面向本體的智能信息檢索技術(shù)的研究
2011-02-09 01:56:46尹哲峰
制造業(yè)自動(dòng)化 2011年4期
尹哲峰
(延邊大學(xué),延吉 133002)
0 引言
隨著計(jì)算機(jī)技術(shù)以及網(wǎng)絡(luò)技術(shù)的快速發(fā)展,信息資源共享波及范圍越來(lái)越廣,信息資源量也越來(lái)越多。因此,面對(duì)如此多的信息量,如何有效定位需要的信息資源已經(jīng)成為人們關(guān)注的問(wèn)題。信息檢索技術(shù)應(yīng)運(yùn)而生。
信息檢索就是從信息資源庫(kù)中,搜索出所需信息的過(guò)程與方法。而本體的本義是哲學(xué)方面的術(shù)語(yǔ)。本體具有較好的概念結(jié)構(gòu)以及邏輯推理,面向本體的智能信息檢索可以準(zhǔn)確映射信息資源,提高檢索效率。本文就是重點(diǎn)研究面向本體的智能信息檢索技術(shù)。
1 相關(guān)理論概述
1.1 本體的層次化分類
本體的研究與實(shí)現(xiàn)是在不同層次上進(jìn)行的,可以分為頂層本體、領(lǐng)域本體、任務(wù)本體以及應(yīng)用本體四大層次,如圖1所示:

圖1 本體的層次化分類示意圖
其中,頂層本體主要涉及到一些概念。比如:空間、時(shí)間以及行為等,這些概念與問(wèn)題或者領(lǐng)域是獨(dú)立的,而且頂層本體在一定區(qū)域內(nèi)是完全共享的。領(lǐng)域本體是針對(duì)某一領(lǐng)域而對(duì)應(yīng)的一些術(shù)語(yǔ)。任務(wù)本體主要負(fù)責(zé)任務(wù)、活動(dòng)的定義。任務(wù)本體與領(lǐng)域本體都可以采用頂層本體中共享的術(shù)語(yǔ)而表述各自的術(shù)語(yǔ)。而應(yīng)用本體是針對(duì)應(yīng)用而言的,可以引用領(lǐng)域本體或者任務(wù)本體中的概述描述。
1.2 智能信息檢索的標(biāo)準(zhǔn)
通常情況下,信息檢索是通過(guò)關(guān)鍵詞的匹配來(lái)實(shí)現(xiàn)的,但隨著信息量的增加,這樣的匹配檢索技術(shù)越來(lái)越不滿足需求。智能信息檢索就是通過(guò)智能檢索技術(shù)來(lái)實(shí)現(xiàn),標(biāo)準(zhǔn)主要體現(xiàn)在兩個(gè)方面:檢索的查全率以及檢索的檢準(zhǔn)率。
其中,查全率主要表示的是信息檢索結(jié)果中有用信息量與用戶需求信息量之間的比例,可以有效描述檢索結(jié)果的遺漏情況。查準(zhǔn)率主要表示的是檢索結(jié)果中有效信息量與檢索總量之間的比例關(guān)系,主要描述的是檢索結(jié)果的有用性。常用的關(guān)鍵詞匹配檢索技術(shù)很難達(dá)到查全率以及查準(zhǔn)率的全面兼顧。一個(gè)理想的智能信息檢索系統(tǒng)應(yīng)該保證最高的查全率與查準(zhǔn)率,也就是為1的結(jié)果。
2 面向本體的智能信息檢索
2.1 智能信息檢索的設(shè)計(jì)思想
本文提出的面向本體的智能信息檢索的設(shè)計(jì)思想如下描述:
首先,基于領(lǐng)域?qū)<遥鶕?jù)檢索體系要求,建立該領(lǐng)域的本體;其次,充分收集相關(guān)信息數(shù)據(jù),根據(jù)已經(jīng)建立的領(lǐng)域本體,將信息數(shù)據(jù)轉(zhuǎn)化成規(guī)定格式,并保存至數(shù)據(jù)庫(kù);接著,從用戶界面相關(guān)的檢索框獲取特定的檢索請(qǐng)求,智能檢索器根據(jù)本體將檢索請(qǐng)求轉(zhuǎn)化為規(guī)定的格式,并基于本體從數(shù)據(jù)庫(kù)中檢索出與請(qǐng)求條件相匹配的數(shù)據(jù)。最后,將匹配的數(shù)據(jù)結(jié)果通過(guò)定制操作,傳輸?shù)接脩艚K端加以顯示。
需要注意的一點(diǎn)是,如果面向本體的智能信息檢索系統(tǒng)對(duì)于推理能力沒(méi)有太高的要求,那么系統(tǒng)中涉及到的本體可以采用概念圖加以描述,并保存。信息數(shù)據(jù)也可以存儲(chǔ)到普通的關(guān)系型數(shù)據(jù)庫(kù)中,根據(jù)圖匹配來(lái)實(shí)現(xiàn)智能信息的定位。但如果面向本體的智能信息檢索系統(tǒng)需要較強(qiáng)的推理功能,那必須通過(guò)本體語(yǔ)言,比如:OWL等加以描述,信息數(shù)據(jù)也應(yīng)該存儲(chǔ)到知識(shí)倉(cāng)庫(kù),這樣就可以利用OWL之類的本體語(yǔ)言所具有的推理能力來(lái)完成信息定位,并保證較強(qiáng)的推理功能。
2.2 智能信息檢索的流程
本文研究的面向本體的智能信息檢索系統(tǒng)的框架如圖2所示:
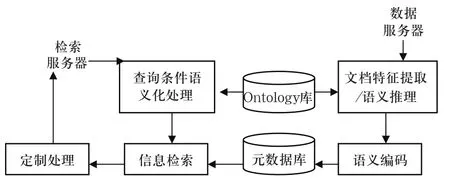
圖2 面向本體的智能信息檢索系統(tǒng)的框架示意圖
根據(jù)系統(tǒng)框架圖,下面詳細(xì)研究一下智能信息檢索的流程。
1)構(gòu)造領(lǐng)域本體。智能信息檢索系統(tǒng)的關(guān)鍵之處在于領(lǐng)域本體,因?yàn)橄嚓P(guān)的信息、文檔特征、推理等都是基于領(lǐng)域本體的。所以,領(lǐng)域本體的構(gòu)造需要在領(lǐng)域?qū)<业闹笇?dǎo)下完成。
2)提取文檔的相關(guān)特征、語(yǔ)義推理的處理。根據(jù)領(lǐng)域本體將收集的文檔信息進(jìn)行相關(guān)特征的提取,并進(jìn)行語(yǔ)義方面的推理處理。傳統(tǒng)的信息檢索只是局限于索引器的索引信息提取,而且索引相關(guān)信息一般也只是通過(guò)貝葉斯或者統(tǒng)計(jì)方法來(lái)獲取,并不能很好地體現(xiàn)文檔之間的關(guān)聯(lián)性。而本文研究的智能信息檢索系統(tǒng)是基于領(lǐng)域本體,對(duì)收集的文檔信息進(jìn)行特征提取,并完成語(yǔ)義方面的推理。這樣的處理步驟,不僅能夠很好地表述文檔的內(nèi)在信息,也可以描述文檔之間的關(guān)系,為后續(xù)的信息檢索奠定了基礎(chǔ)。由于語(yǔ)義方面的推理處理具有比較高的時(shí)間復(fù)雜度,所以可以將其中的一部分推理過(guò)程直接放在這第二階段預(yù)先完成,這樣可以有效提高在線檢索的速率。
3)信息語(yǔ)義的編碼加工。智能信息檢索系統(tǒng)對(duì)于語(yǔ)義處理后的數(shù)據(jù)統(tǒng)一編碼成XML格式,這樣便于信息處理,便于高速檢索。
4)將提交的查詢條件進(jìn)行語(yǔ)義化的處理。用戶在使用智能信息檢索系統(tǒng)時(shí),首先是提交查詢條件,系統(tǒng)會(huì)將查詢條件根據(jù)領(lǐng)域本體進(jìn)行語(yǔ)義化方面的處理。該語(yǔ)義處理針對(duì)于多個(gè)查詢條件,并進(jìn)一步明確各查詢條件之間的關(guān)聯(lián)性。
5)智能信息的檢索。智能信息檢索是系統(tǒng)的核心模塊,但由于前面幾個(gè)階段已經(jīng)完成了檢索的許多相關(guān)工作,所以該階段只需要將語(yǔ)義化處理后的查詢條件與數(shù)據(jù)庫(kù)中的所有信息進(jìn)行對(duì)比,滿足條件的信息,直接轉(zhuǎn)發(fā)給定制模塊即可。
6)信息的定制處理。信息的定制處理就是對(duì)系統(tǒng)檢索出的數(shù)據(jù)進(jìn)行后期的處理,比如:排序等。排序的時(shí)候,可以根據(jù)信息的相關(guān)性大小進(jìn)行,這其中涉及到了排序算法,也是一個(gè)比較重要的研究?jī)?nèi)容。
2.3 文檔信息數(shù)據(jù)的存儲(chǔ)
系統(tǒng)的信息庫(kù)必須具有特定的結(jié)構(gòu),這樣才能有利于檢索效率。通常情況下,Internet網(wǎng)絡(luò)上的信息都是由HTML語(yǔ)言編寫(xiě)的,但可惜HTML并不注重結(jié)構(gòu)性,只是注重各個(gè)元素的呈現(xiàn),也缺少語(yǔ)義分析。而本文采用的是XML,因其簡(jiǎn)易性以及功能優(yōu)秀性成為了替代HTML的網(wǎng)絡(luò)語(yǔ)言。
XML其實(shí)只是SGML的一個(gè)子集,它能夠很好地解決HTML語(yǔ)言不能描述內(nèi)容的不足,因此XML在電子交易、銀行、政府等各個(gè)領(lǐng)域都被廣泛使用。目前,XML已經(jīng)成為數(shù)據(jù)描述及交換的標(biāo)準(zhǔn)。此外,文檔類型定義DTD涉及到對(duì)XML結(jié)構(gòu)以及語(yǔ)法方面的規(guī)范定義。從邏輯意義上分析的話,可以將DTD對(duì)應(yīng)的XML文檔直接保存到文檔表中,每個(gè)文檔表中的記錄都分別對(duì)應(yīng)各自的XML文檔,也可以通過(guò)一個(gè)固定的DTD表來(lái)對(duì)所有DTD文檔進(jìn)行管理。文檔表與DTD表之間的關(guān)系如圖3所示:
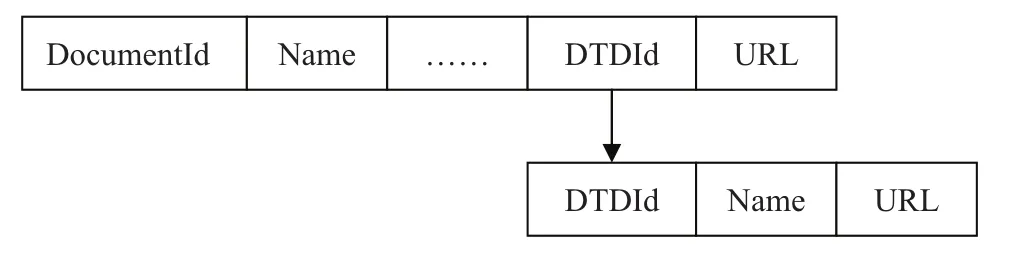
圖3 文檔表與DTD表之間的關(guān)系示意圖
2.4 在線語(yǔ)義推理的技術(shù)
針對(duì)本文研究的智能信息檢索系統(tǒng),當(dāng)終端用戶通過(guò)錄入一個(gè)檢索詞時(shí),系統(tǒng)就會(huì)根據(jù)語(yǔ)義擴(kuò)展后的信息庫(kù),進(jìn)行檢索滿足檢索詞要求的信息對(duì)象。如果終端用戶錄入的檢索詞是多個(gè),那么系統(tǒng)就必須進(jìn)行在線語(yǔ)義的推理。
系統(tǒng)在線語(yǔ)義推理的檢索過(guò)程主要包括:輸入檢索條件、檢索詞詞性的確定、檢索詞關(guān)系的確定、信息檢索以及返回檢索結(jié)果等。當(dāng)終端用戶輸入相關(guān)檢索詞后,系統(tǒng)會(huì)按照領(lǐng)域本體確定檢索詞對(duì)應(yīng)的詞性以及多個(gè)檢索詞間的關(guān)聯(lián)性。
比如:用戶的檢索詞是“李四 數(shù)據(jù)的挖掘”,系統(tǒng)就需要根據(jù)檢索詞明確終端用戶的具體查詢意圖。通過(guò)領(lǐng)域本體來(lái)確定檢索詞的詞性,其中“李四”表示的是一個(gè)人的人名。而“數(shù)據(jù)的挖掘”表示的是數(shù)據(jù)庫(kù)范疇的概念。下一步就是確定檢索詞之間的關(guān)聯(lián)。“李四”與“數(shù)據(jù)的挖掘”到底是什么關(guān)聯(lián)呢?它們之間是write的關(guān)系或者work-in的關(guān)系。這樣,系統(tǒng)就會(huì)給出這樣的推測(cè)結(jié)果:用戶終端需要查詢的是有關(guān)“李四撰寫(xiě)的針對(duì)數(shù)據(jù)挖掘方面的文章或者專注”或者“李四參加的針對(duì)于數(shù)據(jù)挖掘相關(guān)的項(xiàng)目”。接著,系統(tǒng)在特定信息庫(kù)中進(jìn)行有針對(duì)性的查詢,并將最終的查詢結(jié)果返回到終端用戶。
2.5 系統(tǒng)的推理算法描述
本文研究的面向本體的智能信息檢索系統(tǒng)在檢索失敗的情況下,需要根據(jù)領(lǐng)域本體對(duì)信息描述進(jìn)行一定的推理。其中就涉及到了推理算法,該算法也是智能信息檢索系統(tǒng)中的關(guān)鍵部門(mén)。推理的過(guò)程其實(shí)就是一個(gè)進(jìn)一步檢索的過(guò)程,生成相關(guān)的結(jié)果信息。下面研究一下系統(tǒng)相關(guān)的在線語(yǔ)義推理過(guò)程所涉及到的算示。
輸入部分:用戶錄入的N個(gè)檢索詞,系統(tǒng)的領(lǐng)域本體;
輸出部分:N個(gè)檢索詞之間的查詢公式;
算法部分:
Getback-result = NULL;
For ( i=1; i<= 檢索詞的具體數(shù)目; i++)
{
Getback-result(i) = NULL;
在系統(tǒng)領(lǐng)域本體中查詢檢索詞對(duì)就的概念Ci;
對(duì)堆棧進(jìn)行初始化操作,設(shè)置stack成為空;
For (j=1; j<=Ci和根節(jié)點(diǎn)之間的距離值;j++)
{
確定Ci和其他父親節(jié)點(diǎn)間的路徑類型Fj,其中路徑是以有向邊加以表示;
進(jìn)行入棧操作;
Push ( stack, Fj, Ci )
}
當(dāng)堆棧stack不為空的時(shí)候
Getback-result (i ) = Getback-result ( i ) *pop (stack )
Getback-result = Getback-result Getbackresult ( i );
}
Return Getback-result ( i ) }
3 結(jié)束語(yǔ)
在實(shí)際檢索過(guò)程中,人們?cè)絹?lái)越認(rèn)識(shí)到通過(guò)基于本體的語(yǔ)義檢索的精確性以及高效性。本體在智能信息檢索系統(tǒng)中提供了必須的元語(yǔ),該元語(yǔ)能夠生成有效的查詢與資源表述,通過(guò)本體建立的領(lǐng)域語(yǔ)義,可以提供標(biāo)注信息,使檢索系統(tǒng)形成一個(gè)統(tǒng)一的認(rèn)識(shí)。這些認(rèn)識(shí)涉及到了域內(nèi)以域間的概念及聯(lián)系,從而提高了系統(tǒng)的聯(lián)想能力,也為終端用戶的檢索提供了有意義的信息。總之,本體已經(jīng)逐步成為智能信息檢索系統(tǒng)的知識(shí)表述,是整個(gè)系統(tǒng)的最核心部位。
[1] 張敏,宋睿華,馬少平. 基于語(yǔ)義關(guān)系查詢擴(kuò)展的文檔重構(gòu)方法[J]. 計(jì)算機(jī)學(xué)報(bào), 2009,(10).
[2] 張映海,何中市. 基于關(guān)鍵詞與語(yǔ)義概念結(jié)合的信息檢索研究[J]. 計(jì)算機(jī)應(yīng)用, 2009,(12).
[3] 李振東,費(fèi)翔林. 基于概念的信息檢索模型研究[J]. 南京大學(xué)學(xué)報(bào)(自然科學(xué)版), 2010,(01).
[4] Perez AG, Benjamins VR.Overview of Knowledge Sharing and Reuse Components: Ontologies and Problem-Solving Methods.Proceedings of the IJCAI-99 workshop on Ontologies and Problem-Solving Methods(KRR5).2009:1-15.
[5] 李曼,王大治,杜小勇,王珊.基于領(lǐng)域本體的Web服務(wù)動(dòng)態(tài)組合[J]. 計(jì)算機(jī)學(xué)報(bào), 2008,(04) .
[6] 洋,易禾,楊春. 基于關(guān)鍵詞語(yǔ)義擴(kuò)展的檢索策略[J]. 計(jì)算機(jī)應(yīng)用, 2009, (06) .
猜你喜歡
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
新聞傳播(2016年18期)2016-07-19 10:12:06
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
現(xiàn)代計(jì)算機(jī)(2016年11期)2016-02-28 18:35:15
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
河南科技(2014年11期)2014-02-27 14:10:19
