,引入四個低頻分量的全局頻域池化對模型性能的提升效果最佳。最終的實驗結果表明,本文方法可以利用較低的浮點運算量和參數量實現更高的識別準確率。
下一步的研究方向可以從更加細粒度的角度出發,先觀察每個頻率分量單獨使用時模型表現出的性能,然后按照性能提升的幅度,從高到低依次引入不同數目的頻率分量,以便更好地補充特征信息,解決信息損失問題。隨后,可以延伸至卷積神經網絡中非全局的最大池化和平均池化,以尋找更為優越的降采樣技術。
參考文獻:
[1]朱相華, 智敏, 殷雁君. 基于2D CNN和Transformer的人體動作識別[J]. 電子測量技術, 2022, 45(15): 123-129. (Zhu Xianghua, Zhi Min, Yin Yanjun. Human action recognition based on 2D CNN and Transformer[J]. Electronic Measurement Technology, 2022, 45(15): 123-129.)
[2]張銀環. 基于IA-Net的人體行為識別方法[J]. 國外電子測量技術, 2022, 41(6): 52-59. (Zhang Yinhuan. Human action recognition method based on IA-Net[J]. Foreign Electronic Measurement Technology, 2022, 41(6): 52-59.)
[3]Ahn D, Kim S, Hong H, et al. STAR-Transformer: a spatio-temporal cross attention transformer for human action recognition[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway, NJ: IEEE Press, 2023: 3319-3328.
[4]Mobasheri B, Tabbakh S R K, Forghani Y. An approach for fall prediction based on kinematics of body key points using LSTM[J]. International Journal of Environmental Research and Public Health, 2022, 19(21): 13762.
[5]梁緒, 李文新, 張航寧. 人體行為識別方法研究綜述[J]. 計算機應用研究, 2022, 39(3): 651-660. (Liang Xu, Li Wenxin, Zhang Hangning. Review of research on human action recognition methods[J]. Application Research of Computers, 2022, 39(3): 651-660.)
[6]Mo Jianwen, Zhu Rui, Yuan Hua, et al. Student behavior recognition based on multitask learning[J]. Multimedia Tools and Applications, 2023, 82(12): 19091-19108.
[7]Simonyan K, Zisserman A. Two-Stream convolutional networks for action recognition in videos[C]//Proc of the 27th International Confe-rence on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 568-576.
[8]Wang Xianyuan, Miao Zhenjiang, Zhang Ruyi, et al. I3D-LSTM: a new model for human action recognition[J]. IOP Conference Series: Materials Science and Engineering, 2019, 569(3): 032035.
[9]Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3D convolutional networks[C]//Proc of IEEE International Conference on Computer Vision. Piscataway,NJ:IEEE Press,2015: 4489-4497.
[10]周生運, 張旭光, 方銀鋒. 基于行人組運動信息表達的人群異常檢測[J]. 儀器儀表學報, 2022, 43(6): 221-229. (Zhou Shengyun, Zhang Xuguang, Fang Yinfeng. Crowd anomaly detection based on pedestrian group motion information expression[J]. Chinese Journal of Scientific Instrument, 2022, 43(6): 221-229.)
[11]Liu Daizong, Fang Xiang, Hu Wei, et al. Exploring optical-flow-guided motion and detection-based appearance for temporal sentence grounding[J]. IEEE Transactions on Multimedia, 2023,25:8539-8553.
[12]Du T, Ray J, Shou Zheng, et al. ConvNet architecture search for spatiotemporal feature learning[EB/OL]. (2017-08-16). https://arxiv.org/abs/1708.05038.
[13]Carreir J, Zisserman A. Vadis Q. Action recognition?A new model and the kinetics dataset[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 4724-4733.
[14]Tran D, Wang Heng, Torresani L, et al. A closer look at spatiotemporal convolutions for action recognition[C]//Proc of IEEE Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2018: 6450-6459.
[15]Lin Ji, Gan Chuang, Han Song. TSM: temporal shift module for efficient video understanding[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 7082-7092.
[16]He Kaiming, Zhang Xia, Ren Shaoqing, et al. Deep residual lear-ning for image recognition[C]//Proc of IEEE Conference on Compu-ter Vision and Pattern Recognition. Piscataway, NJ: IEEE Press,2016: 770-778.
[17]Ehrlich M, Davis L. Deep residual learning in the JPEG transform domain[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 3483-3492.
[18]李長海. 基于深度學習的人體行為識別算法研究[D]. 成都:電子科技大學, 2021. (Li Changhai. Research on human action recognition algorithm based on deep learning[D]. Chengdu: University of Electronic Science and Technology of China, 2021.)
[19]Qin Zequn, Zhang Pengyi, Wu Fei, et al. FcaNet: frequency channel attention networks[C]//Proc of IEEE/CVF International Confe-rence on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 763-772.
[20]Yang Aitao, Li Min, Wu Zhaoqing, et al. CDF-Net: a convolutional neural network fusing frequency domain and spatial domain features[J]. IET Computer Vision, 2023, 17(3): 319-329.
[21]Yu Feng, Li Huiyin, Shi Yankang, et al. FFENet: frequency-spatial feature enhancement network for clothing classification[J]. PeerJ Computer Science, 2023, 9: e1555.
[22]張海超, 張闖. 融合注意力的輕量級行為識別網絡研究[J]. 電子測量與儀器學報, 2022, 36(5): 173-179. (Zhang Haichao, Zhang Chuang. Research on lightweight action recognition network fusing attention[J]. Journal of Electronic Measurement and Instrumentation, 2022, 36(5): 173-179.)
[23]Soomr K, Zamir A R, Shan M. UCF101: a dataset of 101 human actions classes from videos in the wild[EB/OL]. (2012-12-03). https://arxiv.org/abs/1212.0402.
[24]Gloro X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[C]//Proc of the 13th International Conference on Artificial Intelligence and Statistics.[S.l.]:PMLR,2010: 249-256.
[25]De S, Mukherjee A, Ullah E. Convergence guarantees for RMSProp and ADAM in non-convex optimization and an empirical comparison to Nesterov acceleration[EB/OL]. (2018-11-20). https://arxiv.org/abs/1807.06766.
[26]Ioffe S, Szeged C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//Proc of the 32nd International Conference on Machine Learning.[S.l.]: JMLR.org,2015: 448-456.
[27]Qiu Zhaofan, Yao Ting, Mei Tao. Learning spatio-temporal representation with Pseudo-3D residual networks[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2017: 5534-5542.
[28]劉釗, 楊帆, 司亞中. 時域非填充網絡視頻行為識別算法研究[J]. 計算機工程與應用, 2023, 59(1): 162-168. (Liu Zhao, Yang Fan, Si Yazhong. Research on time Domain unfilled network video behavior recognition algorithm[J]. Computer Engineering and Applications, 2023, 59(1): 162-168.)
[29]Diba A, Fayya M, Sharm V, et al. Temporal 3D ConvNets: new architecture and transfer learning for video classification[EB/OL]. (2017-11-22). https://arxiv.org/abs/1711.08200.
[30]胡希國. 基于視頻的輕量級人體行為識別算法研究[D]. 成都: 電子科技大學, 2021. (Hu Xiguo. Research on lightweight human action recognition algorithm based on video[D]. Chengdu: University of Electronic Science and Technology of China, 2021.)
[31]徐鵬飛, 張鵬超, 劉亞恒,等. 一種基于SR3D網絡的人體行為識別算法[J]. 電腦知識與技術, 2022, 18(1): 10-11. (Xu Pengfei, Zhang Pengchao, Liu Yaheng et al. A human action recognition algorithm based on SR3D network[J]. Computer Knowledge and Technology, 2022, 18(1): 10-11.)
收稿日期:2023-11-02;修回日期:2024-01-10 基金項目:國家自然科學基金資助項目(62272234)
作者簡介:賈志超(2000—),男,安徽天長人,碩士研究生,主要研究方向為深度學習;張海超(1997—),男,河南洛陽人,碩士,主要研究方向為深度學習、行為識別;張闖(1976—),女(通信作者),河北唐山人,副教授,碩導,博士,主要研究方向為光電信息、視覺信息采集與處理(zhch_76@163.com);顏蒙蒙(1995—),女,江蘇連云港人,碩士研究生,主要研究方向為深度學習、行為識別;儲金祺(1998—),男,江蘇泰州人,碩士研究生,主要研究方向為深度學習、目標檢測;顏之岳(1999—),男,江蘇常州人,碩士研究生,主要研究方向為小目標檢測.
