淺談語音識別技術的應用和發展
2009-12-30 03:41:48于大海孫建民
科技傳播 2009年22期
于大海 孫建民
摘要 語音識別技術就是讓機器通過識別和理解過程把語音信號轉變為相應的文本或命令的技術,其最終目標是實現人與機器進行自然語言通信。語音作為一個交叉學科,具有深遠的研究價值,近50年的研究發展,語音識別技術已經有了極大的發展。本文介紹了語音識別技術的基本原理和應用,并且對語音識別技術的發展趨勢進行了展望。
關鍵詞 語音識別;應用;發展
中圖分類號 TN912.34 文獻標識碼 A文章編號 1674-6708(2009)08-0022-02
0 引言
語音是人類互相之間進行交流時使用最多、最自然、最基本、最重要的信息載體。在高度信息化的今天,語音處理的一系列技術及其應用已經成為信息社會不可缺少的組成部分。語音的產生是一個復雜的過程,包括心理和生理等方面的一系列因素。當人們需要通過語音表達某種信息時,首先是這種信息以某種抽象的形式表現在說話人的大腦里,然后轉換為一組神經信號,這些神經信號作用于發聲器官,從而產生攜帶信息的語音信號。
1 語音識別的研究歷史及現狀
在國外語音識別的研究工作可以追溯到上世紀50年代。1952年AT&T貝爾實驗室的Audry系統是第一個可以識別十個英文數字的語音識別系統。
上世紀60年代末70年代初出現了語音識別方面幾種基本思想,其中重要成果是提出了信號線性預測編碼(LPC)技術和動態時間規整(DTW)技術,有效的解決了語音信號特征提取和不等長語音匹配問題,同時,還提出了矢量量化(VQ)和隱馬爾可夫模型(HMM)理論。
上世紀80年代語音識別研究進一步走向深入,其顯著特征是隱馬爾可夫模型(HMM)和人工神經網絡(ANN)在語音識別中的成功應用。上世紀90年代,在計算機技術、電信應用等領域飛速發展的帶動下,迫切的要求語音識別系統從實驗室走向實際應用。具代表性的是IBM的Via Voice和Dragon公司的Dragon Dictate系統,這些語音識別系統具有說話人自適應能力,新用戶不需要對全部詞匯進行訓練便可在使用中不斷提高識別率[1]。
國內在語音識別研究上也投入了很大的精力,中科院的自動化所、聲學所以及清華大學等科研機構和高校都在從事語音識別領域的研究和開發。國家863智能計算機專家組為語音識別技術研究專門立項,我國語音識別技術的研究水平已經基本上與國外同步。
2 語音識別系統的分類
目前,語音識別的系統分類有孤立語音和連續語音識別系統,特定人和非特定人語音識別系統,大詞匯量和小詞匯量語音識別系統,嵌入式/服務器模式等。
2.1 孤立語音和連續語音識別系統
自然的語音,只在句尾或是文字需要加標點的地方必須間斷,其它的部分可以連續不斷地發音。以前的語音識別系統,幾乎都是以單字或單詞為單位的孤立語音識別系統,但隨著近年來的研究和發展,連續語音識別技術漸趨成熟,這個最自然的說話方式,將成為語音識別系統的主流。
2.2 特定人和非特定人語音識別系統
特定人和非特定人語音識別系統是按照聲學模型建立的方式來劃分。特定人系統是指系統在使用前必須由用戶輸入大量的發音數據,并對其進行訓練。非特定人系統則試圖達到在系統構建成功之后,用戶不需要事先輸入大量的訓練數據,即可使用的目的。
2.3 大詞匯量和小詞匯量語音識別系統
在語音識別技術的發展過程中,詞匯量也正是從少到多不斷積累的,隨著詞匯量的增大,對系統各方面的要求也越來越高,該系統的成本也越來越高了。語音識別系統只是要為你在開車的時候利用語音進行電話撥號,那它只要能聽懂十個數字就可以了,屬于小詞匯量語音識別系統。如果它是為你自動訂飛機票,那么它就應該還會認識地名、時間等字和詞,這屬于中等詞匯量語音識別系統。如果它是為一個記者把口述的一篇報告轉換成為文字,那它的詞匯量就必須很大才能勝任這樣的工作,這屬于大詞匯量語音識別系統[2]。
2.4 嵌入式/服務器模式
嵌入式是將語言識別軟件及模型寫在設備(如手機)的存儲器里,識別過程在終端完成。在服務器模式,終端只負責收集和傳導語音信號,由服務器負責完成識別。因此,對于大規模、多用戶和有大量識別需求的系統,服務器模式提供了有效的方式。同時服務器方式對最終用戶的知識需求甚少,系統的更新、升級和管理方便、有效,可由運營商負責,而嵌入式則在很大程度上受終端設備資源所限。
3 語音識別的幾種基本方法
當今語音識別技術的主流算法,主要有傳統的基于動態時間規整(Dynamic Time Warping,DTW)算法、基于非參數模型的矢量量化(VectorQuantization,VQ)方法、基于參數模型的隱馬爾可夫模型(Hidden Markov Models,HMM)的方法和基于人工神經網絡(Artificial Neural Network,, ANN)等語音識別方法[3]。
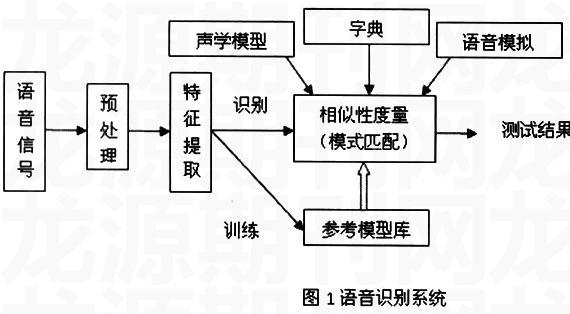
4 語音識別系統的結構[4]
語音系統基本構造,如圖1所示,系統可以分為前端處理和后端處理。前端處理包括語音的錄入、處理、特征值的提取,后端是個夸數據庫的搜索過程,,分為訓練和識別。訓練是對所建的模型進行評估、匹配、優化,獲得模型參數。識別是一個專用的搜索數據庫,獲取前端數值后,在聲學模型、一個語言模型和一個字典。聲學模型表示一種語言的發音聲音,可以通過訓練來識別特定用戶的語音模型和發音環境的特征。語言模型是對語料庫單詞規則化的概率模型。字典列出了大量的單詞及發音規則。總體上說,語音識別是一個模式識別匹配的過程,在這個過程中,計算機首先要根據人的語音特點建立語音模型,對輸入的語音信號進行分析,并抽取所需的特征,在此基礎上建立語音識別所需的模板。然后,在識別過程中,計算機根據語音識別的整體模型,將計算機中已經存有的語音模板與輸入語音信號的特征進行比較,并根據一定的搜索和匹配策略找出一系列最優的與輸入語音匹配的模板。最后通過查表和判決算法給出識別結果。顯然識別結果與語音特征的選擇、語音模型和語言模型的好壞、模板是否準確等都有直接的關系。
5 語音識別尚未解決的問題及值得研究的方向
5.1 就算法模型方面而言,需要有進一步的突破。
聲學模型和語言模型是聽寫識別的基礎。目前,使用的語言模型只是一種概率模型,還沒有用到以語言學為基礎的文法模型,而要使計算機確實理解人類的語言,就必須在這一點上取得進展。
5.2 語音識別的自適應性也有待進一步改進
同一個音節或單詞的語音不僅隨著講話者的不同而變化,而且對同一個講話者在不同場合、不同上下文環境中也會發生變化,這意味著對語言模型的進一步改進。
5.3 語音識別技術還需要能排除各種環境因素的影響
對語音識別效果影響最大的就是環境雜音或噪音。要在嘈雜環境中使用語音識別技術必須有特殊的抗噪麥克風才能進行,這對多數用戶來說是不現實的。在公共場合,對于語音識別技術能清除環境嗓音并從中獲取所需要的特定聲音,是一項艱巨的任務。
參考文獻
[1]柳春.語音識別技術研究進展[J].甘肅科技2008,24(9):41-43.
[2]朱淑鑫,謝忠紅.淺談語音識別技術的應用及發展[J].長春理工大學學報(高教版),2009,4(2):64-65.
[3]趙力.語音信號處理[M].北京:機械工業出版社,2003.
[4]崔文迪,黃關維.語音識別綜述[J].福建電腦,2008,(1):28-29.
福建省積極推進科普惠農服務站建設
近日,福建省科協和省財政廳聯合下發了《關于加強福建省科普惠農服務站建設的意見》(以下簡稱《意見》),旨在更好地調動福建省社會力量實施《全民科學素質行動計劃綱要》,強化農村科普基層組織建設,提升科協的農村科普服務能力和水平,逐步完善并延伸農村科普服務鏈,促進海峽西岸經濟區社會主義新農村建設。
《意見》 指出,福建省科協系統和財政部門將通力協作、密切配合,本著“科協統籌、財政支持、基層建站;立足科普、服務農民;集成資源、形成合力;因地制宜、多方探索” 的原則,力爭在2010年底前,推動全省獲得國家級和省級科普惠農興村計劃表彰獎勵的單位和個人建成科普惠農服務站,并帶動有條件的專業技術協會、專業合作組織和行政村等建設科普惠農服務站,形成覆蓋全省的科普工作組織網絡。
《意見》中詳細規定了科普惠農服務站的場地、設施、標牌、隊伍、制度、載體等標準,明確了“科協組織主要負責科普惠農服務站的建設、運行和管理,財政部門主要負責為科普惠農服務站的建設和運行提供資金和項目支持”的工作機制和各級科協組織的任務和職責。
《意見》要求縣級科協組織必須建設科普惠農服務總站,選聘各科普惠農服務站負責人,鼓勵在地方特色產業中建設科普惠農服務站,積極指導和支持科普惠農服務站的建設和管理,努力形成覆蓋面廣、運轉流暢、聯系緊密、長效運作的科普惠農服務站建設機制。
猜你喜歡
中國核電(2021年3期)2021-08-13 08:56:36
家庭影院技術(2018年11期)2019-01-21 02:20:52
華人時刊(2017年21期)2018-01-31 02:24:01
北方交通(2016年12期)2017-01-15 13:52:53
考試周刊(2016年76期)2016-10-09 08:45:44
科技視界(2016年20期)2016-09-29 14:22:00
科技視界(2016年20期)2016-09-29 12:03:12
科技視界(2016年20期)2016-09-29 11:47:01
科技視界(2016年20期)2016-09-29 11:02:20
大眾理財顧問(2016年8期)2016-09-28 13:45:18
