聚類算法在高脂血癥辨證分型研究中的應用*
2011-03-13 09:30:26涂泳秋易法令樸勝華周蘇娟
自動化與信息工程 2011年2期
關鍵詞:分類
涂泳秋 易法令 樸勝華 周蘇娟
(1.廣東藥學院醫藥信息工程學院 2.國家中醫藥管理局高脂血癥調肝降脂重點研究室3.國家中醫藥管理局脂代謝三級實驗室)
1 概述
高脂血癥是血管及臟器疾病的主要基礎病變之一,隨著人們生活水平的提高,高脂血癥的發病率呈逐年上升的趨勢。中醫藥在防治高脂血癥方面因其毒副作用小、療效明顯的優勢而日益受到醫學界的廣泛重視。但是,由于傳統中醫沒有高脂血癥的病名,且病證分散,臨床病變復雜,導致目前對高脂血癥的辨病和辨證分型尚未有統一的標準[1],不利于高脂血癥中醫辨證的規范化及對有效治療方案的歸納總結,影響科研成果的客觀評估和臨床推廣應用[2]。中醫對于建立一個完善的規范化、客觀化的高脂血癥辨證體系的研究已持續了三十年[3]仍沒有完全達到目標,探究其原因主要有以下兩條:其一,中醫對高脂血癥的辨證分型主要根據古籍文獻理論、患者主觀表現及臨床經驗來確認,用來統計分析的樣本存在片面性;其二,辨證體系、分型層次、學術流派及對兼夾證型認識的不同導致證型分類不統一,影響辨證分型的規范化[4]。
利用計算機挖掘技術建立疾病的中醫辨證模型的研究正日益受到關注和重視[5~7],高脂血癥辨證分型的規范化研究一個重要難點在于證型分類不統一,利用聚類分析算法對臨床四診信息進行自動分類,獲得統計學意義上的分類結果,并依此與已有證候表征進行比對,經過確定證型類別,發現了高脂血癥四診信息與辨證分型間的統計學規律,為高脂血癥辨證分型標準化研究奠定基礎,同時具有重要研究價值。
2 調查指標的設置
分析樣本為臨床采集的316例高脂血癥患者中醫四診調查數據。通過對其進行聚類分析,獲得相應的證型特點,與傳統的證型分類方法進行比較,以進一步佐證傳統分類方法的科學性。臨床樣本中記錄了316例患者的基本信息、血液查驗信息、中醫相關癥狀的臨床資料,包括患者的望診、問診、脈診信息等共54項。部分信息如圖1所示。
3 聚類分析方法
聚類分析,是按研究對象在性質上的親疏關系進行分類的一種多元統計方法,能夠反映變量或樣本間的內在組合關系。基本思想是,從一批樣品的多個觀測指標中,找出能度量樣品之間或指標之間的相似程度的統計量,構造一個對稱的相似性矩陣,在此基礎上進一步找尋各樣本之間或樣本組合之間的相似程度,按相似程度的大小,把樣本逐一歸類。關系密切的歸類聚集到小的分類單位,關系疏遠的聚類到大的分類單位,直到所有樣品或變量都聚集完畢,形成一個親疏關系譜系圖,用以更自然、更直觀地顯示分類對象的差異和聯系[8~10]。
聚類分析使用相似統計量進行分類,相似統計量是依據觀測數據所建立的分類指標。本文中用到的相似統計量為距離系數、夾角余弦以及相關系數,其計算公式如(1)~(3)所示。
3.1 相似統計量
3.1.1 距離系數
假設有n個樣本,每個樣本有m個分量。這時每個樣本可以看成是m維變量空間中的一個點,每個變量可以看成是n維樣本空間中的一個點。用點的歐幾里德距離表示研究對象的親疏關系。距離越小,關系越密切;距離越大,關系越不密切。
用行表示樣本、列表示變量的觀測數據矩陣,樣本間的距離系數如式(1)所示:
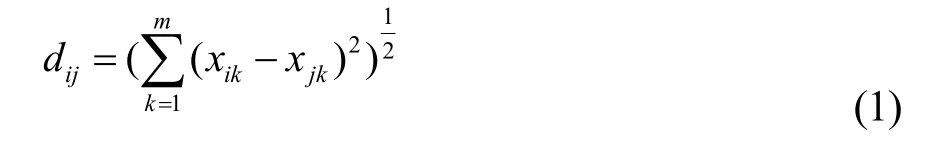
式中i,j = 1,2,...n,其中i,j均表示樣本的序號,k表示樣本中的分量號。
上面所定義的距離系數與變量的量綱有關,比如以米為單位時某變量為1,以厘米為單位時,就變成100,這會影響到距離的計算結果。為克服這個問題,在計算前需要對數據進行預處理。
此外,上面的距離系數要求與變量之間沒有相關性。如果變量之間存在相關性,則會影響分類結果。有多個相關變量支持的分類特征比沒有多個相關變量支持的特征,意味著有更大的權,在分類時會受到額外的“照顧”,因而有失公平。因此在算法實現中將使用逐步回歸法剔除相關變量。
3.1.2 夾角余弦
夾角余弦用角度的分割表示樣本之間的相似程度。在對樣本進行分類時,可以把每個樣本看成m維變量空間中的一個向量,樣本Xi= (xi1,xi2,...,xim)與樣本 Xj= (xj1,xj2,...,xjm) 之間的相似程度就可以用這兩個向量之間的夾角余弦cosθ表示,cosθ的值在1和-1之間變化,如果等于1則表示兩個樣本非常相似,接近1則很相似,如果數值很小,則表示樣本差異極大。夾角余弦的表達式如式(2)所示:
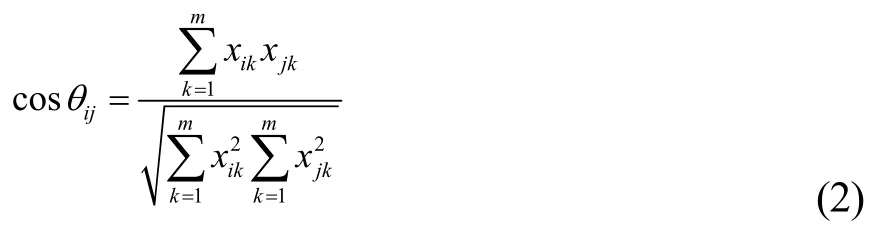
其中,i,j = 1,2,...,n。
3.1.3 相關系數
樣本之間的相關系數如式(3)所示:
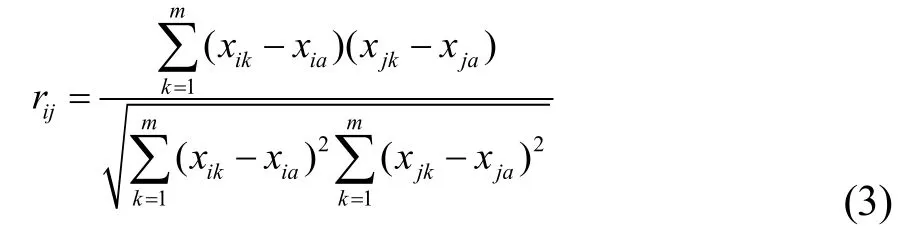
式中i,j = 1,2,...,n,i和j是樣本號,n 是樣本個數,m是變量個數。xia和xja分別表示i樣本和j樣本的平均值。
3.2 聚類分析的數據預處理
聚類分析的結果與量綱有關,為了消除量綱的影響,算法中用到了標準差標準化的數據預處理方法。計算公式如公式(4)~(6)所示。
標準差標準化預處理是將各個觀測值減去觀測值的平均值,再除以觀測值的標準差,即:

xia是平均值,其表達式為:

si是標準差如式(7)所示,經過標準差標準化處理的所有觀測值的平均值為0,標準差等于1。
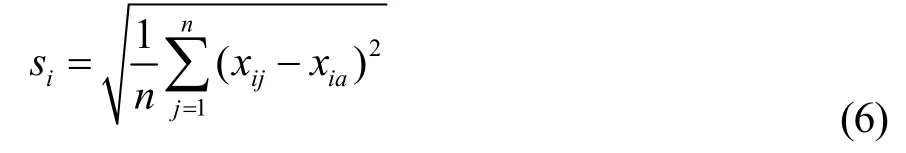
3.3 聚類算法構造
3.3.1 聚類算法思想
在聚類分析過程中,需要經過將類由多變少的聚類過程。其具體思想是:
(1)開始
每個樣本自成一群;
(2)合并
① 計算類的分類統計量(距離系數、夾角余弦、相關系數);
② 按某種分類統計量,將分類統計量最接近的兩個樣本(或群)合并成一群;
(3)求群的變量值
利用加權平均的方法求新群的各變量值。假定Li群與Lj群合并,Li群有Ni個樣本,Lj群有Nj個樣本,這時新群的k變量為:
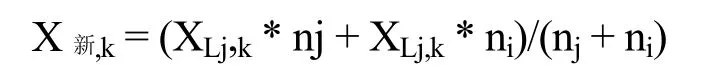
(4)終止
重復(2)到(3),直到所有的類歸為一群。
3.3.2 聚類算法
設定相似性條件P:0<=P<=1
(1)開始
所有樣本歸入同一群;
(2)計算:假如已分解為n個群C1,C2,………, Cn
① 計算類的分類統計量(距離系數、夾角余弦、相關系數):假如 Cm中有 k個樣本,則:Sm=sigma(cos(thetai,j))/k(k-1)
② 計算類平均相似性:S = (S1 + ……+Sn)/n
(3)判別
如果S>=P跳到(5)終止。否則下一步。
(4)分解
對Sm<P的每個類Cm, 對其中的每個樣本I:
① 為I創建一個新類Cn+1,或將I歸入其它類C1,…Cm-1,Cm+1,…,Cn中。分別計算S,使S增加最多的類獲勝。
② 若Sm>P,返回(3)
(5)終止
4 實驗結果與評價
利用該程序對前期搜集到的316例高脂血癥患者臨床癥狀資料進行聚類分析,設置相似度閾值為75%,如圖2所示。
圖2 設置閾值界面
對預處理過的數據進行聚類分析,如圖3所示,其中f1,f2……,f54分別對應中醫癥狀特征信息如:體胖身重,心悸……,脈細等。程序得到的最終聚類結果如圖4所示,將總樣本自動分為5類,得到每類的相似性得分以及每類對應的實例個數。同時得到了每個分類中最具代表性和最不具代表性的樣本實例所具有的特征,如圖5所示。以第一類為例,最具代表性的樣本具有體胖身重,頭暈,失眠……等特征;而最不具代表性的樣本具有體胖身重,頭暈,面色淡白等特征。
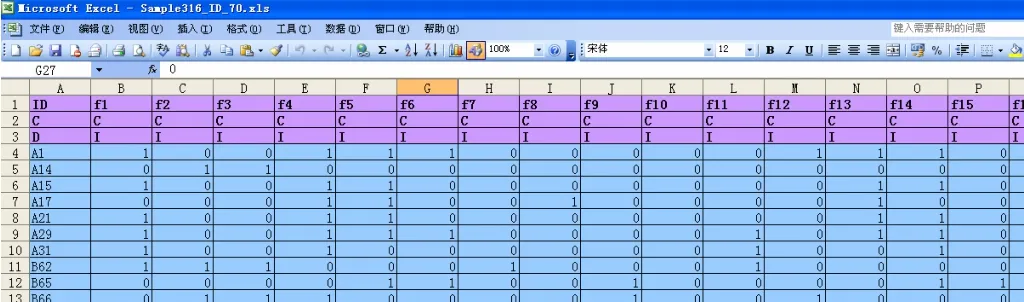
圖3 316例患者54種臨床癥狀記錄表截圖
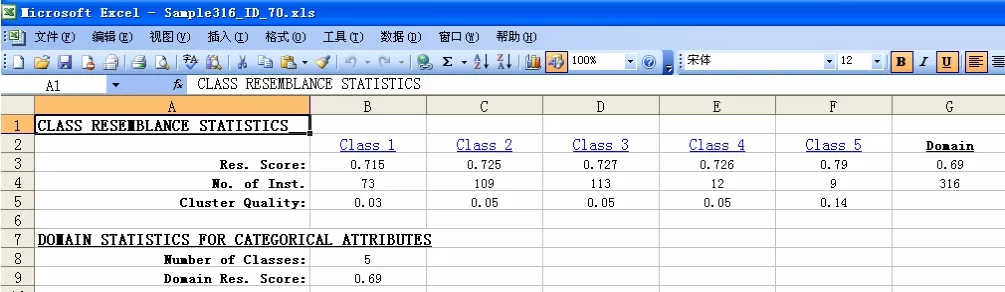
圖4 316個樣本的聚類分析結果
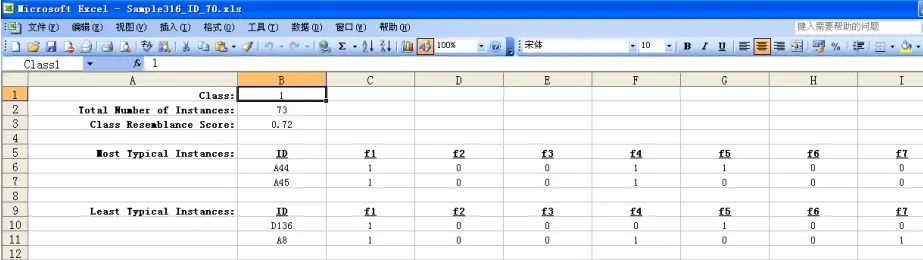
圖5 第一種分類中最典型與最不典型癥狀表
將聚類算法得到的五類實例與中醫師的證候判斷結果對比發現,這五類實例中80%以上的樣本分別對應于“痰濕內阻型”、“肝郁氣滯型”、“氣滯血瘀型”、“肝陽痰火型”、“脾腎陽虛型”五類證型,其中“肝陽痰火型”為兼雜證型。
5 小結
實現聚類分析算法并將其用于高脂血癥臨床病癥中醫證候研究中,通過對采集的臨床四診信息的聚類得到證候分型結果,與傳統經驗獲得的證候分類相對照,得到基于統計分析的客觀分類結果,為高脂血癥證候標準化研究奠定了基礎。
雖然聚類獲得的五個分型結果都得到了 70%左右的相似度,但第四類與第五類證型的實例數較前三類明顯偏低,因此高脂血癥臨床采集數據仍有待進一步擴充,使聚類的結果更科學客觀。除此之外,下一步工作的重點是將模糊規則理論引入到聚類算法中解決兼雜證型的分類問題,將兼雜證型與其相關證型關聯起來,而不再是完全獨立的一個分型。
[1]黃波夫.中醫治療高脂血癥研究進展[J].廣西中醫學院學報,2008,11(4): 102-104.
[2]陳建民.癌癥患者血液高黏度狀態與活血化瘀治療[J].中西醫結合雜志, 1985,5:89-91.
[3]唐沙玲.高脂血癥中醫研究進展[J].Internal Medcine of China.2008,3(1):129-131.
[4]錢小奇,陳紅,田曉虹等.高脂血癥中醫辨證分析不一致探因[J].深圳中西醫結合雜志,2007,17(2):25-26.
[5]王階,李海霞,孫占全等.基于復雜算法的中醫證候研究[J].北京中醫藥大學學報, 2006, 29 (9) : 581 – 585.
[6]白云靜,申洪波,孟慶剛等.基于人工神經網絡的中醫證候非線性建模研究[J].中國中醫藥信息雜志.2007, 14(7):3-6.
[7]聶莉芳,于大君,余仁歡等.308例IgA腎病中醫證候分布多中心前瞻性研究[J].北京中醫藥大學學報,2005,28(4):66-68.
[8]XU Rui, Wunsch., D. Survey of Clustering Algorithms[J].IEEE Transaction on Neural Networks, 2005,16(3):645-678.
[9]WANG Shi-tong, JIANG Hai-feng, LU Hong-jun. A New Integrated Clustering Algorithm GFC and Switching Regressions[J]. International Journal of Pattern Recognition and Artificial Intelligence, 2002,16(4):433-446.
[10]JIANG Sheng-yi, LI Xia. A Hybrid Clustering Algorithm[C].Fuzzy Systems and Knowledge Discovery, 2009, 1:366.
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
