基于YOLOv5-CBAM 模型的劃痕智能檢測
2024-12-25 00:00:00朱哲維李珂匡璐曹國棟劉紫權史旭陽
無線電工程 2024年12期






摘 要:帶鋼作為現代鋼鐵產業的核心產品,劃痕檢測對于確保產品質量、提升生產效率和降低成本至關重要,廣泛應用于汽車制造、金屬加工、電子產品生產等領域。然而,劃痕形態各異且易受光照、背景和噪聲等因素影響,使得檢測任務極具挑戰性。近年來,隨著空間數據智能技術的不斷進步,基于深度學習的目標檢測算法(如Faster RCNN、SSD、YOLO 等) 在檢測任務中表現出色,通過自動學習、特征檢測和精準目標定位,在復雜背景下也能準確檢測。基于YOLOv5模型進行了算法結構的改進,將空間金字塔池化(Spatial Pyramid Pooling,SPP) 模塊替換為快速空間金字塔池化(SpatialPyramid PoolingFast,SPPF) 模塊,引入注意力機制,改進現有的目標檢測算法,提升劃痕檢測的準確性和魯棒性。結合卷積塊注意力機制模塊(Convolutional Block Attention Module,CBAM) 構建了YOLOv5CBAM 模型。CBAM 通過關注通道和空間維度上的信息,使模型更精準地聚焦于劃痕區域,提升了檢測效果。實驗結果顯示,YOLOv5CBAM 模型在各類交并比(Intersection over Union,IoU) 閾值下相較于YOLOv5,精確率、召回率和mAP @ 0. 5 有著較好的表現,分別提升了5. 6% 、9. 1% 和5. 9% 。隨著空間數據智能技術的不斷進步,未來有望為劃痕檢測提供更多創新思路和解決方案。
關鍵詞:劃痕檢測;YOLOv5;卷積塊注意力機制模塊;模型構建與訓練
中圖分類號:TP315 文獻標志碼:A
文章編號:1003-3106(2024)12-2789-11
0 引言
鋼鐵工業作為國家經濟的基礎支撐產業,不僅是構建現代化強國的重要基石,還扮演著推動綠色低碳發展的角色。帶鋼作為當代鋼鐵工業的核心產出品,伴隨著工業智能制造技術的持續進步,其市場需求正不斷攀升。然而,隨著生產能力的增強,市場對于帶鋼品質的期望也越來越高。熱軋工序在帶鋼制造中扮演著核心角色,被眾多工廠采用。在熱軋帶鋼的生產過程中,表面劃痕的存在與否成為了衡量產品質量的關鍵指標。劃痕等缺陷會顯著降低產品的品質,從而影響熱軋帶鋼質量的整體水平。
從20 世紀70 年代以來,渦流[1]、紅外線[2]等多種檢測方法開始興起。紅外檢測方法是一種以工件瞬態導熱原理為基礎的非破壞性測試手段[3]。從20 世紀90 年代起,人們開始對帶鋼的表面缺陷進行研究,有了一些較成熟的檢測方法。張濤等[4]提出了一種改進的層次分析法,機器視覺技術借助電荷耦合器件(Charge Coupled Device,CCD)相機的廣泛應用,正在逐步取代傳統的帶鋼表面缺陷檢測方法,發展成為識別帶鋼表面缺陷的主要技術手段[4]。在國外,許多企業較早地采用機器視覺技術來檢測帶鋼的表面瑕疵。德國的Parsytec 公司成功研發了一種使用面陣CCD 攝像頭的HTS2 帶鋼表面缺陷檢測系統[5]。Hang 等[6]提出一種基于領域像素灰度閾值的缺陷檢測方法,通過缺陷及其相鄰像素的灰度情況來判斷缺陷類型,獲得了良好的效果。然而,某些缺陷可能會被誤歸為背景,進而造成分類錯誤。為了解決這一問題,提出一種基于背景差分與改進遺傳算法最大熵的軌道表面缺陷分割方法[7]。該方法首先采用改進的列灰度均值背景圖像建模技術對軌道表面圖像進行背景建模,隨后通過計算軌道表面圖像與背景圖像的差分來獲取差分圖像。其次,利用改進遺傳算法的最大熵原理來確定差分圖像的最佳分割閾值,并對其進行二值化處理。最后,對軌道表面的二值圖像進行形態學處理和濾波,從而得到軌道表面缺陷的分割圖像。這一解決方案在帶鋼表面缺陷檢測領域表現出色且相對成熟,至今仍在廣泛應用。在國內,北京科技大學徐科等[8]采用多個面陣CCD 攝像機同步捕獲鋼板表面圖像,并通過構建一個由多臺客戶機與一臺服務器組成的并行計算機系統,成功實現了對鋼板表面部分缺陷的高效檢測。Li 等[9]采用智能漩渦、漏磁記憶檢測儀等技術對曲軸外表面進行無損檢測,但是檢測成本過高且誤差過大,對小目標的檢測效果不佳。上海寶鋼集團攜手東北大學共同研發了一款熱軋鋼板表面缺陷檢測系統,已在寶鋼集團的生產車間中付諸實踐應用[10]。
近期,計算機技術的快速進步使得利用深度學習技術識別帶鋼表面缺陷的圖像成為了研究的熱點。當前,許多關于帶鋼表面缺陷檢測的研究都集中在運用卷積神經網絡(Convolutional NeuralNetwork,CNN)自動進行特征提取和缺陷識別,這種方法省去了手動特征提取的環節,并且通常能夠達到比傳統機器學習技術更優的檢測性能。He 等[11]提出了一套創新的缺陷檢測框架,該框架首先對缺陷圖像進行分類,然后根據不同類別的缺陷使用特定的卷積核來提取特征,最終確定缺陷的位置。雖然這種方法在提高缺陷檢測率方面表現出色,但也帶來了模型復雜性增加的問題。主要分為以SSD[12]、CenterNet[13]、YOLO 系列[14]為代表的單階段網絡,以及以RCNN[15]、Fast RCNN[16]、Faster RCNN[17]和Mask RCNN[18]為代表的兩階段網絡。二者之間的主要區別在于是否存在生成區域候選框的階段。一階段目標檢測算法無需預先生成區域候選框。檢測結果可以通過網絡直接計算,速度很快,但檢測精度可能相對較低。兩階段目標檢測算法過程分為2 個階段。首先,生成候選框,然后根據這些候選框優化檢測點以獲得更高的準確性,但代價是檢測速度較慢。這種方法檢測精度較高,但是檢測速度較慢。其中,在2015 年Joseph Redmon 和AliFarhadi 首次提出YOLO 系列[19]算法,其檢測速度和精度非常平衡,更適合檢測工業缺陷。東北大學的宋克臣教授團隊創新性地引入了生成對抗網絡(Generative Adversarial Network,GAN)應用于帶鋼表面缺陷檢測,采用GAN 技術,有效緩解了帶鋼表面缺陷分類任務中樣本稀缺的問題,通過創建大量的未標記缺陷圖像數據來增強缺陷識別能力[20]。這種方法顯著擴充了缺陷圖像的庫容,盡管如此,GAN 在訓練階段相對繁瑣,且在模擬復雜場景下的缺陷時遇到了一些難題。此外,該團隊還提出了一種名為缺陷檢測網絡(Defect Detection Network,DDN)的網絡架構,該架構是對Faster RCNN 的改進,顯著提高了模型的檢測精度,成功實現了端到端的帶鋼表面缺陷檢測[21]。雖然該模型在檢測精度方面表現優異,但其檢測速度較慢,尚無法滿足實時檢測的需求。季娟娟等[22]提出了一種將注意力機制與YOLOv4 相結合的網絡,該網絡分割模型凸顯出鋼表面缺陷,識別微小的缺陷,但由于只用了空間注意力機制,特征提取能力較差。
針對現有的目標檢測算法仍存在一定的局限性,且對劃痕檢測任務的檢測準確性不高、對復雜背景的魯棒性不強,本文引入了基于YOLOv5 模型,將空間金字塔池化(Spatial Pyramid Pooling,SPP)模塊替換成快速空間金字塔池化(Spatial PyramidPoolingFast,SPPF)模塊,并結合卷積塊注意力機制模塊(Convolutional Block Attention Module,CBAM)構建了YOLOv5CBAM 模型,通過同時關注通道和空間2 個維度的信息,使得模型能夠更加關注劃痕區域,從而提高檢測的準確性。
1 相關理論與技術
1. 1 YOLOv5
在目標檢測領域,基于候選區域的算法曾經是關鍵技術。這種方法主要經歷2 個階段:從大量的候選位置中篩選出最合適的幾個;在這些選定的區域進行對象的識別和位置的精確調整。YOLO 算法則采用不同的策略,通過一個CNN 直接在整幅圖像上識別和定位對象,將目標檢測的任務轉換為一次性的回歸問題,實現了目標類別和位置的同時預測。
YOLO 的亮點在于其快速、實時和高效的性能表現,能夠在速度與精確度之間找到一個優秀的平衡點。YOLO 算法將圖像分割成S×S 的格子,每個格子負責預測對象的類別和位置。這種方法摒棄了傳統的候選區域提取步驟,通過簡化的流程加速了檢測速度。YOLO 檢測系統主要由一個基礎的網絡結構和若干后續的卷積層組成。它常用的基礎網絡,如DarkNet53,是一個事先訓練好的深卷積網絡。后續卷積層的任務是產生目標的邊框和分類標簽。在訓練階段,YOLO 利用交叉熵和均方誤差等多種損失函數來優化模型,在推斷階段,則通過結合框的類別概率和置信度得分來過濾和校正最終的檢測結果。
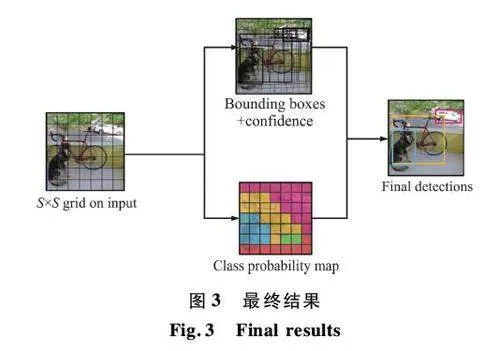
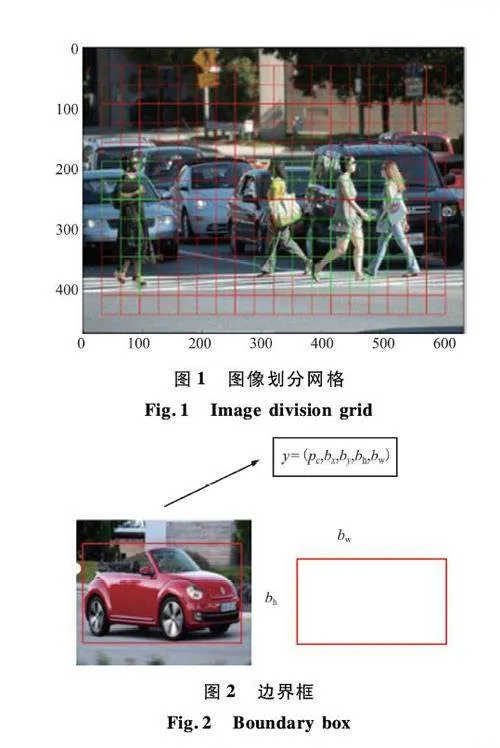
圖像劃分網格如圖1 所示[23]。展示了眾多的三維網格,每個網格都能夠檢測和識別圖中的物體。當物體中心位于某個特定網格內,該網格便啟動檢測程序。通過邊緣條紋技術,圖像中物體的微小細節得以更準確地捕獲。邊界框以其特有的形態和功能而顯著,其寬度(bw )、高度(bh )、類型(如人、車輛、紅綠燈等)以及中心點位置都能被明確地確定。邊界框如圖2 所示,清楚展示了邊界框的示例,使用紅色輪廓來突出顯示邊界框。
YOLO 是一種創新的目標檢測方法,通過將傳統的目標檢測任務簡化為單一的回歸問題,并結合CNN 來進行高效識別,顯著提升了檢測的速度和精度。YOLO 的架構由多個關鍵模塊組成,這些模塊相互配合,共同提升模型性能。首先,YOLO 采用了殘差塊設計,不僅優化了訓練速度,還提高了模型的準確性。其次,在目標檢測過程中,YOLO 通過邊框回歸為每個檢測到的目標預測獨特的邊框,提供包括目標位置和尺寸的關鍵信息。此外,YOLO 使用交并比(Intersection over Union,IoU)來評估預測邊框與真實邊框之間的重合程度,從而驗證預測的準確性。通過這些模塊的整合,YOLO 實現了在復雜場景下高效、準確的目標檢測能力。最終結果如圖3 所示。
圖3 中的圖片被分割成多個網格,每個網格能夠準確地預測出B 個邊框,并為每個邊框分配置信度得分。使用單元模型來識別每個物體的類別,特別關注汽車、狗和自行車等對象。采用多CNN 并行處理不同的預測任務,通過綜合分析來確保預測與實際相符。此方法排除了與目標屬性不相關的邊緣條件,利用精心設計的邊框精確識別物體。圍繞汽車和自行車的是鮮明的色彩邊緣,營造出城堡般的輪廓;而狗則被深藍色的邊框明確標出,這種處理技術有效強調了目標的特征,提升了檢測的精確度和可靠性。
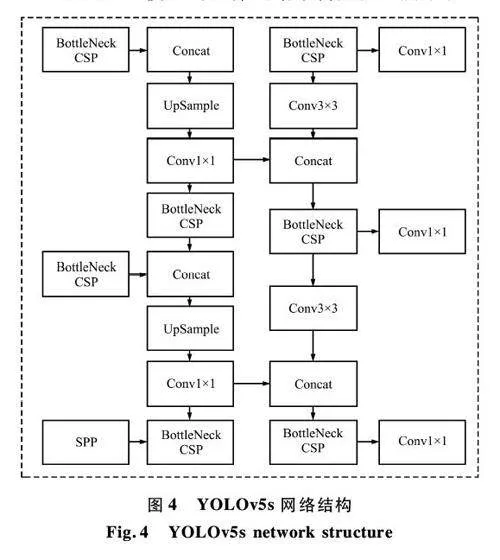
YOLOv5s 模型的整體網絡結構如圖4 所示。
YOLOv5 的架構被劃分為Input、Backbone、Neck 及Prediction 四個關鍵部分。在Input 階段,采用Mosaic數據增強技術對輸入的圖像進行隨機裁剪和合并,旨在提升模型對新場景的適應性。Backbone 階段為特征提取的核心,決定了模型的整體性能。YOLOv5 運用跨階段局部網絡(Cross Stage Partial Network,CSPNet)架構對特征圖進行切割和處理,一部分經過卷積層,另一部分進行下采樣,之后合并這兩部分,增加了對非線性特征的識別能力,改善了模型對復雜環境和多樣目標的檢測效率。在Neck 階段,采用C3 卷積塊進一步融合特征圖。在Prediction 階段,處理后的特征圖被用來精準預測目標的位置和尺寸。
1. 2 CBAM
注意力機制(Attention Mechanism)是機器學習領域內一種廣泛應用的數據處理技術,它覆蓋了自然語言處理、圖像識別、語音識別等多種機器學習任務。這一機制通過賦予不同信息以不同的權重(代表其重要程度),實現對信息的差異化關注。具體而言,注意力機制可被視為由查詢矩陣(Query)、鍵(Key)以及通過計算這些元素得到的加權平均值所構成的多層感知器(Multilayer Perceptron,MLP )結構。
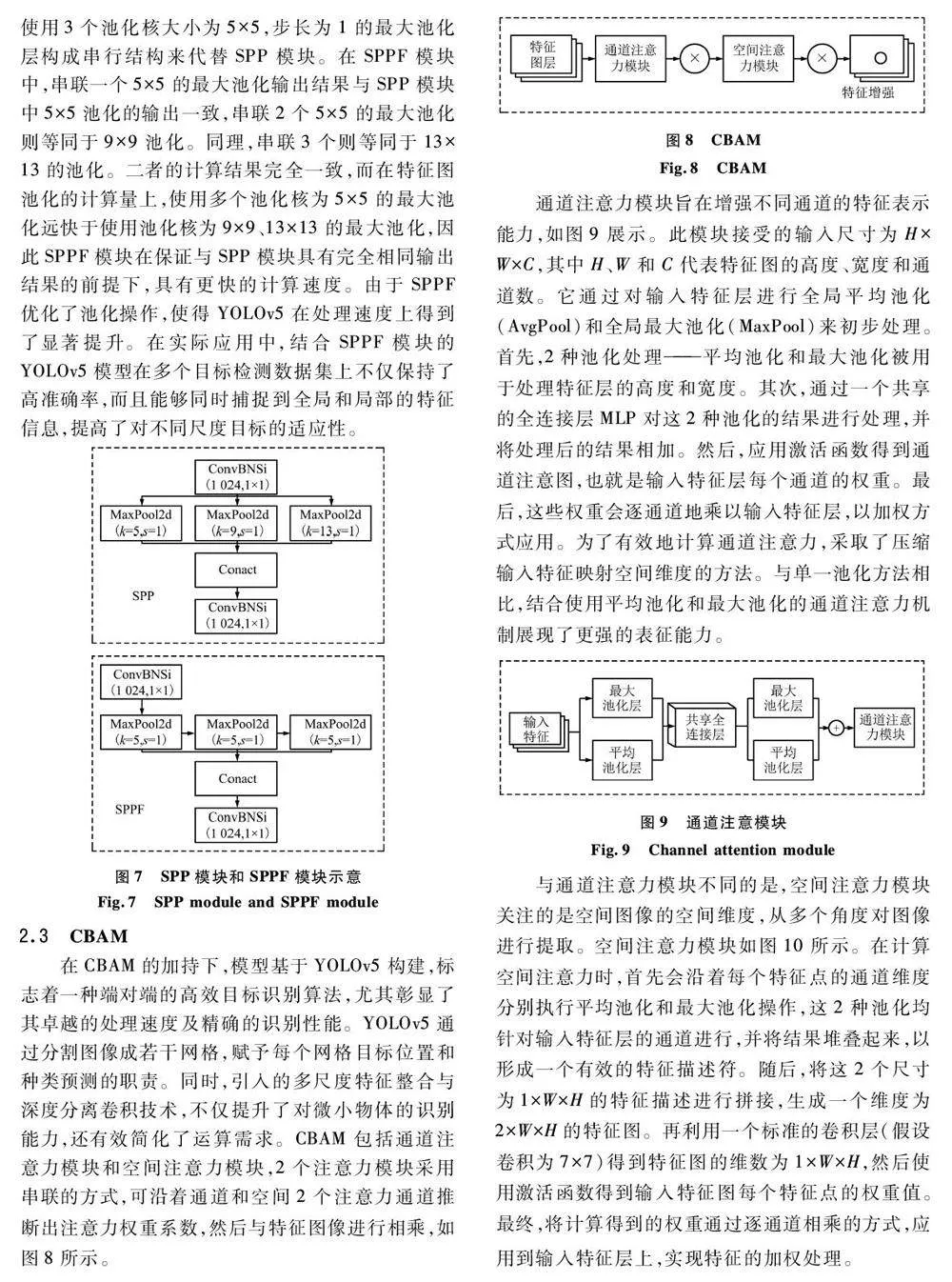
CBAM 是一種旨在提升CNN 性能的注意力機制模塊[24],通過引入通道注意力和空間注意力來提高模型的感知能力,從而在不增加網絡復雜性的情況下改善性能。CBAM 的主要目標是克服傳統CNN 在處理不同尺度、形狀和方向信息時的局限性[25]。為此,CBAM 引入了2 種注意力機制:通道注意力和空間注意力機制。
CBAM 是一種簡單有效的前饋CNN 的注意力模塊,給出一個中間的特征圖,然后CBAM 會按照2 個獨立的維度(通道和空間)依次推導出注意圖示,然后用自適應特征優化乘以輸入特征圖推導出注意圖示,將其與輸入特征圖相乘來推導出注意圖示。經過這2 個注意力模塊的共同作用后,得到最終的注意力增強特征圖,傳遞給網絡的下一層進行進一步處理。這種注意力機制有助于提高網絡在視覺任務上的表現。
CBAM 的應用范圍廣泛,已被應用于各種領域,如目標檢測、圖像分割、圖像分類等。通過引入CBAM,很多模型在各種任務中都取得了顯著的性能提升。
