基于決策樹算法的電子通信網絡數據流冗余消除方法
2024-11-12 00:00:00宋堅
無線互聯科技 2024年19期




摘要:現有的消除方法在消除數據流冗余數據時,空間縮減比例過低,導致消除效果不理想。針對這一問題,文章引入決策樹算法,設計了新的電子通信網絡數據流冗余消除方法。在對電子通信網絡數據進行集成處理后,文章利用決策樹算法,對電子通信網絡數據流進行分類。然后,結合相同類別數據的相似度計算結果,文章對數據流中的冗余數據進行了迭代消除。實驗表明:應用新方法后,電子通信網絡數據流空間縮減比例顯著提升,說明新方法的消除效果更理想。
關鍵詞:決策樹算法;冗余消除;數據流;電子通信
中圖分類號:TP536.5 文獻標志碼:A
0 引言
當前,電子通信網絡中的數據流量呈爆炸性增長。在這一背景下,數據流的冗余問題越發凸顯,它不僅占據了大量的存儲空間和傳輸帶寬,還增加了數據處理的復雜性和成本。因此,有效地消除電子通信網絡中的數據流冗余,成了當前研究的重要課題。
余錦河等[1]利用人工神經網絡算法,對用電信息傳輸冗余量消除進行了仿真。該方法在一定程度上能夠減少數據冗余,提高數據傳輸和處理的效率。然而,該方法基于固定算法模型,難以適應復雜多變的電子通信網絡環境。特別是在面對海量的、多樣化的數據時,難以準確地識別和處理數據流中的冗余數據。張淑清等[2]基于哈希計算,提出了一種大數據冗余消除算法。該方法雖然能有效消除冗余數據并提高數據可用性,但哈希計算對噪聲和缺失數據非常敏感,這可能導致在客戶終端數據預處理階段出現不穩定的情況。
決策樹算法作為一種典型的分類方法,具有直觀易懂、易于實現和擴展性強的特點。決策樹算法可以自動地學習數據中的特征和規律,從而實現對數據流中冗余數據的準確識別和處理。因此,為了解決上述問題,筆者提出了一種基于決策樹算法的電子通信網絡數據流冗余消除方法。
1 電子通信網絡數據集成與預處理
為便于后續的統一管理和分析,筆者針對電子通信網絡數據開展集成處理。在這一過程中,筆者采用數據倉庫法來高效地集成這些數據[3]。筆者通過“Extract”功能從電子通信網絡中抽取數據,之后,通過“Transform”功能對抽取出的數據進行格式轉換和清洗,確保數據的一致性和準確性,再通過“Load”功能將數據加載到數據倉庫中[4]。
為減少隨后的多余數據尋找和排除的困難,對集成后的電子通信網絡數據進行預處理顯得尤為重要。預處理一般可分為特征類別與數值類別2種。
(1)字符類數據通常包括文本、標簽、描述等,須要對這些數據進行清mX7PW+wa59e0EhlpI/teXg==洗、去重、標準化等操作[5]。筆者使用正則表達式去除文本中的無關字符或特殊符號后,將文本轉換為統一的格式。
(2)在數值類數據的預處理階段,筆者對這些數據進行缺失值填充、異常值檢測與處理、數據標準化等操作。對于缺失值,可以使用均值、中位數或插值法進行填充;對于異常值,可以使用統計方法或機器學習算法進行檢測和處理[6];數據標準化則可以通過公式將數據轉換為統一尺度,便于后續分析。
對于缺失值的填補,其計算公式如式(1)所示。
ai=(a1+a2+…+an)/n(1)
其中,ai表示缺失數據;a1、a2、…、an表示序列中除缺失值以外的所有值;n表示缺失值所在序列長度。經過標準化處理后,使得不同特征之間的比較更加公平和有效。
2 基于決策樹算法的電子通信網絡數據流分類
在處理電子通信網絡數據流分類和冗余消除時,直接計算所有數據之間的相似度往往會導致巨大的計算量和較低的工作效率。為了優化這一過程,筆者采用決策樹方法對來自電信網絡的海量數據進行分類,以減少后續去冗工作的復雜性與困難。
筆者選取了ID3決策樹算法進行聚類分析。ID3算法會遍歷數據集中的所有屬性,計算每個屬性作為分裂點時的信息增益[7]。信息增益反映了按照某個屬性進行分裂后,數據集純度提升的程度[8],其計算公式如式(2)所示。
G(S,A)=En(S)-∑VValues(A)|Sv||S|En(Sv)(2)
其中,G(S,A)表示信息增益;S表示待分裂的數據集;A表示候選分裂屬性;Values(A)表示A屬性的所有可能取值;Sv表示數據集S中屬性A取值為v的樣本子集;En(S)表示數據集S的熵。在公式中,En(S)用于度量數據集的不純度,計算公式如式(3)所示。
En(S)=-∑mi=1pilog2pi(3)
其中,m表示數據集中類別數量;pi表示第i個類別在數據集中出現的概率。通過計算信息增益,ID3決策樹算法能夠選擇出最佳分裂屬性,據此構建決策樹的分裂規則[9]。以此,可以先將數據流中的數據按照這些規則進行分類,然后在分類后的數據集中進行冗余消除,從而大大提高工作效率和準確性。
結合上述ID3算法,建立決策樹,具體步驟為:
第1步,設定初始信息增益閾值ε;
第2步,假設有m個訓練樣本,每個樣本包含n個屬性(特征)和1個類別標簽;
第3步,初始化一個節點作為根節點,準備開始構建決策樹;
第4步,如果根節點下的所有樣本都屬于同一類別C,算法運算結束后,把根節點標記成葉子,然后把它的分類設定為C;
第5步,遍歷樣本的n個屬性,對于每個屬性A,根據公式(2),計算其信息增益G(S,A),將信息增益最大的屬性選為當前節點的拆分屬性,其中,S是樣本集;
第6步,如果當前節點是根節點且選定的分裂屬性的信息增益小于閾值ε,則返回第3步。否則,繼續下一步;
第7步,對所選分割屬性的每一個可能的取值v,從當前節點延伸出相應的分支。將當前節點下的樣本按照分裂屬性的取值劃分到不同的分支中;
第8步,對于每個非樹葉節點,重復第3步至第7步,遞歸地構建其子樹。當所有節點都被標記為樹葉節點或達到其他停止條件時,算法終止,得到一棵完整的決策樹[10]。
第19期2024年10月無線互聯科技·電子通信 No.19October,2024
第19期2024年10月無線互聯科技·電子通信 No.19October,2024
利用構建的決策樹,完成對電子通信網絡數據流的分類處理。
3 數據流冗余數據迭代消除
結合決策樹分類結果,計算相同類別中數據的相似度,根據計算結果實現對冗余數據的迭代消除。類間相似度的計算公式為:
S(i,j)=φ∑mi,j=1log2(Yki-Ykj)(4)
其中,S(i,j)表示數據i和數據j之間的相似度;φ表示計算因子;Yki、Ykj表示在k類樣本中數據i、j的哈希值。將得到的計算結果S(i,j)與判別閾值W進行對比,判斷數據流中的數據是否為冗余數據:若S(i,j)>W,則認為該數據為冗余數據,將其消除;反之,若S(i,j)≤W,則認為該數據不是冗余數據。
4 對比實驗
為了驗證上述方法的實際應用效果,筆者設計了如下實驗。
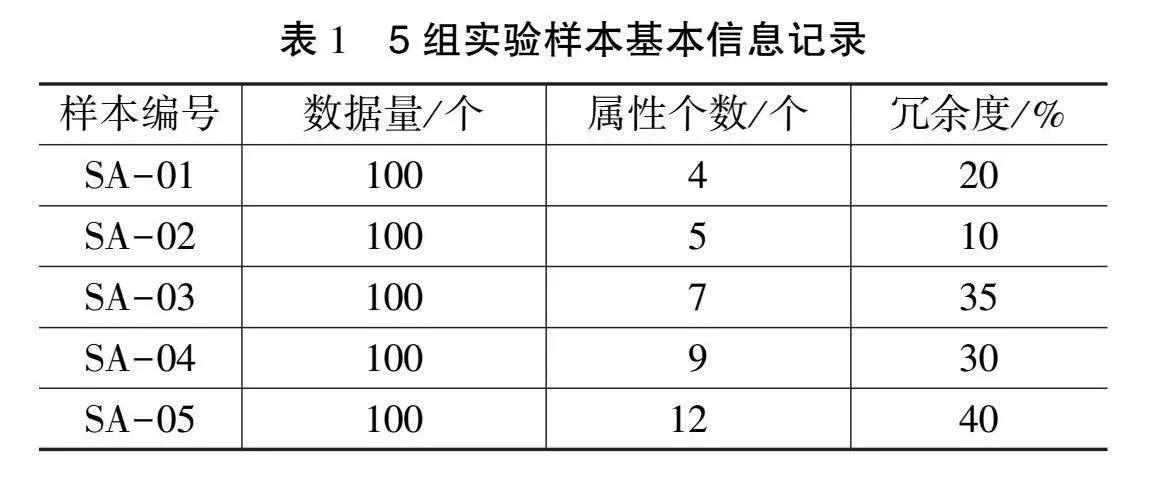
將余錦河等[1]方法設置為對照A組,將張淑清等[2]方法設置為對照B組,將文章上述基于決策樹算法的方法設置為實驗組,利用3種消除方法,在相同實驗環境中對電子通信網絡數據流的冗余進行消除。通過對比消除效果,實現對3種方法應用性能的對比。按照表1所示,設置5組實驗樣本。
從表1中的內容可以看出,5組樣本數據量相同,均為100個,屬性和冗余度均不相同。在利用3種方法完成冗余消除后,將空間縮減比例作為評價冗余消除效果的量化指標,空間縮減比例的計算如式(5)所示。
L=e/E(5)
其中,L表示空間縮減比例;e表示刪除的冗余部分數據量;E表示樣本的數據總量。空間縮減比例越高,說明冗余消除的效果越好,即消除的冗余數據越多,節省的存儲空間或數據體積越大。
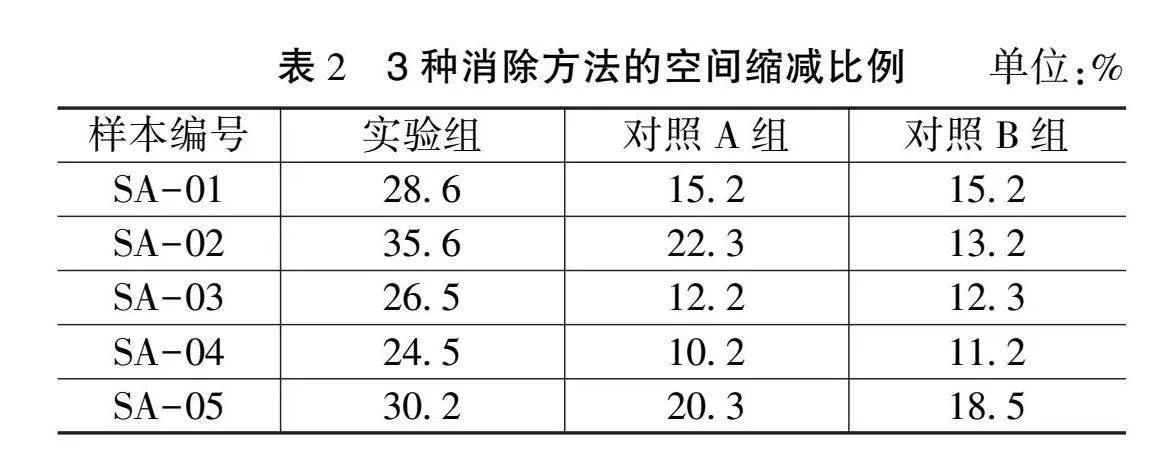
3種方法的空間縮減比例如表2所示。
在對比的5組數據樣本中,實驗組方法展現出了顯著的優勢,其空間縮減比例在每組數據中都達到了最高水平,這一表現不僅證明了該方法的有效性,更凸顯了其在處理電子通信網絡數據流冗余方面的優越性。實驗組的空間縮減比例的具體取值穩定地落在 24.0%至36.0%的范圍內。這一區間不僅體現了該方法在冗余消除上的穩定性能,也顯示了其對于不同類型或規模的數據流都能保持較高的處理效率。而對照A組和對照B組的空間縮減比例均位于10.0%至23.0%的范圍內,明顯低于實驗組。這一對比結果不僅進一步強調了實驗組方法的優勢,也反映出其他2種對照方法在冗余消除效果上的局限性。
5 結語
筆者提出的基于決策樹算法的電子通信網絡數據流冗余消除方法,為電子通信網絡中的數據流冗余問題提供了新的解決方案。該方法不僅能夠準確地識別和處理數據流中的冗余數據,還能夠適應不同的網絡環境和數據類型,具有廣闊的應用前景。
隨著電子通信網絡的不斷發展和數據量的不斷增長,數據流冗余消除將面臨更加復雜和嚴峻的挑戰。因此,須要進一步研究和探索更加高效、準確和智能的數據流冗余消除方法,為電子通信網絡的發展提供有力的支持。同時,也須要關注數據流冗余消除技術的安全性和隱私保護問題,確保數據流在傳輸和處理過程中的安全性和隱私性。
參考文獻
[1]余錦河,劉虎,張才俊.基于人工神經網絡算法的用電信息傳輸冗余量消除仿真[J].電子設計工程,2023(23):54-57,62.
[2]張淑清.基于哈希計算的大數據冗余消除算法設計[J].微型電腦應用,2021(12):68-70.
[3]張莉,丁毛毛,李瑋,等.基于決策樹算法的客服終端冗余數據迭代消除方法[J].計算技術與自動化,2022(4):118-122.
[4]張翼英,王德龍,渠慧穎,等.面向不平衡數據和特征冗余的網絡入侵檢測[J].天津科技大學學報,2023(5):57-63.
[5]郭勤,曾輝,李慧玲.基于數據驅動的光纖網絡冗余節點狀態調度方法[J].激光雜志,2023(10):162-166.
[6]謝絨娜,范曉楠,李蘇浙,等.基于標簽的數據流轉控制策略冗余與沖突檢測方法[J].網絡與信息安全學報,2023(5):21-32.
[7]張霖,張媛媛,劉星.一種最小化網絡能耗的冗余消除路由策略[J].首都師范大學學報(自然科學版),2023(5):37-40.
[8]陳潤星,劉杰,李龍杰,等.基于HWD32F429的主從冗余數據記錄系統的設計[J].電腦知識與技術,2024(2):43-46.
[9]高文昀,戴勝,涂麗萍,等.基于冗余數據消除的不平衡樣本加權支持向量機方法研究[J].長江信息通信,2022(1):46-50.
[10]俞立平,舒光美.一種期刊評價指標數據冗余消除法:獨立信息測度[J].現代情報,2023(5):114-122,167.
(編輯 王永超)
Electronic communication network based on decision tree algorithm
SONG Jian
(Fuzhou Polytechnic, Fuzhou 350108, China)
Abstract: The existing elimination methods have a low spatial reduction ratio when eliminating redundant data in data streams, resulting in unsatisfactory elimination effects. In response to this issue, the author introduces the decision tree algorithm and designs a new method for eliminating data stream redundancy in electronic communication networks. After integrating and processing electronic communication network data, the author uses decision tree algorithm to classify the electronic communication network data flow. Then, based on the similarity calculation results of data in the same category, the author iteratively eliminates redundant data in the data stream. The experiment shows that after applying the new method, the reduction ratio of data flow space in electronic communication networks is significantly improved, indicating that the elimination effect of the new method is more ideal.
Key words: decision tree algorithm; redundancy elimination; data flow; electronic communication
