地質大數據與機器學習在成礦預測中的應用
2024-12-17 00:00:00王俊潔呂雨璐
中國新技術新產品 2024年20期



摘 要:本文針對金屬成礦預測問題,利用地質大數據分析與機器學習技術進行了系統研究。采用支持向量機(SVM)和隨機森林(RF)等機器學習算法,構建并優化成礦預測模型。研究過程包括數據預處理、特征選擇、模型訓練和交叉驗證等步驟。結果顯示,本文構建模型在預測精度和可靠性方面表現出色,預測準確率為85%以上,將多源地質數據融合與高級機器學習算法結合,提高了成礦預測的精度和效率,為地質勘查提供了新的技術手段和方法。
關鍵詞:地質大數據;機器學習;成礦預測;地質勘查
中圖分類號:P 632" " " 文獻標志碼:A
地質勘查在礦產資源的發現和開發中至關重要。隨著全球經濟發展,各國對礦產資源的需求增加,高效、準確的成礦預測成為地質勘查的核心問題。傳統預測方法基于經驗和有限的地質數據,預測結果不確定且難以處理現代地質勘查中積累的大規模、多源和異構數據[1-2]。
地質大數據包括地質圖、遙感影像、地球物理測量數據、地球化學分析數據和礦產資源數據。這些數據不僅體量龐大,而且類型多樣、時空分布廣泛[3]。機器學習能從數據中自動學習規律并進行預測,具有處理大規模數據、識別復雜模式和高效預測的能力[4-5]。本文提出基于地質大數據和機器學習的成礦預測方法,將多源地質數據與先進的機器學習算法相結合,不僅可以提高成礦預測的精度和效率,還能為地質勘查提供新的技術手段和方法。本文分析了大量地質數據,識別成礦的關鍵因素和模式,并進行精準的礦產預測,以提高地質勘查效率,降低勘查成本,更好地指導礦產資源開發和利用。
1 方法論
1.1 數據預處理
本文從多種源頭收集了地質數據,主要包括地質圖、遙感數據和地球化學數據等。具體數據來源如下所示。1) 地質圖數據。包括地層圖、巖性圖和構造圖。這些圖件提供了區域地質構造和巖石類型的詳細信息。2) 遙感數據。采用衛星遙感技術獲取多光譜影像數據,識別地表的礦化蝕變特征。3) 地球化學數據,包括土壤、巖石樣品的化學成分分析數據,反映了地下礦物的分布情況。
對于缺失值處理,本文使用均值填補、插值法或刪除含有過多缺失值的樣本。對于異常值檢測,本文利用z-score方法進行檢測并處理異常值。對于數據集X中的某個特征xi,其z-score計算公式如公式(1)所示。
(1)
式中:為xi的均值;為xi的標準差;Zi為得分,如果|Zi|gt;3,就認為xi為異常值。
對于數據匹配與整合,假設有2個數據集A和B,二者通過位置L進行匹配,則整合后的數據集C如公式(2)所示。
C=A∪B" (2)
式中:A為地質圖數據;B為遙感數據。
1.2 特征選擇與工程
完成數據預處理后,將數據輸入模型前需要進行特征選擇,這是構建有效機器學習模型的關鍵步驟。利用特征選擇,模型能夠獲得最能反映成礦潛力的地質特征,從而提高模型的預測性能。根據地質學理論和實際數據,本文選取關鍵地質特征如下:地層厚度、巖性組合、巖石類型及其礦物組成、斷層/褶皺等構造特征以及金屬元素含量(例如Au、Cu和Pb等)的地球化學指標。
為了提高模型性能,本文對所選特征進行了歸一化和標準化等處理。歸一化是將特征值縮放到[0,1],標準化是將特征值轉換為均值為0、標準差為1的標準正態分布。
對于歸一化,將特征x進行歸一化處理,映射到[0,1],如公式(3)所示。
(3)
式中:X為歸一化結果;xmin和xmax分別為x的最小值和最大值;x′為標準化后的數據點。
對于標準化,將特征x進行標準化處理,使其符合標準正態分布,如公式(4)所示。
(4)
式中:為標準化結果;μ為x的均值;σ為x的標準差。
1.3 機器學習模型的構建與優化
完成特征選擇與工程后,需要構建并優化機器學習模型,這是成礦預測的核心步驟。選擇合適的算法和優化參數,能夠提高模型預測的準確性和可靠性。本文選擇了幾種常用且適用于處理復雜數據的機器學習算法,包括決策樹、隨機森林和支持向量機(SVM)。這些算法各具特色,能夠從不同角度分析、處理地質數據,從而提高成礦預測的準確性和可靠性。
決策樹算法采用樹狀結構進行決策,其優點是易于理解和解釋。每個節點表示對一個特征進行測試,每個分支表示測試結果,而每個葉節點則表示一個類別或回歸值。決策樹遞歸地對數據進行分割,構建出一個樹形模型,可以捕捉數據中的復雜決策路徑。但是單一的決策樹容易過擬合數據,因此需要在應用中進行剪枝以提高其泛化能力。
隨機森林算法是決策樹的集成方法,可構建多棵決策樹并進行投票或平均預測結果,以提高模型的準確性和穩健性。在訓練過程中,隨機森林會對數據集進行有放回的抽樣(即Bootstrap采樣),并對特征進行隨機選擇,生成多棵相互獨立的決策樹,從而增強模型的魯棒性,減少過擬合風險。隨機森林能夠處理高維數據和具有噪聲的數據,在地質數據分析中表現出色。
支持向量機(SVM)可構建一個超平面,將數據劃分為不同類別,具有很強的分類能力。SVM的核心思想是找到一個最大化類別間距的決策邊界,以提高分類的準確性。對于非線性數據,SVM利用核函數(例如線性核、徑向基函數核和多項式核等)將數據映射到高維空間,從而實現線性可分。SVM的優勢是具有良好的高維空間處理能力和泛化性能,適用于復雜的地質數據分類任務。
在模型優化過程中,本文采用交叉驗證的方法評估模型性能,并使用網格搜索調整超參數。例如,對于隨機森林,可以利用調整樹的數量、最大深度和最小樣本分裂數來優化模型。對于SVM,可以調整核函數類型、懲罰參數c和核參數γ,以找到最佳參數組合。通過這些優化步驟,本文構建了高精度、高可靠性的成礦預測模型。
1.4 模型評價指標
模型訓練結束后,需要根據預測任務的不同,采用不同的評價指標來判斷模型訓練的效果。本文將精度(Accuracy)、召回率(Recall)和F1值(F1 Score)作為模型評價指標,分別如公式(5)~公式(7)所示。
(5)
(6)
(7)
式中:Accuracy為模型預測的正確率;Recall為模型對正類樣本的識別能力;Precision為模型預測的準確率;F1值為精度和召回率的調和平均值;TP為真正例;TN為真反例;FP為假正例;FN為假反例。
2 案例分析
為了評估模型的性能和有效性,本文將數據集劃分為訓練集、驗證集和測試集。具體劃分比例為訓練集占70%,驗證集占10%,測試集占20%。為了優化模型性能,本文對模型進行了一系列處理和參數調整。
2.1 數據預處理的應用
本文從地質圖、遙感數據和地球化學數據中收集樣本。缺失值使用均值填補和插值法進行處理,刪除含有過多缺失值的樣本。利用z-score方法檢測并處理異常值。利用位置匹配整合多個數據集,將地質圖數據和遙感數據合并到一個數據集中。
2.2 特征選擇與工程的應用
根據地質學理論,選取地層厚度、巖性組合、巖石類型及其礦物組成、斷層/褶皺特征以及金屬元素含量等關鍵特征。對選取的特征進行歸一化和標準化處理,以提高模型性能。
2.3 機器學習模型的構建與優化的應用
決策樹的最大深度選取30(max_depth=30),可以做相對復雜的決策路徑;最小樣本分割數選取12(min_samples_split=12),可以防止模型學習到噪聲,降低過擬合風險。
隨機森林中樹的數量選取200(n_estimators=200),以提高模型的穩定性和準確性;最大特征數選取8(max_features=8),即每次分割時從所有特征中隨機選取8個特征來評估最佳分割點,有助于提高模型的多樣性和泛化能力。
支持向量機中的正則化參數選取10(C=10),較大的C值減少了對誤分類的懲罰,使模型更靈活。核函數類型(kernel=‘poly’)選擇多項式核函數,使SVM能夠學習非線性邊界。核函數的選擇對模型的性能至關重要,多項式核適用于存在復雜非線性關系的數據集。在訓練過程中,將總訓練輪數(epoch)設置為50,批次大小(batch_size)設置為256,學習率(learning_rate)設置為1×10-3,損失函數設置為Binary Cross-Entropy(二元交叉熵損失函數),該函數適用于分類問題。
2.4 模型評價與結果
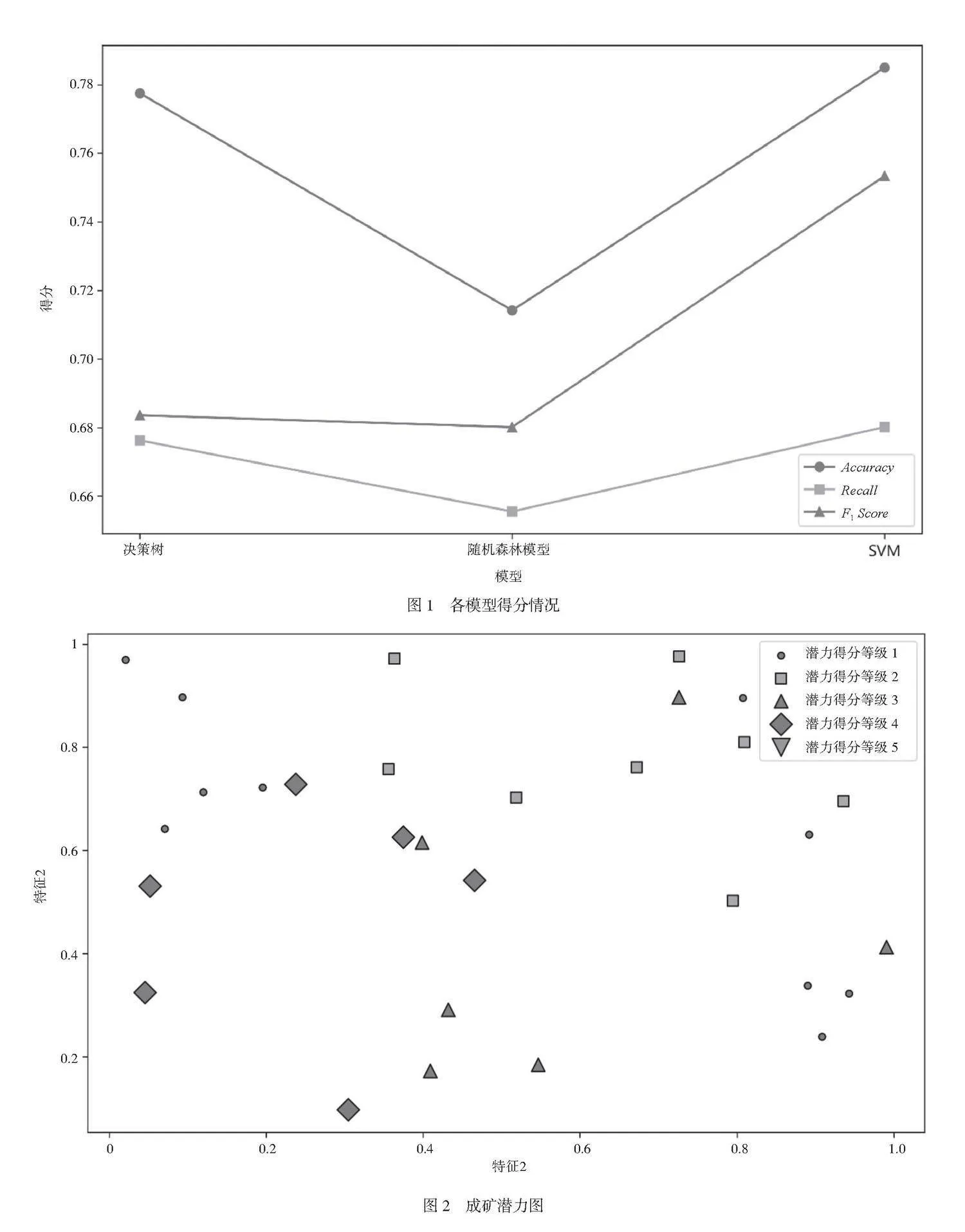
訓練完成后,本文使用測試集對模型進行評估,并記錄精度(Accuracy)、召回率(Recall)和F1值(F1 Score)的性能指標,以確定哪個模型在成礦預測中表現最佳,具體結果如圖1所示。分析圖1可知,隨機森林模型的綜合表現優于其他模型。本文選擇一個具體區域進行成礦預測,并繪制成礦潛力圖,如圖2所示。根據圖2可以快速識別出高潛力區域,從而指導地質勘查的進一步工作。
3 結論
本文探討了地質大數據和機器學習技術在成礦預測中的應用,對數據收集、預處理、特征選擇與工程、模型構建與優化等步驟進行了詳細設計和實施,成功構建了基于決策樹、隨機森林和支持向量機的成礦預測模型,進而對模型性能的評估和比較。結果表明,隨機森林模型在精度、召回率和F1分數等指標上均表現優異,具有較高的預測能力和穩定性。本研究為地質勘查提供了一種新的技術手段,應用地質大數據和機器學習技術,提升了成礦預測的科學性和準確性。
參考文獻
[1]韓世禮,肖健,柳位.機器學習在地球物理勘探中鈾礦資源勘查的應用研究進展[J].鈾礦地質,2024,40(3):555-564.
[2]呼冬強,何福寶,李輝,等.基于隨機森林算法的新疆木吉一帶金礦區域成礦預測[J].新疆地質,2024,42(1):158-163.
[3]郭廣慧,鐘世華,李三忠,等.運用機器學習和鋯石微量元素構建花崗巖成礦潛力判別圖解:以東昆侖祁漫塔格為例[J].西北地質,2023,56(6):57-70.
[4]王堃屹,周永章.粵西龐西垌地區非結構化地質信息機器可讀表達與致礦異常區域智能預測[J].地學前緣,2024,31(4):47-57.
[5]吳巍煒,吳雄輝.基于K-means-RF耦合模型的成礦遠景區預測[J].世界有色金屬,2023(15):91-93.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大地構造與成礦學(2021年5期)2021-10-27 11:15:36
大地構造與成礦學(2021年4期)2021-08-24 05:34:48
大地構造與成礦學(2021年3期)2021-06-29 11:16:24
大地構造與成礦學(2021年2期)2021-05-07 13:57:12
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
