基于OCR技術的檔案智能化收集方法研究
2024-11-12 00:00:00張婷琳陳祥本丁曄張勇
無線互聯科技 2024年19期

摘要:為實現檔案信息的智能化管理,文章提出了一種輕量化的端到端檔案智能化收集系統。首先采用輕量化的目標檢測神經網絡PP-PicoDet作為布局檢測器,用于對檔案材料的版面分析;然后采用SLANet深度學習神經網絡進行表格的結構化識別;最后使用開源的Paddle OCR引擎進行文本識別。系統對表格識別的準確度達到75.8%,印刷體文本識別準確度達到98.3%,總推理時間少于0.85 s。該系統為實現端到端的檔案資料智能化收集,提高檔案資料整理的效率提出了一種有效解決方案。
關鍵詞:檔案智能化收集;深度學習;光學字符識別;中文表格;手寫體識別
中圖分類號:TP391 文獻標志碼:A
0 引言
目前許多存放在檔案館的歷史文檔都是以手寫形式存在,只有近十幾年來的資料才開始以圖片的形式保存。紙質檔案在存儲中存在許多弊端,如易損壞、物理存儲空間需求大、檢索效率低等。隨著信息技術的不斷發展,大量的紙質檔案資料須要進行數字化整理以適應數字化時代的需求。傳統的人工數據錄入方式效率低且成本高昂,而光學字符識別(OCR)技術能夠將圖像中的文字進行自動識別并轉換為可編輯的數字文本,更加方便快捷。自動進行文本分析、信息提取和挖掘將極大地提高檔案資料整理的效率,有助于建立完善的檔案信息管理系統,提升信息化水平。
OCR技術在識別印刷體和手寫體文本方面已經取得了顯著進展,但仍然存在一些問題:低分辨率圖像中,字體大小、扭曲、陰影等因素可能導致字符識別錯誤;手寫文本質量差異大,使得OCR識別難度增加;無法處理復雜的文檔格式和布局,容易導致識別錯誤或丟失重要信息等。這些問題在檔案整理中都可能出現。因此,改進當前的OCR技術以提高識別準確度和效率,是實aa4285e4d6ff36c151a265a315bd3897現檔案信息化管理的關鍵問題。
1 光學字符識別技術
OCR技術是一種將圖像中的文字轉換為可編輯文本的技術。在數字化時代,它在信息處理、文檔管理和自動化任務中發揮著至關重要的作用。傳統的OCR方法主要依賴特征工程和模式匹配,效果容易受到圖像質量、字體和大小等因素的影響。而基于深度學習的OCR方法不僅能自動學習圖像中的文字特征,還具有更好的魯棒性和準確性[1]。OCR技術的工作流程通常包括以下幾個關鍵步驟。
1.1 圖像預處理
圖像預處理是對輸入圖像進行預處理,包括去除噪聲、調整圖像尺寸、灰度化等操作,以提高后續識別步驟的準確性。
1.2 文本檢測
文本檢測是在預處理后的圖像中檢測出文本的位置和邊界框。常用的文本檢測算法可分為基于回歸的算法、基于分割的算法和二者結合的方法。基于回歸的算法改進自一般的目標檢測算法,在識別規則形狀的文本上表現良好,如TextBoxes、CTPN和EAST等。基于分割的算法,如PSENet和DBNet,借助Mask-RCNN目標實例分割框架,在不同場景文本檢測中展現出更好的效果。但這些算法的后處理復雜,速度較慢。
1.3 文本識別
文本識別是在文本檢測切割出的文本區域中識別出文本內容。對于印刷體這類排版規則的文本,常采用基于CTC的算法和基于Sequence2Sequence的算法。對于手寫體和場景文本等存在彎曲、覆蓋和模糊的不規則文本,會添加校正模塊或使用基于注意力機制的方法關注序列間的相關性,其中Transformer算法的各種變體取得了較好的效果。
1.4 后處理
后處理是對識別結果進行后處理,包括糾正識別錯誤、去除不必要的字符等,以提高最終的識別準確性。
傳統的紙質檔案資料以紙張作為載體,通過拍照、掃描等方式將其轉換為電子圖片,然后使用OCR技術實現對紙質檔案的自動化信息提取。對于清晰、標準字體的印刷體文本,當前技術通常能夠實現高準確率的識別。然而,中文手寫體識別由于書寫個體差異大和中文結構復雜,一直是OCR技術中的難題之一。表格數據的識別涉及結構化信息的提取,包括表格的行列識別和單元格內容的識別。相比于普通文本,表格數據的識別需要更復雜的算法和處理步驟。因此,中文表格與手寫體的識別是基于OCR技術實現檔案資料智能化管理的最大挑戰。
2 基于OCR技術的檔案智能化收集方法
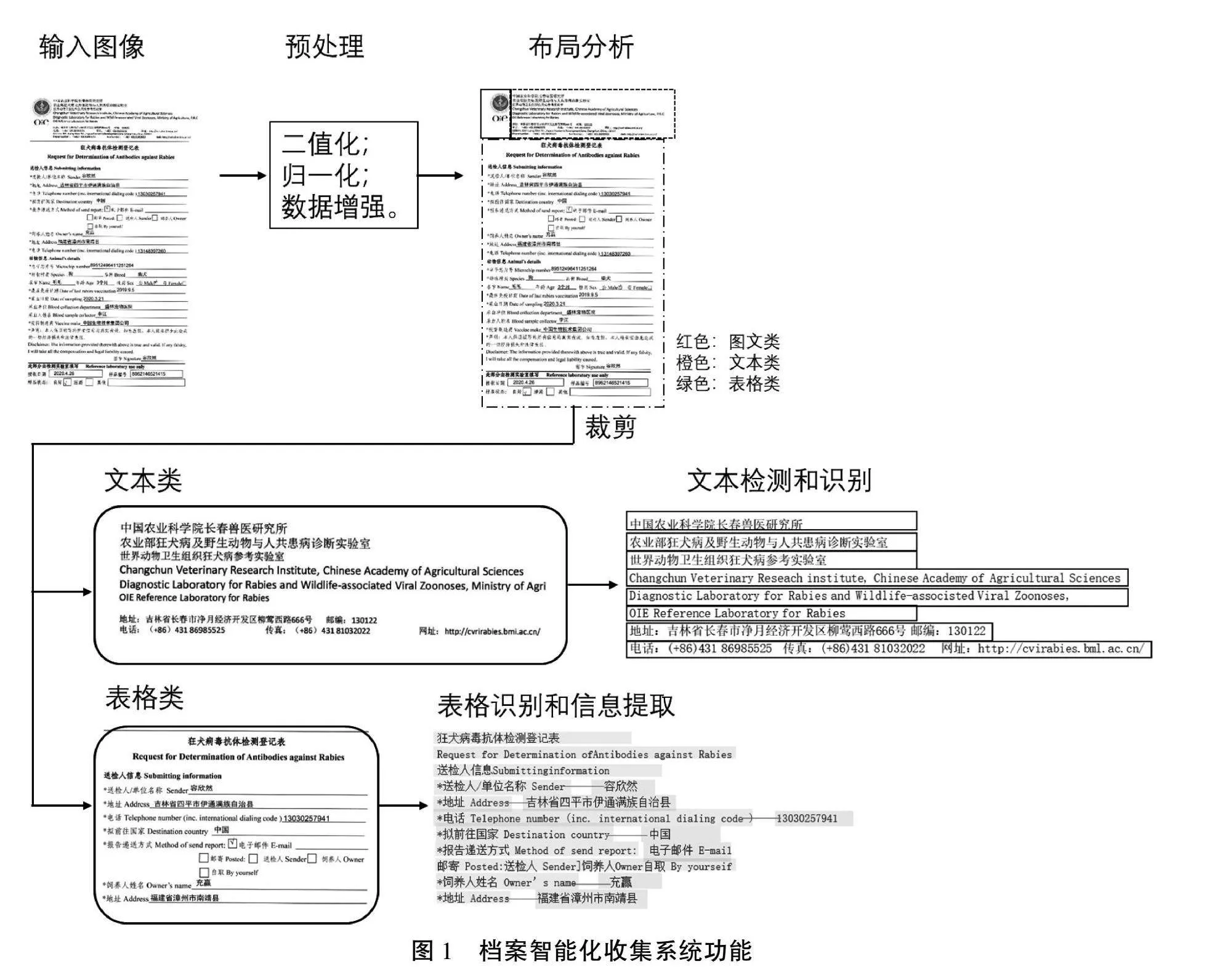
本節主要介紹對檔案資料中常見的印刷體、表格和手寫體進行智能化識別的OCR技術。通過與常見的OCR方法的比較,選擇識別準確率高且輕量化的網絡模型,實現端到端的檔案智能化收集。整個端到端系統功能如圖1所示。
2.1 預處理
首先通過拍照、掃描等方式將紙質檔案資料轉換為.jpg格式的電子圖片,并將圖片調整到統一大小(800×608像素)。由于本文重點關注檔案中文字信息的提取,因此使用自適應閾值算法對圖片進行二值化和歸一化處理,將其轉換為黑白圖像,從而更有效地將文本與背景分離,便于后續的文本檢測和識別。采集圖像時可能會出現模糊、扭曲、陰影等問題,也會遇到多種多樣的手寫文本場景。為了提高模型的魯棒性和泛化性能,須要進行數據增強。通過隨機旋轉、縮放、彈性變換、模糊、添加高斯噪聲和裁剪等方法,可以增加樣本的數量和多樣性。本文使用Python中的OpenCV庫函數實現數據增強。
2.2 布局分析
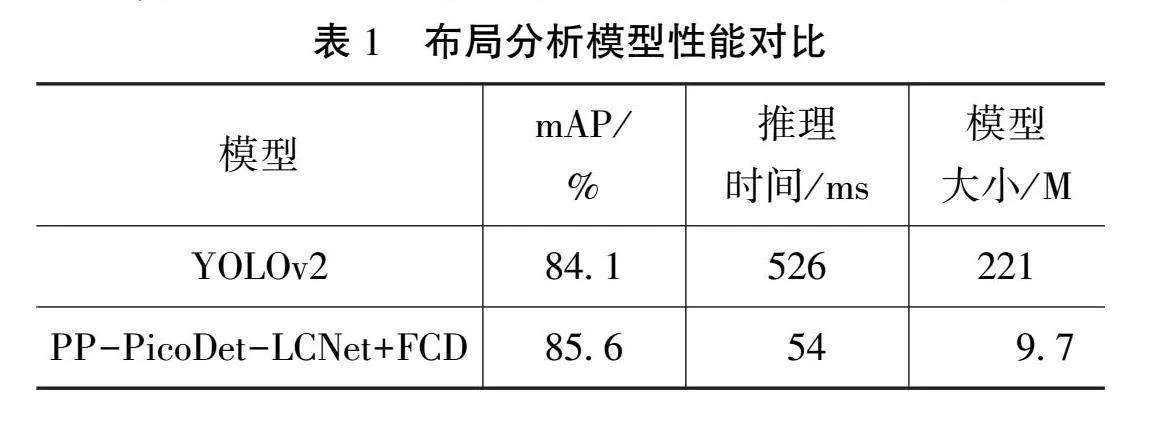
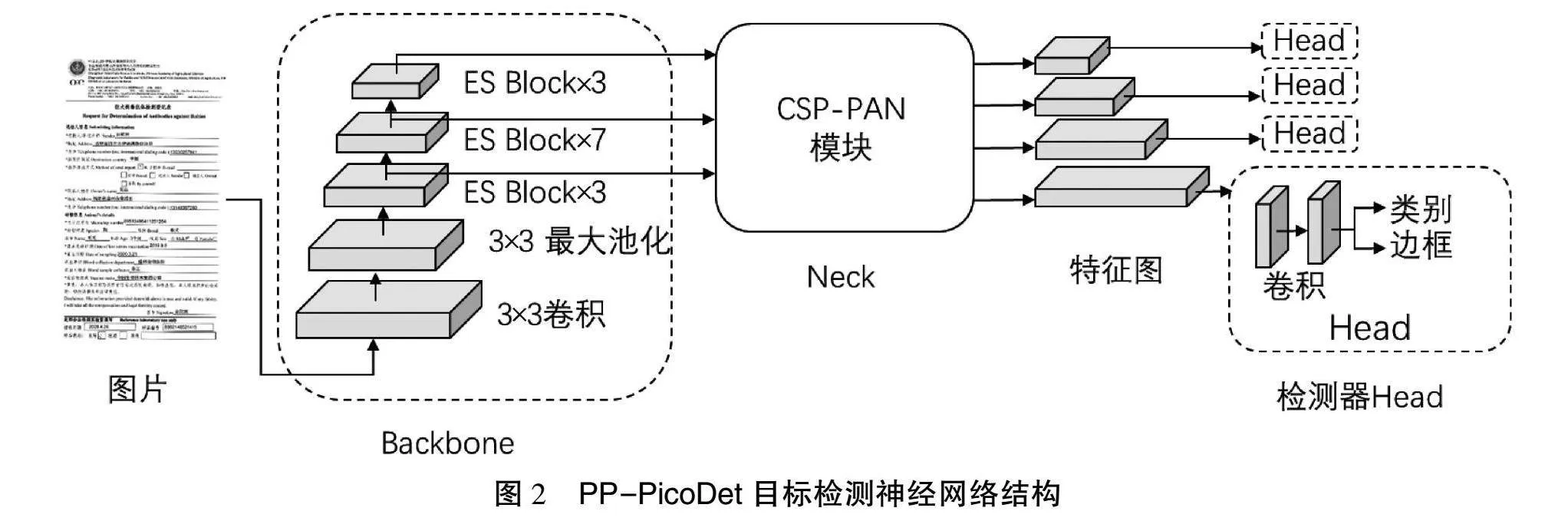
布局分析模塊將每個檔案文檔頁面劃分為不同的內容區域,包括純文本、標題、表格、圖片和列表等,便于后續對不同區域的識別,網絡結構如圖2所示。該模塊采用輕量化的目標檢測神經網絡PP-PicoDet作為布局檢測器[2-3]。使用CSP-PAN模塊作為Neck層,采用SimOTA動態標簽分配策略并以PP-LCNet為主干網絡Backbone層。通過一次性神經結構搜索(One-shot Neural Architecture Search, One-shot NAS)算法,自動找到目標檢測的最優結構。與市面上流行的YOLO目標檢測算法相比,PP-PicoDet具有輕量化和運行速度快的優勢[2-3]。在CPU上運行時,它可以達到與PP-YOLOv2相當的檢測精度,但運行速度快11倍。為進一步壓縮目標檢測模塊,并使模型更輕量化,使用知識蒸餾算法中的特征一致性蒸餾(Feature Consistency Distillation,FCD)算法[4],同時考慮局部和全局特征圖。局部蒸餾分離圖像的前景和背景,使學生網絡專注于教師網絡的關鍵像素和通道;全局蒸餾重建不同像素之間的關系,將其從教師網絡傳遞給學生網絡,以補償局部蒸餾中缺失的全局信息。
2.3 表格識別
在檔案文檔頁面中劃分的表格區域,需要對表格結構和單元格坐標進行預測,以進一步識別表格中的內容和結構化信息。為此,采用輕量化的SLANet(Structure Location Alignment Network)深度學習神經網絡進行表格的結構化識別[5]。具體來說,SLANet的Backbone層使用基于MKLDNN加速策略的輕量化卷積神經網絡PP-LCNet,其預訓練權重通過SSLD(Simple Semi-supervised Label Distillation)知識蒸餾算法在ImageNet數據集上訓練得到,以提高模型精度。Neck層采用CSP-PAN模塊,對Backbone層提取的特征進行多層融合,輸出通道為96。PAN 結構用于獲取多層特征圖,CSP 網絡則進行相鄰特征圖間的特征連接和融合,同時采用深度可分離卷積策略以降低計算代價。Head層為特征解碼模塊SLAHead,用于對齊表格的結構與位置信息,輸出表格的結構token和全部單元格的坐標。在結構序列中,每個位置的預測是一個多分類任務,損失函數采用交叉熵。每個單元格的坐標預測是一個回歸任務,損失函數則采用smooth L1 函數。
2.4 文本識別
對檔案文檔頁面中的純文本區域和表格中的文本區域,系統使用開源的Paddle OCR引擎進行文本識別。通過比較2種常用的OCR引擎Paddle OCR和Tesseract OCR,發現PaddleOCR提供了豐富的預訓練模型,可以進行遷移學習,而Tesseract OCR需要單獨訓練模型。此外,PaddleOCR的識別精度更高且更輕量化。因此,本文選擇Paddle OCR中的PP-OCRv3超輕量中文識別模型進行文本識別。PP-OCRv3模型引入了SVTR-LCNet文本識別網絡,融合了基于Transformer的SVTR算法和基于卷積神經網絡的輕量化神經網絡PP-LCNet[6]。該模型使用TextConAug數據增強策略、注意力引導的CTC(Connectionist Temporal Classification)訓練方法、自監督的預訓練模型TextRotNet以及U-DML和UIM技術,可以有效地提高模型效率和識別精度。
2.5 信息提取
信息提取模塊主要用于理解和識別文檔中的具體信息或信息之間的關系,包括語義實體識別(SER)和關系提取(RE)2個子任務。本文采用飛槳 PaddleNLP推出的UIE-X(Unified Information Extraction-X)開源信息抽取模型。該模型采用結構化抽取語言,對不同的抽取結構進行統一編碼,并通過基于模式的提示機制(Schema-based Prompt Mechanism)自適應生成目標抽取結果。UIE-X模型基于文心ERNIE-Layout跨模態布局增強預訓練模型,經過大規模數據的訓練后,具備很強的遷移性能,僅須少量數據微調即可獲得較好的抽取性能。為實現系統端到端的功能并保證模型輕量化,本文選用UIE-mini模型。
3 結果與討論
3.1 數據集
由于檔案資料種類繁多,決定了檔案收集系統模型所使用的訓練數據需要具有多樣性。本文采用文檔數據、手寫體數據、表格數據等多個公開數據集,分別對系統中布局分析模塊、表格識別模塊、文本識別模塊和信息提取模塊進行了預訓練,然后使用采集的檔案資料圖片對系統模型進行微調。其中,印刷體文本數據集來自開源數據庫Text_Render生成的文檔式的合成文本圖像( https://github.com/Sanster/text_renderer),文本為印刷體文本。該數據集共包含500000個樣本,其中80%被隨機劃分為訓練集,10%為驗證集,10%為測試集。表格數據使用TableGeneration表格工具生成(https://github.com/WenmuZhou/TableGeneration),生成了20000張圖片,并按8∶1∶1的比例隨機劃分為訓練集、驗證集和測試集。合成文本和表格的語料庫均來源于維基百科、亞馬遜和百度百科。手寫文本數據來自飛槳 AI Studio(https://aistudio.baidu.com/datasetdetail/102884),包括公開數據集Chinese OCR、中國科學院自動化研究所的手寫中文數據集CASIA-HWDB 2.x以及網上開源數據合并組合的數據集。其中,訓練樣本共200000個,測試樣本共10000個。本研究共采集了檔案圖片2000張,用于對系統模型進行參數微調,其中隨機選擇了1600張用于訓練,400張進行模型測試。
3.2 試驗結果與分析
布局分析模塊采用了PP-PicoDet-LCNet 2.5x 模型作為教師網絡,同時使用PP-PicoDet-LCNet 1.0x模型作為學生網絡,采用FCD知識蒸餾算法。如表1所示,與YOLOv2目標檢測算法相比,目標檢測精度的平均精度均值(mean Average Precision,mAP)提高了0.5%。此外,推理時間方面,平均CPU耗時顯著減少至54 ms,同時模型大小僅有9.7 M。因此,模型在輕量化和性能方面均優于YOLOv2。
本文還將表格識別模塊SLANet模型與最新的幾種效果較好的模型(TableMaster和飛槳表格識別模型PP-Structure的TableRec-RARE網絡)進行了對比。如表2所示,SLANet的預測時間最短,同時在準確度和TEDS(Tree-Edit-Distance-based Similarity)方面都有所提高,超過了TableRec-RARE。盡管TableMaster在準確度和TEDS指標上略高于SLANet,但其模型規模大且參數多,是SLANet的27.5倍,推理時間是SLANet的2.8倍。因此,綜合考慮輕量化和預測性能,SLANet的優勢更為明顯。
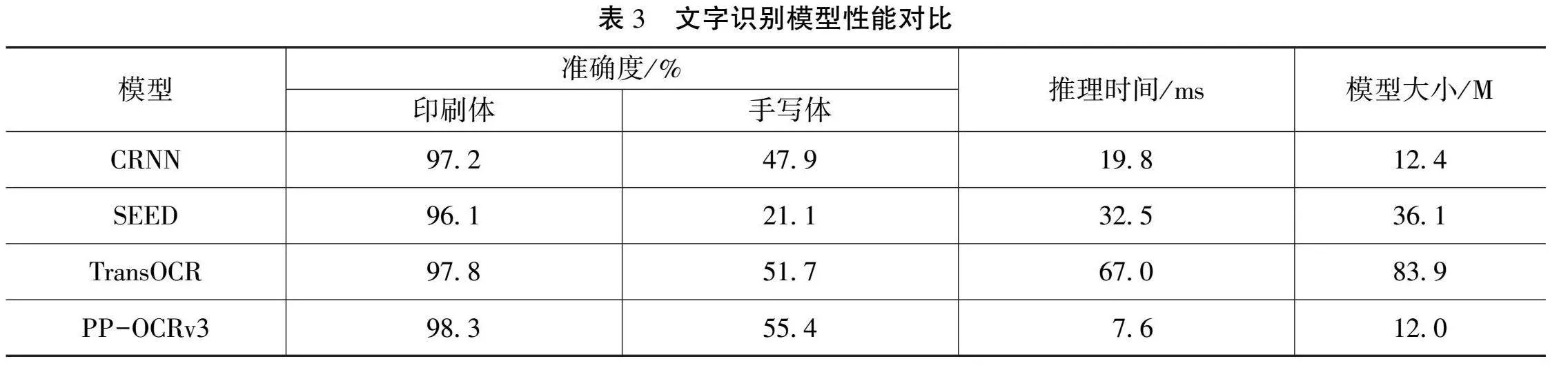
本文對印刷體文本和手寫體文本進行了單獨識別,以測試系統的文本識別性能。通過與幾種表現較好的模型比較,發現由于印刷體文本排版較規則且字形規整,更容易被識別,其識別準確率達到95%以上。而手寫體文本屬于易出現彎曲、覆蓋和模糊的不規則文本,因此其識別正確率較低,具體模型識別性能如表3所示。CRNN和PP-OCRv3的算法均采用了基于CTC注意力引導的方法,而TransOCR則基于Transformer的自注意力模塊作為解碼器。這些模型的識別準確率均高于SEED,再次證實了自注意力機制在序列識別中的優勢。CRNN和PP-OCRv3的模型更為輕量化,但PP-OCRv3的運行時間更短,且識別準確度更高。
與飛槳PP-Structure的Ⅵ-LayoutXLM模型相比,UIE-X信息提取模塊的F1 score提高了10%。尤其是對于文本行無序和含噪聲的文檔圖像,UIE-X識別效果更好。雖然UIE-X模型規模更大,但其具備強大的模型遷移能力,無須耗費時間使用大量數據進行訓練,僅須對30個少量樣本進行微調,即可達到0.89的F1 score值。
4 結語
本文提出了一種輕量化的端到端檔案智能化收集系統,通過與常見的OCR技術進行比較,選擇了識別正確率高且輕量化的網絡模型,以實現端到端的檔案智能化收集。本文重點解決了當前OCR技術在識別檔案資料中常見的表格、圖表或非線性文本等復雜的文檔格式和布局的問題。同時,為了將系統部署到移動設備前端,盡量平衡了模型精度和推理速度。系統對表格識別的準確度達到了75.8%,印刷體文本識別準確度達到了98.3%,而總推理時間不超過0.85 s。因此,本文系統可以實現端到端的檔案資料智能化收集,為提高檔案資料整理的效率提供了一種有效的解決方案。未來的工作將進一步解決圖像采集中造成的低分辨率或低質量掃描等噪聲的影響,提高手寫體4cac820ab21bae3716d5e87d2ea33bb4識別精度并提高大型文檔識別效率,以更好地服務于檔案信息智能化管理系統。
參考文獻
[1]王睿,林凱.基于神經網絡的OCR技術在自動閱卷系統中的應用研究[J].現代計算機,2024(30):103-106.
[2]倪吳廣,汪朵拉,張卓.基于PP-PicoDet技術的智能垃圾分類[J].計算機測量與控制,2023(31):291-298.
[3]陳永祺,顧茜,林郁.基于PP-PicoDet的半自動標注煙絲異物檢測研究[J].中國煙草學報,2023(29):11-21.
[4]YANG Z,LI Z,JIANG X,et al.Focal and global knowledge distillation for detectors:2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR),June 18-19,2022[C].London:INSPEC,2022.
[5]陳雨,蔣三新.基于改進結構與位置對齊網絡的表結構識別法[J].國外電子測量技術,2023(42):57-62.
[6]DU Y K,CHEN Z N,JIA C Y,et al.SVTR:Scene text recognition with a single visual model:31st International Joint Conference on Artificial Intelligence(IJCAI 2022),July 23-29,2022[C].New York:EI,2022.
(編輯 沈 強)
Research on intelligent collection method of archives based on OCR technology
ZHANG Tinglin1, CHEN Xiangben2*, DING Ye1, ZHANG Yong2
(1.Yancheng Institute of Technology, Yancheng 224051, China;
2.Yancheng Institute of Science and Technology Information, Yancheng 224002, China)
Abstract: In order to realize the intelligent management of file information, a lightweight end-to-end intelligent file collection system is proposed. Firstly, a lightweight object detection neural network PP-PicoDet is used as a layout detector to analyze the layout of archival materials. Then, SLANet deep learning neural network is used for structural recognition of the tables. Finally, the open source Paddle OCR engine is used for text recognition. The accuracy of the system for table recognition is 75.8%, the accuracy of printed text recognition is 98.3%, and the total reasoning time is less than 0.85s. This system brings forward an effective solution to realize the intelligent collection of file data from end to end and improve the efficiency of file data sorting.
Key words: intelligent collection of archives; deep learning; optical character recongnition; Chinese form; handwriting recognition
