面向聯合收割機故障領域的命名實體識別研究
2024-12-31 00:00:00楊寧,錢曄,陳健
中國農機化學報 2024年8期




摘要:聯合收割機作為一種機械化設備不可避免地會出現機械故障,為快速地找出并解決機械故障,提出一種面向聯合收割機故障領域的命名實體識別模型RP-TEBC(RoBERTa-wwm-ext+PGD+Transformer-Encoder+BiGRU+CRF)。RP-TEBC使用動態編碼的RoBERTa-wwm-ext預訓練模型作為詞嵌入層,利用自適應Transformer編碼器層融合雙向門控單元(BiGRU)作為上下文編碼器,利用條件隨機場(CRF)作為解碼層,使用維特比算法找出最優的路徑輸出。同時,RP-TEBC模型在詞嵌入層中通過添加一些擾動,生成對抗樣本,經過對模型不斷的訓練優化,可以提高模型整體的魯棒性和泛化性能。結果表明,在構建的聯合收割機故障領域命名實體識別數據集上,相比于基線模型,該模型的準確率、召回率、F1值分別提高1.79%、1.01%、1.46%。
關鍵字:聯合收割機;故障領域;命名實體識別;知識圖譜;預訓練模型;對抗樣本
中圖分類號:S225; TP391.1" " " 文獻標識碼:A" " " 文章編號:2095?5553 (2024) 08?0338?06
Research on named entity recognition for combine harvester fault domain
Yang Ning1, Qian Ye1, 2, Chen Jian1
(1. College of Big Data, Yunnan Agricultural University, Kunming, 650201, China;2. Agricultural Big Data Engineering Research Center of Yunnan Province, Kunming, 650201, China)
Abstract: Combine harvesters as a kind of mechanized equipment will inevitably have mechanical failure, in order to quickly find out the relevant fault entity and solve the mechanical failure, a named entity recognition model RP-TEBC (RoBERTa-wwm-ext+PGD+Transformer-Encoder+BiGRU+CRF) for combine harvester fault field is proposed. RP-TEBC uses the dynamically encoded RoBERTa-wwm-ext pre-trained model as the word embedding layer, uses the adaptive Transformer encoder layer to fuse the Bidirectional Gating Unit (BiGRU) as the context encoder, and finally uses the conditional random field (CRF) as the decoder layer, using the Viterbi algorithm to find the optimal path output. At the same time, the RP-TEBC model generates adversarial samples by adding some perturbations in the word embedding layer. Through continuous training and optimization of the model, the overall robustness and generalization performance of the model can be improved. On the constructed named entity recognition data set in the field of combine harvester faults, experiments have shown that compared with the baseline model, the accuracy, recall rate, and F1 value of this model have increased by 1.79%, 1.01%, and 1.46% respectively.
Keywords: combine harvester; fault domain; named entity recognition; knowledge graph; pre?trained model; adversarial sample
0 引言
近年來,隨著我國農業機械化的不斷發展,聯合收
割機作為一種有效的農作物收割工具得到大量生產和廣泛應用。與聯合收割機維修相關的非結構化文本數據也在持續增長,如何在這些紛繁復雜的數據中高效精準地檢索出所需信息,成為當前要解決的問題。
命名實體識別(NER)作為自然語言處理(NLP)信息抽取領域一項基本任務,近年來得到了廣泛研究,其本質上是在句子中查找實體的開始和結束并為此實體分配類別的任務。隨著深度學習技術的不斷創新和發展,命名實體識別任務也從早期的基于規則和機器學習的方法朝著向深度學習的方法發展,并取得了不錯的成效。Hammerton[1]首次將長短期記憶網絡(LSTM)用于命名實體任務,這也是首次將神經網絡模型用于命名實體識別任務。Collobert等[2]使用CNN-CRF的模型結構達到了和基于統計機器學習方法相媲美的結果。Huang等[3]首次將雙向長短期記憶網絡(BiLSTM)和條件隨機場(CRF)相結合用于命名實體識別任務。在中文命名實體識別領域中,由于中文句子中詞與詞之間連接在一起,不像英語有著天然的空格分割符,所以中文的命名實體識別相較于英文更加困難,因此中文的命名識別任務的首要任務是先分詞,將詞級的命名實體識別模型用于分詞后的句子。但是再好的分詞工具也會出現一些分詞錯誤的現象,這也會導致在進行命名實體識別模型訓練的時候出現實體邊界的檢測和識別類別的預測錯誤的情況,從而影響模型的整體效果。為了解決這個問題,一些直接在字符級別執行中文命名識別的方法開始得到研究,經過相關試驗證明在字符級別執行命名實體識別不僅避免了分詞錯誤對模型的影響,而且模型的效果也得到了提升。Dong等[4]是第一個將基于字符的BiLSTM-CRF神經架構用于中文命名實體識別任務。Ma等[5]將單詞詞典合并到字符表示中,巧妙的結合了詞典的信息,使得模型的穩健性得到進一步提升。受到在計算機視覺中對抗訓練的啟發,相關研究人員也開始在自然語言處理任務加入對抗訓練,來提升模型的泛化能力,Zhou等[6]提出雙對抗轉移網絡(DATNet),通過在詞嵌入層增加噪聲解決了在低資源下的命名實體任務。
目前大多數的命名實體模型都是針對通用領域而設計的,針對特定領域的命名實體識別模型研究較少,有關聯合收割機故障領域的命名實體識別研究還尚未見報道。由于在聯合收割故障診斷方面缺乏相關的數據集,因此本文需自行標注。針對現有的命名實體識別模型,實體識別準確率不高、一詞多義等問題。本文在聯合收割機故障領域方面提出RP-TEBC命名實體識別模型。RP-TEBC模型采用動態編碼的RoBERTa-wwm-ext預訓練模型作為詞嵌入層,能夠很好地解決一詞多義的問題。通過使用自適應Transformer編碼器層融合雙向門控循環單元(BiGRU)可以更好地學習文本中的語義信息。同時,添加對抗訓練有幫助模型提升魯棒性和泛化能力。
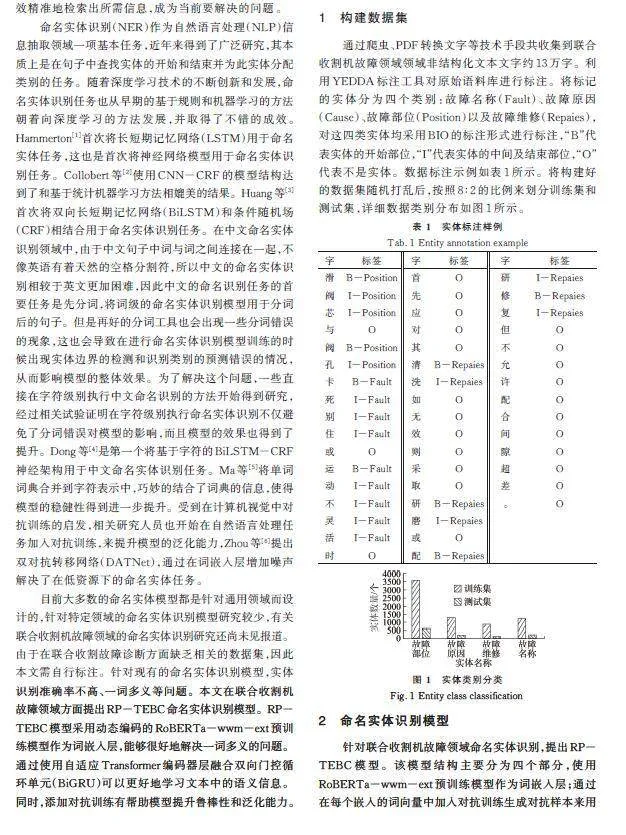
1 構建數據集
通過爬蟲、PDF轉換文字等技術手段共收集到聯合收割機故障領域領域非結構化文本文字約13萬字。利用YEDDA標注工具對原始語料庫進行標注。將標記的實體分為四個類別:故障名稱(Fault)、故障原因(Cause)、故障部位(Position)以及故障維修(Repaies),對這四類實體均采用BIO的標注形式進行標注,“B”代表實體的開始部位,“I”代表實體的中間及結束部位,“O”代表不是實體。數據標注示例如表1所示。將構建好的數據集隨機打亂后,按照8∶2的比例來劃分訓練集和測試集,詳細數據類別分布如圖1所示。
2 命名實體識別模型
針對聯合收割機故障領域命名實體識別,提出RP-TEBC模型。該模型結構主要分為四個部分,使用RoBERTa-wwm-ext預訓練模型作為詞嵌入層;通過在每個嵌入的詞向量中加入對抗訓練生成對抗樣本來用來提升模型的健壯性和泛化性;利用自適應Transformer編碼器融合雙向門控循環單元(BiGRU)作為上下文編碼器;最后使用條件隨機場(CRF)作為預測標簽的輸出層,得到輸入文本中的實體。模型總體結構如圖2所示。
2.1 詞嵌入層
在中文語句中相同的詞語出現在句中不同的位置往往所表達語義會不相同,例如“他用小米手機掃碼付錢在超市買了一袋小米。”中的“小米”在第一次出現的位置表示的意思就是手機品牌,在第二次出現的位置表示的就是糧食名稱。由于Word2vec、GloVe等傳統的詞向量訓練方法其向量表示都是恒定不變的,不能夠跟隨上下文變化而變化,因此很難表達一個詞在不同上下文或不同語境中不同語義信息。針對這個問題Devlin等[7]基于深層的Transformer結構提出了BERT預訓練模型。其在Transformer編碼結構中引入多頭注意力機制來獲取輸入文本的語義信息,運用遮蔽語言模型(MLM)和下一句預測(NSP)的子任務來訓練語料的詞向量表示。在這種表示方法中,詞向量是由當前詞所在的上下文計算獲得,所以相同的詞出現同一句話不同地方,詞向量表示是不相同的,所表達語義也就不相同,BERT預訓練模型整體結構如圖3所示。
從圖3可以看出,模型的輸入是由兩段文本拼接而成,經過BERT的建模獲取到輸出文本的上下文語義表示,最終學習掩碼語言模型和下一句預測。RoBERTa預訓練模型是在BERT模型的基礎改進而來,RoBERTa預訓練模型使用動態掩碼策略和更多樣的訓練數據,在訓練過程中取消了NSP,通過改進使得RoBERTa預訓練模型的性能要比BERT預訓練模型的性能更加出色。RoBERTa-wwm-ext是根據Cui等[8]提出的全詞遮蔽(WWM)策略使用中文數據集重新訓練RoBERTa所得到的一種新的預訓練模型。全詞遮蔽策略是對詞語作遮蔽語言訓練,因為中文的詞語由多個字符組成,直接遮蔽單個字符可能會導致語義信息的丟失。通過使用全詞遮蔽策略,能夠更好地捕捉中文詞語的完整語義,從而提高模型在中文自然語言處理任務中的表現。
2.2 上下文編碼器層
上下文編碼器層的主要構成是自適應Transformer編碼器和雙向門控循環單元(BiGRU)。Transformer編碼器不同于傳統的循環神經網絡(RNN)類型的編碼器,利用多頭注意力機制可以更好地學習到輸入文本的上下文信息,解決了傳統循環神經網絡在學習較長輸入文本時所存在的梯度消失和梯度爆炸的問題。但是傳統的Transformer編碼器在命名實體識別任務中性能表現遠不如在其他自然語言處理任務中的表現,因此本文利用Yan等[9]所提出自適應Transformer編碼器對輸入文本的字符級特征和字級特征進行編碼用于命名實體識別任務。原始的Transformer編碼器中的正弦位置嵌入對距離感知較為敏感,但對方向感知卻不怎么敏感。針對這個問題自適應Transformer編碼器采用了相對位置編碼,并對相對位置編碼進行改進,改進后相對位置編碼不僅使用參數更少而且性能也更好。
考慮到傳統的Transformer編碼器的注意力分布是縮放和平滑的,但是在命名實體識別的任務中并不是所有的詞都需要值得去注意,因此對于命名實體識別任務來說一個稀疏的注意力機制顯然是更加合適的。對此自適應Transformer編碼器使用了一個非縮放和尖銳的注意力機制,計算如式(1)~式(4)所示。
[Q,K,V=HWq,Hdk,HWv]" " " " " " " " " " " " " " " " " (1)
式中:Q,K,V——查詢向量、鍵向量和數值向量;
[Wq]、[Wv]——權重參數;
H——參數矩陣;
[Hdk]——矩陣的運算結果;
[Rt-j=…sin(t-j1 0002i/dk)cos(t-j1 0002i/dk)…T] (2)
式中:[Rt-j]——相對位置編碼,[ Rt-j]∈[Rdk];
t——目標詞的索引;
j——上下文詞的索引;
i——索引變量,范圍為[0,[dk2]]。
[Arelt,j=QtKTj+QtRTt-j+uKTj+vRTt-j] (3)
式中:[Arelt,j]——相對注意力;
[QtKTj]——Qt和Kj標記之間的注意力得分;
[QtKTt-j]——對特定相對距離的偏差;
[uKTj]——對標記的偏差;
[vRTt-j]——特定距離和方向的偏差項。
[Attn(Q,K,V)=softmax(Arelt,j)V] (4)
[Rt,R-t=sin(c0t)cos(c0t)" " " " "?sin(cd2-1t)cos(cd2-1t),-sin(c0t)cos(c0t)" " " " " "?-sin(cd2-1t)cos(cd2-1t)]" " (5)
式中:c0——位置標記。
d——維度。
由于傳統的循環神經網絡(RNN)在時間方向進行反向傳播更新梯度參數時會流經[tanh]節點和矩陣乘積節點。[y=tanh (x)]的導數為[dydx=1-y2],根據其導數可知,當導數的值小于1時,隨著[x]的值在正數方向不斷增加,導數的值是越來越接近于0的,這就意味著如果梯度經過[tanh]節點過多的話,導數的值就會慢慢趨近于0,從而出現梯度消失的現象。一旦出現梯度消失,權重參數將無法進行更新,這也是傳統循環神經網絡無法學習到長時序依賴的主要原因之一。當梯度經過矩陣乘機節點時梯度會隨這時間步的增加呈現出指數級別的增長,當梯度過于龐大時就會出現非數值,導致神經網絡無法進行學習,從而引發梯度爆炸。長短時記憶網絡(LSTM)通過引進輸入門、遺忘門和輸出門在一定程度緩解了傳統循環神經網絡所帶來的問題。LSTM在進行反向傳播時是采用的是對應元素乘積的運算,對應的元素每次都會根據不同的門值進行相應的乘積運算,所以緩解了梯度消失和梯度爆炸的問題。門控循環單元(GRU)是對LSTM進行的一次升級改進,GRU由于只有重置門和更新門,所以計算成本和參數相比與LSTM更少,性能也能和LSTM相媲美。GRU計算圖如圖4所示,計算如式(6)~式(9)所示。
[z=σ(xt1W(z)x+ht1-1W(z)h+b(z))]" "(6)
[r=σ(xt1W(r)x+ht1-1W(r)h+b(r))]" "(7)
[h=tanh(xt1Wx+(r☉ht-1)Wh+b)]" "(8)
[ht=(1-z)☉ht-1+z☉h]" "(9)
式中:z——更新門;
r——重置門;
[h]——隱藏狀態;
[ht1]——時間步t1時刻的隱藏狀態;
[xt1]——時間步t1時刻的輸入;
b——偏置項;
W——權重。
對于命名實體識別任務來說目標詞的詞性不僅和前面的詞相關,后面的詞也會影響著目標詞的詞性。但是無論是傳統的循環神經網絡還是LSTM,GRU信息都是單向流動的,因此只能利用前面詞的信息而利用不到后面詞的信息。為解決這個問題,本文引入了雙向門控循環單元(BiGRU),一層GRU根據輸入文本從頭到尾對文本進行編碼,另一層則從尾到頭對輸入文本進行編碼,這樣便可以同時利用到上下文的信息。BiGRU網絡結構如圖5所示。
自適應Transformer編碼器能夠更好地學習輸入文本的語義信息,雙向門控循環單元可以更好地區分目標詞的上下文信息。通過融合兩個模型的優點對輸入文本進行編碼使之更加適合于命名實體識別任務。
2.3 解碼器層
為了利用不同標簽之間的依賴性,本文使用條件隨機場(CRF)作為RP-TEBC模型的解碼層。條件隨機場是在隱馬爾可夫模型(HMM)和最大熵模型(EM)的基礎提出的,打破了隱馬爾可夫假設使得標簽的預測更加合理,同時也修正了EM模型存在標簽偏差的問題,使其可以做到全局歸一化。給定一個序列[s=[s1,s2,…,sT]]其對應標簽序列為[y=[y1,y2,…,yT]],[Y(s)]代表所有有效標簽的序列,[y]的概率可由式(10)計算。在式(10)中[f(yt-1,yt,s)]是計算[yt-1]到[yt]的轉化分數,來最大化[P(y|s)],使用維特比算法找到最優的標簽路徑輸出。
[P(y|s)=t=1Tef(yt-1,yt,s)y'Y(s)t=1Tef(y't-1,y't,s)] (10)
2.4 對抗訓練
在訓練深度神經網絡模型的時候很容易受到對抗性示例的影響,這些對抗數據很難讓模型和正常數據相區分,從而造成錯誤分類的結果。圍繞對模型的對抗性和魯棒性進行的優化的思路,Madry等[10]提出的PGD(Projected Gradient Descent)對抗訓練算法為解決這個問題提供了很好地幫助。假設考慮一個標準的分類任務的數據分布為[D],數據[x∈Rd],標簽[y∈[k]],損失函數為[L(θ,x,y)],θ為固定的參數,利用經驗風險最小化(ERM)找到模型最優的參數即:[minθE(x,y)~D[L(x,y,θ)]]。但是ERM不會產生對對抗數據具有魯棒性的模型,因此需要來擴充ERM范式。通過對每個數據點[x]引入一組擾動,擾動的大小為[S],利用原始樣本生成對抗樣本,再利用對抗樣本求得期望,這就是著名的[Min-Max]公式,如式(11)所示。[Min-Max]主要有內部損失最大化和外部經驗最小化組成,內部最大化問題的目的是找到給定數據點[x]的對抗樣本,做到最高損失;外部經驗風險最小化是找到模型的最優參數,使對抗性損失最小化。PGD通過“小步幅的走,一點一點靠近”的策略來保證擾動不要太大,如果走出擾動半徑就重新映射會“球面”上,計算如式(12)所示。
[minθρ(θ),whereρ(θ) = E(x,y)~D[maxδ ∈ SL(θ,x +δ,y)]] (11)
[xt+1=x+S(xt+∝sgn(?xL(θ,x,y)))]" " " "(12)
式中:x——原始輸入文本;
[y]——真實的標簽;
[∝]——小步步長;
[θ]——固定參數。
RP-TEBC通過利用PGD對抗訓練算法,在詞嵌入層輸入到上下文編碼器前,通過添加擾動來增加模型的魯棒性和泛化性。
3 試驗與分析
3.1 評估指標
本文試驗中采用精確率P(Precision),召回率R(Recall)和F1(F1-measure)值作為評價指標。精確率是指在預測的結果中預測正確的數量占全部結果的比重,召回率是指在預測正確樣本被找出來的比重。由于召回率和精確率難以平衡,因此引入調和平均F1值,只有精確率和召回率比較高的情況下才能有較高的F1值。P、R、F1計算如式(13)~式(15)所示。
[P=TPTP+FP×100%]" " " " " " " "(13)
[R=TPTP+FN×100%]" " " " " " " " (14)
[F1=2×P×RP+R]" " " " " " " " (15)
式中:P——陽性;
N——陰性;
TP——預測是P,答案果然是P;
FP——預測是P,答案是N,因此是假的P;
FN——預測是N,答案是P,因此是假的N。
3.2 試驗配置
試驗所使用的編程語言為Python3.9,使用一塊NVIDIA 3090顯卡,在CUP型號為Intel(R) Xeon(R) Silver 4210R CPU @ 2.40 GHz,操作系統為Linux的服務器,利用Pytorch1.12.1深度學習框架進行命名實體識別試驗。試驗中所使用的超參數配置如表2所示。
3.3 與其他模型的對比試驗
為了驗證RP-TEBC模型對聯合收割機故障領域命名實體識別的有效性,本文在相同的試驗環境下進行了對比試驗,試驗結果如表3所示。
試驗以目前主流的命名實體識別模型BERT+BiLSTM+CRF為基線模型,從表3中可以看出,RP-TEBC模型相比于基線模型準確率、召回率和F1值分別提高了1.79%、1.01%、1.46%,證明RP-TEBC模型對聯合收割機故障領域命名實體識別的效率均優于傳統的模型。
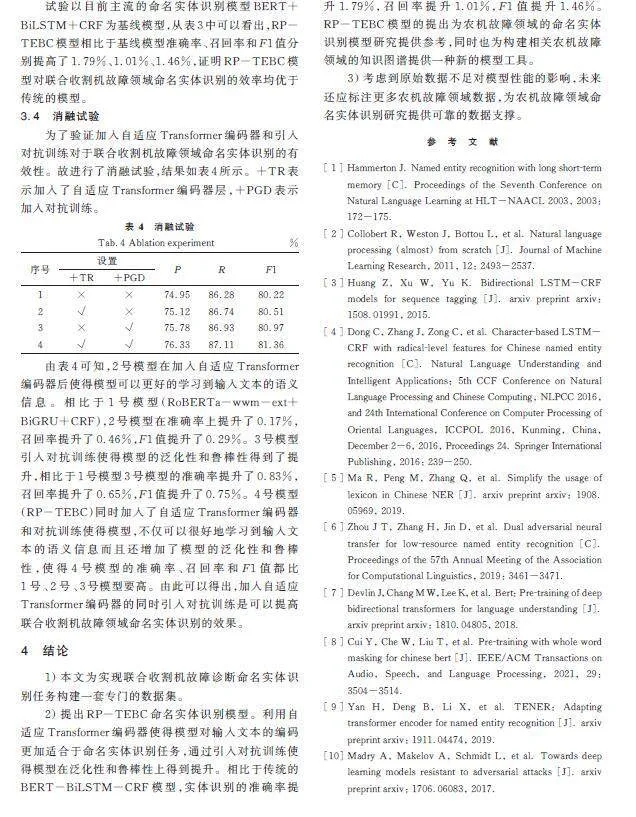
3.4 消融試驗
為了驗證加入自適應Transformer編碼器和引入對抗訓練對于聯合收割機故障領域命名實體識別的有效性。故進行了消融試驗,結果如表4所示。+TR表示加入了自適應Transformer編碼器層,+PGD表示加入對抗訓練。
由表4可知,2號模型在加入自適應Transformer編碼器后使得模型可以更好的學習到輸入文本的語義信息。相比于1號模型(RoBERTa-wwm-ext+BiGRU+CRF),2號模型在準確率上提升了0.17%,召回率提升了0.46%,F1值提升了0.29%。3號模型引入對抗訓練使得模型的泛化性和魯棒性得到了提升,相比于1號模型3號模型的準確率提升了0.83%,召回率提升了0.65%,F1值提升了0.75%。4號模型(RP-TEBC)同時加入了自適應Transformer編碼器和對抗訓練使得模型,不僅可以很好地學習到輸入文本的語義信息而且還增加了模型的泛化性和魯棒性,使得4號模型的準確率、召回率和F1值都比1號、2號、3號模型要高。由此可以得出,加入自適應Transformer編碼器的同時引入對抗訓練是可以提高聯合收割機故障領域命名實體識別的效果。
4 結論
1) 本文為實現聯合收割機故障診斷命名實體識別任務構建一套專門的數據集。
2) 提出RP-TEBC命名實體識別模型。利用自適應Transformer編碼器使得模型對輸入文本的編碼更加適合于命名實體識別任務,通過引入對抗訓練使得模型在泛化性和魯棒性上得到提升。相比于傳統的BERT-BiLSTM-CRF模型,實體識別的準確率提升1.79%,召回率提升1.01%,F1值提升1.46%。RP-TEBC模型的提出為農機故障領域的命名實體識別模型研究提供參考,同時也為構建相關農機故障領域的知識圖譜提供一種新的模型工具。
3) 考慮到原始數據不足對模型性能的影響,未來還應標注更多農機故障領域數據,為農機故障領域命名實體識別研究提供可靠的數據支撐。
參 考 文 獻
[ 1 ] Hammerton J. Named entity recognition with long short?term memory [C]. Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, 2003: 172-175.
[ 2 ] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch [J]. Journal of Machine Learning Research, 2011, 12: 2493-2537.
[ 3 ] Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging [J]. arxiv preprint arxiv: 1508.01991, 2015.
[ 4 ] Dong C, Zhang J, Zong C, et al. Character?based LSTM-CRF with radical?level features for Chinese named entity recognition [C]. Natural Language Understanding and Intelligent Applications: 5th CCF Conference on Natural Language Processing and Chinese Computing, NLPCC 2016, and 24th International Conference on Computer Processing of Oriental Languages, ICCPOL 2016, Kunming, China, December 2-6, 2016, Proceedings 24. Springer International Publishing, 2016: 239-250.
[ 5 ] Ma R, Peng M, Zhang Q, et al. Simplify the usage of lexicon in Chinese NER [J]. arxiv preprint arxiv: 1908. 05969, 2019.
[ 6 ] Zhou J T, Zhang H, Jin D, et al. Dual adversarial neural transfer for low?resource named entity recognition [C]. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019: 3461-3471.
[ 7 ] Devlin J, Chang M W, Lee K, et al. Bert: Pre?training of deep bidirectional transformers for language understanding [J]. arxiv preprint arxiv: 1810.04805, 2018.
[ 8 ] Cui Y, Che W, Liu T, et al. Pre?training with whole word masking for chinese bert [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3504-3514.
[ 9 ] Yan H, Deng B, Li X, et al. TENER: Adapting transformer encoder for named entity recognition [J]. arxiv preprint arxiv: 1911.04474, 2019.
[10] Madry A, Makelov A, Schmidt L, et al. Towards deep learning models resistant to adversarial attacks [J]. arxiv preprint arxiv: 1706.06083, 2017.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
小學教學參考(2015年20期)2016-01-15 08:44:38
汽車維修與保養(2015年6期)2015-04-17 03:31:50
