基于云端的Web數據挖掘預取技術研究
2010-01-05 06:10:08陳鋒敏
統計與決策 2010年22期
陳鋒敏
(湖北經濟學院 網絡與教育技術中心,武漢 430205)
基于云端的Web數據挖掘預取技術研究
陳鋒敏
(湖北經濟學院 網絡與教育技術中心,武漢 430205)
WWW以其多媒體的傳輸及良好的交互性而倍受青睞。 但由于Web服務和網絡固有的延遲,用戶并沒有得到與帶寬相應的服務體驗。為此文章提出了一種基于云端的智能Web預取技術,它能夠加快用戶瀏覽Web頁面時獲取頁面的速度。該技術通過簡化的WWW數據模型表示用戶瀏覽器緩沖器中的數據,在云端利用數據挖掘技術挖掘類聚用戶隱含的興趣關聯規則,并利用類聚用戶的歷史連接記錄創建確定的影射關系模型,存放在云端興趣關聯知識庫中,作為對用戶行為進行預測的依據。在用戶端,瀏覽器插件負責在用戶帶寬空閑時根據用戶興趣進行Web預取,從而對用戶實現透明的高速瀏覽。
WWW;互聯網;數據模型;數據挖掘;預取;映射;云端
隨著互聯網高速普及以及互聯網基礎設施的逐步完善,人均享有帶寬也在逐步的增加,但由于Web服務和網絡固有的延遲,用戶并沒有得到與帶寬相應的服務體驗。根據用戶當前的請求,預測用戶將來可能發出的訪問請求,在用戶瀏覽當前Web頁面時將預測的內容取到本地高速緩存(cache)中,通過主動的高速緩存可以有效提高用戶瀏覽體驗。預取技術的基礎是預測算法。數據挖掘是從大量的數據中采掘出隱含的、先前未知的、對決策有潛在價值的知識和規則的一種技術。我們可以根據用戶訪問的歷史數據和當前訪問的數據、利用數據挖掘技術來預測用戶將來的可能行為,從而為用戶預取一些Web頁面。
本文首先討論了Web預取的解決思路,然后通過簡化WWW數據模型建立興趣關聯知識庫,最后討論了一個基于云端和插件的Web預取原型系統。
1 Web預取映射關系研究
1.1 Web預取面臨的問題及解決思路
從根本上說,Web預取面臨的問題只有一個,那就是:從用戶訪問的過的大量歷史鏈接記錄中推測和判斷出用戶在當前頁面下最有可能點擊的鏈接頁面并提前將預測的內容取到本地高速緩存中,從而在很大程度上減小用戶的訪問延遲。如下圖所示:
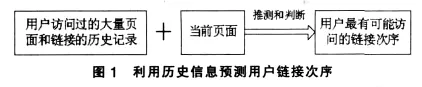
雖然互聯網中具有海量的數據,但對于具體的某一用戶而言,其所接觸的只是萬維網的有限的極小一部分,所以我們可以通過Web頁面的向量類型作為有限集合,以類聚用戶的歷史鏈接記錄(包含有用戶的偏好)確定映射關系。
1.2 預取映射關系的構建
(1)用戶訪問過的歷史Web頁面通過TFIDF向量表示法進行聚類。
(2)用戶的鏈接記錄加入到兩集合之間作為確定的映射關系,同時記下鏈接次數作為權重。
所構建的集合之間的映射包含下列二種具體的映射關系:
第①種映射是一一映射。
第②種映射是一對多的關系,我們可以通過記錄其分別映射的次數形成權重來限制在預取的過程中沿著權重大的目標結點進行映射。最終形成一一映射。
1.3 基于確定映射關系的新的預取思路
在確定的映射關系構建之后
step1:將當前的Web頁面進行詞條切分,應用TFIDF向量表示法與知識庫中的源Web頁面類型進行匹配,在知識庫的源Web頁面集合中找出對應的源Web頁面類型;
Step2:沿著知識庫中確定的映射關系找出對應的目標Web頁面類型;
Step3:將當前Web頁面鏈接集合中的Web頁面與目標Web頁面類型進行匹配,并按匹配程度進行排序,并按規定的預取數量按順序從前向后進行預取。
該預取思路的優點:
①構建了確定的映射關系,提高了預取的效率。
②算法的復雜度為,大大節省了計算資源,提高了響應速度。
2 簡化WWW數據模型
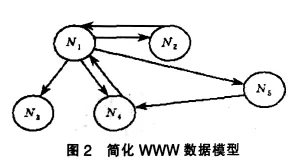
Web頁面之間可以通過超級鏈接而相互鏈接,從而構成一個相互鏈接的超媒體系統。為了對用戶行為做出預測,必須有一種數據模型能夠很好地描述Web頁面間的興趣關聯規則。為便于本文的討論,我們將定義一種數據模型一一簡化WWW數據模型。
定義1 頁面節點用三元組(P Id,P,time)表示,其中,P Id唯一標記一個頁面節點,time為其最近被訪問的時間,P為屬性集,P={pi|pi為屬性,i=1,2,…}。
定義2 頁面中的鏈接點用三元組 (L Id,string,target.node.id)表示,L Id唯一標記一個鏈接點,string描述了該鏈接的展示信息,target.node.id是L Id所標記的鏈接點所指向的目標頁面節點的P Id.
定義3 頁面中的鏈接用三元組(source.node,L,target.node)表示,其中,source.node為源頁面節點,L為source.node中的鏈接點,target.node為目標頁面節點,L.target.node.id=target.node.
針對數據挖掘的要求及高速緩存的特點,我們通過頁面節點鏈接點和鏈接描述一種簡化WWW數據模型。
定義4 簡化WWW數據模型可以用三元組(Page.node.set,Page.linknode.set,Link.set)表示,其中,Page.node.set為頁面節點集合,Page.linknode.set為鏈接點集合,L ink.set為鏈接集合。
如圖2所示,頁面節點N1,N2,N3,N4,N5分別表示不同的Web頁面,這些頁面節點之間可以通過有向邊相互鏈接。這些有向邊直觀地表示了頁面間的鏈接。
高速緩存中保存的歷史數據反映了用戶訪問頁面過程中的興趣愛好。利用用戶的興趣間的關聯信息可以對用戶的行為進行預測。高速緩存中頁面間的聯系可以很方便地用圖2中的簡化WWW數據模型來描述,但是這種數據模型不能直觀地表示用戶的興趣間的關聯信息.為了對用戶的行為進行預測,從而實現主動的緩沖(預取),需要通過某種方法將由簡化WWW數據模型所表示的高速緩存中的數據反映到適合于預測的數據模型中去。
3 云端興趣關聯知識庫與用戶行為預測
一般的用戶都是喜歡訪問有限的網站中的感興趣的Web頁面,受用戶習慣行為的影響,其點擊頁面的順序中隱含了該用戶的興趣關聯規則,因此我們可以將用戶曾經訪問過的Web頁面進行抽象提取成向量的形式后存入興趣關聯知識庫(設有存儲上限和自動更新功能),同時將Web頁面鏈接順序(L Id—>target.node.Id)一并存入,則該條記錄就隱含了用戶的興趣關聯規則,例如:用戶訪問Web頁面的順序為A—>B—>C—>D,則我們可以將下列記錄存入興趣關聯數據庫:

序號次數123…….N Source.page P(A)P(B)P(C)…….P(N)L Id L Id(A)L Id(B)L Id(C)…….L Id(N)target.node.Id target.node.Id(B)target.node.Id(C)target.node.Id(D)……target.node.Id()target.page P(B)P(C)P(D)……P()N1N2 N3 Nn
興趣關聯知識庫中的記錄隱含了用戶的興趣關聯規則,即用戶從某一詞條(興趣)轉向其它詞條(興趣)的可能性。利用它再結合用戶訪問的當前頁面可以預測用戶可能訪問的鏈接(圖 1)。
興趣關聯知識庫中的興趣關聯規則記錄建立在對大量歷史數據進行統計的基礎上。用戶在訪問頁面時,一般是連續訪問多個頁面。這些頁面實際上表明了用戶當前的興趣狀況,它們相對那些用于構造興趣關聯知識庫的歷史數據來說,對預測用戶的行為更有價值,即它們的新鮮度更高。根據用戶目前訪問軌跡進行類聚分析,從而獲取最可能預取頁面路徑。
4 基于云端的Web預送技術
通過瀏覽器插件在用戶空閑時段與云端進行交互,云端基于興趣關聯知識庫預測用戶行為算法對用戶當前頁面進行分析,云端根據用戶興趣,返回最可能興趣頁面路徑,由插件負責預取Web頁面并將之存放到本地高速緩存中。同時云端通過興趣關聯知識庫調整增量算法,對興趣關聯知識庫進行更新,插件的存在對用戶是透明的。用戶仍像平時一樣使用瀏覽器。
5 總結
本文在給出簡化WWW數據模型的基礎上,利用數據挖掘技術對用戶瀏覽器高速緩存中的數據進行挖掘,從中獲取知識,并將其存放在興趣關聯知識庫中,用來預測用戶即將訪問的鏈接。通過對用戶行為興趣分析形成龐大的興趣關聯知識庫不僅可以為用戶帶來快速的瀏覽體驗,還可以在不泄露用戶隱私的前提下為Web服務商提供詳實的服務報告以及訪問用戶行為分析。
[1]陳康,云計算.系統實例與研究現狀[J].軟件學報,2009,(5).
[2]張建勛.云算研究進展綜述[J].計算機應用研究,2010,(2).
[4]朱志國.持久偏愛的Web用戶訪問路徑信息挖掘方法[J].情報學報,2010,(2).
[5]王繼承,潘金貴等.Web文本挖掘技術研究[J].計算機研究與發展,2000,37(5).
[6]王晗.一種新的增量式關聯規則數據挖掘方法研究[J].儀器儀表學報,2009,(2).
[7]班志杰.Web預取技術綜述[J].計算機研究與發展,2009,(2).
TP3
A
1002-6487(2010)22-0161-02
(責任編輯/易永生)
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
當代陜西(2021年17期)2021-11-06 03:21:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
信息通信技術(2015年6期)2015-12-26 01:16:46
電子設計工程(2014年18期)2014-02-27 12:00:13
電腦愛好者(2011年11期)2011-06-22 08:20:18
