人工神經(jīng)網(wǎng)絡(luò)建立的環(huán)孢素A血藥濃度預(yù)測模型
2010-08-01 07:18:20余俊先史麗敏溫愛萍衛(wèi)紅濤王汝龍首都醫(yī)科大學附屬北京友誼醫(yī)院臨床藥理室北京00050南京醫(yī)科大學數(shù)學與計算機教研室江蘇南京009
中國藥物應(yīng)用與監(jiān)測 2010年1期
關(guān)鍵詞:模型
余俊先,夏 杰,史麗敏,李 珊,程 晟,溫愛萍,衛(wèi)紅濤,王汝龍(.首都醫(yī)科大學附屬北京友誼醫(yī)院臨床藥理室,北京 00050;.南京醫(yī)科大學數(shù)學與計算機教研室,江蘇 南京 009)
環(huán)孢素A(cyclosporine A, CsA)自上個世紀80年代應(yīng)用于臨床器官移植以來,已經(jīng)大大提高了患者的生存率和移植物的存活率。CsA是目前臨床常用的強效免疫抑制劑,但是應(yīng)用CsA的最大困擾是其治療窗狹窄,藥動學參數(shù)個體差異非常大,用藥量過大會導(dǎo)致患者發(fā)生肝腎功能損害[1-2],用藥量過小則會出現(xiàn)排斥反應(yīng),嚴重影響器官移植受者的治療效果[3]。現(xiàn)行的CsA給藥方案,首次劑量一般依據(jù)體重,此后則參考CsA的測定濃度,常需要進行頻繁的劑量調(diào)整。有些器官移植,特別是腎移植,由于患者生理病理因素的影響,CsA 生物利用度可相差10~20倍[4],因而依據(jù)血藥濃度再調(diào)整給藥劑量具有滯后性。本研究借助人工神經(jīng)網(wǎng)絡(luò)技術(shù),嘗試對CsA的血藥濃度進行前瞻性的預(yù)測,以期最大限度地提高藥物療效,降低毒副作用。
1 研究方法
1.1 資料來源
回顧性地收集本院2005-2007年的所有腎移植病例,這些病例住院期間均接受CsA(新山地明)、MMF(麥考酚酸莫酯)和Pred(強的松)三聯(lián)免疫抑制給藥方案,并剔除部分不合格樣本:住院病歷記錄不完整,合并用藥中使用了影響CsA濃度的藥物,在1~ 2個月內(nèi)出現(xiàn)移植器官明顯排異,以及嚴重并發(fā)癥的病例。共獲得160份有效病例。
1.2 變量篩選
根據(jù)臨床意義并結(jié)合相關(guān)文獻資料,篩選出可能影響CsA血藥濃度的因素,包括性別(GE)、年齡(AG)、體重(WE)、移植后天數(shù)(PTD)、肌酐(CR)、谷丙轉(zhuǎn)氨酶(ALT)、堿性磷酸酶(ALP)、尿素氮(BUN)、血糖(GLU)、白細胞(WBC)、血紅蛋白(HGB)、紅細胞壓積(HCT)、用藥劑量(D)、CsA全血谷濃度(C0)等,所有資料錄入Excel表格。其中,各項生理生化指標均為自動生化儀測定結(jié)果,C0測定采用特異性單克隆試劑盒的熒光偏振免疫法(TDx分析儀,美國Abbott公司)。
1.3 建模數(shù)據(jù)庫和GA-BP模型構(gòu)建
從已收集160份有效病例中,順序取135份,其中男性96例,女性39例,共獲建模數(shù)據(jù)579組。這些病例隨機分成兩組,其中90例作為訓練組樣本,45例作為測試組樣本。GA-BP(genetic algorithm-back propagation,遺傳算法優(yōu)化的反向傳播算法)模型構(gòu)建原理:先將自變量及因變量的原始數(shù)據(jù)歸一化處理,并將其分別作為BP神經(jīng)網(wǎng)絡(luò)的輸入和輸出;利用GA搜索全局范圍內(nèi)的優(yōu)化初值,然后以此作為BP算法的初始權(quán)值對網(wǎng)絡(luò)進行訓練,獲得進一步優(yōu)化的權(quán)值和閾值,即完成GA-BP模型的構(gòu)建。構(gòu)建GA-BP模型的整個流程如圖1所示。
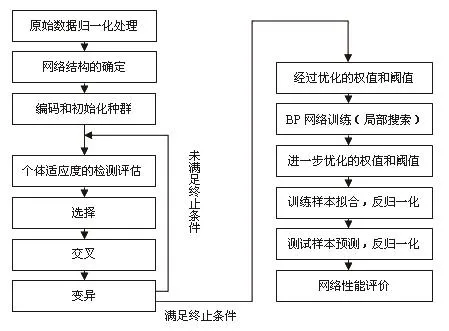
圖1 GA-BP模型的構(gòu)建流程Fig 1 Construction flow-sheet of GA-BP model
1.4 血藥濃度預(yù)測模塊的建立
首先,采用Matlab語言實現(xiàn)遺傳優(yōu)化BP神經(jīng)網(wǎng)絡(luò)(GA-BP)算法,三層GA-BP神經(jīng)網(wǎng)絡(luò)實際上是兩層函數(shù)f1和f2,其形式如以下4個公式:
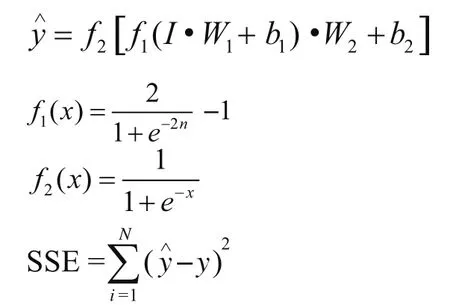
其中W1、b1分別為第一層到第二層的權(quán)重和閾值;W2、b2分別為第二層到第三層神經(jīng)元的權(quán)重和閾值;I表示一系列自變量的值組成的向量。遺傳算法是構(gòu)建一個W1、b1、W2、b2的隨機數(shù)矩陣作為初始化種群,然后通過選擇、交叉、變異的遺傳操作,以從種群中尋找使得SSE(誤差平方和)最小的W1、b1、W2、b2;以遺傳算法優(yōu)化的W1、b1、W2、b2作為初始值,仍然通過上述公式通過誤差反饋調(diào)整權(quán)值和閾值(即BP算法)尋找使得SSE最小的W1、b1、W2、b2,這便是GA-BP模型的核心。當該模型用于預(yù)測時,通過輸入向量I,根據(jù)以上公式,可計算出血藥濃度值。然后,使用編程工具Visual Basic 6.0和Matlab語言編譯工具MIDEVA 4.5開發(fā)CsA血藥濃度預(yù)測模塊。最后,采用該模塊預(yù)測血藥濃度,順序取10個樣本(病例),每個樣本預(yù)測3個濃度,并將該預(yù)測濃度與其實驗室的測定濃度進行對比,驗證模型的預(yù)測性能(偏差)。
2 結(jié)果
2.1 血藥濃度預(yù)測模型
血藥濃度預(yù)測模型的界面見圖2。首先,確定建模的訓練樣本數(shù)量(總樣本的2/3),點擊“確定”,進行隨機分組訓練;根據(jù)大量數(shù)據(jù)的回歸分析,確定影響CsA血藥濃度的因素(變量)包括性別、前次的HCT、C0,以及本次的ALT、CR、HGB、dose1,點擊“確定”,彈出血藥濃度預(yù)測模型構(gòu)建窗口。其次,血藥濃度預(yù)測模型構(gòu)建的參數(shù)設(shè)置,具體見圖3。最后,點擊“GA-BP網(wǎng)絡(luò)訓練”,進行遺傳算法尋優(yōu)和BP訓練,經(jīng)過多次訓練后,根據(jù)預(yù)測精度確定模型是否完成構(gòu)建過程;一般情況,當精度合適(訓練集預(yù)測精度與測試集預(yù)測精度接近)時,就可以保存最優(yōu)的權(quán)值,進行血藥濃度預(yù)測。

圖2 建立CsA血藥濃度預(yù)測模型的界面Fig 2 Page for building up predictive model on plasma level of CsA
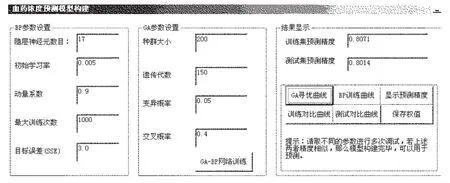
圖3 CsA血藥濃度預(yù)測模型參數(shù)設(shè)置的界面Fig 3 Page for parameter setting of predictive model on plasma level of CsA
2.2 血藥濃度預(yù)測結(jié)果
打開血藥濃度預(yù)測窗口(圖4),輸入相應(yīng)的變量值,點擊“獲得預(yù)測值”,即可獲得預(yù)測的血藥濃度值。從未參與建模的25個樣本(病例)中順序取10個樣本,每個樣本預(yù)測3個濃度,并與測定濃度進行比較,檢驗預(yù)測效果。結(jié)果,在參與預(yù)測的30個濃度中,預(yù)測誤差小于10%的有22個濃度,誤差在10% ~20%之間的有7個濃度,誤差大于20%的有1個濃度(表1)。這一結(jié)果初步表明,神經(jīng)網(wǎng)絡(luò)建立的模型可嘗試用于CsA濃度的預(yù)測研究。
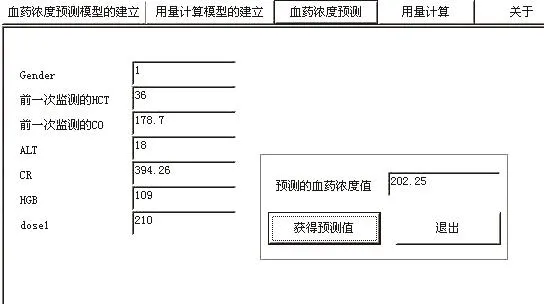
圖4 CsA血藥濃度預(yù)測窗口Fig 4 Predictive window of plasma level of cyclosporine A
3 討論
治療藥物的濃度監(jiān)測,在特殊群體中顯得尤為重要[5],它是提高藥物療效、減少藥物毒性的有效手段,也是實現(xiàn)臨床給藥方案個體化的基礎(chǔ)。對某些治療窗窄且監(jiān)測費用較高的藥物如CsA而言,除了常規(guī)的濃度監(jiān)測外,可以嘗試進行前瞻性的預(yù)測研究。
經(jīng)典的CsA 濃度預(yù)測,應(yīng)用最多的是采用基于非線性混合效應(yīng)模型的群體藥動學程序—NONMEN 程序,這種預(yù)測模型已經(jīng)得到廣泛應(yīng)用,并為大家所接受。但是,根據(jù)群體藥動學結(jié)果設(shè)計給藥方案也有一定的局限性,因為真實的生物系統(tǒng)是極其復(fù)雜的,藥物在人體內(nèi)的代謝過程千差萬別,僅靠有限的數(shù)學結(jié)構(gòu)模型很難理想地確定藥動學變量、藥物輸入與藥效學之間的定量關(guān)系。人工神經(jīng)網(wǎng)絡(luò)(artificial neural network, ANN)技術(shù)是在現(xiàn)代神經(jīng)科學研究的基礎(chǔ)上對生物神經(jīng)系統(tǒng)的結(jié)構(gòu)和功能進行數(shù)學抽象、簡化和模仿而逐步發(fā)展起來的,根據(jù)生物神經(jīng)系統(tǒng)對外界系統(tǒng)的認知過程,用以模擬人的大腦神經(jīng)處理信息的方式,進行信息并行處理和非線性轉(zhuǎn)換的復(fù)雜網(wǎng)絡(luò)系統(tǒng)。傳統(tǒng)藥動學建立數(shù)學模型本身需要假定一些條件,這些條件不一定符合現(xiàn)實的環(huán)境,是一種理想狀態(tài);人工神經(jīng)網(wǎng)絡(luò)無須假設(shè)藥物行為模型,因而能夠避免模型誤差。此外,只要數(shù)據(jù)量大,神經(jīng)網(wǎng)絡(luò)在學習的過程中,能夠自我學習,自我調(diào)整,尋找合理的非線性關(guān)系;而對于非線性,有的是無法建立數(shù)學模型的。國內(nèi)有人嘗試用國外的EasyNN-plus8.0全功能試用軟件來預(yù)測CsA濃度[6]。EasyNN-plus8.0程序的建模數(shù)據(jù)來源于白種人的臨床資料,而本研究嘗試建立的程序,建模和預(yù)測數(shù)據(jù)均取自中國人,可能更具有參考價值。當然,除了藥物本身外,影響CsA濃度的因素非常多,包括患者的生理病理狀態(tài)、CsA代謝基因CYP3A4和CYP3A5的遺傳變異[7]以及合并用藥[8]等,都是建立預(yù)測模型需要考慮的問題。本文所做的工作只是初步的嘗試性研究,建立成熟的預(yù)測程序還需進行更深入的后續(xù)工作。
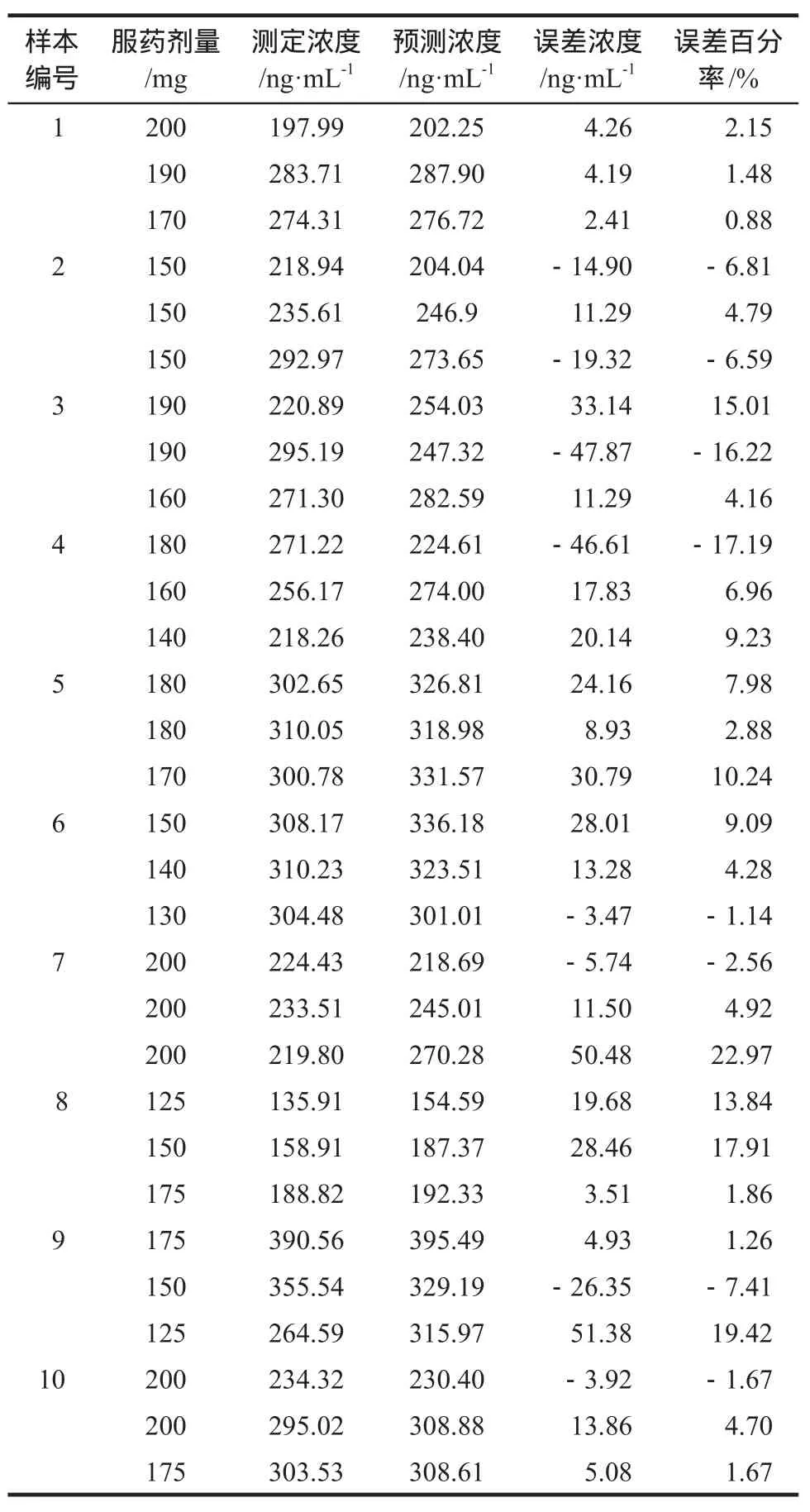
表1 環(huán)孢素A的測定濃度和預(yù)測濃度值比較.n = 30Tab 1 Comparison of actual levels and predictive levels in cyclosporine A.n = 30
[1] 孫增先,周金玉,張騫峰,等.肝腎移植受者環(huán)孢素AUC監(jiān)測評估[J].中國藥學雜志, 2006,41(21):1673-1675.
[2] Tsunoda SM, Aweeka FT.The use of therapeutic drug monitoring to optimise immunosuppressive therapy[J].Clin Pharmacokinet,1996, 30(2):107-140.
[3] 鄭芝欣,翟保同.環(huán)孢素A血藥濃度監(jiān)測及個體化給藥方案設(shè)計在腎移植病人中的應(yīng)用[J].醫(yī)學信息,2006,19(3):503-504.
[4] 李芹,趙秀杰,唐紹芬,等.環(huán)孢素A 人體藥動學影響因素分析[J].中國醫(yī)院藥學雜志,2002,22(7):431-432.
[5] 陳騉,王睿.特殊人群的治療藥物監(jiān)測[J].中國藥物應(yīng)用與監(jiān)測,2004,1(4):33-36.
[6] 徐楚鴻,艾又生,陳華庭.人工神經(jīng)網(wǎng)絡(luò)法預(yù)測腎移植術(shù)后患者環(huán)孢素A 的血藥濃度[J].中國醫(yī)院藥學雜志,2008,28(4):276-278.
[7] 胡永芳,翟所迪,邱雯.CYP3A5*3和CYP3A4*18B基因多態(tài)性對腎移植患者環(huán)孢素藥代動力學的影響[J].中國藥理學通報,2009,25(3):378-382.
[8] 牟燕,李元媛,林琳,等.合并用藥對環(huán)孢素A血藥濃度的影響[J].中國藥物應(yīng)用與監(jiān)測,2006,3(1):20-22.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
