基于復合知識蒸餾的骨科影像診斷分類研究
2024-11-07 00:00:00王烤吳欽木
軟件工程 2024年11期


摘要:針對醫療設備存儲資源有限的問題,提出一種基于復合知識蒸餾的診斷分類方法,旨在確保骨科影像診斷模型的高精度性能。該方法首先采用自適應直方圖均衡化對數據集進行增強;其次引入知識蒸餾,選用EfficientNet\|B7作為教師網絡、EfficientNet\|B0作為學生網絡,同時對學生網絡引入漸進式自蒸餾,以提升特征挖掘和泛化能力。在MURA(MusculoskeletalRadiographs)數據集上進行驗證的結果表明,復合知識蒸餾(CKD)模型的準確率為96.26%,其參數量僅為EfficientNet\|B7模型參數量的8.48%,并且在準確率方面僅下降了1.16%,驗證了此模型的有效性。
關鍵詞:骨科影像;自適應直方圖均衡化;特征挖掘;知識蒸餾;漸進式自蒸餾
中圖分類號:TP391文獻標志碼:A
0引言(Introduction)
X射線影像作為骨科疾病檢測的一種經濟且高效的工具,其應用廣泛但受限于需要專業醫師進行耗時診斷,可能會延誤診斷和治療[1]。基于深度學習的診斷模型能在短時間內提供準確的診斷信息,從而有效減輕醫生的工作負擔并提高診斷效率[2]。然而,骨科影像具有低分辨率、低對比度、多紋理等特點,如果僅使用DNN(DeepNeuralNetwork)對其進行特征提取及分類,可能效果不盡如人意。同時,盡管深度學習在骨科影像識別等領域取得了顯著成就,但也面臨資源需求高和過擬合等挑戰[3]。雖然已有研究者提出如剪枝[4]、量化[5]、知識蒸餾[6]等輕量化的方法用來降低模型的參數量和計算復雜度,但是在分類精度上仍有一定的提升空間。
基于此,提出一種基于復合知識蒸餾的深度學習診斷模型。在預處理階段,引入了自適應直方圖均衡化[7],以處理骨科影像的亮度和對比度變化,以提高骨科影像數據集的質量。在模型構建上,選擇EfficientNet[8]模型作為主干網絡,其憑借獨特的統一縮放復合系數策略,在保持模型性能的同時,又能在一定程度上減少參數量。此外,為了進一步提高分類精度,并盡可能降低模型的參數量,提出一種復合知識蒸餾(CompositeKnowledgeDistillation,CKD)的方法,有效解決了模型性能差和設備存儲有限的問題。該方法為深度學習在骨科影像診斷中的應用提供了可靠的解決方案。
1相關工作(Relatedwork)
針對骨科影像的特殊性,研究人員在預處理階段采用了多種預處理技術,如直方圖均衡化[9]、小波變換[10]、非局部均值去噪[11]等方法,旨在降低圖像中的噪聲水平和改善圖像的質量和視覺效果。自適應直方圖均衡化已經被證明能在增強圖像對比度、亮度的同時,有效應對骨科影像中的變化。
在骨科影像診斷分類方面,有許多研究已經證明CNN(ConvolutionalNeuralNetwork)網絡能夠對骨科影像進行有效的診斷分類[12\|14]。遷移學習可以將一個領域或任務中學到的知識遷移到另一個相關領域或任務中。最初,使用預先訓練的DL(DeepLearning)系統,例如AlexNet[15]、VisualGeometryGroup的DL網絡(VGG16和VGG19)[16]和ResNet50[17],通過SoftMax分類器將所選的射線照片圖像分類為正常和異常類,類似的還有Inception[18]和DenseNet121[19]。然而,傳統的CNN網絡往往存在參數量大、計算復雜、優化困難及任務局限等缺點。EfficientNet是對相對傳統的CNN網絡(如VGG、ResNet、Inception和DenseNet)的一種優化和改進,在平衡深度和寬度方面表現出色,可以通過自動網絡搜索獲得高效結構。
在存儲設備資源有限且分類精度較低的情況下,HINTON等[20]提出使用基于知識蒸餾的方法將復雜的教師模型的知識轉移到簡化的學生模型中,提高了學生模型的性能,并降低了模型的復雜性和計算開銷,使其適用于移動的設備和資源有限的環境中。隨后,研究人員利用特征圖[21]、注意力[22]等方法,實現了多種教師模型知識向學生模型的傳遞。魏淳武等[23]借助知識蒸餾在模型遷移方向上的優勢,將帶有長時期隨訪信息的分類任務轉換為基于領域知識的模型遷移任務;劉明靜[24]采用多個教師輔助模型來進行知識傳遞;李宜儒等[25]利用知識蒸餾算法訓練輕量級學生模型,并引入師生間的注意力機制提高模型性能。然而,學生模型可能過于依賴教師模型的知識,導致在面對與教師模型的訓練數據分布不一致的新數據時的表現較差。有研究者嘗試將學生網絡本身作為教師網絡命名為自我知識蒸餾(Self\|KnowledgeDistillation,SKD)[26]。KANG等[27]結合了神經架構搜索和自蒸餾,以改進學生模型在圖像分類任務中的性能。ZHANG等[28]研究了深度相互學習策略,該策略不需要強大的靜態教師網絡,而是采用一組學生網絡在訓練中相互合作學習。KIM等[29]提出漸進式自蒸餾(ProgressiveSelf\|KnowledgeDistillation,PS\|KD)方法,通過逐漸增大溫度參數,實現了漸進性訓練,提高了模型的泛化能力、適應性和穩定性。
綜上,本文提出了一種復合知識蒸餾(CKD)方法,綜合利用知識蒸餾和漸進式自蒸餾兩者的優勢,可以同時傳遞詳細和抽象的知識,提升模型性能,減少過擬合,并增強模型的適應性。
2算法原理(Algorithmprinciple)
2.1數據增強
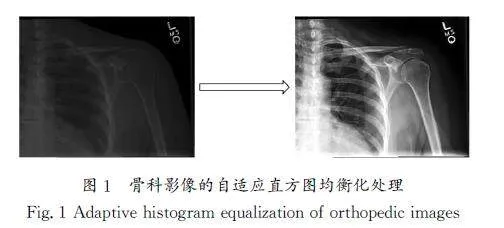
自適應直方圖均衡化是醫學影像預處理的關鍵步驟,目的是增強圖像的對比度,以便于診斷網絡更好地識別細節和結構特征。對輸入圖像的直方圖進行評估、歸一化,然后將輸入圖像轉換為輸出圖像。骨科影像的自適應直方圖均衡化處理如圖1所示。
2.2主干網絡:EfficientNet
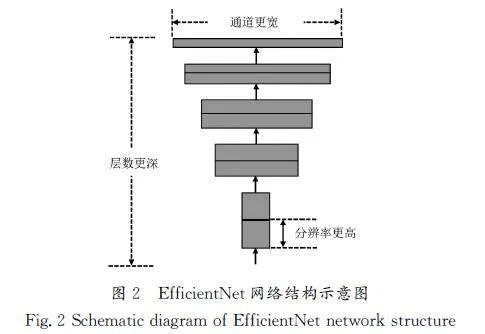
本文在知識蒸餾部分中的教師網絡和學生網絡分別為EfficientNet\|B7和EfficientNet\|B0,漸進式自蒸餾部分中的教師網絡和學生網絡同時為EfficientNet\|B0。EfficientNet網絡通過協同增加網絡的寬度(每層的通道數)、深度(網絡的層數)及輸入圖像的分辨率,實現模型性能的顯著提升,其結構示意圖如圖2所示。
EfficientNet網絡的結構以EfficientNet\|B0為基礎,通過調整分辨率、通道數和層數,形成一系列從EfficientNet\|B1到EfficientNet\|B7的模型變體。該網絡共包含9個階段,Stage1為步長為2的3×3卷積層(帶有批標準化和Swish激活函數),從Stage2到Stage8,采用重復堆疊的MBConv(MobileInvertedBottleneckConvolution)結構,其中每個MBConv后附帶數字1或6,表示倍率因子n。每個MBConv包括Depthwise卷積和1×1卷積,其中k3×3或k5×5表示Depthwise卷積核的大小。Channels表示每個階段輸出特征圖的通道數。Stage9由一個1×1卷積層、平均池化層和全連接層組成。這種網絡設計通過在不同層級上的調整和倍率因子的引入,實現了高效的特征提取和性能優化。
2.3知識蒸餾
知識蒸餾是結合了遷移學習和模型壓縮思想的方法,旨在通過從預先訓練的教師模型向未經訓練的學生模型傳遞暗知識,使得學生模型在特定任務中也能表現出色。教師模型使用SoftMax輸出每個類別的概率Si,如公式(1)所示,而知識蒸餾的重點在于使用logits表示模型對每個類別的概率預測值,如公式(2)所示:
其中:qi是學生網絡學習的軟標簽,zi是每個類別的輸出概率,N是類別數,T是蒸餾溫度的超參數。取T為1時,公式(2)退化為SoftMax,按照logits輸出各類的概率;若T逐漸增大,則輸出結果的分布比較平坦,有助于保持相似的信息。教師網絡和學生網絡的蒸餾損失如公式(3)所示:
其中:Loss是教師網絡和學生網絡的總蒸餾損失,α是教師網絡和學生網絡中二者知識的權重。lossμ和lossν分別表示硬標簽(T=1)和軟標簽(T≠1)的損失,如公式(4)和公式(5)所示:
其中:lossμ表示真實的標簽和學生模型預測的交叉熵,lossν表示教師模型和學生模型的軟標簽預測的相對熵,cj是真實標簽,qj是學生模型的輸出,pj是教師模型的輸出,N是類別數。
2.4漸進式自蒸餾
自蒸餾是指使用學生網絡成為教師網絡本身,并利用其過去的預測在訓練期間具有更多的信息監督,設PSt(x)是來自學生網絡在第t輪的關于x的預測。然后在第t輪的目標可以寫為
其中:x、y分別為輸入和對應的硬標簽,超參數α為教師網絡的權衡系數。
a1be18f90026d386b15bc0f9c5a3efcd在傳統的知識蒸餾(KD)中,教師網絡保持不變,因此α通常在訓練期間被設置為固定值。然而在漸進式自蒸餾PS\|KD中,應該考慮教師網絡的可靠性,這是因為模型通常在訓練的早期階段沒有足夠的數據知識。為此,可以逐漸增加α的值。第t輪的α計算公式如下:
其中:T是訓練的總次數,αT是最后時期的α,在第t輪的目標函數可以寫為
2.5&na1be18f90026d386b15bc0f9c5a3efcdbsp;復合知識蒸餾模型
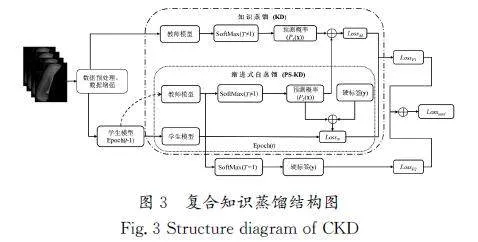
本文融合了知識蒸餾和漸進式自蒸餾的優勢,同時彌補了學生網絡容易過擬合和過度依賴教師網絡的問題,提出了一種復合知識蒸餾的方法。此模型能在進行模型壓縮的同時,盡可能提高模型的性能。將EfficientNet作為數據特征提取器,在知識蒸餾部分,教師網絡為EfficientNet\|B7,學生網絡為EfficientNet\|B0,在漸進式自蒸餾部分,選擇EfficientNet\|B0作為學生網絡,最終將兩個部分的損失之和作為復合蒸餾模型的損失。復合知識蒸餾結構圖如圖3所示。
復合知識蒸餾分為兩個部分,分別為整體框架下的知識蒸餾和局部的漸進式自蒸餾。漸進式自蒸餾部分使用EfficientNet\|B0作為訓練網絡,整體框架下的知識蒸餾網絡的教師網絡為EfficientNet\|B7,其學生網絡來自同一訓練輪次下的漸進式自蒸餾網絡。最終復合知識蒸餾網絡訓練的總損失為Losstotal,分別來自知識蒸餾網絡的蒸餾損失LossF1,以及漸進式自蒸餾網絡的預測與真實硬標簽的損失LossF2。Losstotal的計算公式為
其中:β為二者損失的權衡參數,知識蒸餾網絡的蒸餾損失LossF1由LossM和LossN兩個部分組成,LossM為知識蒸餾網絡在蒸餾溫度為T時的蒸餾損失,LossN為漸進式自蒸餾網絡中Epoch=t且蒸餾溫度T≠1時與硬標簽y之間的損失;LossF2為漸進式自蒸餾網絡中Epoch=t-1且蒸餾溫度T=1時與硬標簽y之間的損失。相應的計算公式如下:
其中:x為輸入圖像,y為圖像的真實硬標簽。PT1j(x)、PT2j(x)分別為教師模型和學生模型在蒸餾溫度為T時的軟標簽預測值,N為類別數,H表示交叉熵。αT為漸進式自蒸餾中軟標簽和硬標簽之間損失的權衡系數,PSt、PSt-1分別表示學生網絡中第t輪、t-1輪的預測結果。
3實驗結果與分析(Experimentresultsandanalysis)
3.1數據集及預處理
MURA(MusculoskeletalRadiographs)是由美國斯坦福大學研究人員創建的,旨在幫助開發自動化算法檢測和診斷骨骼系統肌肉骨骼影像中的關節疾病。MURA數據集包含超過40000張X射線圖像,分布在大約14800個患者上,涵蓋7個主要的關節類別,如肘關節、指關節、肱關節、肩關節、尺關節、掌關節、腕關節,MURA數據集樣本展示如圖4所示。原MURA的數據集共有1560張肱關節圖片,通過隨機水平翻轉、隨機旋轉和高斯模糊技術對數據集進行數據增強,將數據集的數量增加了3倍,達到4680張。為了更有效地評估模型性能,同時重新劃分訓練集和測試集的比例,按照8∶2的比例將數據集劃分為訓練集和測試集,數量分別為3744張和936張。
3.2實驗參數配置
使用Python語言在GPU加速環境中進行實驗,采用Pytorch深度學習框架,電腦配置為Windows11系統、128GB內存、NVIDIARTXGeforce4090顯卡、48GB顯存。表1列出了本實驗的部分參數設置。
3.3實驗評價指標
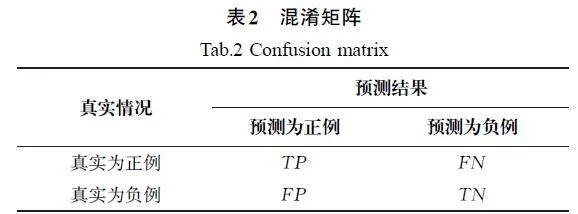
計算機輔助診斷系統的診斷性能通常用準確率(Accuracy)、召回率(Recall)、精確率(Precision)3個指標來衡量,這些指標可通過混淆矩陣計算獲得,混淆矩陣主要用于比較真實情況和預測結果,如表2所示。
對于醫學圖像的ROI(RegionofInterest)區域,可以用陽性或陰性描述病變或非病變,其判斷的正確性可以用真或假表示。準確率、召回率、精確率的公式表示如下:
Accuracy=[(TP+TN)/(TP+TN+FP+FN)]×100%[JZ)][JY](14)
Recall=TPR=[TP/(TP+FN)]×100%[JZ)][JY](15)
Precision=[TP/(TP+FP)]×100%[JZ)][JY](16)
3.4模型對比分析
本文使用4種不同的分類網絡(VGG16、InceptionV3、ResNet50、DenseNet121)驗證在經過數據增強之后的MURA當中肱關節的分類識別效果。訓練過程和訓練超參數在所有網絡上保持完全一致,并保存了每個網絡的最佳模型。接著,使用肱關節數據集對這些模型進行訓練,使用相同的參數設置,包括BatchSize為16、Epoch為50、學習率為0.0001,均使用交叉熵損失函數和Adam優化器。
將本文提出的模型經訓練后,對20%的樣本進行測試,訓練和測試過程的Loss曲線如圖5所示。從圖5中可知,模型經過訓練,在訓練集和測試集上都展現出了較好的學習能力,損失曲線逐漸下降并趨于穩定。盡管在測試集上的損失略高于訓練集,差距僅為0.2,表明模型在未見過的數據上仍然保持了相對良好的泛化能力。為了驗證本文算法的有效性和優越性,將本文所提出的模型與其他基線模型進行對比和消融實驗對比。首先在同一數據集上分別與傳統的基線模型VGG16、InceptionV3、ResNet50、DenseNet121進行對比,表3為本文算法與其他基線模型的算法比較結果。
從表3中的數據可以看出,本文方法性能表現出顯著優勢,準確率達到96.26%、召回率達到95.49%,精確率達到96.94%。準確率比基線模型VGG16、InceptionV3、ResNet50、DenseNet121依次提高了10.77%、8.69%、4.48%、2.93%。
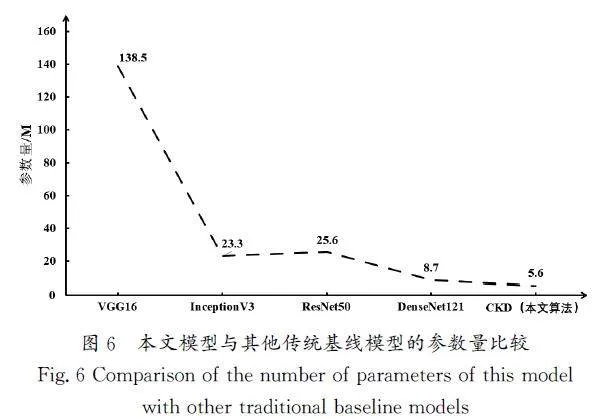
從圖6中可以看出,針對模型參數量而言,VGG16的參數量最大,本文模型參數量僅是它的4.04%,相對于其他模型而言,參數量也較小,這得益于EfficientNet網絡本身及復合知識蒸餾的效果,充分驗證了本文模型的有效性。
上述實驗僅僅對MURA當中的肱關節數據集進行實驗對比,為了更好地驗證所提出模型在其他數據集上的遷移能力和性能,以同樣的方法,對MURA當中的其他類別的數據集進行了訓練和測試。
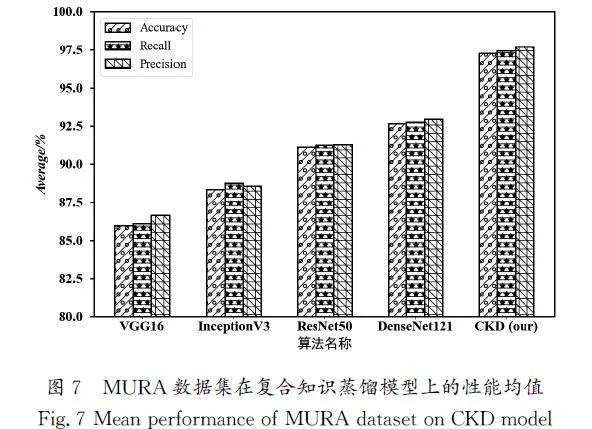
為了全面評估本文模型的性能,將其應用于MURA數據集中的其他多個關節部位,包括指關節、肘關節、腕關節、尺關節、肩關節和掌關節進行訓練和測試,求出每一種數據集的相關測試評價指標的數值。將該模型在每一種數據集上針對相同的評價指標得到的數值做平均,即該模型在不同數據集上針對相同評價指標的測試結果的均值。采用同樣的方法求得VGG16、InceptionV3、ResNet50、DenseNet121在MURA的其他數據集上的均值,如圖7所示,總體性能情況與單一肱關節數據集的測試結果一致,本文模型依然能夠表現出優異的遷移能力和性能。
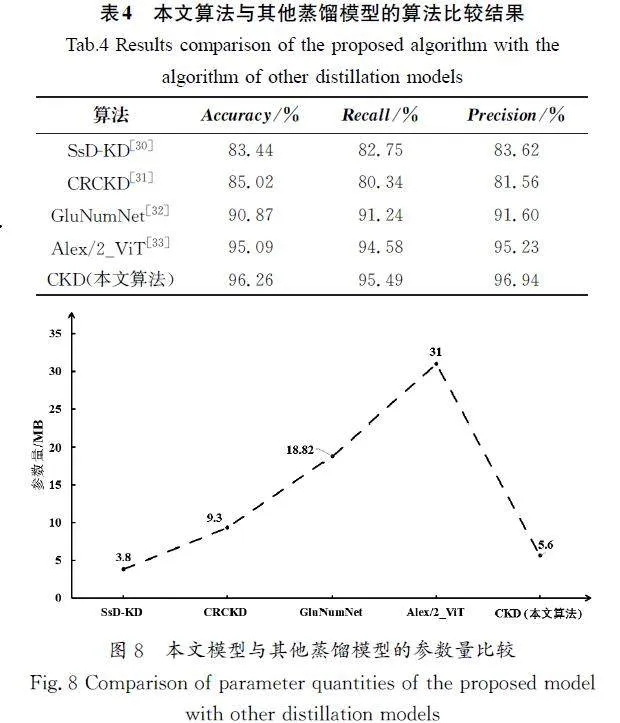
將本文的復合知識蒸餾(CKD)方法與當前其他先進的蒸餾方法在肱關節數據集上進行實驗比較,結果如表4所示。相較于SsD\|KD[30]、CRCKD[31]、GluNumNet[32]、Alex/2_ViT[33],本文算法的準確率、召回率、精確率都具有明顯的提升,其中準確率相較于它們依次提高了15.36%、13.22%、5.93%、1.23%。由圖8可知,與SsD\|KD相比,本文算法的模型參數量增加了約0.5倍;與CRCKD、GluNumNet、Alex/2_ViT相比,本文算法的參數量有明顯的降低,參數量減少了39.78%、70.24%、81.94%,并且在降低模型參數量的同時提升了模型的性能。
3.5消融實驗
為進一步分析各個模塊的作用,分別用EfficientNet\|B0、EfficientNet\|B7、自蒸餾(SKD)、知識蒸餾(KD)以及本文方法復合知識蒸餾(CKD)對同一數據集(肱關節數據集)進行消融實驗,并利用相關評價指標對實驗結果進行對比,結果如表5所示。從表5中的數據可以看出,EfficientNet\|B0是EfficientNet系列中參數量最低的網絡,其準確率達到了較好的水平,結果為85.86%。EfficientNet\|B0通過自蒸餾,得以充分利用單模型訓練,節約了計算的內存和資源。自蒸餾使得學生模型可以從自己的輸出中學習到教師模型的知識,并逐漸提高了自身的性能,準確率也提升至92.74%,從而在資源有限的設備上實現較好的性能,但容易造成過擬合的現象。通過知識蒸餾,本實驗采用的離線蒸餾將訓練好的模型用作測試,并將其遷移至移動設備上,能夠大大節省設備的占用資源,對于自蒸餾而言,知識蒸餾的準確率也提升至93.53%。學生模型在訓練時充分利用了教師模型的知識,提高學生模型的泛化能力,尤其在數據較少的情況下的表現更好,但是存在學生模型過于依賴教師模型的現象。因此,本文提出的復合知識蒸餾方法結合了二者的優勢,并彌補了各自的不足。蒸餾模型的共同點均是利用小模型達到大模型所具有的優勢,從而實現模型壓縮與效能提升的雙重目標。
消融實驗各模型參數量比較如圖9所示,本文提出的復合知識蒸餾方法較Efficient\|Net\|B0、自蒸餾、知識蒸餾的模型參數量略微增加,但其模型性能卻有了明顯的提升,準確率達到了96.26%,較EfficientNet\|B0、自蒸餾、知識蒸餾分別提高了12.11%、3.80%和2.92%。此外,本文提出的復合知識蒸餾方法的模型參數量僅為EfficientNet\|B7的8.48%,但其準確率卻只相差1.16%,模型性能可與之相媲美。
3.6不同的超參數對模型性能的影響
蒸餾模型的性能在很大程度上受到超參數α和蒸餾溫度T的影響,同時本文提出的復合知識蒸餾方法中含有自蒸餾模型,其中采用的是漸進式自蒸餾模型,超參數α是隨著訓練的次數變化而變化的,受αT和Epoch的影響,設置αT為0.8,設置Epoch為50。為了對比不同的超參數對蒸餾模型性能的影響,上述實驗是在α=0.85、T=3的條件下進行測試的。同理,在肱關節數據集上對本文模型進行對比,可以在一定范圍內得出最佳的性能,如表6所示。從表6中的數據可知,隨著α和蒸餾溫度T的不斷增大,其模型的測試準確率大致呈現逐漸上升的趨勢,但也發現,超參數不是越大越好,在蒸餾溫度為7時,蒸餾效果就不如3和5。其中,當蒸餾溫度為5、α為0.85時,本文模型的準確率高達97.13%,與EfficientNet\|B7相媲美。同時,表6中的數據是在有限的參數設定下的結果,要想探索更優的效果,可以采用更加系統的方法進行搜索,如網格搜索法等。
4結論(Conclusion)
針對醫學影像診斷領域因設備存儲有限等導致模型診斷結果不理想的問題,本文提出一種復合知識蒸餾方法。選用EfficientNet作為主干網絡,為了提高模型的性能和減少設備資源占用,引入了知識蒸餾的思想,選用模型較大、性能優的EfficientNet\|B7作為教師模型,選用模型較小、性能優的EfficientNet\|B0作為學生模型。此外,研究人員對學生模型采用了漸進式自蒸餾方法,旨在更好地挖掘數據特征。本文綜合了二者的優勢,知識蒸餾使得復雜模型的精華能夠被傳遞給學生模型,使得簡單模型能夠在保持較低計算資源消耗的情況下,達到接近復雜模型的性能。漸進式自蒸餾則通過引入“偽標簽”進行自我訓練,不斷地提升模型在未標記數據上的表現,從而加強了其泛化能力。然而,本文方法也存在一些缺陷,主要是本文模型的性能與超參數(T、α、αT等)的設置有緊密聯系,但在選擇和調整超參數時方法相對局限,因此未來工作應重點解決如何通過更加簡單有效的方法調整超參數以獲得最佳性能。此外,還可以探索更好的模型輕量化方法,不斷提升模型的性能和降低模型的復雜度。
參考文獻(References)
[1]趙曉陽,許樹林,潘為領,等.公共人工智能平臺在膝關節骨性關節炎分期中的應用[J].實用臨床醫藥雜志,2022,26(8):22\|26.
[2]JOSHID,SINGHTP.AsurveyoffracturedetectiontechniquesinboneX\|rayimages[J].Artificialintelligencereview,2020,53(6):4475\|4517.
[3]HGEM,WHLINGT,NOWAKW.Aprimerformodelselection:thedecisiveroleofmodelcomplexity[J].Waterresourcesresearch,2018,54(3):1688\|1715.
[4]LISL,ZHANGXJ.ResearchonorthopedicauxiliaryclassificationandpredictionmodelbasedonXGBoostalgorithm[J].Neuralcomputingandapplications,2020,32(7):1971\|1979.
[5]SEIBOLDM,MAURERS,HOCHA,etal.Real\|timeacousticsensingandartificialintelligenceforerrorpreventioninorthopedicsurgery[J].Scientificreports,2021,11(1):3993.
[6]DIPALMAJ,SURIAWINATAAA,TAFELJ,etal.Resolution\|baseddistillationforefficienthistologyimageclassification[J].Artificialintelligenceinmedicine,2021,119:102136.
[7]PIZERSM,AMBURNEP,AUSTINJD,etal.Adaptivehistogramequalizationanditsvariations[J].Computervision,graphics,andimageprocessing,1987,39(3):355\|368.
[8]TANMX,LEQV.EfficientNet:Rethinkingmodelscalingforconvolutionalneuralnetworks[EB/OL].(2020\|09\|11)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1905.11946.
[9]WANGJJ,LUOJW,HOUNYEAH,etal.Adecoupledgenerativeadversarialnetworkforanteriorcruciateligamenttearlocalizationandquantification[J].Neuralcomputingandapplications,2023,35(26):19351\|19364.
[10]RINISHAB,SULOCHANAW,KUMARAW.Awavelettransformandneuralnetworkbasedsegmentationclassificationsystemforbonefracturedetection[J].Optik,2021,236:166687.
[11]SEZERA,SEZERHB.Deepconvolutionalneuralnetwork\|basedautomaticclassificationofneonatalhipultrasoundimages:anoveldataaugmentationapproachwithspecklenoisereduction[J].Ultrasoundinmedicine&biology,2020,46(3):735\|749.
[12]BIENN,RAJPURKARP,BALLRL,etal.Deep\|learning\|assisteddiagnosisforkneemagneticresonanceimaging:developmentandretrospectivevalidationofMRNet[J].PLoSmedicine,2018,15(11):e1002699.
[13]LINL,DOUQ,JINYM,etal.DeeplearningforautomatedcontouringofprimarytumorvolumesbyMRIfornasopharyngealcarcinoma[J].Radiology,2019,291(3):677\|686.
[14]AKCAYS,KUNDEGORSKIME,WILLCOCKSCG,etal.UsingdeepconvolutionalneuralnetworkarchitecturesforobjectclassificationanddetectionwithinX\|raybaggagesecurityimagery[J].IEEEtransactionsoninformationforensicsandsecurity,2018,13(9):2203\|2215.
[15]KRIZHEVSKYA,SUTSKEVERI,HINTONGE.ImageNetclassificationwithdeepconvolutionalneuralnetworks[J].CommunicationsoftheACM,2017,60(6):84\|90.
[16]SIMONYANK,ZISSERMANA.Verydeepconvolutionalnetworksforlarge\|scaleimagerecognition[EB/OL].(2015\|04\|10)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1409.1556.
[17]HEKM,ZHANGXY,RENSQ,etal.Deepresidual&nbdRHaOJtq8GNN55+t29kdY4b8gAUIKn+2z1cHgDXawM=bsp;learningforimagerecognition[C]∥IEEE.ProceedingsoftheIEEE:2016IEEEConferenceonComputerVisionandPatternRecognition.Piscataway:IEEE,2016:770\|778.
[18]SZEGEDYC,LIUW,JIAYQ,etal.Goingdeeperwithconvolutions[C]∥IEEE.ProceedingsoftheIEEE:2015IEEEConferenceonComputerVisionandPatternRecognition.Piscataway:IEEE,2015:1\|9.
[19]HUANGG,LIUZ,VANDML,etal.Densely?;connectedconvolutionalnetworks[C]∥IEEE.ProceedingsoftheIEEE:2017IEEEConferenceonComputerVisionandPatternRecognition.Piscataway:IEEE,2017:2261\|2269.
[20]HINTONG,VINYALSO,DEANJ.Distillingtheknowledgeinaneuralnetwork[EB/OL].(2015\|03\|09)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1503.02531.
[21]ROMEROA,BALLASN,KAHOUSE,etal.Fitnets:Hintsforthindeepnets[EB/OL].(2015\|03\|27)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1412.6550.
[22]ZAGORUYKOS,KOMODAKISN.Payingmoreattentiontoattention:Improvingtheperformanceofconvolutionalneuralnetworksviaattentiontransfer[EB/OL].(2017\|02\|12)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1612.03928.
[23]魏淳武,趙涓涓,唐笑先,等.基于多時期蒸餾網絡的隨訪數據知識提取方法[J].計算機應用,2021,41(10):2871\|2878.
[24]劉明靜.基于多教師知識蒸餾改進策略的醫學圖像分類方法研究[D].天津:天津大學,2020.
[25][JP3]李宜儒,羅健旭.一種基于師生間注意力的AD診斷模型[J].華東理工大學學報(自然科學版),2023,49(4):583\|588.
[26]HAHNS,CHOIH.Self\|knowledgedistillationinnaturallanguageprocessing[EB/OL].(2019\|08\|02)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1908.01851.
[27]KANGM,MUNJ,HANB.Towardsoracleknowledgedistillationwithneuralarchitecturesearch[J].ProceedingsoftheAAAIconferenceonartificialintelligence,2020,34(4):4404\|4411.
[28]ZHANGHB,LIANGWN,LICX,etal.DCML:deepcontrastivemutuallearningforCOVID\|19recognition[J].Biomedicalsignalprocessingandcontrol,2022,77:103770.
[29]KIMK,JIB,YOOND,etal.Self\|knowledgedistillationwithprogressiverefinementoftargets[C]∥IEEE.ProceedingsoftheIEEE:2021IEEE/CVFInternationalConferenceonComputerVision.Piscataway:IEEE,2021:6547\|6556.
[30]WANGYW,WANGYH,CAIJY,etal.SSD\|KD:aself\|superviseddiverseknowledgedistillationmethodforlightweightskinlesionclassificationusingdermoscopicimages[J].Medicalimageanalysis,2023,84:102693.
[31]XINGX,HOUY,LIH,etal.Categoricalrelationpreservingcontrastiveknowledgedistillationformedicalimageclassification[C]∥Springer.ProceedingsoftheSpringer:MedicalImageComputingandComputerAssistedIntervention\|MICCAI2021:24thInternationalConference,Strasbourg,France,September27\|October1,2021,Proceedings,PartV.Piscataway:SpringerInternationalPublishing,2021:163\|173.
[32]LIGY,WANGXH.Multi\|branchlightweightresidualnetworksforhandwrittencharacterrecognition[J].Computerengineeringandapplications,2023,59(5):115\|121.
[33]LENGB,LENGM,GEMF,etal.Knowledgedistillation\|baseddeeplearningclassificationnetworkforperipheralbloodleukocytes[J].Biomedicalsignalprocessingandcontrol,2022,75:103590.
作者簡介:
王烤(1998\|),男,碩士生。研究領域:控制理論與應用,深度學習,圖像處理。
吳欽木(1975\|),男,博士,教授。研究領域:控制理論與應用,電動汽車傳動控制,電驅動系統效率優化和故障診斷,深度學習。
