結合核函數與神經網絡的實體嵌入規范化
2024-12-31 00:00:00謝晟祎?陳新元?陳慶強
信息系統工程 2024年10期


摘要:開放的知識庫缺少本體信息,進一步影響服務下游應用的能力,需對實體進行規范化。傳統相似性度量方法及現有機器學習/深度學習方法泛化能力有待提升。提出結合核函數與神經網絡的規范化表示框架,引入外源輔助信息,與實體嵌入拼接,增強細粒度的維度互動以改善語義識別能力,將相似性得分用于實體聚類。在行業數據集和開放知識圖數據集上驗證框架的實體規范化能力,并進一步開展鏈路預測任務,與基準模型比較以驗證性能。
關鍵詞:知識圖嵌入;實體規范化;實體消歧;行業領域;聚類
一、前言
知識圖是事實集合,以三元組的形式組織知識,在問答系統等領域應用廣泛。三元組可表示為(h,r,t),h,t∈E分別為頭、尾實體,r∈P表示實體之間的關系。現有知識圖缺失事實,許多三元組不完整,缺少實體/關系。知識圖嵌入(Knowledge Graph Embedding,KGE)[1]將三元組嵌入低維向量空間中,應用機器學習技術補全知識圖。實體表示規范化有助于正確識別實體,是知識圖補全/更新的重要任務。
開放知識圖(OpenKG)缺少本體信息支撐,下游應用的性能受到影響,更需要規范化。以在線求職平臺LinkedIn為例,平臺包含大量行業信息,如公司/機構名稱、崗位和技能等,但絕大部分內容為企業/個人用戶提供,缺少統一規范的描述框架,內容變化程度高,如華爾街日報的表示包括“Wall Street Journal”“www.wsj.com”“wsj.com”“WSJ”等,既存在語義相同或相近的縮寫或簡寫,也有“WSJ Online”“WSJ Pro”“WSJ Vacation”等分支下屬機構,分支名中可能覆蓋了“WSJ”。此外,正確識別相關實體還涉及“Wall Stret Journal”拼寫錯誤及領域特定概念等情況。
傳統統計學方法使用靜態模型,通過人工設計規則/特征模式進行實體規范化,在大規模數據集上學習領域特定概念或近似語義的能力較弱。本文提出結合核函數與神經網絡的嵌入表示規范化框架(An Embedding amp; Canonicalization Framework with Kernel Functions and Neural Network,ECF),將外源輔助信息與實體的嵌入表示拼接,通過元素積和范式距離等方式增強不同維度上的信息互動,進一步在神經網絡中使用核函數將數據映射到高維特征空間,發掘細粒度[2]的語義相似性用于聚類相同實體,在行業數據集和開放知識圖上驗證框架的相似性識別能力,并進一步執行鏈路預測任務,與基準模型進行比較。
二、相關研究
KGE將實體/關系表示嵌入低維向量空間[3],可分為基于平移/旋轉的模型和基于語義的模型,前者如TransE[1],認為若三元組成立,則頭實體經關系平移后靠近尾實體,即vh+vr≈vt,vh,vr,vt分別表示頭/尾實體和關系。后續模型如TransH(用超平面wr取代關系向量),TransR(使用投影矩陣Wr替換超平面wr)以及TransD、STransE和TranSparse等[4]。語義模型關注實體間的語義相似性,經典模型如RESCAL、DistMult和ComplEx等。近年,神經網絡模型在KGE中得到廣泛應用。
傳統規范化方法借助人工定義的特征空間,對于相似性的識別能力有限。Han等[5]和Vashishth等[6]結合嵌入模型的思路,借助外部輔助信息對實體和關系進行聯合處理,但受稀疏性、噪聲和領域特定上下文信息缺失等因素影響,圖模型在對實體進行無監督聚類時性能欠佳。因此,本文利用Wikidata和必應搜索接口補充領域特定的上下文信息。
Yan等[7]設計了基于二分法的公司名稱規范化方法,將公司的完整文本介紹作為輔助信息,在LinkedIn社交圖數據集上驗證,但對于缺少信息的新公司實體學習能力較弱。上述研究未能徹底解決模型泛化能力較弱的問題。ECF框架嘗試將文本描述與實體嵌入拼接,通過元素積、范式距離等方式增強向量在不同緯度上的互動,從而提取細粒度的語義信息。
此外,基于核函數的模型將數據映射到高維特征空間,從而實現非線性數據的線性可分,在身份檢測、遷移學習和分類等任務中應用廣泛。本文利用核函數計算開銷低,學習能力強的優點,將其與神經網絡結合,進一步捕捉潛在語義關系。聚合層次聚類(Hierarchical Agglomerative Clustering,HAC)被廣泛應用于規范化任務,本文參考這一思路,并應用嵌入拼接、增強互動和引入核函數等方法提升自動聚類的準確性。
三、ECF
本文核心任務是利用外部輔助信息判定實體間相似性,即對于實體的嵌入表示e1,e2∈E,其輔助信息分別為s1,s2∈S,目標是找到fsimilarity(e1,e2,s1,s2),進一步在此基礎上為所有實體對生成相似性矩陣,并應用聚類算法找到特定實體所對應的向量簇,實現規范化。
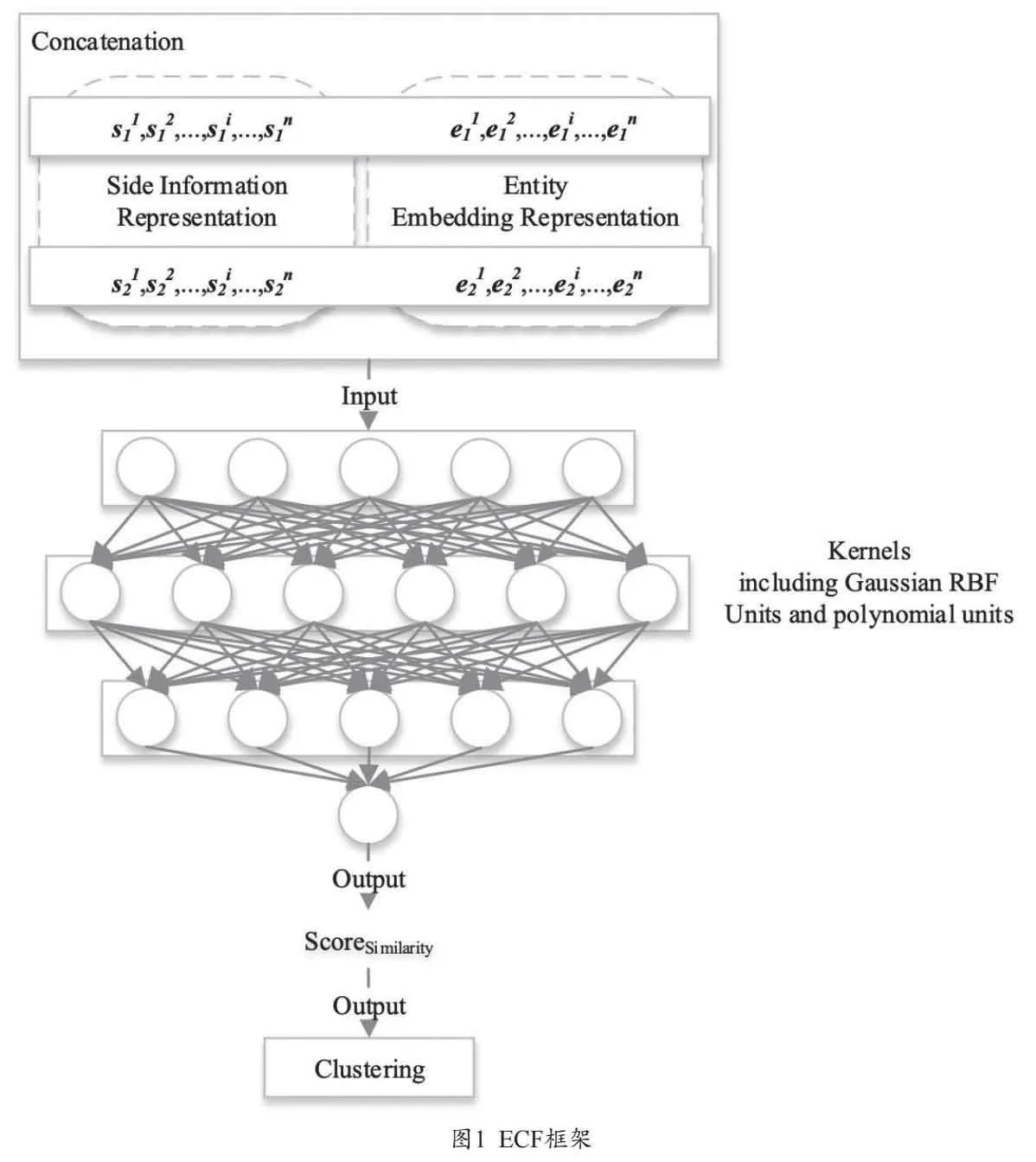
本文框架如圖1所示,生成實體嵌入表示和外源輔助信息的嵌入表示后,拼接作為核函數神經網絡的輸入,獲得實體對的相似度得分,進一步用于后續聚類。
CaRe使用GloVE[8]的預訓練嵌入表示,但未能解決實體類型兼容性問題。Jain等[9]和Xie等[10]分別引入多向量關系映射和層次類型結構進行改進,但都依賴知識庫的本體信息。考慮到在開放知識圖上的應用,ECF框架采用distilled S-BERT模型的預訓練結果以保證類型兼容性。為每一對候選實體(e1,e2)生成m維向量的上下文嵌入表示。
借助Wikidata和必應(Bing.com)檢索接口獲取外源輔助信息。Wiki信息可分為企業簇(C)、機構簇(I)、技能簇(S)和職位簇(D)。必應接口用于獲取實體的文本描述,公司描述包括性質、位置、類型、董事等,如“Jeff Bezos founded Amazon from his garage in Bellevue, Washington, on July 5, 1994. It started as an online marketplace for books but expanded to sell ... ”,同樣使用預訓練的distilled S-BERT模型為每個實體生成n維向量s,與對應實體嵌入拼接,表示為ir=s⊙e,其中⊙為向量/矩陣拼接,ir為m+n維向量。進一步處理得到Inp=|ir1-ir2 |p⊙(ir1·ir2),其中p=1或p=2,|ir1-ir2 |p表示實體對拼接表示的向量距離,·表示元素積(element-wise product)。Inp為2×(m+n)維向量,作為神經網絡的輸入單位,維度根據輪廓系數(silhouette index)[11]確定。神經網絡中包括多項式核和高斯徑向基核,逐維度處理向量的元素積和向量L1/L2距離,在細粒度級別上學習實體對間的非線性關系和對稱表示,從而提升泛化能力。神經網絡使用ReLU函數輸出,設置正則懲罰避免梯度消失,采用隨機失活策略。設定核數為Inp維度的整數倍。近似性可被視作實體對屬于同一概念的概率。在得到所有實體對概率得分和近似性矩陣的基礎上應用聚合層次聚類,將單一概念映射為矩陣。
四、實驗與分析
(一)實體相似性識別
行業數據集來源為LinkedIn,包括2864個企業簇(C)、2259個機構簇(I)、165個技能簇(S)和762個職位簇(D),人工標定,指標一致性系數0.87。樣本中去除非ASCII字符。為平衡樣本分布,以實體對為單位生成負樣本。開放知識圖數據集包括ESCO和DBpedia,ESCO(S)和ESCO(D)分別表示技能和職位,前者包括2644個實體簇和35554個實體對,后者包括2903個實體簇和62969個實體對。DBpedia(C)通過檢索公司名稱提取,包括2949個實體簇和182511個實體對。訓練集/測試集劃分為80%-20%。使用準確率(Precision)和F1得分衡量模型表現。
將本文模型與Distilled S-BERT+cosine、CharBiLSTM+A、WordBiLSTM+A以及CharBiLSTM+A+Word+A進行比較。Distilled S-BERT+cosine使用相同的預訓練模型進行嵌入表示,但計算余弦相似度,且沒有外源輔助信息支持。CharBiLSTM+A使用字符嵌入作為雙向LSTM網絡的輸入,結合注意力機制。WordBiLSTM+A使用詞級輸入,其他設置相同。CharBiLSTM+A+Word+A綜合了上述2種模型的架構。
使用Adam優化器和交叉熵損失函數,模型失活率dropout rate設為0.2,learning rate l∈{0.001,0.005,0.01,0.05},dimensionality m,n∈{128,256,512,1024},batch size s∈{512,1024,2048},使用Grid Search網格搜索發現最優組合,在行業數據集上為{l=0.005,m=n=256,s=1024},在ESCO上{l=0.01,m=n=256,s=1024},在DBpedia上{l=0.001,m=n=512,s=1024}。最大迭代訓練輪數epochs設置為3000,但10輪MRR提升lt;0.01時停止。其他模型盡可能尊重原研究的最優參數設置。
近似性識別結果見表1,可見ECF框架在所有指標上相比主流模型都有一定提升。Distilled S-BERT + cosine模型的得分普遍偏低,應為缺少外源輔助信息導致部分實體變化識別能力較弱,如“Wall Street Journal”和“WSJ”的相似性得分僅為0.59,ECF得分為0.93,說明上述文本在語義空間中實現了有效的非線性映射。對于“www.wsj.com”和“WSJ”,Distilled S-BERT + cosine得分0.84,說明該模型具備一定的學習字符重疊結構信息的能力,ECF得分更高為0.96。所有模型在部分重疊的實體文本上都表現較好。在開放數據集上,Distilled S-BERT + cosine得分相比行業數據集有明顯降低,進一步說明了外源輔助信息的重要性。對于領域特定的概念,如近義詞組“State Protocol Development”和“REST Developer”,在外源輔助信息的支持下,BiLSTM系列模型和ECF表現都較穩定(gt;0.85),但是移除外源信息嵌入后,都有一定程度的性能下降,可能是因為“State Protocol”的嵌入表示與“REST”存在較大差異。
ECF相比CharBiLSTM + A + Word + A,由于引入核函數神經網絡加強了實體互動,語義提取的能力有所提升。CharBiLSTM + A + Word + A相比僅使用詞級嵌入或字符級嵌入表現也較好。詞級嵌入整體上性能表現優于字符級嵌入(plt;0.01),說明前者能更好地提取語義信息。但是,對于拼寫錯誤,如“Wall Stret Journal”和“WSJ”,詞級嵌入僅給出了0.67的近似度得分,字符級嵌入卻達到了0.91,CharBiLSTM + A + Word + A 0.89,ECF 0.90,說明ECF對于該類文本的識別能力接近逐字符匹配的模型,規范化能力較強。
(二)鏈路預測
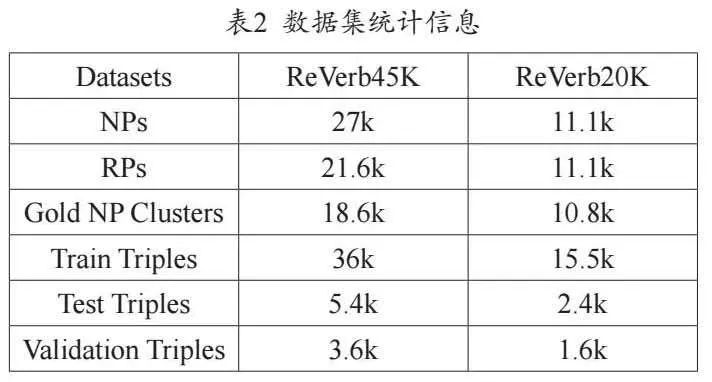
進一步在開放數據集ReVerb45K和ReVerb20K上進行鏈路預測,該任務在給定頭/尾實體和關系的前提下預測缺失實體,對候選集合進行排序。上述數據集來自開放知識庫ReVerb,統計信息見表2,NP和RP分別表示三元組的實體和關系。可見數據集的NP/RP分布稀疏,在此類數據集上的鏈路預測更符合真實世界的場景設置。訓練集/測試集劃分、負例生成與實驗設置與CaRe[8]相同。使用平均排名(Mean Rank,MR)、平均倒數排名(Mean Reciprocal Rank, MRR)、排名在第1位的有效實體的比例(Hits@1)以及Hits@3、Hits@10作為評估指標。
將ECF框架與TransE、ConvE、CaRe(圖卷積網絡GCN的引入有可能導致性能下滑,故采用ConvE方案)和OKGIT等基準模型比較,鏈路預測結果見表3。ECF的表現明顯優于CaRe,可見ECF的規范化能力有一定提升。在ReVerb20K數據集上,ECF相比CaRe優勢更大,而OKGIT的整體表現略優于ECF,說明ECF框架使用的預訓練嵌入能有效保證類型兼容性,而類型映射和隱式類型得分可能有助于進一步提升,改進模型在開放數據集上的表現,將其作為未來的工作方向之一。基于平移的TransE模型和基于神經網絡語義提取模型ConvE在稀疏開放數據集上表現欠佳。
五、結語
缺少本體信息的開放數據集存在大量噪聲,為實現實體規范化,將實體嵌入與外源輔助信息結合,使用結合核函數與神經網絡嵌入的方法實現細粒度的非線性特征提取和聚合層次聚類,規范實體表示并將其應用于行業數據集和開放數據集上,近似性識別和鏈路預測任務驗證了方案可行性。未來計劃設計關系規范化并與ECF框架集成,以及改進模型在外源輔助信息較少時的規范化能力。
參考文獻
[1]張天成,田雪,孫相會,等.知識圖譜嵌入技術研究綜述[J].軟件學報,2023,34(01):277-311.
[2]Pavlick E, Rastogi P, Ganitkevitch J, et al. PPDB 2.0: Better paraphrase ranking, fine-grained entailment relations, word embeddings, and style classification[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). 2015: 425-430.
[3]Nickel M, Rosasco L, Poggio T. Holographic embeddings of knowledge graphs[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2016, 30(1): 17-25.
[4]金婧,萬懷宇,林友芳.融合實體類別信息的知識圖譜表示學習[J].計算機工程,2021,47(04):77-83.
[5] Han X, Sun L, Zhao J. Collective entity linking in web text: a graph-based method[C]//Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. 2011: 765-774.
[6] Vashishth S, Jain P, Talukdar P. Cesi: Canonicalizing open knowledge bases using embeddings and side information[C]//Proceedings of the 2018 World Wide Web Conference. 2018: 1317-1327.
[7] Yan B, Bajaj L, Bhasin A. Entity resolution using social graphs for business applications[C]//2011 International Conference on Advances in Social Networks Analysis and Mining. IEEE, 2011: 220-227.
[8] Pennington J, Socher R, Manning C D. Glove: Global vectors for word representation[C]//Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014: 1532-1543.
[9] Jain P, Kumar P, Chakrabarti S. Type-sensitive knowledge base inference without explicit type supervision[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018: 75-80.
[10] Xie R, Liu Z, Sun M. Representation Learning of Knowledge Graphs with Hierarchical Types[C]// IJCAI. 2016: 2965-2971.
[11] Starczewski A, Krzy?ak A. Performance evaluation of the silhouette index[C]//International conference on artificial intelligence and soft computing. Springer, Cham, 2015: 49-58.
基金項目:1.福建省教育科學“十三五”規劃 2020 年度課題(項目編號:FJJKCG20-402);2.福建省中青年教師科技類教育科研項目(項目編號:JAT210619)
作者單位:謝晟祎,福建農業職業技術學院;陳新元,福州工商學院;陳慶強,福建理工大學
■ 責任編輯:王穎振、楊惠娟
