基于參考標簽的射頻識別定位算法研究與應用
2010-08-04 08:32:52王遠哲毛陸虹劉輝肖基誥
通信學報 2010年2期
王遠哲,毛陸虹,劉輝,肖基誥
(1.天津大學 電子信息工程學院,天津 300072;2.香港大學 電機電子工程系,香港)
1 引言
室內定位就是要在室內環境下對目標進行追蹤定位,且定位的誤差在許可的范圍之內。與室外環境不同,室內環境通常更為復雜,各種干擾因素更多,現有的很多定位技術,如GPS(global positioning system)定位,紅外定位等,考慮到定位精度、成本、可行性等方面,并不適合于室內定位[1,2]。射頻識別定位技術以其非接觸、非視距、高靈敏度和低成本的優點,正在成為室內定位系統的優選技術,受到人們越來越多的關注[3~6]。
射頻識別定位技術使用的定位依據包括入射信號的強度值、角度值和時間差等。GPS系統就是使用時間差進行定位[7],但是這種方法成本較高,主要是用在大范圍的定位,并不適合于空間狹小環境復雜的室內定位。使用信號角度值進行定位的原理是通過相鄰天線接收到的信號的相位差計算信號的入射角度。但是這種方法需要天線陣列,硬件開銷較大。基于接收信號的強度值的定位方法需要閱讀器提供接收到的射頻標簽信號的強度值作為定位依據。這種方法具有低功率和低成本的優點,使得它已較多用于實際的定位系統中,如LANDMARC[3]、RADAR[8]、SpotOn[9]等。基于場強值進行定位的現有的算法主要包括解析算法[10]、估值算法[11,12]、基于參考標簽的最近鄰居算法[3]幾大類。
最近鄰居定位算法在 LANDMARC的定位系統中被采用。它在環境中按照一定的方式布置一定數目位置已知的參考標簽作為定位的基準,通過比較閱讀器測得目標標簽場強值與閱讀器測得參考標簽場強值的相對大小來對目標標簽進行定位。這種算法有以下幾個優點。首先,這種算法采用多標簽代替多閱讀器,可以降低系統成本。其次,參考標簽和目標標簽處于同樣的環境之中,可以有效地抵消環境因素的影響。第三,這種算法對于非視距的定位效果較好。
但是,LANDMARC系統提供的精度有限。LANDMARC系統使用的閱讀器能夠提供信號強度的8個等級,而本文中使用的閱讀器能夠提供256個等級,硬件條件的升級給優化算法提供了可能。同時,由于RFID標簽讀取不穩定的影響,經常會出現某些閱讀器讀取某些標簽的場強值失敗或者出錯的情況。由于一個參考標簽要同時被幾個閱讀器讀取,而只要有其中一個閱讀器的讀取失敗就會對這個參考標簽參與定位造成很大影響,導致很多參考標簽喪失了參考價值。另外,由于各個閱讀器的增益不同或者離目標標簽的距離不同,造成在目標標簽處的各向異性,即各個方向上同樣的距離反映出來的場強差不同,影響了最近鄰標簽的選取和權值的設定。在這些惡劣的情況下,現有的最近鄰居算法定位精度不高,最大誤差比較大。為此,提出了動態k值設定的方法,參考標簽可信度的概念,最近鄰標簽偏差校正算法并采用了目標標簽歷史軌跡算法。
基于Intel的R1000射頻識別開發平臺,用多天線的時分復用代替多閱讀器,搭建了一個定位系統,并且開發了相應的界面軟件。通過實測,改進后定位算法提高了定位精度和惡劣環境下的適應能力。
2 最近鄰居定位算法介紹[3,13,14]
下面簡要介紹最近鄰算法的具體實現。閱讀器和標簽的排列方式如圖1所示。現假設共有m個閱讀器和n個參考標簽以及u個目標標簽。m個閱讀器分別讀出n個參考標簽和u個目標標簽發送給閱讀器的信號場強值,在LANDMARC系統中此場強值是1~8總共8個等級。把上述場強值寫成向量的形式,記目標標簽的場強值向量為-→=(T1,T2,…,Tm),其中T代表第j個閱讀器讀到目標---標-→簽的場強值;參考標簽的場強值向量為Rj(i)=(R1(i),R2(i) ,…,Rm(i )),其中 Rj(i)代表第j個閱讀器讀到參考標簽i的場強值。為了判斷參考標簽與目標標簽的近鄰程度,對于每個目標標簽p,p∈[1,u],定義表征第i個參考標簽與目標標簽的距離大小,Ei越小表示距離越近,i∈[1,n]。
通過比較Ei值的大小,選出k個離目標標簽最近的參考標簽稱為最近鄰標簽,其標簽序號組成集合Κ。其中k值的大小可以根據不同的應用環境人為設定。定義這k個最近鄰標簽的權值為
這樣,目標標簽的位置可以由式(2)得出
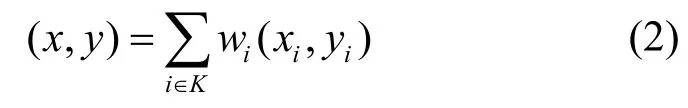
LANDMARC系統使用16個參考標簽,4個閱讀器(閱讀器可以得到信號強度的 8個等級值),參考標簽之間距離約為 1~2m。在這種情況下,得到的定位誤差最大約為2m,平均誤差約為1m。
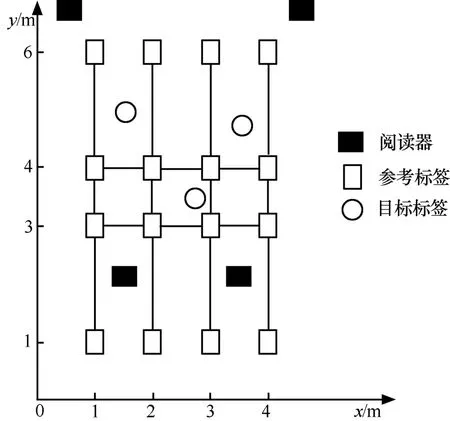
圖1 定位系統標簽擺放示意圖
3 參考標簽算法不同參數設定對于定位精度的影響
3.1 參考標簽分布和最近鄰數目 k值的設定對于定位精度的影響
目標標簽位置的確定是根據一定數目的(k個)參考標簽的位置加權得到的,故而參考標簽的排列方式和最近鄰數目 k值的設定會對定位的結果產生極大的影響。在實際的應用系統中,根據具體的定位需要,參考標簽的分布和k值的設定可能大不相同。比如在空曠的環境中對物體進行定位,一般采取網格式的參考標簽排列方法。在生產流水線或者運輸路線中對于貨物進行定位,貨物一般來說不會脫離流水線或者道路,故而只需要進行一維的定位,參考標簽一般沿著流水線或者道路線形排列,而k值一般取2(或者 3)。在倉庫中對貨物進行定位,貨物一般會位于某一個貨架上,故可以在每一個貨架的四周布置 4個參考標簽,k值設置為4,就可以通過定位算法找到貨物所在的具體貨架,如圖2所示。
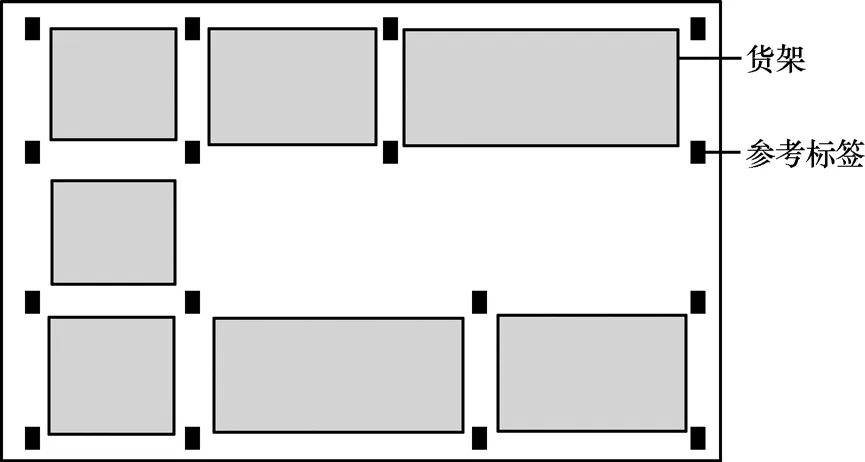
圖2 倉庫內參考標簽擺放示意圖
3.2 權值定義方法對于定位精度的影響
最近鄰標簽權值的確定有很多種方法,但是必須滿足2個基本的條件:1) 離目標標簽越近的參考標簽(即E值越小),權值W必須越大。即W(E)必須是單調的減函數;2) 權值之和必須為1,即 W1+W2+…Wk=1。(注W的下標對第2節中w的下標進行了重排。)除了最近鄰居算法中的二階權值的設定方法,還有一階權值和對數權值的設定方法,如下所示。

為了考察不同權值設定方法對結果的影響,定義單一標簽依賴程度 ξ=(Wi)max,表征定位結果與距目標標簽最近的一個參考標簽的接近程度。ξ越大代表距目標最近的標簽的權重越大,定位結果也就越接近這個標簽。
下面用一個具體的例子分析3種權值設定方法的單一標簽依賴程度。假設K=5,5個最近鄰標簽的E值分別為其中x<40,故剩下的4個標簽E>40。在x的不同取值下分別使用3種權值設定方法計算W值,得到3個不同的ξ,如圖3所示。由圖3可見,二階權值設定方法的單一標簽依賴程度最高,一階權值次之,對數權值最低。在實際應用中要根據不同的環境選擇不同的方法。如果信號強度隨著距離的增加衰減嚴重的話,一般采用單一標簽依賴程度低的權值設定方法,否則目標會完全定位到最近的一個參考標簽的位置;如果信號強度隨著距離的增加衰減較小的話,一般可以采用單一標簽依賴程度高的權值設定方法,否則目標會完全定位在幾個最近鄰標簽的幾何中心。
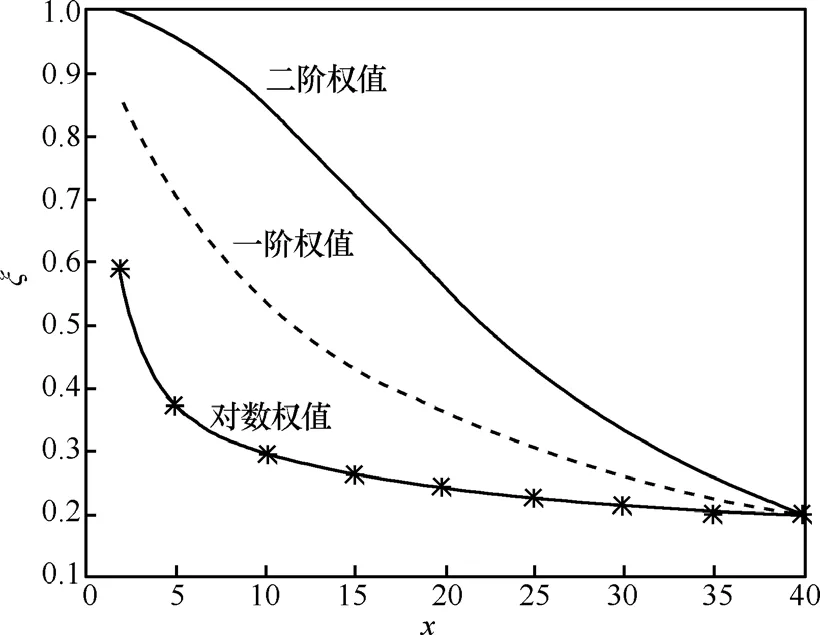
圖3 不同的權值設定方法單一標簽依賴程度曲線
4 基于最近鄰居提出的新型定位算法
4.1 目標標簽歷史軌跡算法
該改進來源于文獻[14],由于在實際測試中發現加入該改進對精度有一定作用,故予以采用。為了敘述的完整性,在這里進行了簡要的描述。詳細內容可以參考文獻[14]。
由于目標標簽的運動速度有限,在一段很小的時間內目標標簽的位置不可能發生很大的變化。因此,可以利用目標標簽的歷史位置加權估計當前位置,這樣做的好處是可以減小隨機誤差和隨機電磁干擾對定位精度的影響。
設要獲取當前時刻目標標簽的位置。在t0時刻和t0時刻之前與t0接近的s個時刻 t1,t2,t3,…,ts,分別進行測量,每一次的測量均用上面所述的算法得到一個估計值。設當前時刻估計值為(x0,y0),設第i次歷史測量得到的估計值為(xi,yi),i=1,2,…,s,考慮歷史軌跡后得到的估計值為(x,y)。考察殘差加權函數[11]:

當Q值取得極小值的時候,可以得到最佳的估計位置(x,y)。為此,上式對x和y分別求偏導數,令偏導數等于0,可以解出(x,y)值如下:
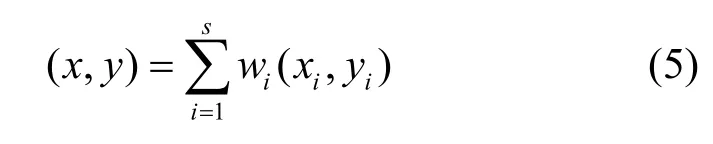
其中wi值如下,表示每個歷史位置的權值:
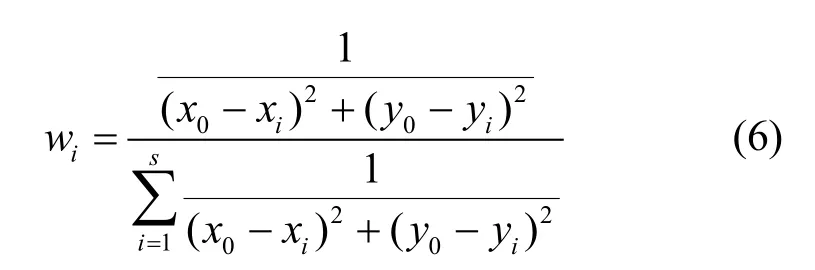
由wi的表達式可見,如果歷史位置(xi, yi)與當前位置(x0,y0)之間距離越近,則wi越大,它在估計值中的權重也就越大。實踐表明,在進行上述修改之后,算法能夠更好地克服隨機干擾的影響,準確度和穩定性得到了提高。
4.2 動態k值設定方法
在實際的測量中經常會出現某些參考標簽的場強向量有一個或幾個分量讀不到的情況,如果這些標簽正好離目標標簽最近,就可能導致目標標簽最近鄰標簽選擇的極大偏差,從而導致定位結果偏離。例如在網格形的參考標簽排列方式中,如果目標標簽周圍的4個標簽同側2個有場強沒有讀到,則最近鄰標簽很可能選成目標標簽另一側的網格4角的4個標簽,導致定位結果誤差很大。為了避免這種狀況發生,可以增大k值的設定,使更多的最近鄰標簽參與到目標標簽定位的加權中去,以減小定位誤差。
在定位程序的初始化時,可以先給k設一個初始值k0。在硬件操控程序中,對于讀不到的場強值分量,可以將其人為的設定成一個固定的場強值(一般可以設成一個負的大值)。在定位程序中,檢測出現了人為設定的場強值的標簽的個數,即場強向量中有某一或幾個分量沒讀到的標簽的個數。如果檢測到c個,則修正k值為 k=k0+c 。
4.3 參考標簽可信度的概念
在實際測量過程中發現,在閱讀器讀取每個標簽的場強時,總會出現個別場強值出錯(過大或過小),或者甚至讀不到的情況(讀不到時一般由程序設置為負的一個大值)。而只要有一個參考標簽的場強值偏離特別大,而偏離值恰好與目標標簽場強值接近的話,這個標簽就會被選為最近鄰標簽從而使定位出現極大的偏差。為了防止這種誤差,定義了參考標簽的可信度的概念。一般來說,一個參考標簽在某個閱讀器上的場強值會在它周圍的4標簽在這個閱讀器上場強值之間。假設共有m個閱讀器,則某個參考標簽在各個閱讀器上會有m個場強值,它上下左右4個標簽在各個閱讀器上也各有m個值。設x(j)為某個參考標簽在第j個閱讀器上的場強值,min(j)為在第j個閱讀器上此標簽上下左右4個標簽場強值的最小值,max(j)為最大值(j=1,2,…,m)。設使 x(j)∈[min(j),max(j)]的j值共有M個。現分段定義可信度Y如下:
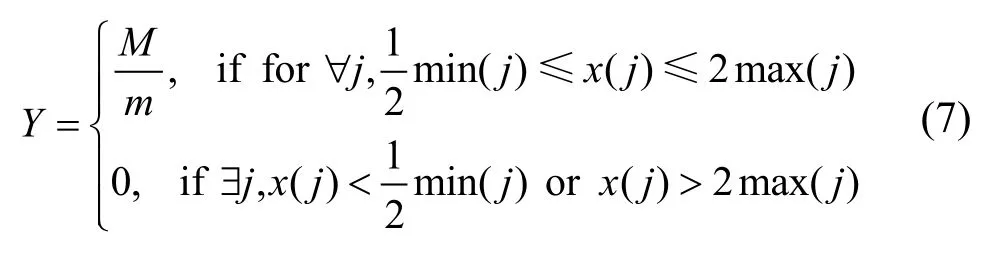
Y在0到1之間取值,越大表示可信度越高。如果對于任意 j有 min(j)<x(j)<max(j)則 Y值取 1。在選擇最近鄰標簽時,通過比較選擇 的值最小的k個標簽。同時最近鄰標簽的權值修正為
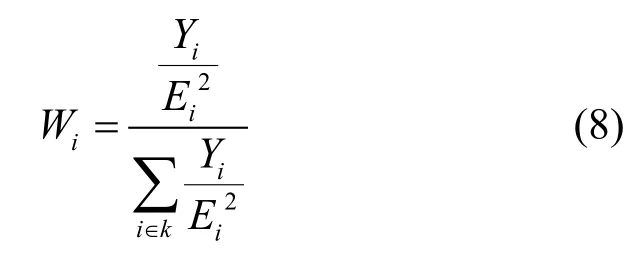
在實際的應用中,由于各種原因可能導致某些參考標簽失效,或者位置偏離了設定的位置(尤其是在野外),或者讀取時失敗或者出錯的情況。進行這種改進之后,能有效地防止個別參考標簽讀取出錯對于結果的影響。
4.4 最近鄰標簽偏差的自校正
閱讀器讀到的標簽的場強值隨距離的變化關系并不是線性的,而是一條類似于負指數的曲線。在距離近的時候,場強值隨距離的變化比較快(場強對距離導數的絕對值大);在距離遠的時候,場強值隨距離的變化比較慢(場強對距離導數的絕對值小)。這樣,如果目標標簽的位置離某一個閱讀器較近而離其他的閱讀器較遠時,近處的閱讀器讀到的標簽場強值變化陡峭,導致這個閱讀器的方向上的距離差L對于E值的貢獻大于其他3個方向上同樣的距離差L對于E值的貢獻。這樣會導致最近鄰標簽選取的偏差和權值的偏差,對定位結果造成影響。或者由于各個方向上閱讀器的增益不同,導致各個方向上同樣距離讀到的場強值不同,也會導致各向異性,對定位結果造成影響。
為了解決這種各向異性導致的定位偏差,可以用最近鄰標簽的定位偏差作為校正。具體操作如下。首先采用 4.1節中的方法選擇出 k個最近鄰標簽,然后分別把這k個參考標簽作為目標標簽,把剩下的n-1個參考標簽作為參考標簽,使用 4.1節中的方法進行計算,得到每一個最近鄰參考標簽的估計位置,記為(xi′,yi′),i=1,2,…,k。然后把這k個最近鄰標簽的估計位置和它們的實際位置作比較,得到修正值:
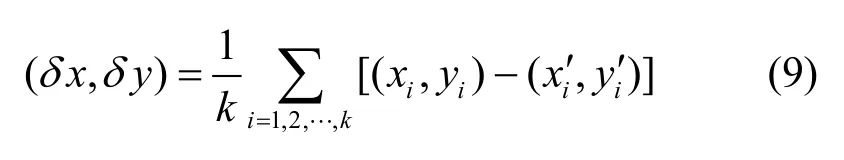
最后使用這個修正值對目標標簽的估計位置進行校正,得到:
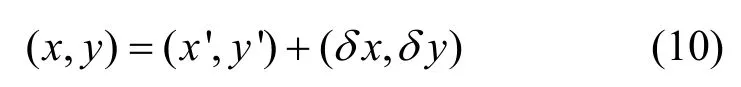
4.5 算法的最終流程
綜合以上幾點改進,算法的最終流程如圖4所示。
下面是對算法流程的詳細說明。
1) 設置各個參數的值,如閱讀器數目m,參考標簽數目n,最近鄰標簽數目k,歷史值讀取次數s;
2) 各個閱讀器讀取各個標簽的場強值;
3) 檢測2中讀到的場強值中設定值的數量(即讀取失敗的場強值的數量),修正k值;
4) 計算各個參考標簽的E值;
5) 計算各個參考標簽的可信度Y;
6) 根據E值和Y值選擇k個最近鄰標簽;
7) 計算各個最近鄰標簽的權值;
8) 最近鄰標簽位置加權得到估計值;
9) 以每個最近鄰標簽當做目標標簽,其他n-1個參考標簽作為參考標簽,重復4)~8)的步驟,得到各個最近鄰標簽位置估計值,并計算其偏差;
10) 用偏差值對目標標簽估計值進行校正,得到新的估計值;
11) 重復2)~10)的步驟s+1次,最后一次的估計值為當前值,前s次的估計值為歷史值;
12) 計算各個歷史位置的權值;
13) 加權得到最后的目標標簽位置估計值。
5 硬件系統和實際測試結果
基于Intel的R1000射頻識別開發平臺,搭建了定位的硬件系統。硬件系統的主要構件包括Intel R1000射頻識別開發平臺、PC機、遠距離閱讀器天線、XCTF-8030a型無源RFID標簽等。該系統可以讀出0~255共256個等級的信號強度值(遠大于LANDMARC系統的8個等級[3]),使用3對天線的分時復用代替多閱讀器,用PC機作為主機。還根據上面提出的算法開發了界面軟件,搭建了軟硬件協同的定位系統。軟件的界面如圖5所示。
圖5 定位界面軟件
分別在空曠的大廳和開放實驗室內搭建了定位系統,參考標簽按照界面上的排列方式擺放,網格的邊長為0.7m。定義測量誤差[3]為其中(x,y)是目標標簽的估計,(x?,y?)表示目標標簽的實際位置。使用統計學概率分布函數的方法,e為實際測量中的定位誤差(單位為 m),L為概率分布函數的橫坐標(單位也是m),定義測量誤差e小于橫坐標 L的測量結果出現的次數占總測量次數的百分比為P(e<L),如P(e<0.5)即為所有測量誤差結果中,小于0.5m的e出現的次數占總測量次數的百分比。在連續10h內進行了大量的測量,根據測量結果繪制出 P(e<L)的曲線。
為了研究各種參數的設置對于定位精度的影響,使用本文提出的算法,在其他條件相同的情況下,分別改變k0值設定和權值設定方法,對結果進行分析。在空曠大廳中,采用本文提出的算法,權值設定為二階權值,分別令k0等于3、4、5進行實驗,得到的結果如圖6所示。可見k0=4時定位效果最好,k0=5次之,k0=3較差。
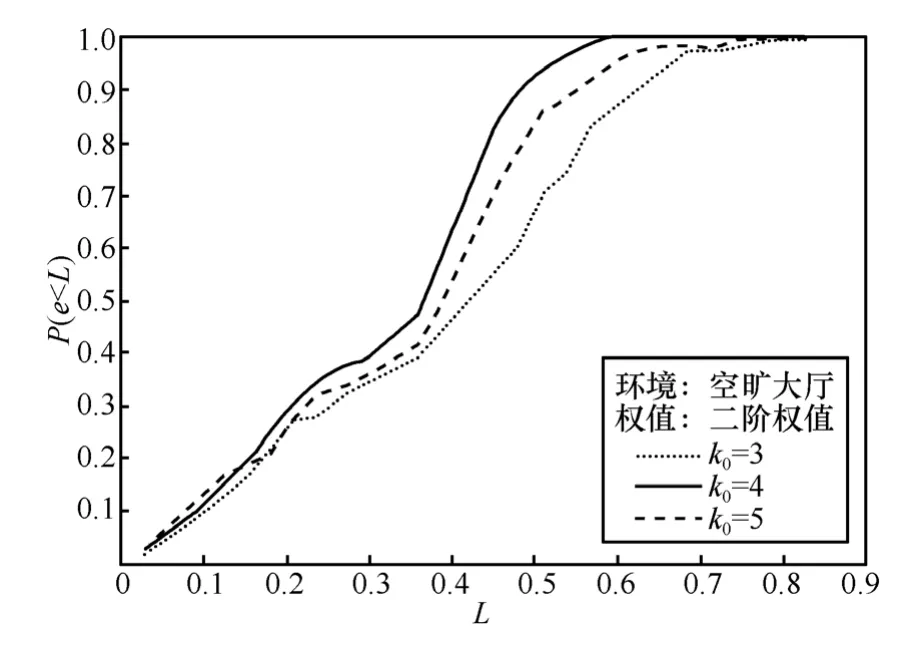
圖6 不同k0值的設定對于定位結果的影響
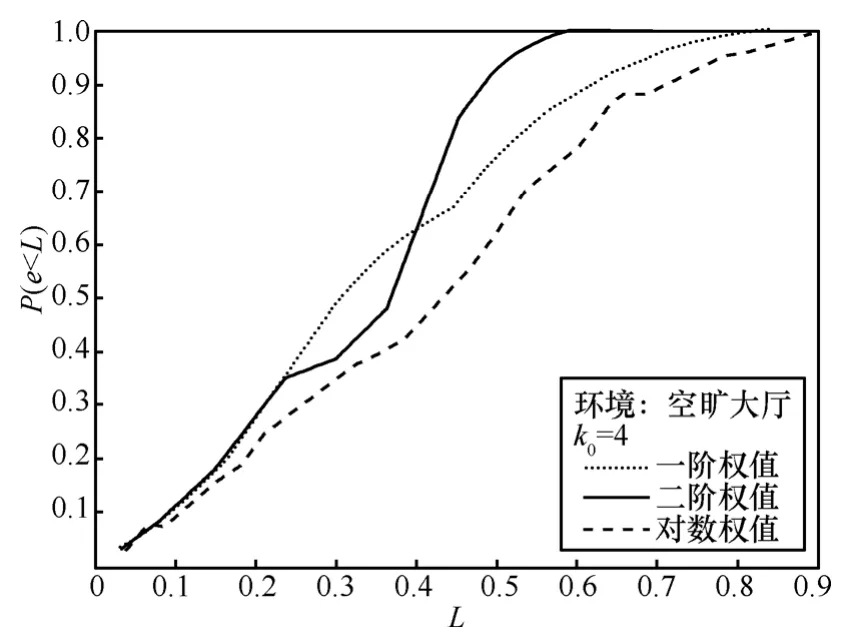
圖7 不同的權值設定方法對于定位結果的影響
在空曠大廳中,采用本文提出的算法,k0設置為 4,分別采用一階、二階和對數的權值設定方法進行實驗,得到的結果如圖7所示。可見二階權值設定方法精度最好,一階權值在誤差較小的時候定位精度高于二階權值,但是當環境惡劣時定位精度下降嚴重,最大定位誤差大于一階權值。對數權值定位精度較差。在最理想的情況下(k0設置為4,權值取二階權值),分別在開放實驗室和空曠大廳內進行實驗,結果分別用原有的最近鄰居算法和本文提出的改進后的算法進行計算。其中原有的最近鄰居定位算法的測量也是在上面提出的 256等級的硬件系統上進行的,因此排除了硬件不同的影響,原算法和改進算法得到的不同結果均是由于算法改進而非硬件升級造成的。得到的結果如圖8和圖9所示。由圖可見,在同樣的256等級的硬件平臺上,采用新提出的改進算法比使用現有的最近鄰居算法定位精度明顯提高。不論是在空曠大廳還是在開放實驗室,均可看出2條曲線在L值較小的時候擬合較好,在L值比較大時有明顯分離。這表明在比較理想的測試結果中,2種算法定位結果的偏差不大。在測試結果情況比較惡劣的情況下,本文提出的算法的精確度顯著高于最近鄰居算法,說明本文提出的算法在惡劣環境條件下會顯示出更精確與穩定的定位結果。
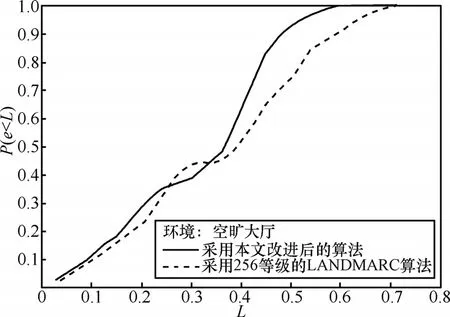
圖8 空曠大廳內定位誤差分布曲線
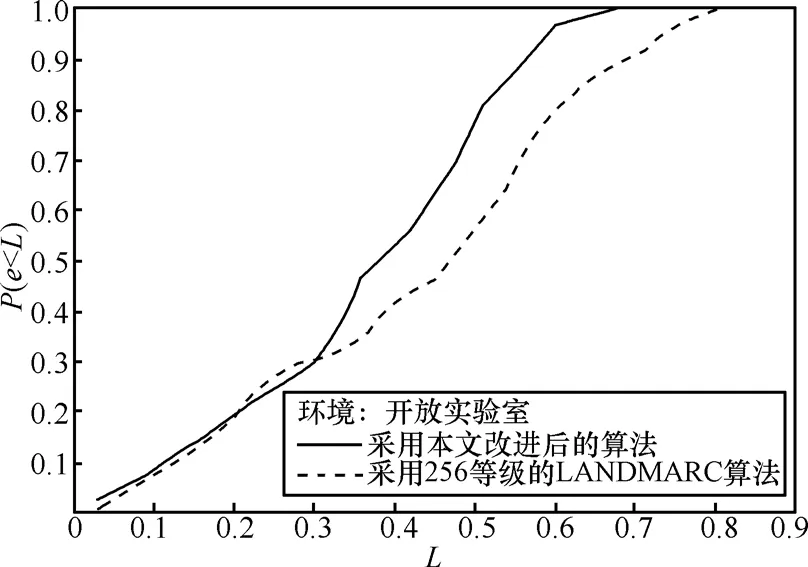
圖9 開放實驗室內定位誤差分布曲線
經過計算,在同樣的256等級的硬件平臺上,在空曠大廳內,使用最近鄰居算法定位的平均誤差是0.404 6m,最大誤差是0.72m;使用新型改進算法定位的平均誤差是0.331 0m,最大誤差是0.60m。在開放實驗室內,使用最近鄰居算法定位的平均誤差是0.441 6m,最大誤差是0.81m;使用新型算法平均誤差是0.379 2m,最大誤差是0.69m。
6 結束語
本文基于最近鄰居定位算法,提出了新型的改進算法。基于R1000射頻識別開發平臺,使用多天線分時復用代替多閱讀器搭建了定位的硬件系統,并且開發了定位的軟件界面。本文的測量都是在人員走動、物品擺放、電磁干擾等情況都未加限制的情況下進行的,貼近實際的應用環境。通過實際測量,本文提出的改進算法在惡劣環境下的適應能力和穩定度顯著提高,定位的最大誤差減小,且平均精度比最近鄰居算法有了20%左右的提高。
[1] YAMASAKI R,OGINO A,TAMAKI T.TDOA: location system for IEEE 802.11b WLAN[A].Wireless Communications and Networking Conference,2005 IEEE[C].New Orleans,LA,USA,2005.2338-2343.
[2] HEADLEY W,DASUVA C,BUEHRER R M.Indoor location positioning of non-active objects using ultra-wideband radios[A].Radio and Wireless Symposium,2007 IEEE[C].Long Beach,CA,USA,2007.105-108.
[3] NI L,LIU Y,LAU Y,PATIL A.LANDMARC: indoor location sensing using active RFID[A].Proceedings of the First IEEE International Conference on Pervasive Computing and Communications(Per-Com2003)[C].Dallas,Texas,USA,March 2003.407-415.
[4] SHIRAISHI T,KOMURO N,UEDA H.Indoor location estimation technique using UHF band RFID[A].Information Networking,2008 International Conference on[C].Busan,Korea,2008.1-5.
[5] SHIH S,HSIEH K,CHEN P.An improvement approach of indoor location sensing using active RFID[A].Innovative Computing,Information and Control,2006 First International Conference on[C].Beijing,China,2006.453-456.
[6] DAI H,SU D.Indoor location system using RFID and ultrasonic sensors[A].Personal,Indoor and Mobile Radio Communications,2006 IEEE 17th International Symposium on[C].Kunming,China,2006.1179-1181.
[7] GERTEN G.Protecting the global positioning system[J].Aerospace and Electronic Systems Magazine,IEEE,2005,20(11):3-8.
[8] BAHL P,PADMANABHAN V.RADAR: an in-building rf-based user location and tracking system[A].Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies,Proceedings IEEE[C].TelAviv,Israel,2000.775-784.
[9] HIGHTOWER J,WANT R,BORRIELLO G.SpotON: An Indoor 3D Location Sensing Technology Based on RF Signal Strength[R].Seattle,WA: UW CSE,2000.
[10] KRISHNAKUMAR A,KRISHNAN P.The theory and practice of signal strength-based location estimation[A].Collaborative Computing:Networking,Applications and Worksharing,2005 International Conference on[C].San Jose,CA,USA,2005.10-19.
[11] NI W,SHEN G,LENG X,GUI L.An indoor location algorithm based on taylor series expansion and maximum likelihood estimation[A].Personal,Indoor and Mobile Radio Communications,2006 IEEE 17th International Symposium on[C].Helsinki,2006.1-4.
[12] 熊瑾煜,王巍,朱中梁.基于泰勒級數展開的蜂窩 TDOA 定位算法[J].通信學報,2005,25(4):144-150.XIONG J,WANG W,ZHU Z.A new TDOA algorithm based-on taylor series expansion in cellular networks[J].Journal on Communications,2005,25(4): 144-150.
[13] BAHL P,PADMANABHAN V,BALACHANDRAN A.Enhancements to the RADAR User Location and Tracking System[R].Microsoft Research Technical Report,2009.
[14] 孫瑜,范平志.射頻識別技術及其在室內定位中的應用[J].計算機應用,2005,(5):1205- 1208.SUN Y,FAN Z P.RFID technology and its application in indoor positioning[J].Journal of Computer Applications,2005,(5):1205- 1208.
