基于即時學習策略的火電廠煙氣含氧量軟測量
2010-02-20 07:42:22張炎欣
裝備制造技術 2010年4期
張炎欣,張 航,王 偉
(中南大學信息科學與工程學院,湖南長沙410083)
電力生產是國民經濟發展的先行軍。雖然我國近年來在風力發電、光伏發電、核電等方面取得了長足發展,但目前火力發電仍占主導地位,其容量占總容量80%以上[1~2]。隨著國民經濟的高速發展和科學技術的進步,電力工業發展迅速,現代大型火電機組普遍采用大容量、高參數單元機組,生產技術達到了一定水平[3~4]。但在效益、環保等方面,同國家建設節約型社會的能源基本方針還存在很大差距[5]。
影響火電廠優化運行的一個重要因素,是許多重要的過程參數和經濟指標難以在線實時檢測。如煙氣含氧量等,都是直接反映發電效率和運行安全的重要熱工參數,由于管理體制和技術、經濟等原因,沒有進行實時準確的測量,嚴重制約了火電廠過程控制和優化運行技術的發展,降低了企業的發電效率、提高了企業的生產成本。因此,對煙氣含氧量等熱工參數進行實時、準確的測量具有重要的意義。
1 對煙氣含氧量軟測量的研究概述
針對鍋爐燃燒過程煙氣含氧量無法實時準確檢測的問題,眾多學者在分析煤質變化、鍋爐爐膛漏風和未完全燃燒等因素對煙氣含氧量影響的基礎上,展開了煙氣含氧量軟測量模型的研究。
文獻[6]提出基于一種由一個包含隱層的三層前向網絡,和一個不包含隱層的線性前向網絡并聯組成的復合型神經網絡,并將該復合型神經網絡應用到火電廠煙氣含氧量軟測量,通過對不同負荷下實測數據的仿真實驗,驗證了該方法的有效性。
文獻[7]采用燃燒機理分析以及統計分析方法,建立風量和給煤量的軟測量模型。采用多傳感器數據融合方法,并加以煤質校正等處理,得到一個完整的氧量軟測量模型。通過仿真驗證,建立的氧量軟測量模型,能較好的反映煙氣含氧量的變化。
文獻[8]提出基于混合高斯過程的軟儀表,利用期望最大算法,實現對混合模型中的參數估計。判斷出與特定工況相關程度最大的過程知識,利用它們建立與特定工況對應的局部模型,并將它們合并組成具有多模型結構的全局模型。仿真結果表明,文中提出的方法能有效地實現工業過程參數的軟測量,具有較大的實用價值。
文獻[9]提出一種新型的基于支持向量回歸算法的軟側量模型,利用訓練數據性能信息獲得模型訓練參數,減少人為因素對模型精度的影響,以提高建模效率和模型精度。針對某火電廠歷史實測數據仿真結果表明,文中提出的方法能有效實現熱工過程參數的軟測量,有較大實用價值。
文獻[10]采用徑向基核函數的最小二乘支持向量機建模方法,進行煙氣含氧量的軟測量,由于該方法中正則化參數和核函數寬度參數的選取,對預測模型精度影響較大,引入粒子群優化算法對進行上述兩參數的尋優,基于實際檢測數據的仿真結果表明,該方法具有較好的預測效果。
文獻[11]針對常規建模方法,在實際應用中所面臨的建模難題,提出了一種新的建模思想——反向建模方法,利用實際復雜熱力系統運行時產生的大量實時數據,建立系統數學模型的學術思想。闡述了反向建模方法的思想、建模過程的模式。以煙氣含氧量為例,利用華能福州電廠所采集的大量現場運行數據,選用偏最小二乘算法,利用反向建模思想,建立一個局部系統的數學模型,驗證結果表明,該建模思想的有效性和實用性。
上述研究工作,有效推動了電廠煙氣含氧量軟測量的實際應用。但上述方法主要是基于全局模型的建模技術,建模過程中需要獲得能夠覆蓋整個生產工況的運行數據,對于實際電廠生產過程而言,這是比較困難的;同時,隨著電網調峰任務的加重,火電單元機組負荷變化更加頻繁,針對不同工況下模型的在線自適應問題,上述方法沒有進行很好的考慮,通常需要對模型從新進行離線校正,過程中需要過多的人為干預。因此,上述方法雖然在煙氣含氧量軟測量建模中取得了不錯的應用效果,但是在建模理論方面和實際應用等方面,仍然有很多值得研究的地方。
針對電廠煙氣含氧量難以進行實時有效檢測的問題,從提高軟測量模型在線自適應能力的角度出發,本文提出一種基于即時學習策略的改進支持向量機預測建模方法,并通過基于電廠實際運行數據的仿真實驗,驗證本文方法的有效性。
2 鍋爐燃燒過程分析及輔助變量的確定
循環流化床鍋爐具有燃料適應性廣、低污染排放等優點,是國內外廣泛推廣的一種煤燃燒技術。它采用爐內物料循環燃燒,使得燃料能夠燃燒充分,降低了燃煤電廠的能耗,并能夠燃燒劣質煤,甚至煤矸石、生物質之類的燃料。循環流化床鍋爐使用爐內脫硫法來解決減排問題,即通過爐內添加石灰石粉,經過循環燃燒,使得石灰石粉和煤的充分反應,來實現硫化物的固化,并通過低溫燃燒來抑制氮氧化物的產生。循環流化床鍋爐的主要組成部分有鍋爐本體、給煤系統、一次風系統、二次風系統、分離器、回料器、尾部煙道、冷渣器等。
通過實際現場調研發現,煙氣含氧量主要受煤質變化、鍋爐爐膛漏風、未完全燃燒等因素的影響,從機理分析角度出發需要選擇能反映負荷、燃料、風量、排煙等方面的變量作為輔助變量。因此,本文選取燃料量、主給水流量、主蒸汽流量、排煙溫度、給水流量、高壓主汽閥前壓力、送風機入口風量、送風機動葉開度、引風機入口風量9個過程參數,作為煙氣含氧量軟測量模型的輔助變量。
3 基于即時學習策略的改進支持向量機軟測量建模方法
即時學習策略,利用系統當前工況點,從歷史數據庫中尋找與當前工況點匹配程度最好的一系列數據,采用某種建模方法,建立當前系統的局部模型,并計算出系統的輸出。與全局建模方法相比,由于即時學習模型的建立和優化是局部進行的,使得模型的預測誤差更小,并且由于預測模型只是在查詢工作點處產生,因此可以在線增加新的觀測數據到數據庫,或者從數據庫中刪除舊的數據,使模型具有較好的自適應能力。
即時學習模型的主要缺點,是建模消耗大,從而導致模型實時性不強。但是對于工況變化大,常規方法建立的靜態模型隨時間精度下降大的情況,采用即時學習模型,能夠使測量精度有明顯的改善。
3.1 基于距離和角度信息的即時學習算法
在即時學習建模方法中,根據當前輸入樣本點確定的建模鄰域的大小,對模型預測精度有很大影響,本文同時考慮樣本的距離和角度信息,利用加權策略實現這兩種方法所蘊含的不同信息的集成,將其作為樣本間相似性的量度,以獲得與當前輸入樣本具有較高相似度的建模鄰域數據。
設當前輸入樣本點和樣本樣本集中數據都為9維向量Xa=(Xa1,…,Xa9)T,Xi=(Xi1,…,Xi9)T,則當前輸入樣本點 Xa和樣本樣本集中數據Xi的距離和角度信息表示如下:

式中λ∈[0,1]為權系數,si的取值介于[0,1]之間,其值越大,表示Xa和Xi越相似。
(1)當 Xa與 Xi的夾角較大,即 cos(θi)< 0 時,則認為數據Xi與當前輸入樣本點Xa的相似性較差,從保證建模精度的角度考慮,丟棄該數據樣本;
(2)當 Xa與 Xi的夾角較小,即 cos(θi)≥0 時,認為 Xi數據與當前輸入樣本點Xa的相似性較好,選用式(3)作為相似樣本集的選擇量度。
從式(3)可以得出,該相似性量度準則綜合考慮了樣本信息的歐式距離與角度信急,具有較好的相似信息挖掘能力。利用該公式可構造出當前輸入樣本點Xa的鄰域Ωk,由于Xa和Xi越相似,則si的值越大,因此,鄰域公式可以表示為
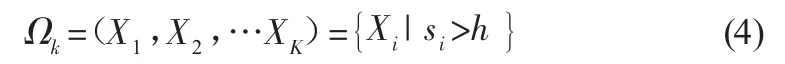
數據窗口h的大小,對局部模型的預測效果影響很大。窗口h值過大,會增加算法的計算開銷,同時引起較大的估計偏差;窗口h值過小,會造成較大的估計方差,使模型的泛化能力下降。所以數據窗口h值的選取是相當重要的。
數據窗口h值的確定方法,大致可分為兩類:
一是數據驅動方法,這類方法是參數化建模方法的直接擴展,其目的是通過極小化某一代價函數獲得最優的數據窗口值;
二是Direct Plug-in方法,該方法通過求解偏差和方差分析的漸進線,得到數據窗口的最優值,但由于偏差量和方差量都是未知項,必須通過估計值來取代這兩個未知量,以得到最優的數據窗口。
基于數據驅動的方法需要極小化某一風險函數,因此算法較為復雜,工業現場具體實施較為困難,本文根據一定的先驗知識,通過對實驗數據多次重復建模,人工確定最佳的局部模型數據樣本集的大小,一般取在30~40之間。
3.2 改進支持向量機預測模型
支持向量機是統計學習理論基本思想的實現,它運用結構風險最小化原則,避免了神經網絡等基于經驗風險最小化建模方法存在的過擬合、局部極小等缺陷,已廣泛應用于工業過程預測建模、系統辨識的領域。支持向量機預測模型的基本思想為:對于給定的樣本數據集合,在高維特征空間中構造一個回歸函數,其中的權系數向量和閾值可通過求解凸二次規劃問題得到。針對優化問題中的目標函數,構造拉格朗日函數,把原始的凸二次規劃問題轉化為對偶問題,并引入核函數,避免使用非線性映射。于是原回歸函數可轉化為
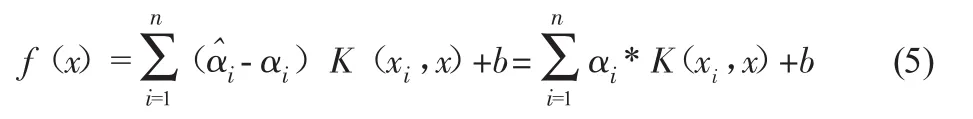
式中,
K(xi,xj)=準(xi)T準(xi)為核函數;
b為閾值,n為數據樣本的組數。
在支持向量機建模過程中,正則化參數C則直接控制目標函數中的模型復雜度和訓練誤差的權重比例;不敏感參數ε控制不敏感帶的寬度,影響支持向量機的稀疏性,一定程度上反映了對模型誤差的容忍度;核函數K(xi,xj)隱式定義了低維變量空間到高維特征空間的非線性映射,對于RBF核而言,核函數的參數主要是核的寬度α2,它主要影響樣本數據在高維特征空間中分布的復雜程度。上述3個參數選取的好壞,很大程度上決定了支持向量機預測模型的預測精度。
傳統的參數選擇方法,主要根據用戶根據經驗來選擇模型參數,但這種方法帶有很大的主觀性,不能準確反映訓練集對模型的影響。本文采用改進粒子群優化算法進行上述參數的尋優。
PSO算法在每一次的迭代中,粒子通過跟蹤兩個“極值”(pbest,i,gbest)來更新自己,其中pbest,i表示第i個粒子的個體最優值,gbest表示當前全局最優值。在找到這兩個最優值后,粒子通過下式來更新自己的速度和位置

式中,
vi(k)是第i個粒子在第k次迭代中的速度矢量;
r1、r2是介于(0,1)之間的隨機數;
c1和c2是學習因子,一般固定為2.0;
w表示慣性權重,采用下式獲得

式中,
w0、w1為初始慣性權重;
Step為粒子群當前迭代的次數;
Gen為預設的總的迭代次數;
w值越大,其全局搜索能力越強;反之,w值越小,其局部搜索能力越強。
共軛梯度法是一個經典的非線性尋優算法,具有線性收斂的特點,其局部搜索能力較強。
設初始點 X(1),取 d1=-犖f(X(1)),
其中X(1)表示向量矢量;d1表示梯度負方向。
設 k ≥ 1,已得到 k 個相互共軛的方向 d(1),d(2),…,d(k),以及由X(1)開始依次沿上述方向精確一維搜索得到點X(2),…,X(k),X(k+1),即:

式中,λi表示通過某種線性搜索計算出的步長。
通過精確一維搜索,保證方向導數為0,即
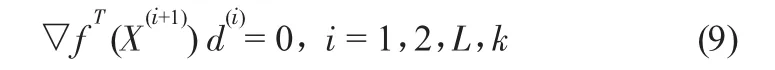
在 X(i+1)點構造新方向 d(k+1)為 -犖f(X(k+1))與 d(1),d(2),…,d(k)的組合,由于 d(1),d(2),…,d(k)相互共軛,則有
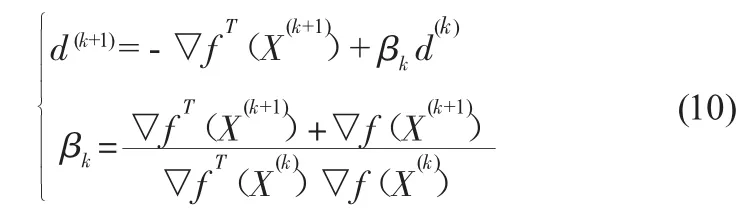
運用改進粒子群優化算法對SVM參數優化,選取的具體步驟如下所示:
(1)在給定范圍內將SVM模型三個參數進行初始化,構成一個由三個浮點隨機數組成的染色體,并進而形成初始種群;
(2)將種群中的個體解碼,還原成SVM模型中的3個參數,并用訓練樣本集對SVM模型進行訓練學習,以主導變量期望值和實際值的擬合誤差作為尋優目標,這樣種群中的每個個體都有一個適應度值,計算當代最佳粒子、全局歷史最佳粒子和個體歷史最佳粒子;
(3)判斷算法是否停滯,若沒有停滯,則繼續執行粒子群算法,否則,對每個粒子產生一個隨機數,如果該隨機數小于0.1,則直接跳轉到步驟(5),如果位于0.1和0.2之間,則對該粒子按照為一個小于1的隨機數)進行變異后,再跳轉到步驟(5);
(4)判斷算法是否滿足終止條件,若滿足終止條件,則停止計算轉到步驟(10),否則跳轉到步驟(2);
(5)將粒子群優化算法得到的該粒子位置值賦給X(1),且d(1)=-犖f(X(1)),k=1;
(6)判斷 ||犖f(X(k))||<ε?若小于,則轉步驟(3),對下個粒子進行判斷,否則進行下一步;
(7)求 min f(X(k)+λkd(k)),X(k+1)=X(k)+ λkd(k);
(8)k=n?,如果相等,則令 X(1)=X(n+1)、且 d(1)=-犖f(X(1))、k=1轉步驟(6),如果不相等,則向下執行;
(9)d(k+1)=-f(X(k))+ βkd(k),k=k+1,轉步驟(6)。
(10)將獲得的種群中選擇最優個體,解碼還原得到SVM模型中的3個參數,建立相應的SVM模型,進行主導變量的預測建模。
3.3 預測模型的具體實現
為使算法具有較小的計算開銷,采用加權模糊C均值聚類算法,對數據樣本集進行聚類,利用兩步搜索策略進行當前輸入樣本數據Xa相似數據集的選取。
首先,計算當前輸入樣本數據Xa與各個聚類中心的歐氏距離,找到與當前輸入樣本數據最近的一個聚類中心;
然后,在該聚類內部使用基于距離和角度信息的相似性公式進行局部模型樣本數據的選取。同時對樣本數據集的更新策略進行了相應的設計。采用上述方法建立煙氣含氧量預測模型的具體過程描述如下:
(1)確定出能夠覆蓋鍋爐燃燒過程各種工況的煙氣含氧量預測模型輸入輸出數據樣本集,數據樣本集中的數據,都是從實際現場采集而來,并且經過過失誤差和隨機誤差的消除,以及數據歸一化處理等;
(2)確定加權模糊C均值聚類算法的初始聚類中心V(0)和閾值ε,計算得到帶標記的l個聚類,并可確定每個聚類的聚類中心
(3)采用兩步搜索策略,得到當前輸入樣本數據Xa(包含燃料量,主給水流量,主蒸汽流量,排煙溫度,給水流量,高壓主汽閥前壓力,送風機入口風量,送風機動葉開度,引風機入口風量,共9個分量)的相似樣本集Ωk;
(4)采用基于改進PSO算法的支持向量機預測模型,估計出當前輸入樣本數據Xa所對應的煙氣含氧量y贊a;
(5)判斷當前輸入樣本數據Xa是否為新數據,如果是,則對數據樣本集中的數據進行聚類調整。
4 實際工業數據的驗證分析
為進一步說明基于即時學習策略的改進SVM煙氣含氧量預測模型的有效性,選取某月份的實際生產數據,經過數據預處理后得到500組有效數據,其中400組數據用于建模,另外100組數據用于算法校驗。
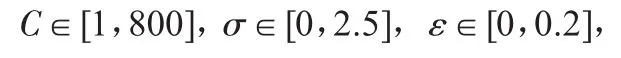
改進PSO算法的種群規模定為pop=30,迭代次數為Gen=200,慣性權重變化范圍為0.9~0.2,c1=c2=2。在每次局部SVM模型建立過程中,都采用改進PSO算法優化其C、σ、ε這3個參數,并用于該輸入數據Xa下的煙氣含氧量在線軟測量。
為了說明本文算法的有效性,與采用采用標準BP神經網絡和標準SVM方法獲得的煙氣含氧量預測建模進行對比分析。標準BP神經網絡采用3層結構,輸入節點數為9個,輸出節點數為1個,隱層節點數設為23個。隱層神經元傳遞函數采用S型正切函數tansig,輸出層神經元傳遞函數采用線性函數purelin。采用變學習率的前向誤差反向傳播學習算法訓練BP神經網絡,隨迭代的進行,學習率η從0.9線性減小至0.1。標準SVM建模方法,采用徑向基核函數,經過多次實驗SVM預測模型中的3個關鍵參數取為C∈32.15,σ=0.25,ε=0.08。
圖1至圖3給出了標準BP神經網絡、標準SVM和本文方法的煙氣含氧量預測曲線。并采用MSE和MAPE兩個指標作為量度,表1給出了三種建模方法的性能對比。其中MSE表示均方誤差,MAPE表示平均絕對百分比誤差,計算表達式為
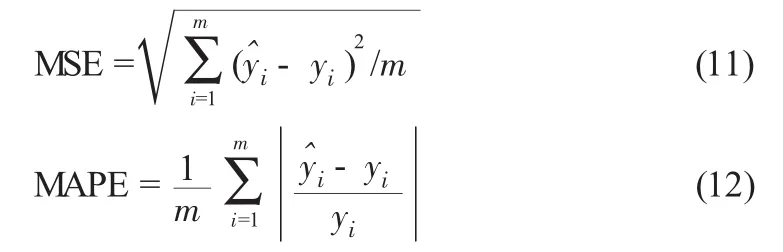
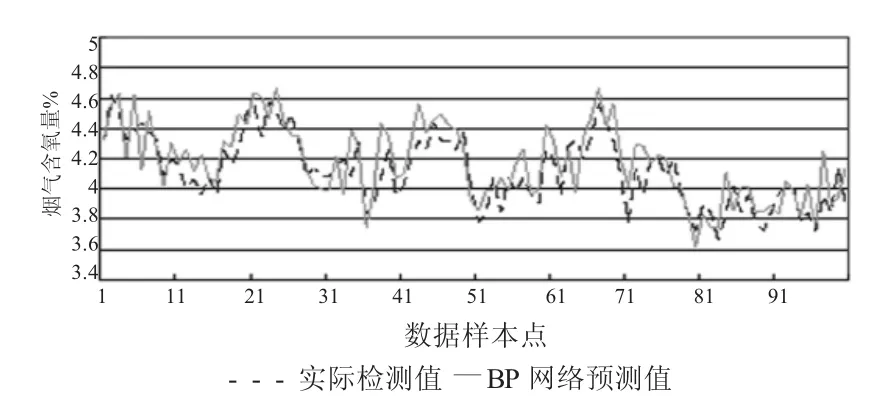
圖1 標準BP神經網絡煙氣含氧量預測曲線
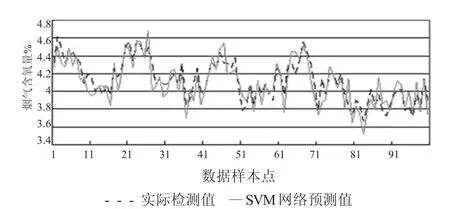
圖2 標準SVM煙氣含氧量預測曲線

圖3 基于即時學習策略的改進SVM煙氣含氧量預測曲線
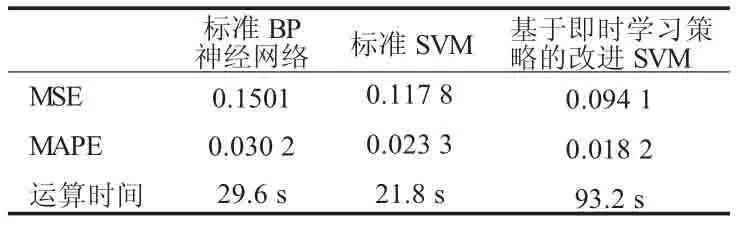
表1 三種建模方法性能統計表
由上圖可知,標準BP神經網絡、標準SVM和基于即時學習策略的改進SVM預測模型的預測值,與煙氣含氧量實際檢測值的變化都基本一致,但基于即時學習策略的改進SVM預測模型的跟隨效果更好。通過表1可知,基于即時學習策略的改進SVM預測方法的均方誤差和平均絕對百分比誤差,比標準BP神經網絡、標準SVM方法要明顯小很多,表現出較高建模精度,但標準BP神經網絡、標準SVM方法沒有建模過程,因此其算法開銷較小。對于煙氣含氧量的預測過程而言,基于即時學習策略的改進SVM預測方法的計算開銷是可以接受的,可以滿足鍋爐燃燒過程的實時性要求。特別地,隨著時間的推移,鍋爐的工況會發生緩慢的改變,使得采用標準BP神經網絡、標準SVM方法獲得的預測值誤差越來越大,而采用基于即時學習策略的改進SVM預測方法,可以有效克服該問題,預測的煙氣含氧量值比標準BP神經網絡、標準SVM方法將更精確,模型的泛化能力也更強。
綜合模型預測精度和鍋爐燃燒過程對實時性的考慮,本文提出的基于即時學習策略的改進SVM預測方法,具有優良的建模性能,適合于建立煙氣含氧量預測模型,煙氣含氧量預測值能滿足鍋爐燃燒過程對煙氣含氧量的誤差要求。
5 結束語
本文針對電廠煙氣含氧量難以進行有效預測的問題,從提高煙氣含氧量預測模型在線自適應能力的角度出發,提出一種基于即時學習策略的改進支持向量機建模方法,并基于電廠實際運行數據進行了仿真研究。通過與標準BP神經網絡和支持向量機等建模方法的比較,本文提出的煙氣含氧量預測模型具有更好的預測性能,雖然算法的計算開銷有所增加,但能夠滿足鍋爐燃燒過程煙氣含氧量預測的實時性要求,并及時為生產操作提供參考。
[1]姚之駒.2006年中國發電設備行業回顧及發展分析[J].電器工業,2007,(1):13-22.
[2]黃其勵.我國清潔高效燃煤發電技術[J].華電技術,2008,30(3):1-8.
[3]李 波.火力發電機組超臨界化的發展趨勢[C].中國電機工程學會2004年學術年會論文集,北京:中國電力出版社,2004.
[4]李振中,吳少華,黃其勵.超超臨界燃煤發電機組的技術選擇與產業化發展[C].中國電機工程學會2004年學術年會論文集,北京:中國電力出版社,2004.
[5]焦慶豐,朱光明,李 明,等.我國火電廠能耗現狀及節能潛力分析 [J].湖南電力,2008,28(1):20-23.
[6]韓 璞,王東風,翟永杰.基于神經網絡的火電廠煙氣含氧量軟測量[J].信息與控制,2001,30(2):189-192.
[7]趙 征,曾德良,田 亮,劉吉臻.基于數據融合的氧量軟測量研究[J].中國電機工程學報,2005,25(7):7-12.
[8]熊志化,張衛慶,趙 瑜,邵惠鶴.基于混合高斯過程的多模型熱力參數測量軟測量[J].中國電機工程學報,2005,25(7):30-33,40.
[9]熊喬弘,周黎輝,潘衛華,陳 麗.基于參數自適應SVR的火電廠熱工參數軟測量[J].華北電力大學學報,2008,35(2):94-97.
[10]王宏志,陳 帥,侍洪波.基于最小二乘支持向量機和PSO算法的電廠煙氣含氧量軟測量[J].熱力發電,2008,37(3):35-38.
[11]付忠廣,靳 濤,周麗君,戈志華,鄭 玲,楊勇平.復雜系統反向建模方法及偏最小二乘法建模應用研究[J].中國電機工程學報,2009,29(2):25-29.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
化工管理(2022年13期)2022-12-02 09:21:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
測控技術(2018年2期)2018-12-09 09:00:52
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
中國資源綜合利用(2016年2期)2016-01-22 07:27:41
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
