圖像數據挖掘技術研究及應用
2011-01-29 06:25:48王文淵
制造業自動化 2011年13期
王文淵
WANG Wen-yuan
(楚雄師范學院,楚雄 675000)
1 圖像數據模型
圖像數據挖掘模型主要有功能驅動模型和信息驅動模型。
1.1 功能驅動模型
功能驅動的圖像數據挖掘是針對具體應用的特定要求來設計挖掘系統的驅動框架。MultiMediaMiner是以DBMiner系統和C-BIRD(content-based image retrieval from digital libraries)系統為基礎發展起來的圖像數據挖掘系統,它是典型的功能驅動模型[2],如圖1所示。它由4個功能模塊組成。圖像采集器(excavator):從多媒體數據庫中抽取圖像數據。預處理器(preprocessor):提取圖像特征,并把所計算的特征存放在特征數據庫中。檢索引擎(search engine):利用圖像特征進行匹配查詢。知識發現模塊(discovery modules):對圖像集進行特征描述、分類、關聯規則挖掘、聚類等挖掘。
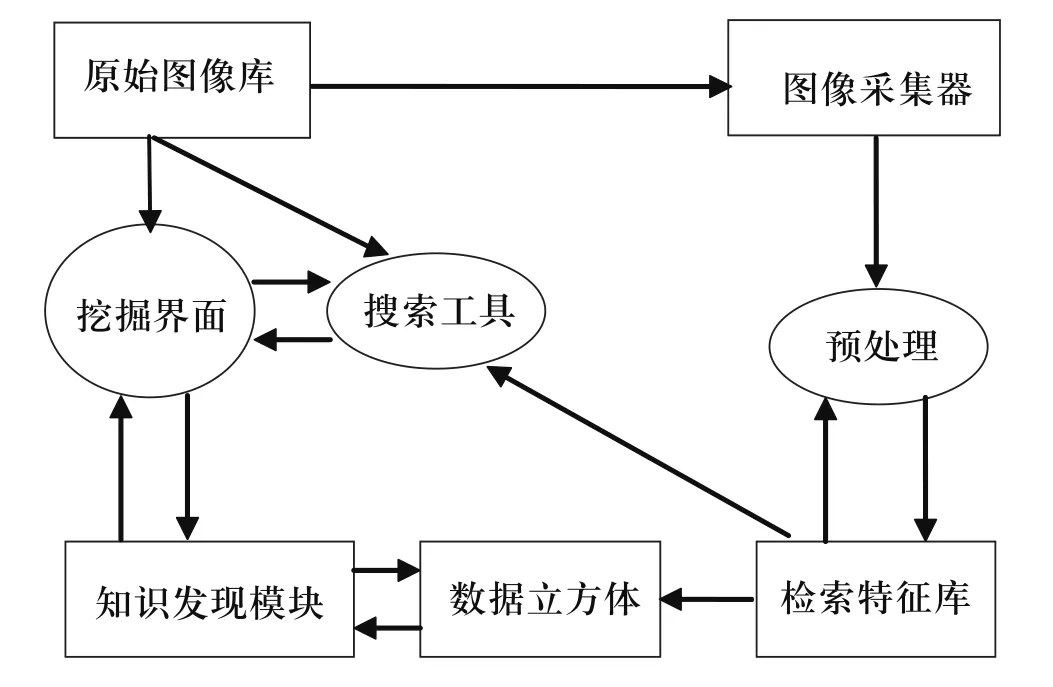
圖1 數據挖掘功能驅動模型
1.2 信息驅動模型
Zhang[3]提出信息驅動模型是針對圖像的原始信息,以基于內容的圖像處理技術為基礎的圖像數據挖掘框架,主要強調不同的圖像信息層次起到的作用不同。該模型首先根據圖像的原始信息,以及基于原始特征的對象或區域信息,利用聚類算法和領域知識將圖像分割成有意義的區域或對象,然后進行高層次的推理和挖掘,從而產生高層次的語義概念和有用的、易于理解的模式。該模型中圖像信息分為4個層次[3]:象素層:由原始圖像信息和原始圖像特征組成,如象素點、紋理、形狀和色彩等。對象層:處理基于象素層原始特征的對象和區域信息。語義概念層:結合領域知識從識別出的對象和區域中生成高層次的語義概念。模式知識層:可結合與某一領域相關的文字和數字信息發現潛在的領域知識和模式。在信息驅動模型中,象素層和對象層主要進行圖像處理、對象識別和特征提取,而語義概念層和模式知識層主要進行圖像數據挖掘和知識集成。該模型不僅只在圖像的高層次進行挖掘,而且還可以擴展此模型以使挖掘能夠在每個層次以及不同層次間進行。
2 圖像數據挖掘技術
2.1 圖像預處理
在大型圖像數據庫中存在許多臟數據和已破壞了的數據,這些數據能使挖掘過程陷入混亂導致不可靠的輸出,有必要對數據進行清洗,以提高數據的質量。圖像數據不僅數據量大,信息豐富,而且原始圖像無法直接應用于數據挖掘,在使用挖掘工具之前,除了必要的數據清洗外,還要根據挖掘工具的特點和挖掘目的對圖像數據進行必要的預處理。預處理主要包括可視特征提取、對象識別、數據規約、遙感數據離散化、圖像融合等。
1)可視特征采用圖像處理技術通過計算獲得,主要包括顏色、紋理、形狀等。顏色是應用最廣泛的可視特征。顏色直方圖用于存放圖像對象中每種顏色的像素的比例,具有平移和旋轉不變性,是最常用的顏色描述。紋理刻畫了顏色和密度分布的均勻性,包含了表面結構和其與周圍環境關系的重要信息,表示方法主要有:共現矩陣法,小波變換法等。形狀表示法主要有基于邊界表示的傅立葉描述法、基于區域表示的不變矩方法。
2)對象識別即在圖像中識別出對象及其空間關系,涉及到的技術有圖像分割、對象模型的表示及對象識別。
3)數據規約主要包括維規約和數據壓縮,是為了提高挖掘質量和效率而進行的數據處理。
4)為了更好地提取圖像特征,有必要進行圖像融合,獲取一種新型圖像,其形態結構顯示得更直觀,可獲取更詳細、準確的特征。
2.2 圖像數據的相似性搜索
對于圖像數據的相似性檢索,主要考慮了兩種圖像標引和檢索系統:1)基于描述的檢索系統,主要是在圖像描述之上建立標引和執行對象檢索;2)基于內容的檢索系統,它支持基于圖像內容的檢索,如顏色構成、紋理、形狀、對象和小波變換等.基于描述的檢索若用手工完成是很費力的;若自動完成,檢索的結果質量通常又較差。基于內容的檢索使用視覺的特征標引圖像并基于特征相似檢索對象。
2.3 目標識別
目標識別一直是圖像處理領域中活躍的研究焦點。這是圖像挖掘領域中的一個主要任務。自動的機器學習和有意義的信息抽取能被實現僅僅在某些目標已經被機器識別的情況下。已知目標的模型通常由人工輸入作為先驗知識。
2.4 圖像關聯規則挖掘
關聯規則挖掘主要根據圖像中象素的光譜特征,構成紋理圖像的各個象素、各個紋理基元之間都具有關聯關系,這是關聯規則挖掘能夠用于圖像的前提。要挖掘紋理圖像的關聯規則,我們可以把每一個圖像看作一個事務,從中找出不同圖像問出現頻率高的模式。如果圖像數據挖掘深入到象素級,則需要將一個象素及其鄰域看作一個事務,從中找出在圖像中重復出現的模式。在紋理圖像中,這種模式實際上就是紋理基元。紋理基元有大小之分,這就要求在多個層次上多分辨率情況下進行挖掘。根據圖像數據的矩陣表達方法,借助圖像矩陣的事務數據模式化的方法,我們界定一系列圖像事務定義。根象素:一個nⅹn鄰域的根象素是這個鄰域的中心象素,一個ⅹn的圖像包含(N-n+1)2個根象素。項:所給定的根象素所在的鄰域中每一個象素映射為一個項。通過一個元組(X,Y,I)來定義,其中X和Y分別是鄰域中相對于根象素的偏移量,I是象素的灰度值。這樣,一個具有G種灰度值的n Xn鄰域中,可能產生n2G個不同的項。項集:一系列項的集合構成項集,實際上映射為圖像中一系列相關象素集合。事務:同某一根象素相關的一系列項組成一個事務。確切地說,每一個根象素對應一條事務,鄰域中每個項都可能進人事務。針對每個根象素,如果有K種偏移量情況,加之每個象素可以有G種可能的灰度值,因此,統計相同的偏移量所構成的事務,會產生Gk條事務。關聯規則:一條關聯規則表達了圖像的局部結構,形式為(X1,Y1,I)∧…∧(Xm,Ym,Im)→(Xm+1,ym+1,I m+1)∧…∧(Xm+n,Ym+Im+n)(s%,c%)。例如,下面這條關聯規則表示了在二值圖像中,一個象素寬的垂直條帶的右邊通常為一個象素寬的白色條帶。(0,1,l)∧(0,0,l)∧(0,-1,l)→(1,0,0)∧(1,1,0)∧(1,-1,0)(s%,c%支持度和置信度表明了這種情況出現的可能性。
2.5 圖像分類和聚類
基于內容的智能圖像分類可通過將圖像與不同的信息類別相關聯實現。圖像分類是一種有監督學習方法,過程分3步:1)建立圖像表示模型,對已進行類別標注的樣本圖像進行特征提取,建立每一圖像屬性描述;2)對每一類別的樣本集進行學習,建立規則或公式;3)使用模型對未標注圖像進行分類判決和標注。常用的分類方法有:判定樹Bayes方法、神經網絡方法,其它方法包括:K一最近鄰分類、粗糙集分類等。圖像聚類是依據沒有先驗知識圖像的內容本身將給定的無標簽圖像集合分為有含義的簇,常用于挖掘過程的早期階段,其特征屬性是顏色,紋理和形狀。
3 結束語
圖像數據挖掘是目前國際上數據庫、圖形圖像技術和信息決策領域最前沿的研究方向之一,是數據挖掘的一個新興的富有挑戰性的領域,具有較高的學術價值和廣泛的應用前景。現階段圖像挖掘的理論與技術有待繼續研究和完善,所以專門研究圖像數據挖掘技術具有重要的意義。
[1]Burl M C,et al.Mining for image content[C]∥Systemics,Cy-bernetics and Informatics/Information System:Analysis and Synthesis.Orlando,FL,1999.
[2]Zaiane OR,Han JW.Mining Multimedia Data,Proceedings of CASCON98,Meeting of Minds,Toronto,Canada,1998:83-96.
[3]Zhang J.An Information–Driven Framework for Image Mining,Proceedings of 12th International Conference on Database and Expert Systems Applications(DEXA),Germa ny,2001-09.
[4]方玲玲,王相海.圖像挖掘研究[J].計算機科學2009,8.
[5]薛麗霞,冀志敏,王佐成.圖像紋理特征挖掘[D].計算機應用研究,2010.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
電力與能源(2017年6期)2017-05-14 06:19:37
信息通信技術(2015年6期)2015-12-26 01:16:46
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
電子設計工程(2014年18期)2014-02-27 12:00:13
