
數據起源安全模型研究
2010-08-29 13:28:04李秀美王鳳英
山東理工大學學報(自然科學版) 2010年4期
關鍵詞:用戶
李秀美,王鳳英
(山東理工大學計算機科學與技術學院,山東 淄博 255049)
數據起源是新興的研究領域,可用來判斷數據的來源、質量和可靠性.數據起源在電子商務、醫學、科學和法律環境下的數字文檔中的應用變得非常重要.迄今為止,對數據起源的研究主要集中在建模、計算、存儲、查詢等工作上,對確保數據起源信息安全方面的研究極少.隨著電子數據可信度重要性的日趨增強,確保數據起源信息安全的需要比以往更加重要.隨著數據起源不斷地用于數字版權保護、DNA檢測、藥物試驗、企業財務和國家情報等領域,起源信息也面臨著越來越嚴重的安全威脅,包括來自敵方的主動攻擊.攻擊者主要動機是根據科學數據的價值來更改數據起源記錄歷史.科學數據的價值依賴于哪個數據被創建以及由誰來創建等起源信息.用戶需要信任與數據相關的起源信息能夠準確地反映數據被創建和被轉化的過程.但是如果沒有適當的保護措施,隨著數據經歷不同應用層或不可信的環境,與數據相關的起源信息可能會遭到意外破壞,甚至更容易遭到惡意篡改.
例如,為了提高商品的產銷率,公司基層人員Alice按照目的和需要來收集購買者有關信息,如購買者個人信息、所購買商品的種類及數量等,然后將收集的信息移交給工作人員Bob來分析,作出判斷,形成結果,提高信息的使用價值.最終將處理過的信息傳輸給管理人員Carlin以作出合理決策,調整商品結構,促使供求平衡.在這個過程中形成了數據起源鏈(PA|PB|PC),如圖1所示.收集信息的質量,即信息的真實性、可靠性、準確性、機密性,決定著能否達到預定的目的和能否滿足需求從而提高企業的經濟效益.因此,企業內部人員和外部敵人很可能有明顯的動機去更改數據記錄歷史.如果工作人員Bob對某一商品的購買量作出不合理的判斷,從而導致錯誤的銷售策略.為了不影響他的業績考核,他可能會通過修改與其操作相匹配的起源記錄來隱藏他的錯誤行為.
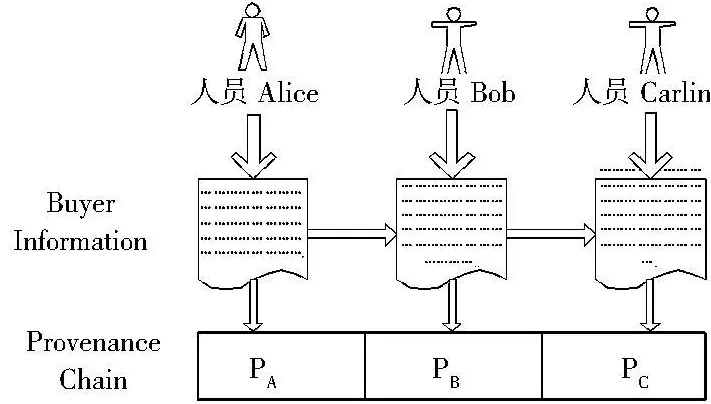
圖1 起源實例
隨著數據及其起源信息在不可信環境中經過不同用戶和任務時,數據起源信息極易被非法更改,為起源提供完整性、機密性保障變得非常重要.
1 數據起源的相關工作
數據起源描述了在數據的整個生命周期中數據當前狀態以及對數據被創建、修改、轉化的過程.數據起源的計算已不是新問題了,Cui等人首先提出了追蹤數據起源的問題[1],首次提出“逆查詢”方法,Buneman等人將其稱為why-provenance[2],同時又提出了where-provenance,正是利用數據起源的這種where-provenance類型來決定標注從哪里并且如何傳播來的.數據起源是與視圖更新密切相關的問題,而標注逐漸成為科學計算的最有用的方法.根據文獻[3],[4]中首次提出的關系數據上可以放置標注的想法,文獻[5]對關系數據庫設計并執行了標注管理系統.這是首次對關系數據庫實施標注管理系統,在這個系統中,允許用戶指定標注傳播方式.標注也可以用來描述一條數據的質量和安全級別,因為標注是隨著查詢的執行被傳播的,可以聚集查詢結果中的標注來確定輸出信息的質量或敏感度.使用標注來描述各種數據項的安全級別或指定細粒度訪問控制策略已有所研究.然而,實際操作是側重于收集存儲信息而不是起源的安全性和可信性,這并不滿足起源信息的機密性、完整性和隱私的各種挑戰.
到目前為止,為了收集和保存起源記錄已經提出了各種系統架構:有些系統收集關于數據修改的信息并且以標注的形式儲存起來,附加到數據本身[5-6];有些把起源信息存放在一個或多個數據庫中[7-8].因此,針對不同的存儲模式,根據其對安全的不同需求,采取不同的安全保護措施.Rigib等人在文獻[9]中的研究工作致力于文件系統中追蹤和存儲起源時的安全問題(完整性和保密性),但是文中沒有使用時間戳技術,文檔存在日期和時間不可確定的問題.文中是基于固定審計用戶數量而建立的密鑰樹,無法為新的審計員分配密鑰.因此,本文提出了新的數據起源安全模型,該模型可以有效的解決上述問題,目前對此研究甚少.
2 數據起源模型的建立
本節對在數據起源鏈傳播過程中,起源記錄可能遭到的威脅進行討論,提出了威脅模型,描述了數據起源的基本概念,提出了新的數據起源安全模型,并對該模型進行了定義、描述.
2.1 威脅模型
當數據經過應用層或組織邊界,經過不可信的環境時,其相關的起源信息很容易受到非法篡改.訪問控制是不能完全阻止這種篡改的,因為非法用戶可能實際控制著駐留數據的機器.如果數據起源沒有特殊的安全保障,非法用戶很容易修改數據并篡改相關的起源信息,甚至可能刪除起源鏈中相應的起源記錄,或者將偽造的起源記錄存儲在起源鏈里,并且這些操作很難被發現.
本文在Ragib等人描述模型[9]的基礎上提出了威脅模型和安全保障.假設在一個安全域中,用戶是讀寫文檔及其元數據的主體.每個組織有一個或多個審計員,他們被授權訪問并且驗證與文檔有關的起源記錄完整性的主體.無論是否有訪問文檔及其起源鏈的權限只要想不當地修改這些信息的個人或組織稱為攻擊者.
假設起源信息P準確地反映了文檔D的轉化,但是一個或多個攻擊者想通過修改D或P來偽造歷史.因此,根據圖1中起源鏈在形成過程中可能遭到的攻擊,列出了關于安全起源所需的以下保障:
S1 攻擊者不能有選擇地修改起源鏈中任何用戶(包括自己)的起源記錄.如圖1中所示的工作人員Bob不能通過修改他的起源記錄來隱藏他的錯誤行為.
S2 攻擊者不能有選擇地移除起源鏈中任何用戶(包括自己)的起源記錄.
S3 攻擊者不能在起源鏈的開始或中間添加起源記錄.
S4 用戶不能否認對起源鏈添加起源記錄.例如圖1中,員工Bob不能對自己的錯誤行為及寫入起源鏈的相應起源記錄進行惡意的否認,以推卸自己應承擔的責任.
S5 攻擊者不能宣稱與一個文檔相關的起源鏈屬于其他文檔.
S6 攻擊者不能只修改文檔而不將正確描述這次修改的起源記錄添加到起源鏈中.
S7 起源鏈本身不能被修改,也就是攻擊者不能破壞起源紀錄的先后次序.
S8 兩個同謀攻擊者不能在他們之間插入非同謀參與者的起源記錄.
S9 兩個同謀攻擊者不能有選擇地移除他們之間非同謀參與者的起源記錄.例如,在圖1中,員工Alice和Carlin不能移除Bob的起源記錄.
S10 審計員不用訪問起源鏈的任何機密性組件的情況下就可以驗證起源鏈的完整性,未授權審計員不能訪問機密性起源記錄.
值得注意的是,如果攻擊者實際完全控制著機器,他就完全可以刪除起源鏈,使用戶無法正常使用這些信息,因此這需要有可信硬件的支持.另一方面,攻擊者可能通過手動地或自動地復制文檔聲稱他們是創作者,從而偽造創作者的身份.因此,我們構造模型的目的是發現篡改,防止惡意攻擊者破壞部分起源鏈.
2.2 數據起源安全模型
為了有效地防止攻擊者非法篡改起源鏈中的起源記錄,綜合考慮可能存在的威脅的安全因素,提出了數據起源安全模型,如圖2所示.使用文檔這個詞代替包括文件、數據庫元組、信息流,網絡數據包在內的數據對象,而數據起源正是為該文檔而收集的.數據的起源信息是在該文檔的生命周期中對文檔的修改行為的記錄,每一次訪問文檔D都可能產生起源記錄P,而非空的起源記錄P1|···|Pn按時間順序排列組成了數據起源鏈.文檔從一個用戶移到另一個用戶,如同電子郵件附件,FTP傳輸,或其他方式.起源鏈隨著文檔一起移動.當用戶修改一個文檔時,描述這次修改的新的起源記錄被附加到數據起源鏈上,而且用戶允許審計員或其子集讀取新的起源記錄.根據起源鏈可以回溯文檔的演化過程,追蹤文檔產生時的來源、在文檔生命周期中的修改過程.起源鏈中的每個起源記錄描述了文檔的當前狀態,如訪問文檔的用戶名、進程序號、訪問行為(讀或寫操作)、相關數據(文檔的字節大小)以及對行為發生環境的描述(包括訪問的主機號、IP、日期時間),以及與完整性、機密性相關的安全組件,例如校驗和、加密簽名、密鑰材料、數字時間戳.對文檔的每個操作都以起源記錄的形式被記載,文檔被刪除后,它的起源信息不再有意義.
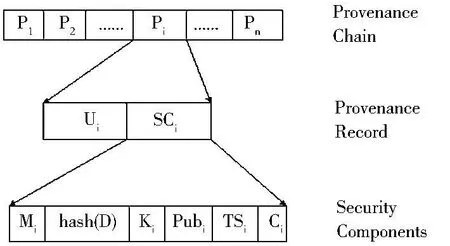
圖2 數據起源安全模型的結構
2.3 安全模型中相關要素的描述
該模型包括三層組件:第一層是起源鏈,每條起源鏈至少含有一個起源記錄;第二層是起源記錄,其中包括起源記錄描述字段Ui和安全組件字段SCi;第三層是安全組件和起源記錄要素.起源記錄是起源鏈中的最基本單元,每個起源記錄Pi匯總了一個或多個用戶在文檔D上執行的一系列操作,將起源記錄定義成如下形式:
Pi=<Ui,Mi,hash(Di),Ki,TSi,Ci,Pubi>其中,Ui是用戶的明文或密文標識符,包括以下要素:訪問文檔的用戶名Uidi,進程序號Pidi,訪問行為Actioni,文檔的字節大小Bytei,IPi,訪問的主機號Hosti,Timei.將Ui字段定義為Ui=<Uidi,Pidi,Actioni,Bytei,IPi,Hosti,Timei>.如果Ui是敏感的,那么它要以密文的形式存儲.
例如,在員工業績評估實例中,允許甚至是鼓勵員工經常去看他們的業績評估結果,以督促他們達到工作業績標準的要求,但是員工不能讀取誰對他們的工作業績做出了評價,因此員工只能夠讀取業績評估文檔而不是文檔的數據起源.在這種情況下,描述文檔當前狀態的用戶標識符就應該用會話密鑰加密形成密文.
Mi是用戶執行的一系列增加,刪除,修改等操作(簡稱修改日志)的密文或明文表示形式.
hash(Di)是文檔當前內容的單向散列值.
[3]For all the recent debate,early signs are that the supply-side shift may not amount to a serious change of course.(2016-01-02)
Ki是密鑰材料,包括審計員可以用來解密被加密字段的密鑰.
TSi表示時間戳,對需要加時間戳的文檔摘要和DTS收到文檔的日期和時間進行數字簽名.
Ci包含了由用戶簽名的起源記錄的完整性校驗和.
Pubi是用戶Ui的加密的或明文公鑰證書.
3 數據起源安全模型需求
3.1 起源鏈的完整性
用戶在修改文檔時,同時對文檔進行單向散列hash(Di).并對此散列值、修改日志、密鑰材料、用戶標識符以及用戶的公鑰證書進一步散列,使用用戶的私鑰對后一次散列結果、時間戳以及前一個起源記錄Pi–1的檢查和Ci–1進行簽名形成完整性校驗和,我們將完整性校驗和字段定義如下:
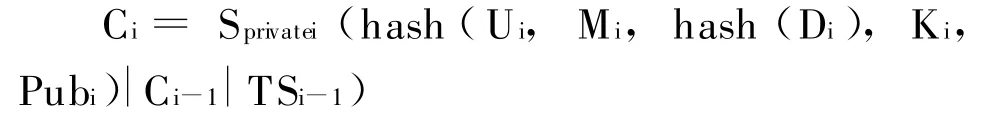
為了增加簽名的安全性,引入了時間戳技術,用戶將需要加時間戳的用戶標識符用Hash加密形成消息摘要,然后將該消息摘要發送到數字時間戳服務中心DTS,DTS對消息摘要和收到消息摘要的日期時間信息再加密(數字簽名),然后送回給用戶,如圖3所示.將時間戳和完整性校驗和存儲在起源記錄相應字段中.時間戳具有唯一性和不可逆性,因此起源記錄被人改動則不能通過驗證.時間戳字段定義如下:
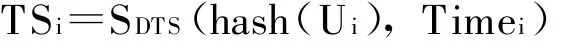

圖3 數字時間戳
審計員獲得由起源記錄提供的信息,他可以通過計算校驗和來判斷數據的來源,驗證在傳輸過程中是否被惡意地修改.為了驗證起源鏈的完整性,審計員從起源鏈的第一個記錄開始,從記錄中提取用戶標識符Ui和Pubi字段,并驗證Pubi是用戶Ui的公鑰證書,審計員從中找到用戶的公鑰對校驗和進行解密,得到hash(Ui,Mi,hash(Di),Ki,Pubi).審計員再對當前記錄中的Ui,Mi,hash(Di),Ki,Pubi字段進行散列得到hash',如果hash=hash'則說明起源信息沒有被修改.
簡要說明威脅模型中針對完整性的安全保障:
(1)如圖1的用戶Bob想修改起源記錄或信息文檔,這必定會引起hash(Ui,Mi,hash(Di),Ki,Pubi)的值的改變,因為每次被修改的信息都是被單向散列的.如果外部攻擊者想修改起源記錄而不被發現,那么他需要得到其他用戶的簽名,或者找到哈希碰撞,因此S1的安全是有保障的.
(2)如果攻擊者想插入或者刪除起源記錄也是可以被發現的,因為每個起源記錄中的校驗和Ci都包含前一個起源記錄的校驗和,這足以保證S2、S3、S8、S9的安全.
(3)函數hash具有無碰撞性,以及文檔當前內容的hash值保存在每個起源記錄中,因此通過比較文檔與起源鏈中最新起源記錄的各字段,便可以驗證S5所述的起源鏈是否被聲稱屬于不同的文檔.
(4)授權審計員對校驗和Ci進行解密,依次驗證起源記錄中hash(Di),Mi字段,如果發現hash(Di)與當前狀態文檔內容不匹配,審計員能夠驗證S6攻擊者只修改文檔而沒有將起源記錄添加到起源鏈中.
(5)S4的不可否認性由起源鏈校驗和中的簽名來保障.
(6)可以通過驗證每個起源記錄中的時間戳來保證S7中起源紀錄的先后次序沒有遭到破壞.
3.2 起源信息的機密性
在起源信息相對于數據更敏感的系統中,為了保證起源信息的機密性,需要使用會話密鑰對修改日志進行加密,并使用不同安全級別審計員的公鑰來加密用戶密鑰.在這個過程中,只有某一可信審計能夠解密相應的用戶密鑰,并使用該密鑰來解密敏感字段.
為了使不同可信審計能夠安全有效地訪問起源鏈中相應敏感字段,用戶需要產生N個會話密鑰復本,分別使用N個審計員的公鑰加密密鑰復本,然后存放在Ki字段中,因此起源鏈中的密鑰存儲量為O(N).隨著文檔的不斷傳播,導致起源鏈本身急劇增大,這將影響到起源鏈的存儲與傳播.因此,為了減少起源記錄Pi中Ki字段存儲的密鑰數量,文中借鑒廣播加密方案[10]構造密鑰樹.密鑰樹是以密鑰為結點的二叉樹,每個結點包含PKI中的公/私鑰對,葉子結點相當于審計員,每個審計員都知道從葉子結點到根結點的私鑰,而把樹中所有的公鑰給用戶.
如果存在用戶同時信任屬于不同子樹的任意葉結點時,便出現了如何選取密鑰的問題.對于這一問題,我們選擇審計員的一個子集,給子集中的所有審計員一個公用的解密密鑰,這樣可以有效地控制授權審計員子集數量的增加,減輕用戶對敏感字段加密和起源鏈傳輸的負擔.在以審計員為葉結點的二叉樹中,設中間結點ki,kj,其中ki是kj的父結點,子集Si,j表示包含以ki為根而不包含以kj為根的所有結點的集合.如圖4中,在以k1為根結點,以審計員A、B、C、D為葉子結點的密鑰樹中,子集Sk1,k6表示被授權的審計員子集包括A、B、D三個,通過判斷可知,A、B屬于同一個根結點,因此將這個子集中分成兩個不相交的差分子集,并計算這些差分子集對應的密鑰.這樣做好處是密鑰字段中只存儲一個加密的會話密鑰復本,有效減少存儲空間和提高起源鏈的傳播效率.相比之下,多叉密鑰樹中同一根結點的葉子數量相對很多,而隨著葉子結點數量的增加,審計員的子集劃分不斷增多,而使用二叉密鑰樹可以有效地減少審計員子集劃分數量.
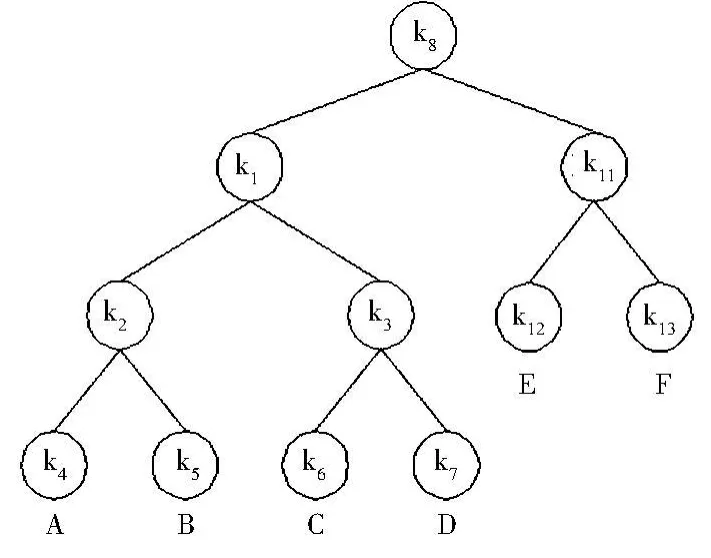
圖4 密鑰樹
當用戶信任某審計子集時,他會使用審計所屬的子集的公鑰加密會話密鑰.審計員必須能夠推斷出他所屬的子集的所有公私鑰對,也就是從葉結點到根結點的所有子集.所有這些子集中的審計員都被授權訪問起源鏈.加密起源鏈修改日志的目的是允許授權審計訪問并驗證起源鏈,所有這些審計員都是某一子集的成員,因此他們擁有屬于這一子集的密鑰.
在加密階段,用戶使用會話密鑰ki加密修改日志mi,即3.1中所定義的字段Mi=Eki(mi),如果此字段對某一可信審計員子集Si可信,用戶會選擇與這一子集相關的密鑰kSi加密會話密鑰的復本,即3.1中的密鑰材料字段Ki=Eksi(ki),然后將加密的密鑰存放在Ki字段中,加密次數為子集的個數.由于私鑰是由審計員保存,而用戶只使用公鑰進行加密,因此不可能泄露審計員的私鑰.
3.3 動態密鑰樹
由于審計用戶數量可能存在動態增加的情況,而傳統的密鑰樹存在無法擴展審計員數量的問題,因此需要在不影響原有審計數量的基礎上動態地擴展審計端.
假設擴展審計端前的密鑰樹為T,以新加入的審計員為葉結點建立密鑰樹T'.第t次擴展以T為左子樹,T′為右子樹將其結合成一棵新密鑰樹T″,根結點為kt.保持左子樹的密鑰系統不變,為右子樹及根結點分配密鑰[11].為了更好的理解密鑰樹擴展問題,給出一個簡單的例子.如圖5所示,保持原有密鑰樹的密鑰分配不變,以新加入審計員E、F為葉子結點構造一棵二叉樹,并分配密鑰,擴展后的密鑰樹的根結點為k8.如果用戶只信任審計員A,那么用戶只需用結點k4的公鑰加密會話密鑰;如果用戶信任C、D、E、F四個審計員,那么會產生兩個差分子集,分別對應的密鑰是k3,k11;相應地,如果用戶信任所有的審計員,那么只需使用結點k8的公鑰加密即可.
對于擴展了t次審計員的密鑰樹中,每次新加入的審計員集合的密鑰分配同未擴展之前的審計端的密鑰分配是一樣的,審計員的密鑰存儲量與該審計員所處的擴展端的個數相關.
4 結束語
本文分析了現有數據起源相關安全問題,對威脅模型進行改進,確保攻擊者不能更改起源記錄的順序;針對機密性需求中的加密方案存在的問題,引入廣播加密樹再生長的思想構造密鑰樹;為了增加簽名的安全性,引入了時間戳技術,構建新的數據起源安全模型.但對這種模型的研究還處于初始階段,還要進行不斷的完善.比如隨著數據的不斷傳播,起源鏈也不斷增長,如何在不影響審計員對起源鏈完整性、機密性的驗證的情況下壓縮起源鏈等問題將是下一步研究的重點.
[1]Cui Y,Widom J,Wiener J.T racing the Lineage of View Data in a Warehousing Environment[J].ACM T ransactions on Database Sy stems(TODS),2000,25(2):179-227.
[2]Buneman P,Khanna S,Tan W.Why and Where:A Characterization of Data Provenance[C]//In Proceedings of the 8th International Conference on Database T heory(ICDT),2001:316-330.
[3]Buneman P,Khanna S,Tan W.On Propagation of Deletions and Annotations Through Views[C]//In Proceedings of the ACM Symposium on Principles of Database Sy stems(PODS),Wisconsin,Madison,2002:50-158.
[4]Wang-C T.Containment of relational queries with annotation propagation[C]//In Proceeding s of the International Workshop on Database and Programming Languages(DBPL),Potsdam,Germany,2003:109-110.
[5]Bhagwat D,Chiticariu L,Tan W,etal.An Annotation Management System for Relational Databases[C]//In Proceedings of theInternationalConferenceonVeryLargeDataBases(VLDB),2004:900-911.
[6]Buneman P,Chapman A,Cheney J.Provenance management in curated databases[C]//Proceedings of the 2006 ACM SIGMOD international conference on M anagement of data,2006:539-550.
[7]Chapman A,Jagadish H V,Ramanan P.Efficient provenance storage[C]//Proceedings of the 2008 ACM SIGMOD international conference on Management of data,2008:993-1006.
[8]Davidson S,Cohen-Boulakia S,Eyal A,et al.Provenance in scientific workflow sy stems[J].IEEE Data Engineering Bulletin,2007,32(4):1-7.
[9]Ragib Hasan,Radu Sion,Marianne Winslett.T he case of the fake picasso:Preventing history forgery with secure provenance[C]//In Proc.of the 7th USENIX conference on File and Storage Technologies,2009.
[10]Halevy D,Shamir A.T he LSD broadcast encryption scheme[C]//Lecture Notes in Computer Science,2002:47-60.
[11]武蓓,王勁林,倪宏,等.一種廣播加密機制的樹再生長方法[J].計算機工程,2007,33(22):169-171.
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
