基于Dense Teacher 的半監督雙階段遙感目標檢測方法
2024-12-25 00:00:00李雨秋薛健呂科王泳
無線電工程 2024年12期







摘 要:針對遙感圖像中的有向物體檢測任務,提出了一種基于半監督學習的密集區域卷積神經網絡(Dense RegionConvolutional Neural Network,DRCNN) 框架,以減少對大規模標注數據的依賴并提高檢測精度。在該框架中,利用教師-學生模型通過稠密偽標簽生成與一致性損失進行訓練,結合偽標簽學習與數據擾動,提升模型對無標注數據的有效利用率。針對長尾分布問題,引入了Seesaw Loss 以動態調整各類別權重,進一步優化模型性能。在DOTA 數據集上進行的實驗表明,DRCNN 在1% 、2% 、5% 標注率下的檢測精度AP50 分別較完全監督方法提升了7. 21% 、8. 02% 和2. 84% 。在低標注率條件下,DRCNN 在多個主要類別上表現出顯著的性能優勢,驗證了其在遙感場景下的有效性。
關鍵詞:半監督學習;遙感圖像;有向物體檢測;偽標簽學習;一致性訓練
中圖分類號:TP311 文獻標志碼:A
文章編號:1003-3106(2024)12-2754-11
0 引言
近年來,隨著遙感技術的快速發展,航拍圖像在城市規劃、災害監測和軍事情報等多個領域得到了廣泛應用。然而,遙感圖像中的目標檢測任務,尤其是定向目標檢測,由于目標的復雜形狀、任意角度旋轉及尺度不一致等特性,給傳統的目標檢測方法帶來了巨大的挑戰[1-2]。盡管監督學習在此類任務上取得了一定進展,但其高度依賴大量標注數據,在實際應用中,特別是大規模遙感場景中往往難以實現。標注遙感圖像中的目標既昂貴又費時,這使得半監督學習成為一個極具吸引力的研究方向。
半監督目標檢測(SemiSupervised Object Detection,SSOD)通過結合少量標注數據和大量未標注數據,顯著提升了目標檢測的性能。近年來,SSOD 的研究主要集中在教師-學生框架和偽標簽學習。一些典型方法如STAC[2]通過離線偽標簽生成與學生模型的交替訓練顯著提高了檢測精度。而UnbiasedTeacher[3]采用指數移動平均(Exponential MovingAverage,EMA)[4]與焦點損失(Focal Loss)[5],進一步緩解了偽標簽中的類別不平衡問題。為了提升偽標簽的質量,文獻[6]引入了一致性訓練,并通過減少負樣本的分類權重,針對偽標簽中的漏檢問題提供了有效的解決方案。此外,文獻[7]提出了多視圖尺度不變學習策略,利用特征金字塔對齊和多尺度偽標簽復用,大幅提升了檢測效果。文獻[8]使用教師模型的密集預測作為偽標簽,并通過區域劃分策略充分利用了復雜背景中的難負樣本信息。
針對遙感圖像中的定向目標檢測問題,半監督定向目標檢測(Semisupervised Oriented Object Detection,SOOD)[9]是目前少數嘗試應用半監督學習于此領域的工作之一。SOOD 引入了動態權重調節與特定的旋轉目標損失函數,盡管在一定程度上解決了偽標簽中的目標錯位和漏檢問題,但其對長尾類別的處理能力仍有不足。此外,現有的SSOD 方法普遍在稀有類別目標檢測上表現欠佳,如何在偽標簽生成過程中提高少見目標的精度仍是亟待解決的問題[10]。
為應對上述挑戰,本文提出了密集區域卷積神經網絡(Dense Region Convolutional Neural Network,DRCNN),一種基于稠密偽標簽生成的SSOD 框架。與現有的SSOD 方法大多使用經過非極大值抑制(NonMaximum Suppression,NMS)后的最終檢測結果作為偽標簽不同,DRCNN 通過利用教師模型生成的稠密預測,即尚未經過NMS 等后處理操作的檢測頭輸出結果作為偽標簽,結合區域劃分策略,充分挖掘了無標注數據中的硬負樣本區域,提高了偽標簽的質量。此外,在有監督訓練分支中引入SeesawLoss,有效緩解了長尾分布下類別不均衡的問題,提升了稀有類別的檢測精度[11-13]。實驗結果表明,DRCNN 在多個標準數據集上均優于現有方法,尤其在稀有類別和旋轉目標檢測任務上取得了顯著提升。
本文的主要貢獻包括:① 提出了一種新的稠密偽標簽生成策略,能夠更好地利用無標注數據中的難檢區域;② 通過Seesaw Loss 緩解了遙感圖像中長尾類別的檢測難題;③ 在遙感圖像定向目標檢測領域,通過大量實驗驗證了DRCNN 在多種標注率下的優越性能,證明了該方法在少量標注數據條件下的有效性和魯棒性。
1 教師-學生訓練框架
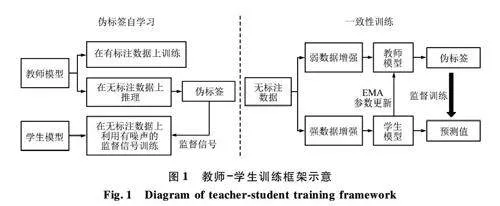
教師-學生訓練框架是一種常用于半監督學習的方法,廣泛應用于目標檢測、圖像分類等任務中。該框架的基本思想是通過2 個模型的協同工作,在有限的標注數據和大量無標注數據上進行高效學習[14]。具體來說,教師模型為學生模型提供偽標簽和監督信號,指導學生模型在未標注數據上的訓練,其框架如圖1 所示。
在教師-學生框架中,教師模型的參數通過對學生模型參數的指數滑動平均進行更新,以確保教師模型具有較強的穩定性和泛化能力[15]。EMA 更新公式如下:
θt = αθt + (1 - α)θs , (1)
式中:θt 表示教師模型的參數,θs 表示學生模型的參數,α 表示平滑系數(通常設置為接近于1),用于逐步融合學生模型的信息到教師模型中。學生模型同時接受來自有標注數據的監督信號,以及無標注數據的偽標簽進行訓練。為提高模型的魯棒性,教師模型和學生模型接收的輸入通常經過不同的數據增強。教師模型的輸入通常只采用弱數據增強,以保持其對輸入數據的基本結構信息;而學生模型的輸入則經過強數據增強,以增加其對噪聲的魯棒性和泛化能力。
半監督學習中的2 個核心原理是偽標簽學習和一致性訓練。偽標簽學習通過教師模型對未標注數據生成偽標簽,并將這些偽標簽作為監督信號,用于指導學生模型的訓練[16]。為提高偽標簽的質量,通常只選擇高置信度的預測作為偽標簽。與此同時,一致性訓練則通過衡量教師模型和學生模型在相同輸入下的預測差異,確保學生模型的輸出與教師模型保持一致,從而逐步提高學生模型的性能[17]。
通過教師-學生訓練框架,學生模型能夠在標注數據有限的情況下,通過教師模型提供的監督信號學習到更多的有用信息,顯著提升模型的檢測性能[18]。
2 DRCNN 方法
2. 1 方法概述
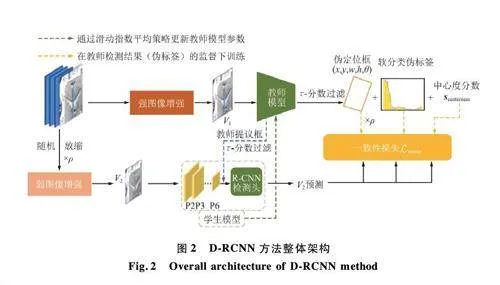
本文提出的DRCNN 方法,旨在結合DenseTeacher 與Faster RCNN 的雙階段目標檢測架構,解決遙感圖像目標檢測中小目標、類不平衡和標注數據稀缺等問題。其整體架構如圖2 所示。
Dense Teacher 方法通過教師模型生成稠密的目標預測結果(稱為稠密偽標簽),這些偽標簽為學生模型提供監督信號,指導其在未標注數據上的訓練。稠密偽標簽包括目標的分類概率、邊界框預測和中心度信息,能夠覆蓋圖像中的不同目標區域。本文采用置信度篩選機制,確保只使用高置信度的前景樣本作為偽標簽,從而減少低質量偽標簽對訓練過程的干擾。與此同時,學生模型在另一條分支上接受來自帶標注數據的監督信息進行有監督訓練。
在訓練過程中,DRCNN 的學生模型通過與教師模型的稠密偽標簽進行對比,計算一致性損失。一致性損失包括三部分:分類一致性、邊界框回歸一致性和中心度一致性。這些損失通過衡量學生模型和教師模型在稠密預測結果上的差異,確保學生模型能夠有效學習教師模型的知識,并逐步優化自身的檢測能力。
2. 2 差異化數據增強策略
在DRCNN 方法中,教師模型與學生模型通過不同的數據增強策略進行訓練。具體而言,教師模型的輸入采用弱數據增強策略,以保留圖像的基本結構信息;而學生模型的輸入則使用了強數據增強策略,以增強其對輸入噪聲和復雜環境的魯棒性。這種增強的區別確保教師模型生成的偽標簽穩定可靠,同時學生模型可以應對更復雜的場景。教師模型的弱增強策略包括圖像的隨機尺寸調整,結合水平和垂直翻轉,以相對較少的變換保留圖像的結構完整性。具體配置如下:
① 隨機調整尺寸:圖像尺寸在1 024 pixel×1 024 pixel與1 500 pixel×1 500 pixel 之間隨機變化。
② 水平和垂直翻轉:以50% 的概率進行水平或垂直翻轉。
學生模型的強增強策略包含更為復雜的變換,除了隨機調整尺寸和翻轉,還包括顏色變換(如隨機顏色調整、隨機對比度調整、隨機亮度調整等)、幾何變換(如隨機旋轉、隨機剪切)以及隨機擦除。這些變換旨在增加訓練過程中對噪聲和場景復雜度的魯棒性。強增強配置的關鍵點如下:
① 隨機調整尺寸:圖像尺寸調整為1 024 pixel×1 024 pixel,學生模型輸入與教師模型輸入之間存在大小為ρ 的放縮率。
② 水平和垂直翻轉:50% 的概率進行水平或垂直翻轉。
③ 顏色變換:應用顏色變換,如隨機顏色調整、隨機對比度調整、隨機亮度調整等。
④ 隨機旋轉:隨機旋轉圖像,角度范圍為(-90°,90°)。
⑤ 隨機擦除:隨機擦除圖像的一部分,模擬噪聲和遮擋情況。
2. 3 稠密偽標簽生成
在DRCNN 方法中,稠密偽標簽是學生模型訓練的重要監督信號。通過教師模型生成的稠密預測結果,稠密偽標簽包括目標的分類概率、邊界框預測和目標的中心度信息。這些偽標簽不僅為標注數據提供了補充,還通過與學生模型的對比學習,促進了學生模型的逐步優化。
然而,由于教師模型和學生模型的輸入經過了不同的數據增強(教師模型使用弱增強,而學生模型使用強增強),二者的空間位置會有所不同。因此,直接使用教師模型生成的區域提議框(RegionProposals)進行監督,可能導致教師模型與學生模型在空間上的不一致。為了解決這個問題,本文設計了一種基于空間變換的機制,以確保教師模型與學生模型的稠密預測值能夠進行一對一映射。
教師模型在區域建議網絡階段生成區域提議框Pt。為了將這些區域提議框投影到學生模型的輸入空間中,必須記錄數據增強過程中教師模型和學生模型之間的空間變換矩陣M。該變換矩陣由數據增強步驟中的幾何變換(如縮放、翻轉和旋轉)計算得到。通過這一矩陣,可以將教師模型的區域提議框映射到學生模型的輸入空間,投影后的區域提議框記作Ps:
Ps = M·Pt, (2)
式中:M 為記錄2 次數據增強之間的變換關系的矩陣,Pt 為教師模型生成的區域提議框,Ps 為投影到學生模型輸入上的區域提議框。通過該投影過程,保證了學生模型可以利用教師模型的區域提議進行進一步的目標檢測和回歸。
完成空間變換后,學生模型的感興趣區域(Region of Interest,RoI)池化層對投影后的區域提議框Ps 進行處理,生成最終的分類預測、邊界框預測和目標中心度預測。此時,教師模型生成的分類預測、邊界框預測和目標中心度預測與學生模型的對應預測值一一對應,同樣,教師模型的稠密預測結果也需要像區域提議框一樣投影到學生模型的輸入空間以得到對齊后的稠密偽標簽,為后續一致性損失的計算奠定基礎。為了進一步提升偽標簽的質量,本文還采用了置信度篩選機制。具體來說,教師模型的輸出結果包括分類分數tcls,根據這些分數選取置信度最高的前景樣本作為偽標簽。只有置信度超過設定閾值的樣本會被保留用于后續的監督學習:
2. 4 一致性損失設計
在DRCNN 的半監督學習框架中,一致性損失是學生模型從教師模型學習的重要機制。通過對教師模型生成的稠密偽標簽進行監督,學生模型的輸出與教師模型的預測保持一致,從而逐步提高模型在未標注數據上的性能。一致性損失主要包括三部分:分類損失、邊界框回歸損失和中心度損失。
① 分類一致性損失:基于教師模型與學生模型在相同區域上的分類概率分布,衡量二者之間的差異。本文的分類損失函數受質量焦點損失(QualityFocal Loss,QFL)[19]的啟發,用于處理遙感圖像中的類不平衡問題。具體而言,QFL 將分類分數與預測質量相結合,計算教師模型與學生模型的分類結果差異。
對于每個樣本i,假設教師模型的分類分數為t(i)cls ,學生模型的分類分數為s(i)cls ,則分類一致性損失的計算公式為:
② 邊界框回歸一致性損失:用于衡量學生模型與教師模型在目標邊界框預測上的差異。通過對教師模型的邊界框偽標簽tbbox 和學生模型的邊界框預測sbbox 進行對比,計算二者在經過空間變換后的區域中的一致性。
邊界框回歸損失采用Smooth L1 損失,結合教師模型的中心度估計作為權重,公式如下:
③ 中心度一致性損失:用于約束學生模型和教師模型在目標中心度估計上的一致性。中心度反映了目標的空間中心性,確保目標的定位準確。中心度一致性損失使用BCE 函數來計算二者的差異:
該損失項確保了學生模型在預測目標的中心度時與教師模型保持一致,進一步提升了目標的定位精度。
總損失:學生模型的總損失由有監督損失Lsup與無監督的一致性損失組成,公式如下:
通過上述一致性損失的設計,DRCNN 能夠充分利用教師模型生成的稠密偽標簽,確保學生模型在分類、邊界框回歸和目標中心度估計上與教師模型保持一致,從而提高其在未標注數據上的檢測性能。
3 實驗與結果分析
3. 1 實驗數據
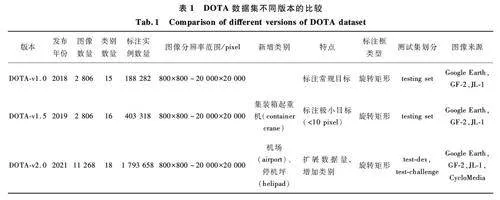
本次實驗主要使用了DOTAv2. 0 數據集[20]。Dataset of Object Detection in Aerial Images(DOTA)是目前遙感目標檢測領域規模最大、應用最廣泛的數據集之一,專為高分辨率遙感圖像中的目標檢測任務設計。DOTA 數據集不同版本的比較如表1 所示。DOTA 數據集自2018 年發布以來,先后經歷了多個版本的更新,從最初的DOTAv1. 0 到最新的DOTAv2. 0,數據量和類別覆蓋范圍逐步增加,現已成為遙感圖像分析領域的標準基準數據集。DOTA數據集為研究者提供了大量來自不同傳感器和平臺的航空圖像,用于發展和評估目標檢測模型。
DOTAv2. 0 版本相較于早期版本,不僅擴展了數據量,還增加了類別。DOTAv2. 0 數據集標注示例如圖3 所示,DOTAv2. 0 包含18 個常見的遙感目標類別,包括飛機(plane)、船只(ship)、儲油罐(storage tank)、棒球場(baseball diamond)、網球場(tennis court)、籃球場(basketball court)、田徑場(ground track field)、港口(harbor)、橋梁(bridge)、大型車輛(large vehicle)、小型車輛(small vehicle)、直升機(helicopter )、環島(roundabout )、足球場(soccer ball field)、游泳池(swimming pool)、集裝箱起重機(container crane)、機場(airport)和停機坪(helipad)。這一版本共有11 268 張圖像和1 793 658 個標注實例,遠遠超過了其上一個版本DOTAv1. 5 的圖像數量和標注數量。
DOTAv2. 0 的數據來源于多種傳感器和平臺,包括Google Earth、GF2 衛星和JL1 衛星,這些圖像既有RGB 圖像,也有灰度圖像,分辨率從800 pixel×800 pixel ~ 20 000 pixel×20 000 pixel 不等。DOTAv2. 0 的圖像涵蓋了各種尺度、方向和形狀的目標,能夠模擬實際遙感應用中的復雜場景。這些目標均由專業遙感圖像專家標注,標注格式采用任意旋轉的四邊形(Oriented Bounding Box,OBB),每個實例由8 個自由度(Degrees of Freedom,DoF)的頂點坐標定義,能夠準確描述物體的方位與形狀[21]。此外,標注文件還包含目標類別和難度等級(difficult)標簽,用于標記檢測難度。
DOTAv2. 0 數據集按任務需要分為訓練集、驗證集、測試集,具體劃分為:訓練集包含1 830 張圖像和268 627 個實例,驗證集包含593 張圖像和81 048 個實例,testdev 集包含2 792 張圖像和353 346 個實例,testchallenge 集包含6 053 張圖像和1 090 637 個實例。為避免模型過擬合,DOTAv2. 0 特別設計了2 個測試集(testdev 和testchallenge),其中testdev提供圖像但不提供標注,更高難度的testchallenge僅在2021 年的挑戰賽期間開放。
DOTAv2. 0 作為一個具有廣泛代表性的遙感數據集,不僅體現在其龐大的數據量上,還因為提供了針對多種復雜場景和類不平衡問題的挑戰,成為當前遙感目標檢測領域評估模型性能的標準基準。
3. 2 實驗設計
為了驗證本文提出的SSOD 方法的有效性,設計了一系列實驗,模擬了標注數據遠少于無標注數據的場景。本實驗基于DOTAv2. 0 數據集,使用雙階段檢測器Rotated Faster RCNN[22]并通過有標注數據與無標注數據的劃分,評估半監督訓練對目標檢測精度的提升。
將DOTAv2. 0 數據集中的訓練集(train set)與驗證集(val set)合并,形成一個新的訓練-驗證集(trainval set)。為了確保模型可以有效學習到小尺度目標,將每張遙感圖像切分為尺寸為1 024 pixel×1 024 pixel 的子圖像。在切分過程中,引入了200 pixel 的重疊部分,以保證目標不會因為切分而被截斷或丟失。通過這種方式處理后的子圖像能夠更好地反映原始圖像中的多尺度和密集目標分布。
得到切分的數據后,對其進行隨機劃分,將其中的一部分作為有標注數據,另一部分去掉標注作為無標注數據。具體而言,設置了3 個標注率,即1% 、2% 、5% ,以模擬不同程度的標注數據稀缺情況。在每個標注率下,對有標注數據和無標注數據進行如下處理:
① 有標注數據:占總數據量的1% 、2% 、5% ,并保持其對應的標注信息,用于有監督訓練。
② 無標注數據:剩余的子圖像被視為無標注數據,即僅保留圖像本身,去掉所有原始標注信息,用于半監督訓練中的偽標簽生成和一致性監督。
為了增加實驗的穩健性,在每個標注率下,進行了10 次隨機劃分(10fold 交叉驗證),在每個折(fold)上進行獨立訓練,并將訓練得到的模型在測試集testdev 上進行評估。每個數據折上對應的AP50 指標取平均值,并計算方差,以得到該標注率下的穩定性能評價指標。
首先,僅利用有標注數據進行有監督訓練,得到模型的檢測性能,作為評價后續半監督方法的基線。其次,引入無標注數據進行半監督訓練。具體而言,通過教師模型生成偽標簽,并在學生模型中計算一致性損失,使模型在無標注數據上學習到更多有用的特征。最終,比較半監督方法相對于基線的檢測精度提升,驗證本文提出方法的有效性。
3. 3 超參數消融實驗
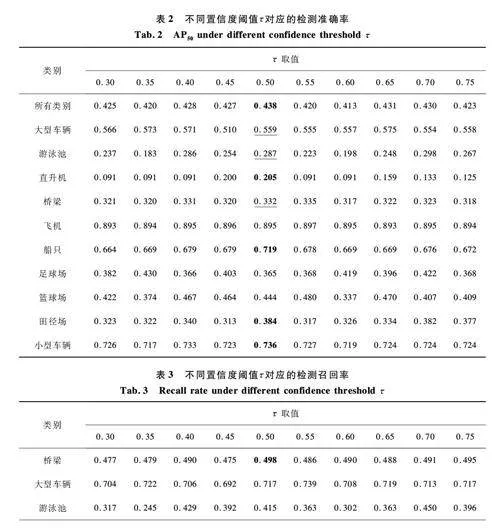
為了確定合適的置信度閾值,進行了超參數消融實驗,實驗目標是在不同值下測試檢測模型的性能,并選擇最優的。為了節省計算資源,本實驗選取了標注率1% 的一個數據折進行訓練,并使用模型在無標注數據部分的測試結果與原有真實標注進行對比分析。實驗評估指標為COCOstyle 的AP50和召回率(Recall)[23]。
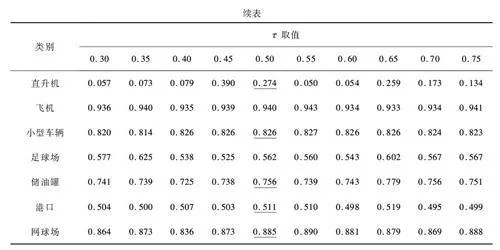
在實驗中, 的取值設置為[0. 3,0. 75],每隔0. 05 取一個值。表2 展示了不同值對應的AP50 ,表3 展示了相同值對應的召回率,其中加粗的數值為同類別中最大值,加下劃線的數值為同類別中次優值。由表2 可以看出,當= 0. 5 時,所有類別的AP50 為0. 438 2,相較于其他值下,整體檢測準確率表現最佳。在部分類別上,如船只(AP50 = 0. 719)和飛機(AP50 = 0. 895), = 0. 5 時的表現處于最佳或接近最佳狀態。同時,雖然大型車輛在=0. 45 時達到最高AP50 =0. 574 9,但=0. 5 時的表現(AP50 =0. 558 5)與其差距不大,依然能保持較高的準確率。此外,游泳池和足球場的表現也接近最優,表明= 0. 5 在多數類別上取得了較好的平衡。
由表3 的召回率結果可以看出, = 0. 5 時,橋梁(Recall = 0. 497 5)、小型車輛(Recall = 0. 825 8)和飛機(Recall = 0. 940 1)等類別的召回率表現達到或接近最優。對于其他類別,雖然= 0. 5 并非所有情況下召回率最高,但其表現與最優值非常接近(如游泳池和大型車輛),因此= 0. 5 可以在保證召回率的同時,取得良好的檢測準確率。
綜合考慮AP50 和召回率2 項指標, = 0. 5 是一個較為合適的置信度閾值。它在整體準確率上取得了最優結果,同時在多數類別的召回率上表現穩定,不會過度損失檢測能力。因此,選擇= 0. 5 作為DRCNN 模型的偽標簽置信度閾值。
3. 4 對比實驗
為了評估DRCNN 方法在半監督遙感目標檢測任務中的表現,并檢驗Seesaw Loss 在處理長尾分布數據集中的效果,設計了4 組對比實驗:
① 僅使用標注數據的有監督訓練,作為全監督基線方法;
② 在①的基礎上引入Seesaw Loss 替代原始交叉熵作為分類損失函數;
③ SSOD 基線方法SOOD;④ 提出的DRCNN 方法。
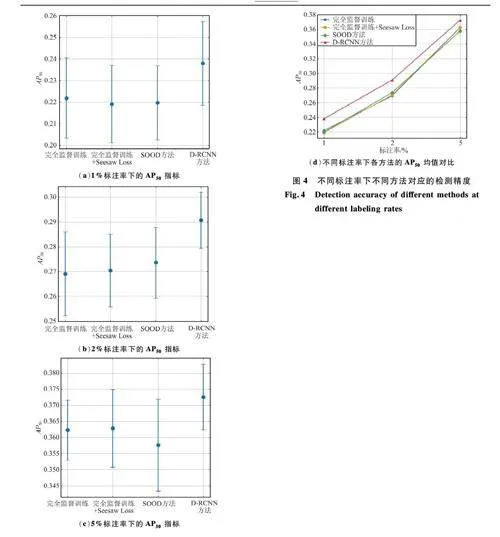
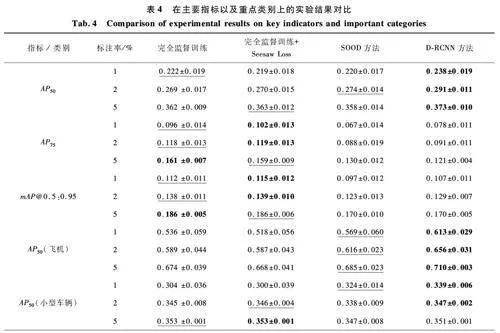
這些實驗在不同的標注率(1% 、2% 、5% )下進行,以COCOstyle 的AP50 為主要評估指標。實驗結果對比如表4 和圖4 所示。
SOOD 方法是一種針對遙感場景中旋轉目標的半監督學習方法,特別適用于具有旋轉特性的目標檢測任務。SOOD 基于半監督偽標簽生成框架,并引入了2 個關鍵損失函數:旋轉感知自適應加權損失(RotationAware Weighted Loss,RAW Loss)和全局一致性損失(Global Consistency Loss,GC Loss)。其中,RAW Loss 通過動態調整旋轉物體的損失權重,提升對多方向物體的檢測效果;GC Loss 則促進了教師模型和學生模型預測結果在全局分布上的一致性,從而提高偽標簽的質量。SOOD 方法在處理旋轉物體檢測任務時具有一定優勢,是本文在半監督訓練范式上的基線方法。
在處理長尾分布問題時,引入了Seesaw Loss 來增強稀有類別的分類能力。在遙感目標檢測數據集DOTAv2. 0 中,常見類別(如飛機、船只)的出現頻率遠高于稀有類別(如直升機、游泳池等)。傳統的交叉熵損失在處理長尾數據時,模型往往傾向于學習常見類別,導致稀有類別的表現較差。SeesawLoss 的設計目標是動態調整正負樣本的損失權重,以平衡類別不平衡帶來的負面影響。其公式如下:
從表4 和圖4 可以明顯看出,本文提出的DRCNN 方法在不同標注率下均表現出較為穩定且顯著的優勢。其中加粗數據為不同方法中最優結果,而加下劃線的數據為次優結果。具體而言,在1% 、2%和5% 標注率下,DRCNN 的AP50 分別為0. 237 9、0. 290 7 和0. 372 6,相較于其他方法均有不同程度的提升。例如,在1% 標注率下,DRCNN 方法比完全監督訓練提升了0. 016,即7. 2% 的增幅;而在5% 標注率下,DRCNN 較SOOD 方法提高了0. 015(4. 2% ),顯示了該方法在低標注率下的優勢。此外,從圖4 (d)可以看出,隨著標注率的提升,DRCNN 方法的優勢愈發明顯,特別是在5% 標注率時,相較于其他方法,提升幅度尤為顯著。
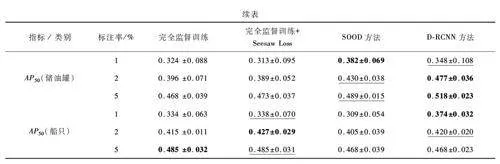
在細粒度的類別分析中,DRCNN 在復雜類別(如“飛機”“小型車輛”“儲油罐”)的檢測表現尤為突出。例如,在1% 標注率下,DRCNN 在“飛機”類別上的AP50 為0. 613 0,顯著優于其他方法;而在“儲油罐”類別中,盡管完全監督訓練加Seesaw Loss方法表現出了一定優勢,但DRCNN 依然能在2%和5% 標注率下分別取得0. 477 0 和0. 517 5 的較好結果,展現了其較強的檢測能力。
總的來說,DRCNN 在不同標注率下均展示出了較好的泛化性和魯棒性,尤其在低標注率場景下,其表現優于傳統方法。引入的密集偽標簽生成策略有效緩解了數據稀缺帶來的挑戰。此外,在自動駕駛、監控、安全等實際應用場景中,DRCNN 通過偽標簽生成策略和自監督學習,提升了模型在低標注數據環境下的魯棒性和準確性。尤其是在這些領域中,標注數據的獲取成本較高,而DRCNN 能夠利用少量的標注數據和大量的未標注數據有效提升目標檢測的性能,展現了其在實際應用中的廣泛適用性。然而,從AP75 和mAP@ 0. 5:0. 95 等更高要求的指標來看,DRCNN 在處理部分類別(如“直升機”和“集裝箱起重機”)時表現仍有提升空間,特別是在精確度要求較高的場景中,未來的改進方向可以著眼于進一步提升高精度檢測的效果。
4 結束語
本文提出的DRCNN 方法,通過稠密偽標簽生成和一致性損失的創新設計,有效提升了遙感圖像中有向物體檢測的性能,特別是在低標注率條件下表現尤為突出。實驗結果表明,該方法在1% 、2%和5% 標注率下,相較于傳統的完全監督方法均顯著提高了檢測精度,尤其是在長尾分布問題嚴重的場景中,引入Seesaw Loss 進一步優化了稀有類別的檢測效果。與現有SSOD 方法(如SOOD)相比,DRCNN 在低標注率下展示出更高的檢測精度,特別是在“飛機”“小型車輛”“儲油罐”等復雜類別中表現尤為優越,驗證了其在多標注率下的廣泛適用性。該方法在自動駕駛、軍事監測和城市規劃等需要處理大量未標注遙感數據的領域具有良好的推廣潛力,實驗數據進一步證明了DRCNN 在復雜場景中的有效性和先進性。然而,Seesaw Loss 在高密度物體檢測或極端長尾數據集下的表現仍有優化空間。未來研究可通過改進Seesaw Loss 適應更復雜的數據分布,并結合動態偽標簽篩選和多尺度數據增強策略,增強模型在高精度檢測場景和復雜環境中的泛化能力,從而推動遙感目標檢測技術在更廣泛應用中的發展。
參考文獻
[1] DING J,XUE N,XIA G S,et al. Object Detection in Aerial Images:A Largescale Benchmark and Challenges[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2021,44(11):7778-7796.
[2] SOHN K,ZHANG Z Z,LI C L,et al. A Simple Semisu pervised Learning Framework for Object Detection [EB /OL]. (2020 - 05 - 10)[2024 - 09 - 09]. https:∥ arxiv.org / abs / 2005. 04757.
[3] LIU Y C,MA C Y,HE Z J,et al. Unbiased Teacher for Semisupervised Object Detection[EB / OL]. (2021 - 02 -18)[2024-08-09]. https:∥arxiv. org / abs/ 2102. 09480.
[4] TARVAINEN A,VALPOLA H. Mean Teachers are Better Role Models: Weightaveraged Consistency Targets Improve Semisupervised Deep Learning Results [C]∥ Proceedings of the 31st International Conference on Neural Information Processing Systems Pages. Long Beach:Curran Associates Inc. ,2017:1195-1204.
[5] LIN T Y,GOYAL P,GIRSHICK R,et al. Focal Loss for Dense Object Detection [C]∥ Proceedings of the IEEE International Conference on Computer Vision. Venice:IEEE,2017:2999-3007.
[6] XU M D,ZHANG Z,HU H,et al. EndtoEnd Semisu pervised Object Detection with Soft Teacher [C]∥ Pro ceedings of the IEEE / CVF International Conference on Computer Vision. Montreal:IEEE,2021:3060-3069.
[7] LI G,LI X,WANG Y J,et al. PseCo:Pseudo Labeling and Consistency Training for Semisupervised Object Detection[C ]∥ European Conference on Computer Vision. TelAviv:Springer,2022:457-472.
[8] ZHOU H Y,GE Z,LIU S T,et al. Dense Teacher:Dense Pseudolabels for Semisupervised Object Detection[C]∥European Conference on Computer Vision. Tel Aviv:Springer,2022:35-50.
[9] HUA W,LIANG D K,LI J Y,et al. SOOD:Towards Semisu pervised Oriented Object Detection[C]∥Proceedings of the IEEE/ CVF Conference on Computer Vision and Pattern Recognition. Vancouver:IEEE,2023:15558-15567.
[10] 王志紅,王煜晟. 面向數據長尾分布的道路目標檢測算法研究[J]. 武漢理工大學學報,2022,44 (10 ):102-108.
[11] WANG J Q,ZHANG W W,ZANG Y H,et al. Seesaw Loss for Longtailed Instance Segmentation[C]∥ Proceedings of the IEEE / CVF Conference on Computer Vision and Pattern Recognition. Nashville:IEEE,2021:9690-9699.
[12] 馮號,黃朝兵,文元橋. 基于改進YOLOv3 的遙感圖像小目標檢測[J]. 計算機應用,2022,42(12):3723-3732.
[13] 劉奕辰. 長尾分布下的深度領域自適應模型泛化性分析與優化研究[D]. 北京:北京郵電大學,2023.
[14] 高玉才,付忠廣,謝玉存,等. 基于指數加權移動平均算法的半監督故障診斷模型[C]∥ 第15 屆全國轉子動力學學術大會(ROTDYN2023). 沈陽:[出版者不詳],2023:162.
[15] 王巖,李少波,張儀宗,等. 數據驅動的無人機異常檢測算法綜述[J]. 無線電工程,2024,54(6):1407-1420.
[16] 劉雅芬,鄭藝峰,江鈴邁,等. 深度半監督學習中偽標簽方法綜述[J]. 計算機科學與探索,2022,16 (6):1279-1290.
[17] 董世超,王愷,李濤. 一種保持多度量空間一致性的多損失聯合訓練方法:CN202010252779. 1 [P ]. 2020 -07-17.
[18] 王嬌,羅四維. 一種半監督協同訓練的正則化算法[J]. 計算機科學,2012,39(7):215-218.
[19] LI X,WANG W H,WU L J,et al. Generalized Focal Loss:Learning Qualified and Distributed Bounding Boxes for Dense Object Detection[C]∥Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver:Curran Associates Inc. ,2020:21002-21012.
[20] XIA G S,DING J,QIAN M,et al. LUAI Challenge 2021 on Learning to Understand Aerial Images [C ] ∥Proceedings of the IEEE / CVF International Conference on Computer Vision. Montreal:IEEE,2021:762-768.
[21] ZAND M,ETEMAD A,GREENSPAN M. Oriented Bounding Boxes for Small and Freely Rotated Objects[J]. IEEE Transactions on Geoscience and Remote Sensing,2021,60:1-15.
[22] YANG S,PEI Z Q,ZHOU F,et al. Rotated Faster RCNN for Oriented Object Detection in Aerial Images[C]∥Pro ceedings of the 2020 3rd International Conference on Robot Systems and Applications. Chengdu:ACM,2020:35-39.
[23] LIN T Y,MAIRE M,BELONGIE S,et al. Microsoft COCO:Common Objects in Context [C ]∥ Computer VisionECCV 2014. Zurich:Springer,2014:740-755.
作者簡介
李雨秋 男,(1998—),博士研究生。主要研究方向:計算機視覺、遙感圖像處理。
薛 健 男,(1979—),博士,教授,博士生導師。主要研究方向:數字圖像處理、科學計算可視化。
(通信作者)呂 科 男,(1971—),博士,教授,博士生導師。主要研究方向:計算機視覺、多媒體信息處理。
王 泳 男,(1975—),博士,講師。主要研究方向:復雜系統建模與優化、模式識別、數據挖掘。
