
銀行智能電話客服用戶體驗優化研究
2024-12-04 00:00:00倪洋
中國新技術新產品 2024年11期

摘 要:本研究旨在探討銀行業中人工智能電話客服系統的用戶體驗優化,利用梯度學習的集成模型對數據進行擬合,預測客戶滿意度。通過收集銀行業應用智能AI真實數據,本文使用了隨機森林模型和梯度提升模型,結合它們的優勢來提高模型的性能。本文分析了模型的擬合效果和預測準確性,并觀察了數據的基本特征以及模型的決策邊界、擬合響應面和預測結果。試驗結果顯示,集成模型在預測客戶滿意度方面表現出了很高的準確性和可靠性,能夠有效優化銀行業電話客服系統的用戶體驗。未來的研究將繼續改進模型,以提高服務質量和用戶滿意度。
關鍵詞:銀行業;人工智能;智能客服;用戶體驗
中圖分類號:TP 18" " " " " " " " " " " " 文獻標志碼:A
目前,隨著智能語音技術的飛速發展,其在融媒體應用中的應用場景和模式創新備受關注。張楷越對智能語音技術在融媒體中的應用進行了深入剖析[1]。王晰巍等通過調查用戶虛擬在線體驗,探討了AI語音助手的影響因素[2]。從用戶體驗的視角,陳積銀等研究了人工智能視頻生產平臺的使用效果[3],而陳曦和宮承波在場景理論的視野下,深入探討了智能音頻用戶體驗模型[4]。人工智能技術在融媒體體驗中的其他方面也得到了廣泛關注。徐延章以廣電融媒體設計模型為基礎,解讀了人工智能與融媒體的交融[5]。顏洪等通過情感交互設計,深入研究了人工智能語境下的情感交互[6]。本文旨在研究使用梯度學習的集成模型進行數據擬合,以優化銀行業中人工智能電話客服系統,提高用戶體驗。
1 模型概述
1.1 隨機森林
隨機森林是一種基于決策樹的集成學習算法。決策樹是一種樹形結構,其中,每個非葉子節點為一個特征屬性的判斷,每個葉子節點為一種類別或者數值。在隨機森林中,通過隨機選擇樣本和特征來構建多棵決策樹,并通過投票或平均值來綜合多棵樹的預測結果。
決策樹如公式(1)所示。
(1)
式中:x為樣本;h(x)為決策樹模型對樣本的預測值;M為弱分類器的數量;N為葉子節點的數量;Ri為第i個葉子節點的區域;wi為該葉子節點的預測值;I為指示函數,用于表示樣本x是否屬于第i個葉子節點的區域Ri。
在隨機森林中,通過隨機選擇特征來構建每棵樹,以增加模型的多樣性。最終的隨機森林模型如公式(2)所示。
(2)
式中:N1為隨機森林中樹的數量;hj(x)為第j棵樹的預測結果;f(x)為隨機森林模型對樣本的預測值。
1.2 梯度提升
在模型中,將客戶滿意度作為目標變量y,而等待時長w和通話時長t則作為特征變量。本文的目標是學習一個函數f(w,t),使其能夠準確地預測客戶滿意度y2。為了實現這個目標,本文使用了梯度提升算法來訓練集成模型。
梯度提升是一種迭代的集成學習算法,通過迭代地訓練一系列弱學習器,每個學習器都在上一個學習器的殘差上進行訓練。最終的模型是所有弱學習器的加權和。
梯度提升算法通過迭代地擬合殘差來逐步優化模型。在第i輪迭代中,假設當前模型的預測結果為fi-1,則第i個弱分類器被訓練來擬合當前模型的殘差,如公式(3)所示。
ri=y1-fi-1 (3)
式中:r為殘差;y1為預測結果。
然后,更新模型如公式(4)所示。
fi=fi-1+γihi (4)
式中:γi為學習率,控制每次迭代更新的步長;fi為更新后的模型預測值;fi-1為更新前的舊模型預測值;hi為弱分類器對樣本x特征的預測結果。
通過迭代地添加弱分類器,并根據殘差進行模型更新,最終得到一個在訓練數據上表現良好的集成模型,可以用于預測客戶滿意度。
1.3 集成模型
本文提出的集成模型基于梯度學習,其核心思想是通過組合多個弱分類器(例如決策樹、隨機森林和梯度提升樹)來構建一個更強大的模型,以提高預測的準確性和魯棒性。本文提出的模型如公式(5)所示。
(5)
式中:f1(x)為最終的集成模型;M為弱分類器的數量;γm為第m個弱分類器的權重;hm(x)為第m個弱分類器的預測結果。
通過梯度學習的方式,迭代優化模型參數,使集成模型能夠最大化擬合訓練數據,從而提高預測的準確性。在訓練過程中,使用損失函數來衡量預測值與真實值之間的差距,并通過梯度下降法來更新模型參數,以最小化損失函數。優化目標如公式(6)所示。
(6)
式中:N為訓練樣本的數量;L為損失函數;yi為第i個樣本的真實值;f(xi)為模型對第i個樣本的預測值。
集成模型通過組合不同的弱學習器,并通過梯度學習的方式優化模型參數,對銀行業中人工智能電話客服系統用戶體驗進行有效預測。
2 模型性能
2.1 模型設置
本文使用了銀行業人工智能電話客服真實數據(N=1000)對模型的性能進行測試。本文所使用的模型包括隨機森林模型和梯度提升模型。其中,由500個決策樹組成的隨機森林模型用于回歸問題,即預測客戶滿意度。由500個弱學習器組成的梯度提升模型使用了最小二乘提升算法(LSBoost),并進行了500輪訓練。
本文利用了兩個不同模型的優勢,結合它們的預測結果以提高模型的性能。由于隨機森林和梯度提升模型處理數據時采用了不同的策略,因此它們的預測結果可能會提供互補的信息。尤其是當面對真實世界的復雜數據時,這樣的集成方法通常有助于提高模型的魯棒性和泛化能力。
為了評估模型的性能,本文將使用銀行業真實數據進行測試,并比較單個模型和集成模型的預測結果。本文使用常見的性能指標,例如均方根誤差(RootMeanSquareError,RMSE)和決定系數(CoefficientofDetermination,R2)來評估模型的擬合效果和預測準確性。通過比較模型在測試數據上的表現,能夠評估集成模型相對于單個模型的優勢,并確定其在銀行業電話客服系統用戶體驗優化中的效果。通過比較模型預測的客戶滿意度與實際調查結果,評估模型的性能。
2.2 數據基本特征
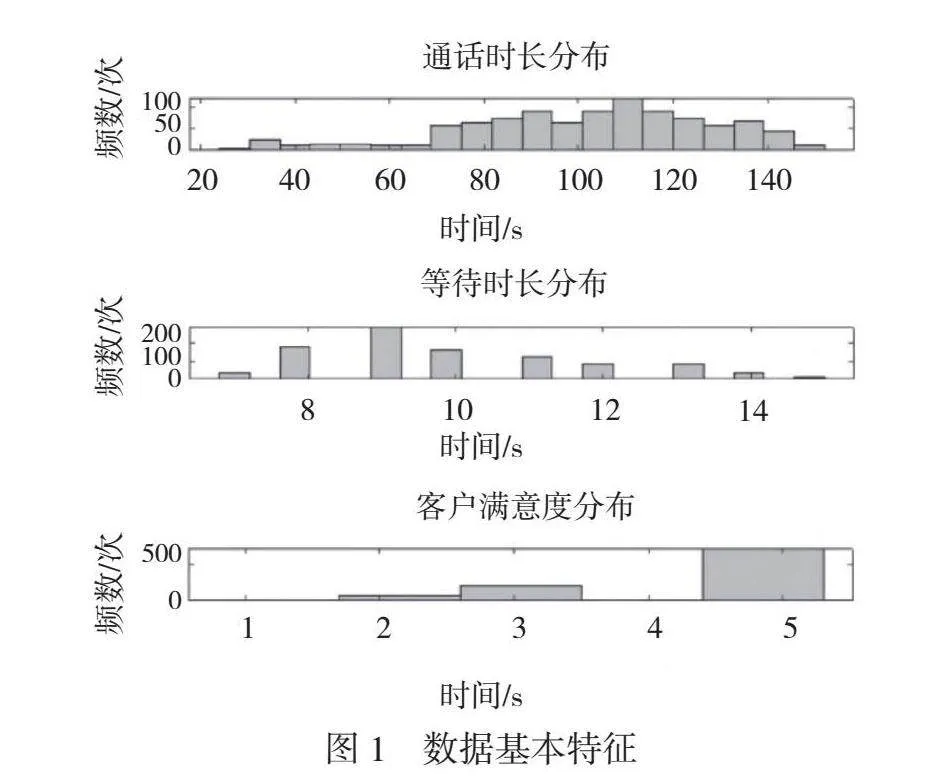
由圖1可知,等待時長和通話時長與客戶滿意度之間存在一定的關系。
通話時間的分布較為集中,大部分通話時長在70s~140s,說明在這個范圍內的通話時長較為常見。然而,也存在少量通話時長較短或較長的情況,這可能受到客戶需求、問題復雜度等因素的影響。人工智能客服對處理特定問題的復雜度和耗時情況基本穩定,因此不同類型和復雜度的問題可能會導致通話時長變化。一些簡單的問題可能解決很快,通話時長較短,而一些復雜的問題可能需要更長的時間來解決,導致通話時長較長。
客戶在通話前的等待時間約為9s,這表明大部分客戶等待時間較短。然而,本文也觀察到一些客戶等待時間較長,最長為15s。等待時間過長可能會使客戶對服務質量和解決方案的準確性有很高期望,因此引入人工智能客服而非人工客服時降低了客戶滿意度,需要進一步關注和改善AI與人工客服的切換。與此同時,人工智能電話客服系統本身的技術問題或系統故障也可能影響等待時長和通話時長。如果系統出現故障或者技術問題,就可能會導致等待時間延長或者通話過程中中斷,導致客戶滿意度降低。
客戶滿意度評分主要集中在五分,這說明大多數客戶對銀行業電話客服系統的服務表示滿意。然而,也有部分客戶選擇了三分,少量客戶選擇了四分、二分和一分。這些低分可能反映了客戶在服務過程中遇到的問題或不滿意的地方,需要重點關注和改進,以提高整體用戶體驗。
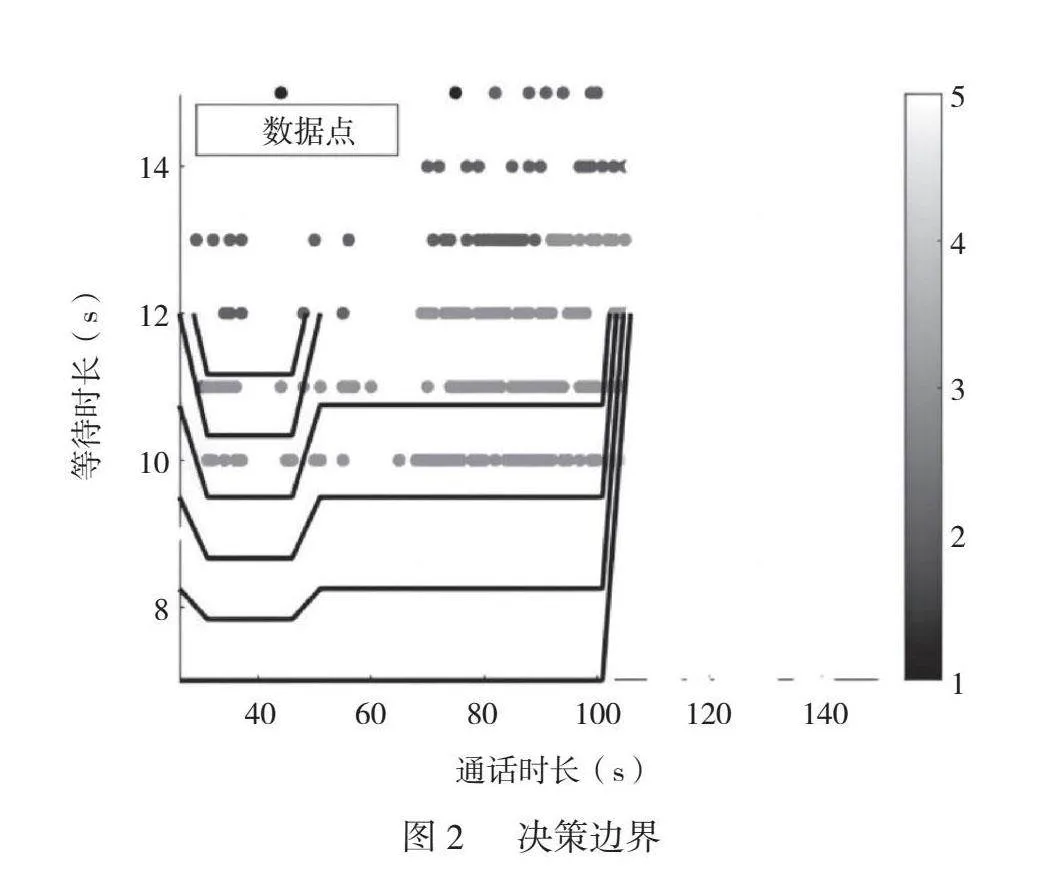
圖2展示了模型的決策邊界,這是指模型在特征空間中劃分不同類別或預測值的邊界。對本文的模型來說,決策邊界表明了模型對客戶滿意度的預測邊界,即不同特征值下模型對客戶滿意度的預測結果。
通過觀察決策邊界的形狀和位置,本文可以深入了解模型對不同特征值的預測結果以及模型在不同區域的表現。
在銀行業電話客服系統中,通話時長和等待時長是影響客戶滿意度的重要因素。因此,本文將重點關注這兩個特征對決策邊界的影響。可以觀察到,隨著通話時間的延長,客戶普遍選擇較高的評分。如果系統的語音識別準確性高,那么客戶能夠更快地完成通話,從而縮短通話時長。反之,如果語音識別存在誤解,就可能導致通話時長延長。然而,等待時長較長使客戶評價下降。特別是通話時長在30s~50s的客戶對等待時間更敏感,更易因為等待時間較長而選擇較低的滿意度評分。因為等待時間較長會讓客戶感到不悅,所以影響了其對服務的整體評價。
因此,通過觀察決策邊界,本文可以更清晰地了解模型對不同特征值的預測結果以及模型在不同區域的表現。這有助于更好地理解客戶滿意度的預測機制,并提出針對性地改進措施,以優化銀行業電話客服系統的用戶體驗。
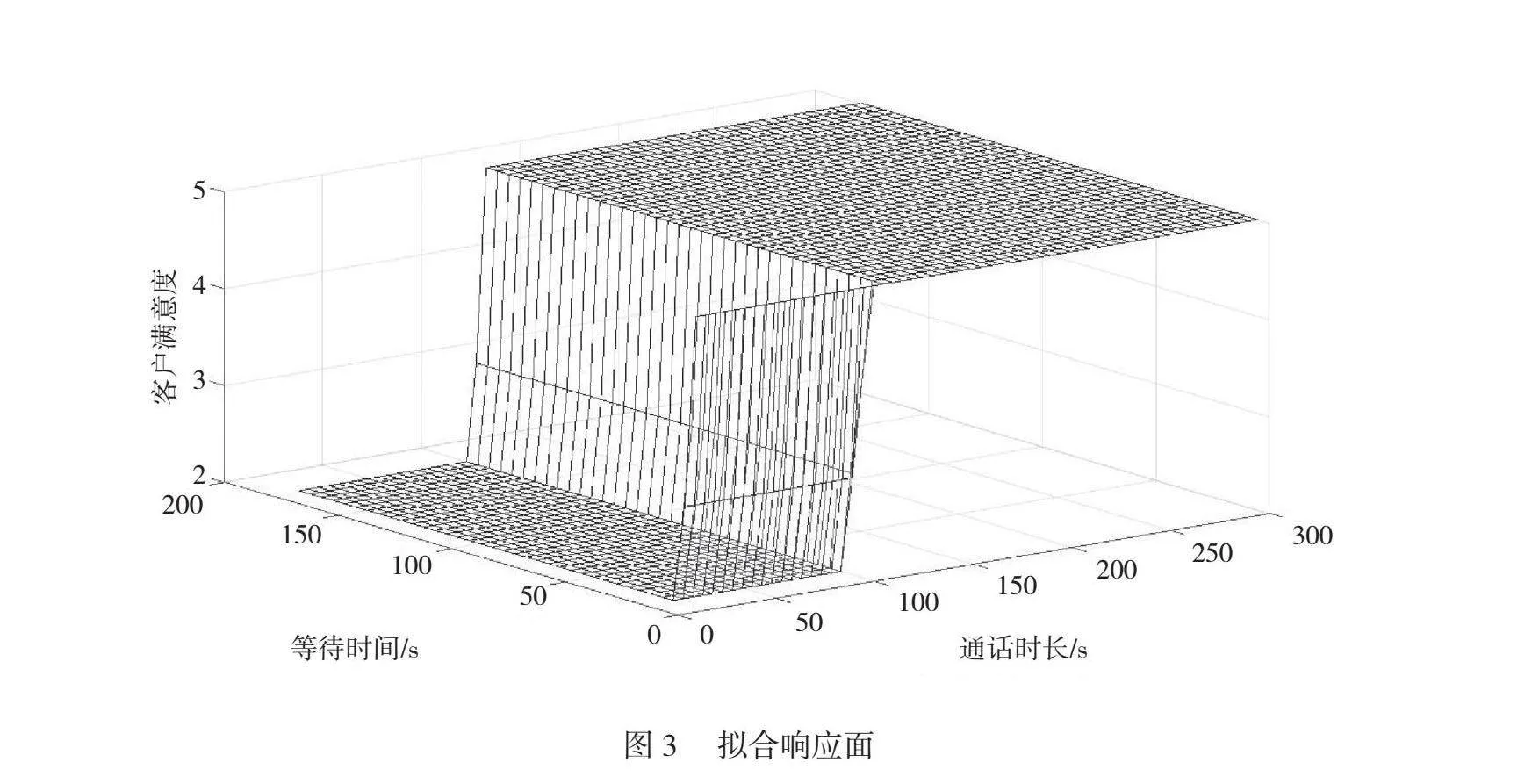
與圖2類似,圖3的擬合響應面也提供了模型對客戶滿意度預測的整體趨勢和變化規律。通過在三維空間中展示不同特征組合下的客戶滿意度預測結果,本文可以更全面地了解模型的預測效果。擬合響應面的形狀和曲線反映了模型對不同特征值的敏感程度以及不同特征組合對客戶滿意度的影響程度。
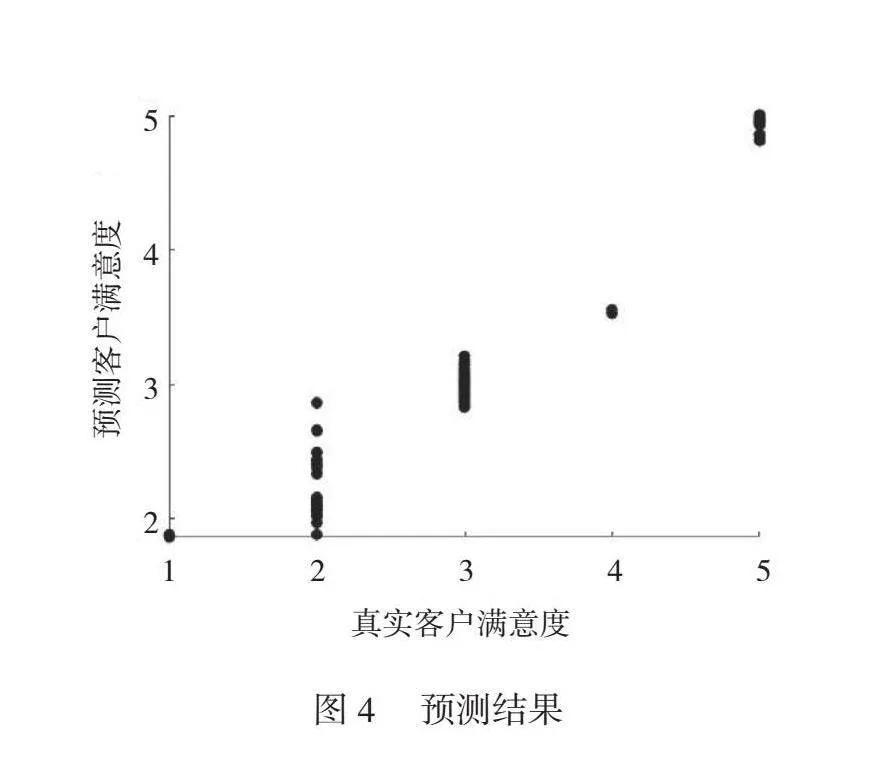
預測結果如圖4所示,當客戶滿意度較高時,模型的預測能力表現較好,當客戶滿意度較低時,更易于高估客戶滿意度。模型的訓練數據可能存在偏差,即在訓練數據中,客戶滿意度較高的樣本比較多,因此模型更擅長預測這種類別。通過比較預測結果與實際觀測值之間的差異,本文可以評估模型的預測準確性和擬合效果,從而更全面地了解模型在銀行業電話客服系統用戶體驗優化中的表現。
模型在銀行業人工智能客戶服務的真實數據上表現出非常高的擬合效果和預測準確性。
決定系數R2為0.99900,非常接近于1。這表明模型能夠解釋目標變量(客戶滿意度)中99.90%的方差,說明模型對數據的擬合效果非常好。
平均絕對誤差(MeanAbsoluteError,MAE)為0.0021,這說明模型的平均預測誤差約為0.0021,在實際問題中屬于非常小的范圍。
均方誤差(MeanSquaredError,MSE)為0.0010,這也是一個非常小的值,表明模型的預測值與實際值之間的偏差非常小。
綜合這些指標來看,模型在銀行業真實數據上的擬合效果非常優秀,能夠準確地預測客戶滿意度。這些結果說明本文提出的集成模型在銀行業電話客服系統用戶體驗優化中具有很高的可行性和實用性。
試驗結果表明,本文的集成模型在預測客戶滿意度方面具有較高的準確性和可靠性。與單一算法相比,集成模型能夠更準確地捕捉不同因素對客戶滿意度的復雜影響,從而提高了預測的準確性。
3 結語
本研究利用梯度學習的集成模型對銀行業中人工智能電話客服系統的用戶體驗進行研究。將等待時長和通話時長進行數據擬合,本文建立了一個預測客戶滿意度的模型,并證明了其在實際應用中的有效性。未來,本文將繼續改進模型,探索更多因素對用戶體驗的影響,以進一步提高銀行業人工智能電話客服系統的服務質量和用戶滿意度。
參考文獻
[1]張楷越.智能語音技術在融媒體中的應用場景與模式創新[J].傳媒,2023(18):25-27.
[2]王晰巍,劉宇桐,烏吉斯古楞,等.AI語音助手用戶虛擬在線體驗影響因素[J/OL].圖書館論壇,2024,44(1):71-85[2024-01-26].http://kns.cnki.net/kcms/detail/44.1306.G2.20230828.1416.006.html.
[3]陳積銀,胡睿心,孫鶴立.用戶體驗視角下人工智能視頻生產平臺使用效果研究[J].新聞大學,2021(12):92-107,124-125.
[4]陳曦,宮承波.場景理論視野下智能音頻用戶體驗模型探究[J].當代傳播,2021(2):89-92.
[5]徐延章.人工智能+融媒體體驗:基于廣電融媒體設計模型的解讀[J].電視研究,2020(6):45-48.
[6]顏洪,劉佳慧,覃京燕.人工智能語境下的情感交互設計[J].包裝工程,2020,41(6):13-19.
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
藝術科技(2016年9期)2016-11-18 15:11:16
出版科學(2016年5期)2016-11-10 06:47:04
農業與技術(2016年15期)2016-11-09 17:19:04
文藝生活·中旬刊(2016年9期)2016-11-07 03:31:21
商場現代化(2016年22期)2016-10-18 19:12:56
科技視界(2016年20期)2016-09-29 11:07:22
