面向對抗干擾的小樣本人臉識別算法研究
2025-02-23 00:00:00王一波楊玉華婁伯韜張勝利
物聯網技術 2025年4期
關鍵詞:人臉識別


摘 要:由于目前的人臉識別算法在樣本不足且有對抗干擾的人臉識別應用場景中存在局限性,提出一種基于對稱網絡的識別算法。首先基于小樣本進行對稱網絡訓練,以獲得樣本的特征向量,確保同類樣本特征向量距離近,異類樣本特征向量距離遠;然后基于樣本特征向量訓練SVM分類器,以進行人臉檢測;同時引入PGD攻擊算法,通過對抗攻擊獲得對抗樣本,基于對抗樣本進行模型訓練,提升模型的魯棒性。在ORL數據集上進行實驗,結果表明,該面向對抗干擾的小樣本人臉識別算法準確率較高,優于傳統單邊CNN模型的效果,能夠實現樣本不足且有對抗干擾的人臉識別。
關鍵詞:對稱網絡;小樣本;人臉識別;對抗干擾;PGD攻擊算法;支持向量機
中圖分類號:TP39 文獻標識碼:A 文章編號:2095-1302(2025)04-00-04
0 引 言
人臉識別目前已得到廣泛的使用。如何不斷提升算法的準確率和魯棒性仍然是模式識別及機器視覺領域研究的熱點。該算法的基本原理:將二維或者三維的人臉圖像通過某種方法進行簡化的特征表達,然后運用相關分類算法對其進行類別劃分。如果從特征抽取角度來看,人臉識別主要包括人工設計特征與深度學習自動表示特征2種技術路線。2種路線各有優勢,其中前者屬于傳統的方法。目前仍有許多研究人員力求通過把握人臉的本質特性,設計出能夠魯棒表達人臉的簡潔特征。文獻[1]較好地融合了降維和稀疏描述的優勢,達到了對人臉特征降維的目的。文獻[2]通過改進局部二值模式(Local Binary Patterns, LBP),在不同灰度層內提取人臉的LBP 特征,再通過加權融合實現復雜光照下的人臉識別。文獻[3]提出了新的Face Relighting方法,即對多種陰影進行建模,同時保留局部人臉細節。文獻[4]提出了一種用于面部模板保護的模塊化體系架構,可以與使用角距離度量的任何面部表情識別系統結合使用。
人工設計特征費時費力,需要研究人員具有高度的敏銳性,而隨著深度學習技術的不斷發展,借助深度模型無監督獲取特征表示,越來越受到研究人員的青睞。目前廣泛使用的單階段人臉識別深度框架有YOLO、SSD[5-6],兩階段人臉識別框架(即特征抽取和目標檢測)有R-CNN、FastR-CNN[7-8]。之后在以上模型的基礎上,通過不斷改進,基于深度學習的人臉識別算法的性能也得到不斷提升,但其優越的性能建立在不斷龐大的數據集和不斷擴充的網絡深度基礎上,對于難以得到大量數據以及需要輕量化部署的場合并不適用。同時,人臉識別在很多應用場景中對于容錯性要求非常高,但在實際生產中,由于圖像采集時的燈光、鏡頭、圖像傳輸等多種設備的影響,可能采集到對抗樣本[9-10]。根據正常圖像分類梯度信息,將對抗攻擊算法生成的對抗擾動疊加在正常圖像上可以形成對抗樣本,導致深度網絡錯誤地推理對抗樣本的類別。所以如何基于小樣本實現具有一定抗攻擊能力的人臉識別算法成為當下重要的研究課題。
本文將構建小規模的孿生卷積,對小樣本進行訓練,學習穩定的人臉特征,同時引入攻擊算法,提升人臉識別的魯棒性。
1 算法基本原理
1.1 對稱網絡特征提取的基本原理
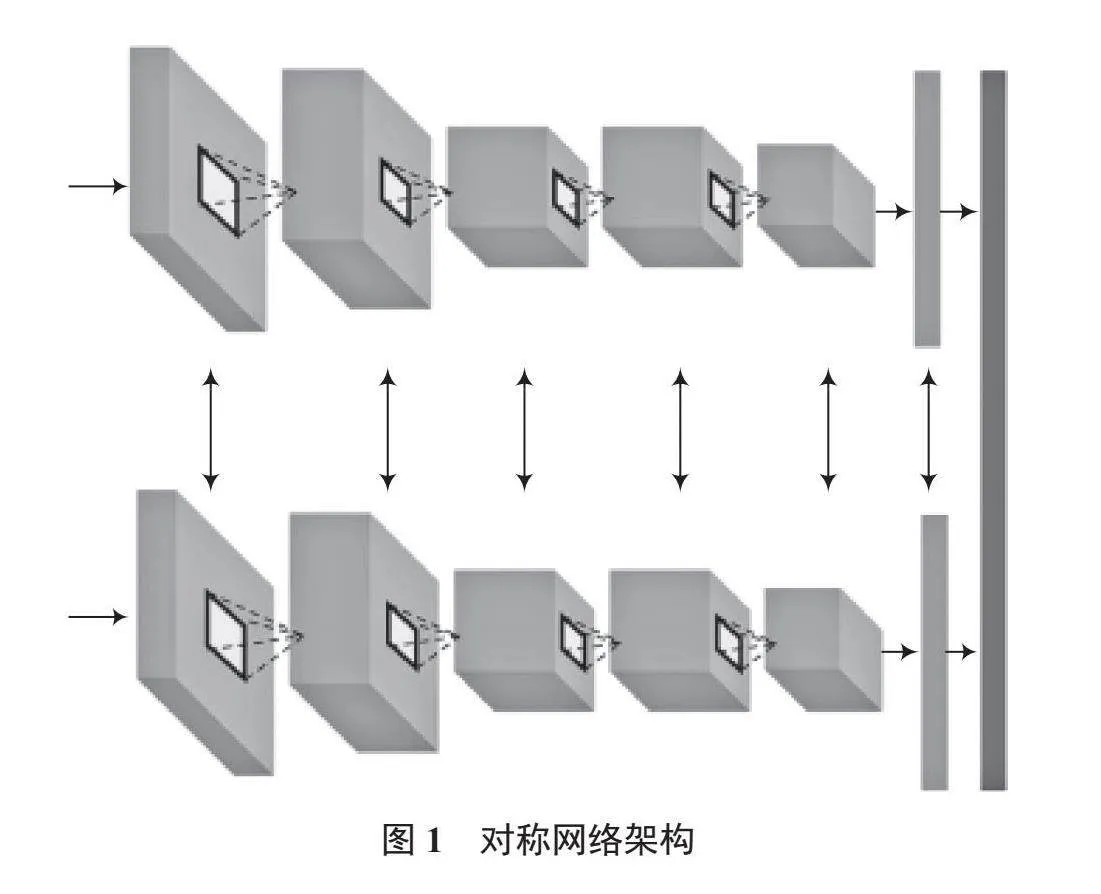
對稱網絡是一種特殊的神經網絡架構,由2個或更多相同的子網絡組成,如圖1所示。每個子網絡接收1個輸入并提取出對應的特征向量,然后通過度量層計算這些特征向量之間的相似性得分,在訓練過程中,使用對比損失或三元組損失等損失函數,最小化相似輸入對的特征距離,最大化不相似輸入對的特征距離,從而自動學習輸入之間的相似度度量[11]。子網絡通常由卷積層、池化層、全連接層等構成。對于每個輸入,子網絡會提取出一個特征向量。在訓練過程中,孿生網絡的子網絡會共享權重參數,反向傳播算法更新這些共享參數,使得相似輸入對的特征向量距離最小化,不相似對的特征向量距離最大化。
1.2 PGD攻擊的基本原理
PGD(Projected Gradient Descent)對抗攻擊為FGSM(Fast Gradient Sign Method)的一種迭代改進。核心思想為通過多次迭代來逐步逼近最優的對抗樣本,同時每次迭代都根據當前樣本的梯度信息來更新樣本,并將更新后的樣本裁剪到規定的范圍內。具體過程如下:
(1)初始化一個被添加對抗擾動的樣本;
(2)計算損失函數的梯度;
(3)計算擾動;
(4)添加并將擾動約束在鄰域內,得到對抗樣本;
(5)將對抗樣本輸入模型,計算新的損失函數,重復步驟(2)~步驟(4),多次迭代。
與FGSM相比,PGD攻擊通過多次迭代和裁剪操作,能夠更精確地找到誤導目標模型的對抗樣本。同時,由于PGD攻擊在每次迭代中都會根據最新的梯度信息來更新樣本,因此它對于非線性模型具有更好的攻擊效果。這是因為對于非線性模型,僅僅進行一次迭代可能無法找到最優的對抗方向,而多次迭代則能夠逐步逼近最優解。
2 基于對稱網絡的識別算法
2.1 網絡結構
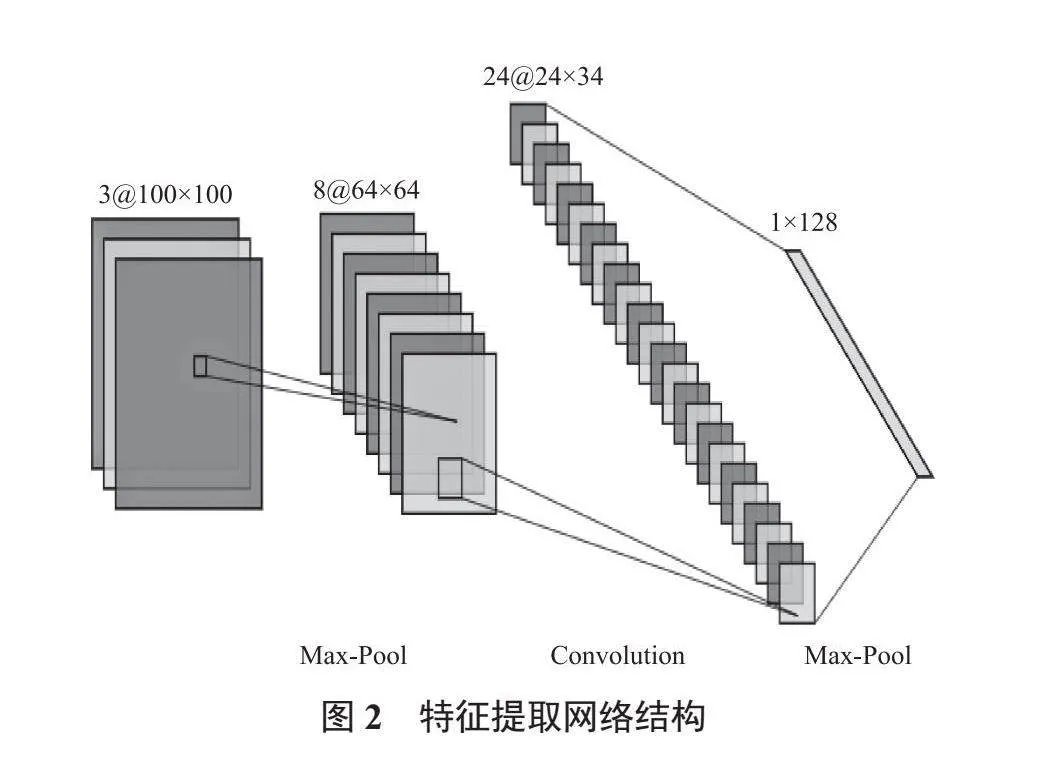
子圖像特征提取的網絡結構如圖2所示,包含2個卷積層、1個最大池化層、1個Dropout層及1個Flatten層。接受輸入(input)的第1個卷積層擁有最少32個卷積核,第2個卷積層擁有64個卷積核數,即該層輸出的特征通道數為64,其中每個卷積層都伴有ReLU層。為降低過擬合風險,加入Dropout層,最后通過Flatten層展平為1個向量。在提取圖像特征時會通過降維的方式優化網絡模型,不僅能減少網絡參數,還有利于得到圖像高層級的語義信息,但網絡在降維的同時也丟失了低層級的像素信息,使得其在表面圖像人臉識別時不太友好,所以本文使用128維特征信息作為后續模塊的輸入,最大限度保留原有圖像的特征信息。
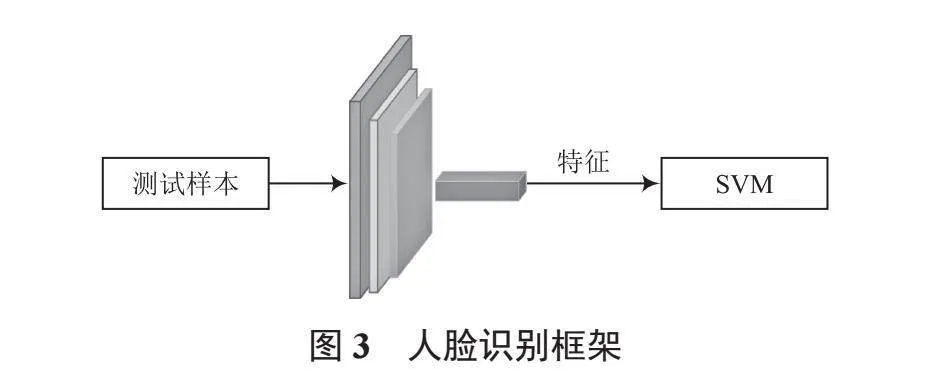
在上述過程中得到特征提取模塊,在此基礎上構建完整的表面人臉檢測模型,如圖3所示。首先將訓練樣本輸入到特征提取網絡得到訓練特征向量,用其訓練SVM分類器,然后將測試樣本輸入特征提取網絡,得到測試特征向量,再基于已訓練好的SVM分類器進行檢測。
2.2 損失函數
為了增強模型對類間樣本特征差異的敏感性,本文構建了基于類別敏感的正負樣本對。三元數表示樣本對(a, a', ya),a、a'表示輸入對稱網絡的樣本對,ya表示樣本對標簽。當ya=0時,表示正樣本對,即a與a'為同類別;否則表示負樣本對,即a與a'為相反類別。
由于訓練目標為最小化正樣本之間的差異,并擴大負樣本之間的差異,本文設計并提出了特征一致性約束策略的模型特征提取模塊損失函數:
(1)
式中:θ表示對稱特征提取模塊的模型參數;Fa、Fa'分別表示經特征提取模塊產生的特征;N表示樣本對的總數;m表示決定負樣本對距離上限的邊界值(Margin),該值根據實際情況確定;Dθ表示樣本對經過特征提取后特征空間上的距離表達。本文在此使用歐幾里得距離公式,如式(2)所示:
(2)
這種損失函數可以很好地表達成對樣本的匹配程度,也能夠很好地用于訓練相關模型。根據特征一致性約束公式可以發現,當ya=0時,模型會更新最小化原始圖像與其對抗變體之間的距離,即最小化類內間距;相反,當ya=1時,且負樣本對之間的距離大于m時,損失值等于0,即模型不做優化,而當負樣本對之間的距離小于m時,此時模型將負樣本對的距離增大到m,即增大類間間距。
2.3 網絡訓練
模型訓練分為2個階段。首先對特征提取模塊進行對抗訓練,然后再對分類模塊進行訓練。特征提取模塊訓練過程
如下:
(1)訓練開始時,將訓練樣本設置為相同尺寸;
(2)運用PGD算法攻擊訓練樣本;
(3)將各類樣本打亂順序分別放入2個隊列之中;
(4)以20的batch size分批隨機讀取以上隊列中的數據,送入對稱網絡;
(5)經過特征提取網絡提取特征向量后,計算出該批次的平均loss值,之后通過Adam自適應梯度下降算法,更新各層的權值與偏置等參數;
(6)重復步驟(2)~步驟(4),直至達到最大訓練輪次。
在特征提取模塊訓練基礎上,基于訓練特征向量對SVM分類模塊進行訓練,在此選用線性核函數。
3 實 驗
3.1 數據集
本文采用的ORL人臉數據庫共有400幅圖像,涉及40個人的不同表情、不同穿戴,其中每人10幅圖像。ORL人臉數據庫中原始圖像大小為112×92,實驗中采用的圖像大小為50×50。隨機選取若干幅圖像作為訓練樣本,其余圖像作為測試樣本,歸一化處理每一幅圖像。部分人臉樣本圖像如圖4所示。
實驗所采用的硬件和軟件配置:CPU為17-12700K"3.6 GHz,GPU為英偉達RTX3090TI,Python版本為3.8.5。深度學習框架采用PyTorch 1.13.0搭建,操作系統采用Windows 10。實驗參數中batch size為30,epoch為20,學習率為0.01。
3.2 結果與分析
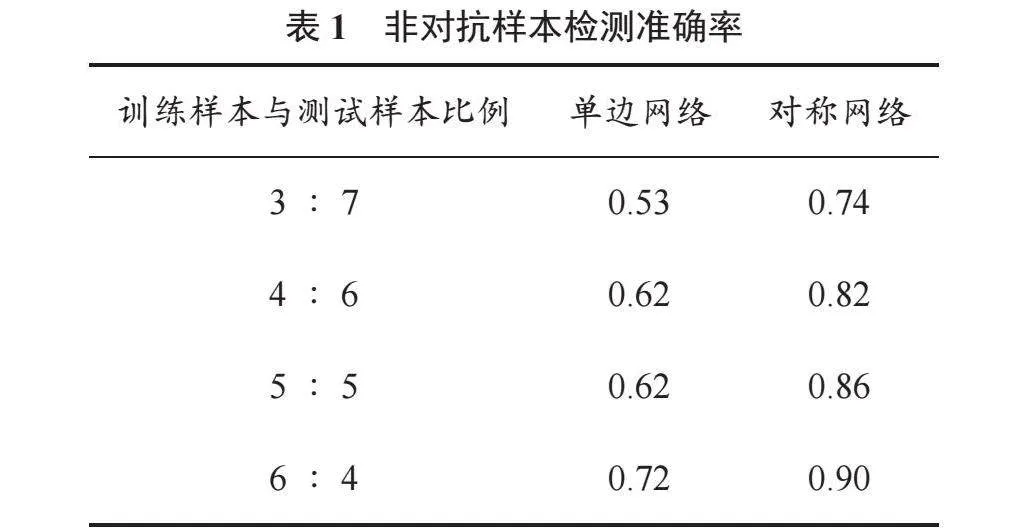
將非對抗樣本集按照一定比例劃分為訓練集和測試集,使用訓練集分別訓練單邊分類網絡(由特征提取模塊和分類模塊構成,其中特征提取模塊與對稱網絡相同)及對稱網絡。單邊分類網絡具有分類模塊,可以直接使用測試集進行人臉檢測測試;對稱網絡利用訓練好的特征提取網絡對訓練集和測試集進行處理,得到對應的訓練特征向量集與測試特征向量集,然后利用訓練特征向量集基于SVM進行分類訓練,最后利用SVM分類器計算測試特征向量集的準確率(圖像分辨率為250)。非對抗樣本檢測準確率見表1。
在未對樣本集進行增強的情況下,以上訓練樣本數量分別是120、160、200、240,相較于一般模型訓練需要的樣本數量非常少。由表1看出,訓練樣本數量與模型檢測準確率呈正相關,即訓練數量越大,則檢測準確率越高;單邊網絡在低樣本情況下,準確率維持在0.6左右,而對稱網絡通過重塑特征空間,讓相同類別樣本特征向量盡量靠近,不同類別樣本特征向量盡可能遠離,為分類提供了良好的基礎。結果表明,對對稱網絡,即使在訓練樣本數量僅為120時,其檢測準確率也可以達到0.742 9;當訓練樣本數量為240時,其檢測準確率超過了0.9,遠遠高于單邊網絡。
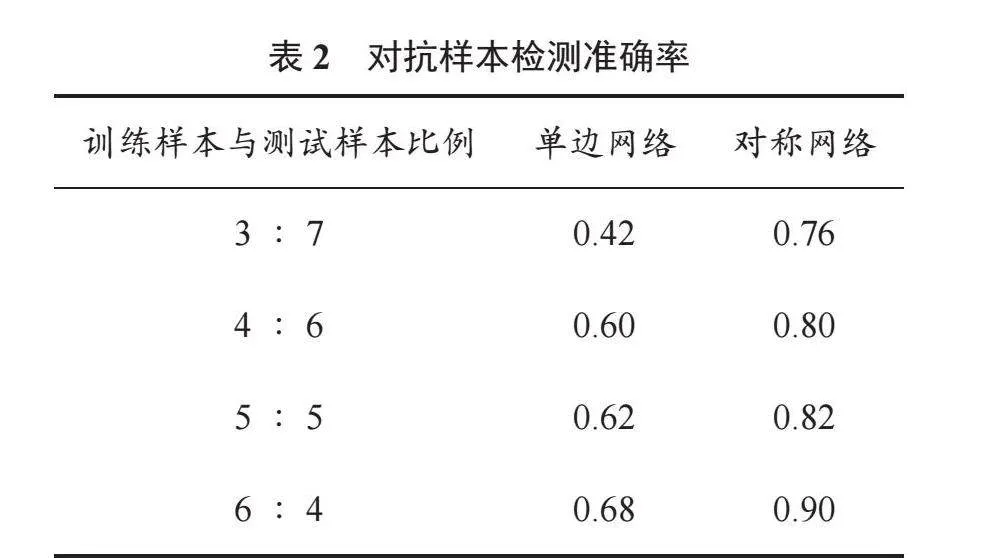
使用對抗樣本集分別訓練單邊分類網絡及對稱網絡。對抗樣本檢測準確率見表2。
由表2可以看出:對抗樣本的檢測準確率整體下降。其中,單邊網絡受影響更加明顯,同時其檢測準確率與訓練樣本數量的正相關性消失。這是因為訓練樣本數量越多,則受到攻擊的樣本也越多,因此對網絡產生的不良影響也將越大。對稱網絡雖然也受到對抗樣本的影響,但當訓練樣本數量增加后,這種影響將變得很小。由此可見,對稱網絡抗干擾性較單邊網絡更強,具有較好的魯棒性。
4 結 語
本文提出了一種新的人臉識別方法。該方法使用對稱網絡對人臉圖像進行識別分類。與傳統人臉識別方法相比,其具有以下優勢:
(1)在傳統DNN網絡的基礎上引入對稱思想,使特征空間類內間距盡可能小、類間間距盡可能大,約束網絡訓練,實現對于干擾樣本的魯棒檢測;
(2)充分發揮對稱網絡可以實現“one shot learning”的特點,在不需要擴充大量訓練數據的前提下,可以自定義增加需要檢測的人臉數目。
未來,本文的研究將涉及復雜背景下精確的人臉定位等方面,通過進一步優化模型結構,提升模型泛化能力。
注:本文通訊作者為張勝利。
參考文獻
[1]程鴻芳,祝軍.基于改進的稀疏描述和降維人臉識別方法[J].綿陽師范學院學報(自然科學版),2023,42(11):89-96.
[2]李根,岳望.復雜光照下LBP人臉識別算法的改進[J].信息與電腦,2023,15:106-109.
[3] HOU A, ZHANG Z, SARKIS M, et al. Towards high fidelity face relighting with realistic shadows [C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021.
[4] KIM S, JEONG Y, KIM J, et al. IronMask: modular architecture for protecting deep face template [C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021.
[5] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016: 779-788.
[6] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multi box detector [C]// European Conference on Computer Vision. Cham: Springer, 2016: 21-37.
[7] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014: 580-587.
[8] GIRSHICK R. Fast R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 1440-1448.
[9] GOODFELLOW I, SHLENS J, SZEGEDY C. Explaining and harnessing adversarial examples [C]// Proceedings of International Conference on Learning Representations 2015 (ICLR 2015). San Diego, California, USA: Yoshua Bengio, Yann LeCun, 2015:"1-11.
[10] MADRY A, MAKELOV A, SCHMIDT L, et al. Towards deep learning models resistant to adversarial attacks [C]// Proceedings of the 6th International Conference on Learning Representations (ICLR 2018). Vancouver, British Columbia, Canada; Yoshua Bengio, Yann LeCun, 2018: 1-28.
[11] LAKE B M, SALAKHUTDINOV R, GROSS J, et al. One shot learning of simple visual concepts [C]// Proceedings of the 33rd Annual Conference of the Cognitive Science Society. Boston, Massachusetts, USA: Cognitive Science Society, 2011: 2568-2573.
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
電子制作(2019年14期)2019-08-20 05:43:34
中國交通信息化(2018年1期)2018-06-06 07:29:55
電子制作(2017年17期)2017-12-18 06:40:55
中國公共安全(2017年7期)2017-10-13 08:18:26
電子制作(2017年1期)2017-05-17 03:54:46
中國公共安全(2017年9期)2017-02-06 03:05:32
現代工業經濟和信息化(2016年6期)2016-05-17 05:36:23
華東理工大學學報(自然科學版)(2015年2期)2015-11-07 09:16:51
