
遙感解譯在影像質量檢查中的應用
2024-12-04 00:00:00邱姝月何奕萱陳柏行秦暢郭紅操
中國新技術新產品 2024年11期


摘 要:亞米級衛星影像為“實景三維成都”建設項目中地形級實景三維的數據基礎,多個部門共享、共用,因此對其質量嚴格把控十分重要。采用人工目視方式對單景影像(約576 km2)進行外觀符合性檢查,時間約為1 h。以2023年11月成都市域亞米級衛星影像為例,將SegFormer網絡模型內嵌在遙感AI解譯監測系統中,對成都市域衛星影像中的不良區域進行快速識別,其平均分類精度達到81.0%,單景影像提取時間約為15 min,該系統為成都市域衛星影像質量檢查工作的高效實施提供有力支撐。
關鍵詞:衛星影像;質量檢查;影像外觀符合性;遙感解譯;SegFormer
中圖分類號:P 23" " " " " " 文獻標志碼:A
隨著遙感和深度學習技術的發展,卷積神經網絡在遙感影像特征的自動化提取中廣泛應用。卷積神經網絡模型過分關注局部特征,忽略整體信息,因此Dosovitskiy提出多層Transformer結構的Vit模型,在影像識別中結合了整體信息。SegFormer網絡模型將Transformer編碼器與輕量級解碼器相結合,避免由于位置編碼改變導致模型性能下降。牛玉珩[1]、楊靖怡[2]在農業、醫學等領域進行研究。本文將SegFormer網絡模型內嵌于遙感AI解譯監測系統中,提取目標圖斑。將該系統應用于成都市域衛星影像中,對不良區域進行識別,當檢測影像外觀時范圍大、效率高,符合檢驗要求,縮短影像質量檢驗周期,減輕影像檢查工作強度。
1 研究區介紹
成都市地處四川盆地西部的岷江中游地段、青藏高原東緣,位于東經102°54'~104°53',北緯30°05'~31°26',境內地勢平坦,河網縱橫,東界龍泉山脈,西靠邛崍山。成都市屬于平原亞熱帶季風性濕潤氣候,雨熱同期,四季分明。大部分地區常年云霧天氣多,日照時間少,空氣濕度大。
2 數據源及預處理
本次試驗數據為2023年10月成都市BJ3和BJ2影像,其空間分辨率為0.5 m~0.8 m,共6景。對其進行遙感影像預處理,為使模型適用于不同類型不良區域(云霧、陰影、高亮和色彩溢出),選取相對集中區域作為樣本。云霧、陰影區域普遍面積較大,高亮、色彩溢出區域普遍面積較小,如果將其構建為1個樣本庫,那么由于樣本庫數量失衡,高亮、色彩溢出影像精度會降低,因此分別構建2個樣本庫。樣本庫一為高亮、色彩溢出的單要素樣本,樣本庫二為云霧、陰影的雙要素樣本,如圖1所示。樣本庫一共選取110個區域遙感影像,并將其劃分為413個512 ppi×512 ppi的樣本。高亮、色彩溢出區域面積較小,為避免模型過擬合,對其進行隨機縮放、翻轉等數據增強操作,將其樣本數擴充至826個。樣本庫二共選取17個區域遙感影像,將其劃分為793個512 ppi×512 ppi的樣本。
3 研究方法
3.1 研究流程
遙感AI解譯監測系統集樣本庫構建、模型訓練、精度評估和影像自動解譯等功能于一體。對衛星影像(分辨率為0.5 m~
0.8 m)中的感興趣(不良)區域進行人工標注,得到與影像數據相對應的標注矢量數據,并將其裁剪為512 ppi×512 ppi,完成樣本庫構建。將樣本庫一和樣本庫二分別按照7∶2∶1的比例劃分為訓練集、測試集和驗證集。將訓練集輸入基于語義分割的SegFormer網絡模型進行訓練,根據樣本數據集情況調整學習率、訓練批次、樣本數和優化方法等超參數,將網絡模型提取的不良區域與驗證集進行比較。根據模型在訓練過程中反饋的Loss損失、訓練精度等信息重新調整模型結構、參數,再次進行訓練,最終獲得精度最佳的模型。調動訓練階段得到的深度學習算法模型,對檢測的遙感影像進行不良區域提取。
3.2 基于語義分割的SegFormer網絡模型
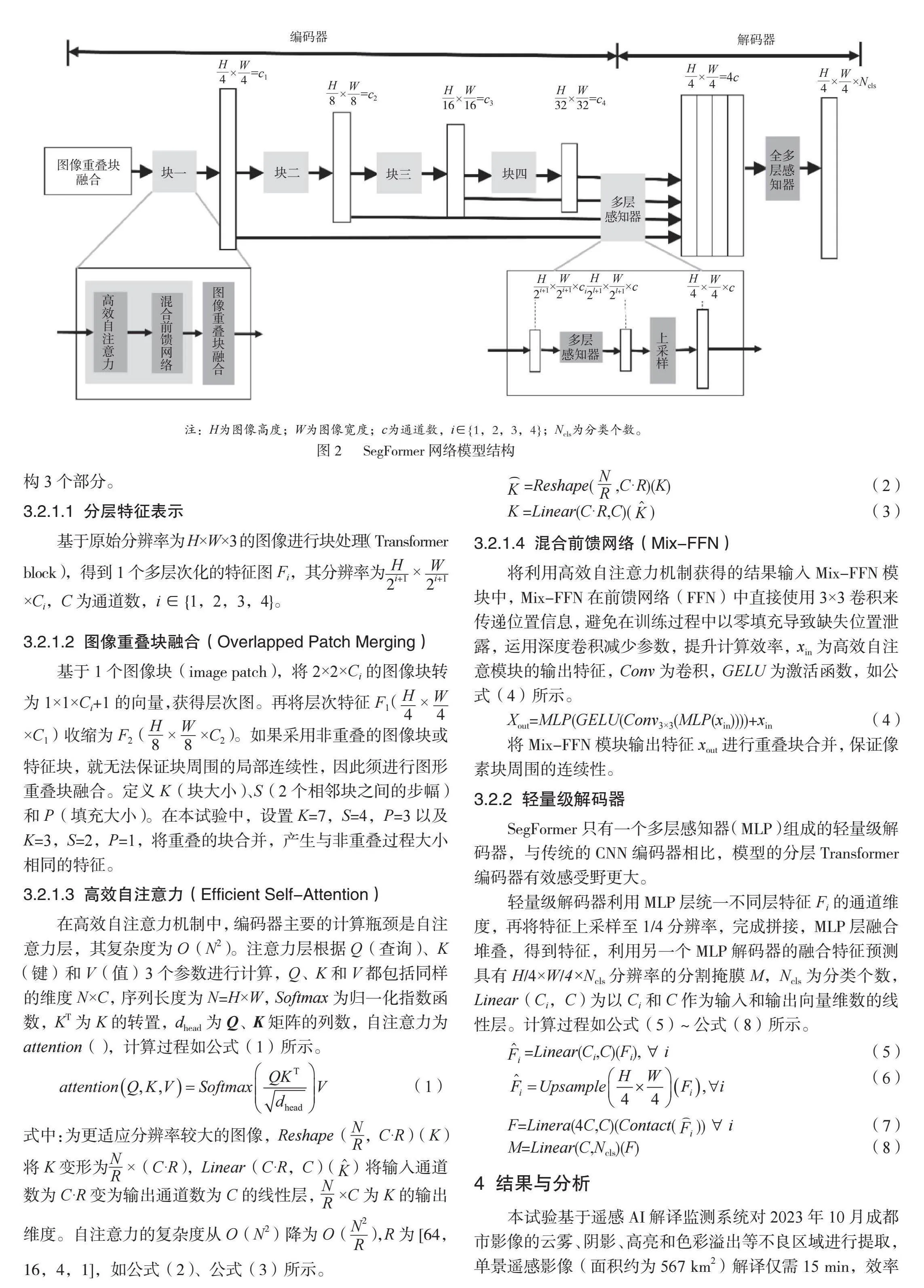
SegFormer網絡模型由2個模塊組成。1)分層Transformers編碼器,可產生高分辨率粗特征和低分辨率細特征。2)輕量級的A11-MLP解碼器,可融合多層次特征并預測語義分割掩碼,使模型魯棒性、準確性更高。SegFormer網絡模型結構如圖2所示。
3.2.1 分級Transformer編碼器
SegFormer采用Mix Transformer(MiT)編碼器,該編碼器由4個Transformer塊組成,每個Transformer塊包括高效自注意力機制(Efficient Self-Attention)、圖像重疊塊融合(Overlapped Patch Merging)和混合前饋網絡(Mix-FFN)結構3個部分。
3.2.1.1 分層特征表示
基于原始分辨率為H×W×3的圖像進行塊處理(Transformer block),得到1個多層次化的特征圖Fi,其分辨率為××Ci,C為通道數,i∈{1,2,3,4}。
3.2.1.2 圖像重疊塊融合(Overlapped Patch Merging)
基于1個圖像塊(image patch),將2×2×Ci的圖像塊轉為1×1×Ci+1的向量,獲得層次圖。再將層次特征F1(××C1)收縮為F2(××C2)。如果采用非重疊的圖像塊或特征塊,就無法保證塊周圍的局部連續性,因此須進行圖形重疊塊融合。定義K(塊大小)、S(2個相鄰塊之間的步幅)和P(填充大小)。在本試驗中,設置K=7,S=4,P=3以及K=3,S=2,P=1,將重疊的塊合并,產生與非重疊過程大小相同的特征。
3.2.1.3 高效自注意力(Efficient Self-Attention)
在高效自注意力機制中,編碼器主要的計算瓶頸是自注意力層,其復雜度為O(N2)。注意力層根據Q(查詢)、K(鍵)和V(值)3個參數進行計算,Q、K和V都包括同樣的維度N×C,序列長度為N=H×W,Softmax為歸一化指數函數,KT為K的轉置,dhead為Q、K矩陣的列數,自注意力為attention(),計算過程如公式(1)所示。
(1)
式中:為更適應分辨率較大的圖像,Reshape(,C·R)(K)將K變形為×(C·R),Linear(C·R,C)()將輸入通道數為C·R變為輸出通道數為C的線性層,×C為K的輸出維度。自注意力的復雜度從O(N2)降為O(),R為[64,16,4,1],如公式(2)、公式(3)所示。
=Reshape(,C·R)(K)" " " (2)
K =Linear(C·R,C)()" " " " " (3)
3.2.1.4 混合前饋網絡(Mix-FFN)
將利用高效自注意力機制獲得的結果輸入Mix-FFN模塊中,Mix-FFN在前饋網絡(FFN)中直接使用3×3卷積來傳遞位置信息,避免在訓練過程中以零填充導致缺失位置泄露,運用深度卷積減少參數,提升計算效率,xin為高效自注意模塊的輸出特征,Conv為卷積,GELU為激活函數,如公式(4)所示。
Xout=MLP(GELU(Conv3×3(MLP(xin))))+xin " " " " " " (4)
將Mix-FFN模塊輸出特征xout進行重疊塊合并,保證像素塊周圍的連續性。
3.2.2 輕量級解碼器
SegFormer只有一個多層感知器(MLP)組成的輕量級解碼器,與傳統的CNN編碼器相比,模型的分層Transformer編碼器有效感受野更大。
輕量級解碼器利用MLP層統一不同層特征Fi的通道維度,再將特征上采樣至1/4分辨率,完成拼接,MLP層融合堆疊,得到特征,利用另一個MLP解碼器的融合特征預測具有H/4×W/4×Ncls 分辨率的分割掩膜M,Ncls為分類個數,Linear(Ci,C) 為以Ci和C作為輸入和輸出向量維數的線性層。計算過程如公式(5)~公式(8)所示。
=Linear(Ci,C)(Fi),i" " "(5)
(6)
F=Linera(4C,C)(Contact()) i" (7)
M=Linear(C,Ncls)(F)" nbsp; " " " " " " " " " " " "(8)
4 結果與分析
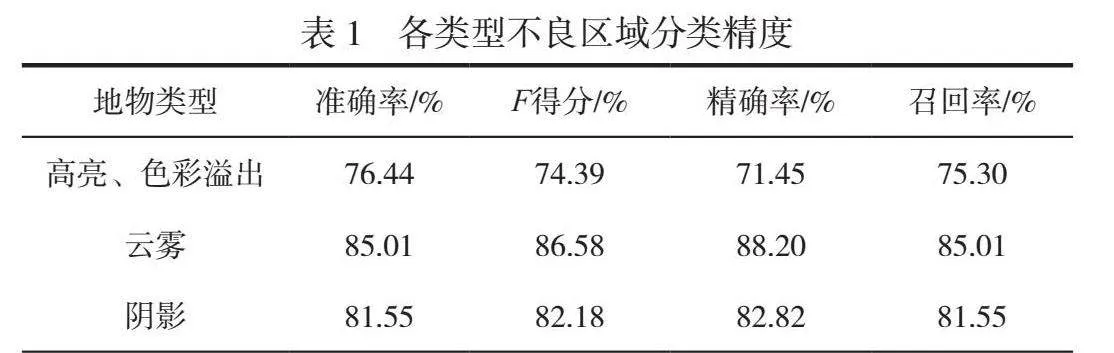
本試驗基于遙感AI解譯監測系統對2023年10月成都市影像的云霧、陰影、高亮和色彩溢出等不良區域進行提取,單景遙感影像(面積約為567 km2)解譯僅需15 min,效率遠高于人工目視判讀。經多次超參數調整測試,每間隔50次迭代進行一次評估,最終確定迭代次數為6 800,批大小為4,當學習率為0.001時得到準確率最高的模型。測試數據整體精度較高,各類型不良區域分類精度見表1,模型的平均準確率為81.00%,平均召回率為81.05%。
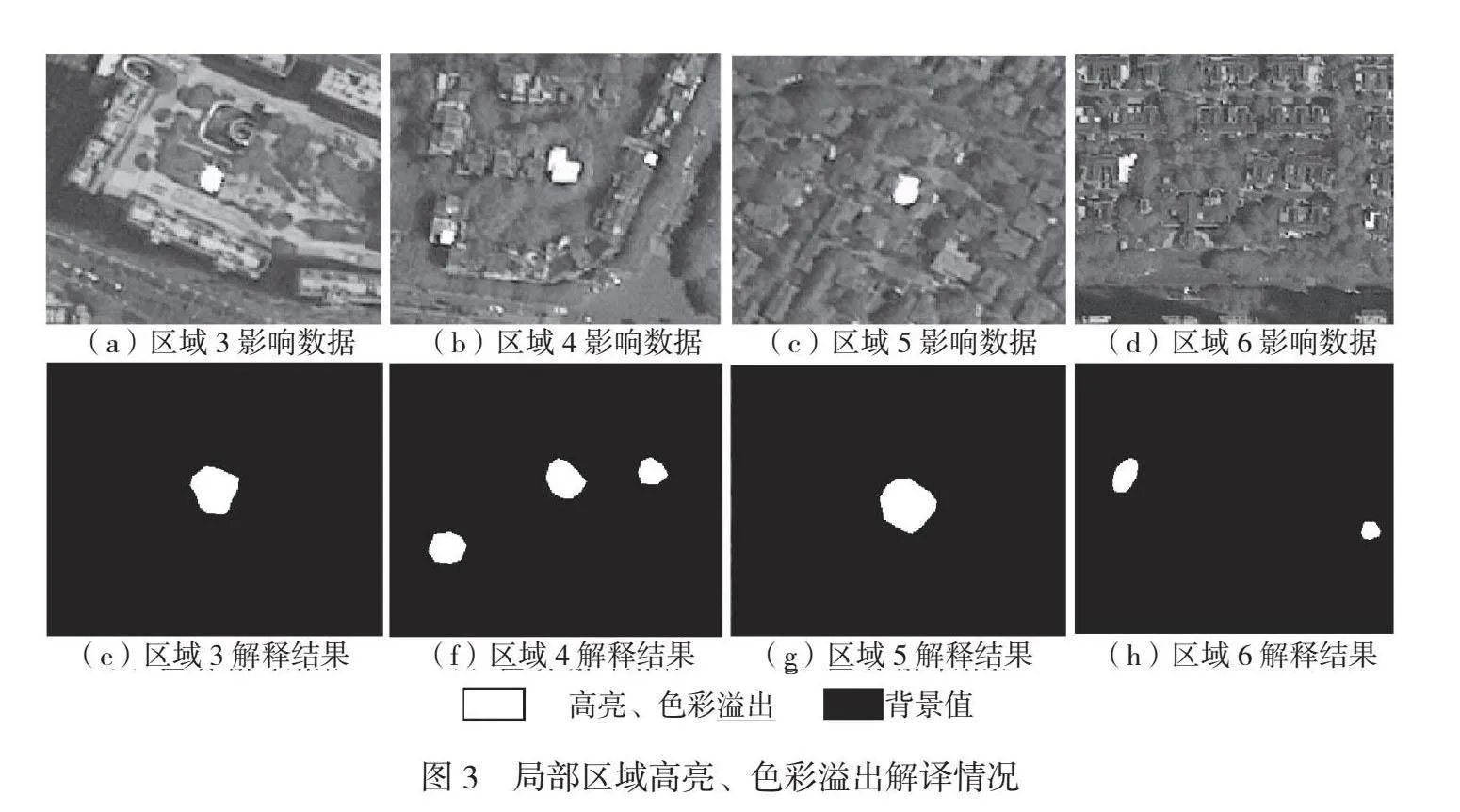
高亮、色彩溢出精度相對較低,為76.44%,整體漏檢情況較少,存在少量誤檢情況,局部區域高亮、色彩溢出解譯情況如圖3所示。在采樣過程中須將高亮及其周圍色彩溢出區域全部采集為樣本,該類不良區域特征邊界并不清晰,因此模型將色彩飽和度較高區域識別為不良區域,導致其精度受限。云霧、陰影的精度分別為85.01%和81.55%,漏檢、錯檢情況較少,局部區域云霧、陰影解譯情況如圖4所示。陰影區域和水體區域色調較暗,較難區分其邊界,但是圖4(d)模型能夠準確識別陰影區域。不良區域具有范圍大、邊界不規則等特點,存在小面積碎斑,經批處理后能夠滿足助影像外觀符合性檢查的要求,與目視檢查相比效率更高。
5 結語
以前通常采用抽查方式檢查衛星影像質量,采用目視方法檢查影像外觀符合性,因此不僅難以掌握樣本外影像外觀符合性的質量情況,還會耗費大量人力資源。為解決衛星影像質量檢查難題,本文基于遙感AI解譯監測系統對成都市典型特征不良區域(云霧、陰影、高亮和色彩溢出)進行識別,不良區域圖斑提取的總體精度為81.0%,解譯時間為15 min。試驗結果表明基于SegFormer模型的遙感解譯系統能夠學習局部和整體特征,解譯準確性較高,模型遷移性能較好。SegFormer網絡模型在影像不良區域中中識別效果良好,云霧、陰影以及高亮區域邊界不清晰,導致模型精度受限,因此針對邊緣的精確識別以及較小識別目標的識別精度仍然有待提升。
參考文獻
[1]牛玉珩,李永可,陳燕紅,等.基于改進SegFormer模型的棉田地表殘膜圖像分割方法[J].計算機與現代化,2023(7):93-98.
[2]楊靖怡,李芳,康曉東,等.基于SegFormer的超聲影像圖像分割[J].計算機科學,2023,50(增刊1):414-419.
