提高個性化推薦精度的定制Web日志方法
2011-05-31 08:39:40蘇玉召中科院國家科學圖書館北京100190
圖書與情報 2011年5期
蘇玉召 (中科院國家科學圖書館 北京 100190)
牛曉太 趙 妍 (鄭州航空工業管理學院 河南鄭州 450015)
隨著網絡信息技術和智能軟件技術的發展,數字圖書館服務質量也得到了大幅度提高。一些數字圖書館網站不但能夠利用網絡信息技術提供圖書館員和讀者在線互動,而且實現了個性化推薦服務。這樣的服務不但提高了圖書館服務效率,而且方便了讀者獲取相關文獻和定期更新的內容。這是一種智能服務系統,由系統自動將用戶感興趣的圖書、文獻和服務信息推送給用戶,并以用戶電子郵箱、注冊賬戶頁面和手機屏幕等方式呈現。同時,這種服務可以采用商業化模式運行,實現讀者付費方式購買和網絡下載。記錄了用戶訪問網站過程的查詢、下載和交易等操作信息的Web日志數據就是一種這樣的數據。[1]通過對這些數據的處理和分析,能為企業發展做出正確的決策和預測提供事實依據。同時,個性化推薦系統實現了吸引用戶、增加人氣和增值服務的目標。
通常,個性化推薦系統分為基于規則過濾、基于內容過濾、基于協作過濾的方法以及這三種方法混合的具有智能性的推薦方法。[2]普通的Web日志格式采集到的數據無法滿足用戶分析、預測和推薦精度的需要,大部分定制專門的Web日志格式暫時能夠滿足目前業務需要。同時,各個企業定制的Web日志都是根據自己的需要,沒有統一的規范和標準化可以遵循,不利于將來數據中心進行數據集成和業務擴展。
本文通過對個性化推薦和數據建模研究,指出普通Web日志格式存在的不足,提出定制Web日志數據建模的過程及方法,建立了基于NSTL嵌入式系統的定制Web日志模型原型。通過定制Web日志的方式采集數據,實現發現關聯規則、內容分類和用戶聚類分析,從而提高個性化推薦的精度。
1 定制Web日志
1.1 問題描述
NSTL定制Web日志數據建模的目的,主要是通過捕獲用戶訪問活動操作瀏覽、查詢、下載、收藏、興趣定制和購買等信息,借助數據挖掘技術發現用戶訪問偏好,進行個性化推送服務,實現NSTL更好的數字圖書館服務功能。通過記錄Web日志的方式,在線收集讀者文獻查詢、下載和購買等信息的數據。系統對讀者訪問的這些日志數據進行分析、挖掘和預測,為其提供相關文獻推薦和定期更新內容推送服務。
1.2 日志建模
Web日志數據是一種特殊的數據類型,因此,數據建模理論適用于進行 Web 日志數據建模的應用研究。[3][4][5]個性化推薦內容的準確性,依賴于挖掘后獲取的用戶訪問內容的具體分類。Web日志中記錄的操作對象屬性完整性、準確性和唯一性,能夠提高定制Web日志的數據質量。
Web日志數據的特殊性在于:采集的數據都是基于用戶在Web頁面上的訪問行為,包括用戶在前臺的操作活動和應用程序在后臺記錄訪問的信息。因此,Web日志數據記錄的是用戶和網站的交換行為。進行Web日志數據建模應明確以下幾方面:
(1)建模采用的模型類型,在不同的建模階段,分別采用概念建模、邏輯建模和物理建模。
(2)建模方法,步驟:①弄清要做的事情包括哪些;②弄清捕獲的數據固有的質量水平;③重點弄清需要捕獲用戶訪問需要記錄的Web日志數據的定義;④重視數據質量;⑤弄清不同用戶對不同層次建模的不同需求。
(3)建模項目類型,主要有三類:①企業項目模型,需要捕獲全部動態數據;②交易項目模型捕獲一次一個用戶活動的具體信息;③數據倉庫/企業報表項目空間模型收集一次一個用戶活動的具體信息,并選擇和集成為簡化準確的報表。
(4)項目使用目標,是通過定制的Web日志數據,在數據質量方面實現提高個性化推薦的精度。
(5)業務類型,捕獲的數據對象和用戶與網站的交互活動有關。在Web日志數據建模方案中,與用戶活動相關的操作包括:瀏覽、查詢、下載、個人收藏、興趣和偏好定制和商品購買等,應用程序的業務根據這些用戶活動捕獲日志數據對象。
(6)業務對象,捕獲的Web日志數據對象,就是建模過程中需要處理的業務對象。在不同的業務平臺,用戶活動操作的對象也各不相同。在數字圖書館領域,業務對象主要是文獻,這些文獻可能是期刊、會議、書籍、專利或者報告等。
(7)對象屬性,不同的業務平臺,捕獲的Web日志數據對象屬性也各不相同。數字圖書館文獻的屬性主要包括題名、作者、關鍵詞、出版社、文獻類型、所屬領域和出版日期等。
(8)屬性命名規則,由于Web頁面存在結構化、半結構化和非結構化的數據對象,因此,需要將捕獲的日志進行結構化處理,記錄的日志數據嚴格按照設計的命名規則處理。
(9)用戶信息,主要記錄用戶注冊信息、興趣和偏好定制、個人收藏等。
(10)訪問時間,用戶的瀏覽、查詢、下載、個人收藏、興趣和偏好定制和商品購買等活動的時間變化,能夠體現其對該網站訪問的習慣、忠誠度和偏好的變化。
(11)使用數據的用戶,捕獲的Web日志數據要滿足不同用戶的需求。在建模階段,考慮使用模型的用戶,不但包括建模技術人員,而且將來的用戶還會包括數據分析師、決策者和進行業務擴展的應用程序開發技術員。
1.3 日志原型
NSTL日志模型屬于交易項目,捕獲一次一個用戶活動的操作信息,采集的日志數據主要用于統計分析、個性化推薦。
在原型系統中,采集的Web日志信息主要包括4個部分:用戶信息、用戶操作信息、購物籃信息、訂購信息。①用戶信息主要記錄用戶注冊的的個人信息,主要包括個人聯系方式、訪問Web頁面的操作統計信息等,包括:用戶標識號、登錄名、真實姓名、電話號碼、地址、注冊日期、最后一次訪問時間、登錄次數、電子郵件、簡單搜索次數、高級搜索次數、訂購次數和訂購總金額;②用戶操作信息主要記錄用戶訪問Web的方式、操作類型和操作對象,包括:用戶標識號、訪問時間、返回代碼、客戶IP地址、操作類型和操作對象;③購物籃信息主要記錄用戶已經放入購物籃,但還沒有提交訂購的信息。主要包括訂購文獻的名稱、價格列表,金額和訂單狀態信息,包括:用戶標識號、文獻列表、文獻數量、價格列表、購物籃金額、訂單號和是否發送郵件確認;④訂購信息主要記錄用戶訂單號、日期和訂單處理狀態,包括:用戶標識號、訂單號、訂單日期和訂單狀態。
1.4 日志數據預處理
本文實驗所用數據來自NSTL嵌入式資源服務系統2周內采集到的用戶訪問日志數據。按照日志數據清洗、轉換、加載的流程對日志數據進行了預處理(見圖1)。
數據清洗主要分為兩個步驟:去除冗余和無效記錄、分割關鍵字段。去除冗余是為了減少重復出現的字段,降低在數據挖掘階段權重重復的可能。去除無效記錄是為了減少一些錯誤的記錄數據、刪除沒有登錄的用戶訪問記錄,目的是有針對性地為注冊用戶提供個性化推薦服務。將用戶訪問時輸入的關鍵詞、操作類型和操作對象分割開來,增加數據挖掘是用戶興趣和偏好的比重,便于更好的提供個性化推薦服務。
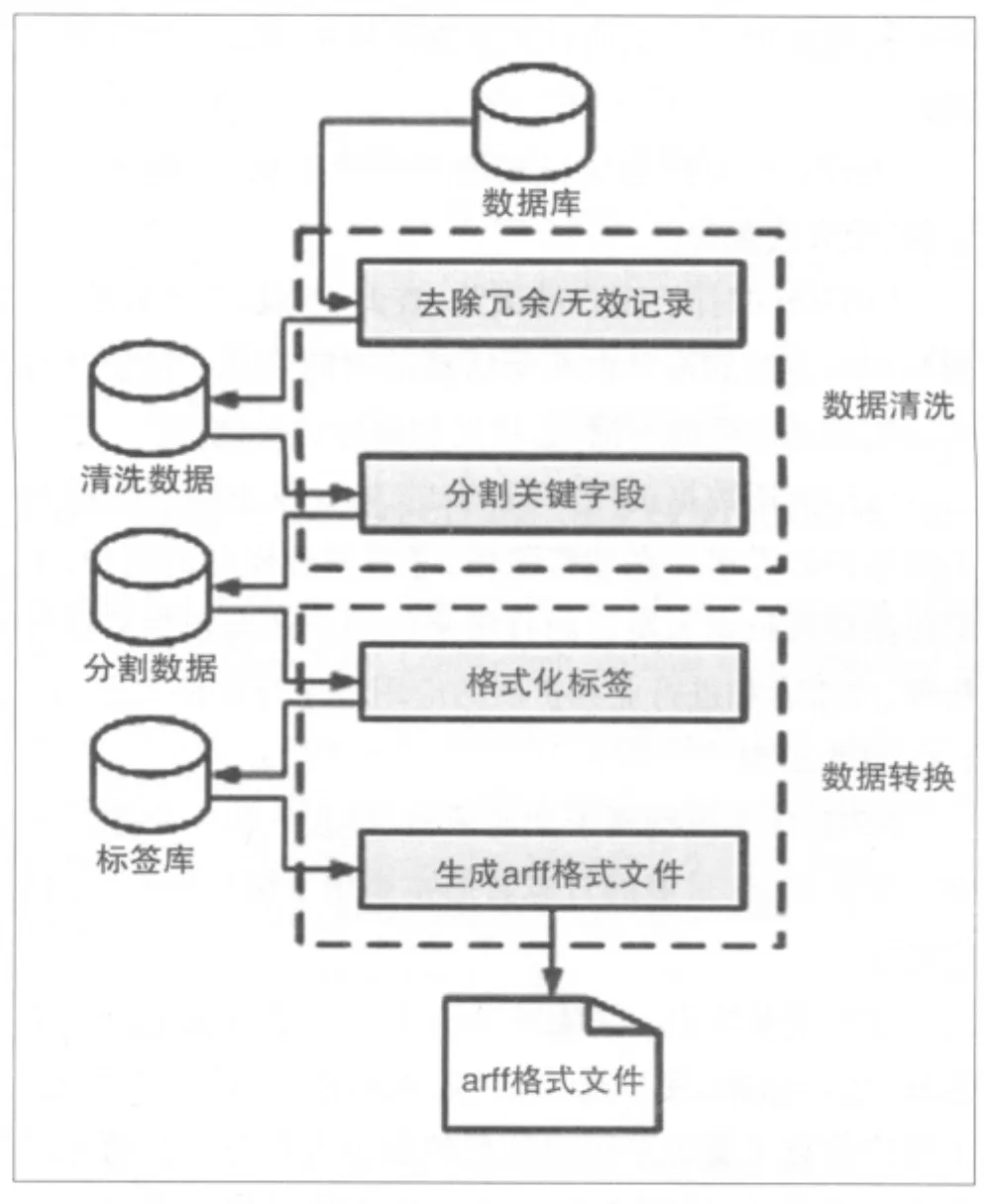
圖1 NSTL日志數據預處理
數據轉換的目的是將清洗過的數據轉換為挖掘工具易于識別的數據類型和格式,為的是得出理想的挖掘結果,從而便于發現用戶興趣和偏好。數據轉換主要分為兩個步驟:格式化標簽與生成arff格式文件。統計分析日志數據中重復出現的數據對象、操作類型、關鍵詞,用標簽的方式進行唯一標示,這樣做的好處是易于生成數據挖掘工具需要的數據格式,也節省了挖掘計算時間。生成的arff文件格式,可以方便地導入一些挖掘工具,例如Weka和RapidMiner等。
2 實驗結果及分析
在個性化推薦應用領域,通過Web日志挖掘技術,發現用戶興趣、使用偏好,推薦用戶可能感興趣的內容,幫助用戶快速找到需要的內容,吸引用戶對本系統的忠誠度,提高個性化服務能力和水平,實現價值增值。定制Web日志數據的方式能夠提高個性化推薦的精度,并且能夠簡化數據預處理工作、提高系統效率。用于Web日志挖掘的技術主要分為三類:關聯規則分析、分類分析和聚類分析。
2.1 關聯分析
在Web日志挖掘研究中,關聯規則分析目的是找出用戶訪問的日志中,所執行的操作與操作、操作和訪問對象、對象和對象之間的關系,進而預測用戶行為、興趣和偏好。
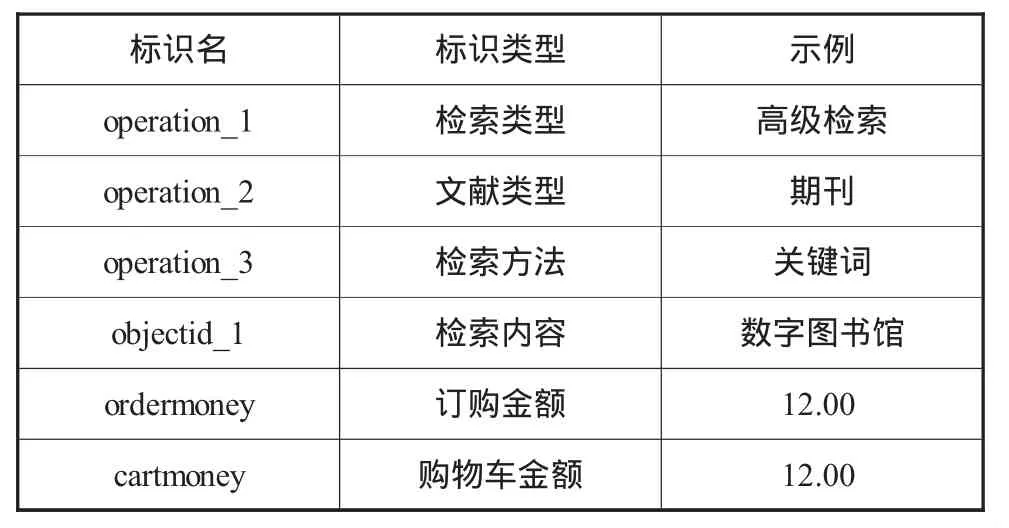
表1 關聯項目標識定義
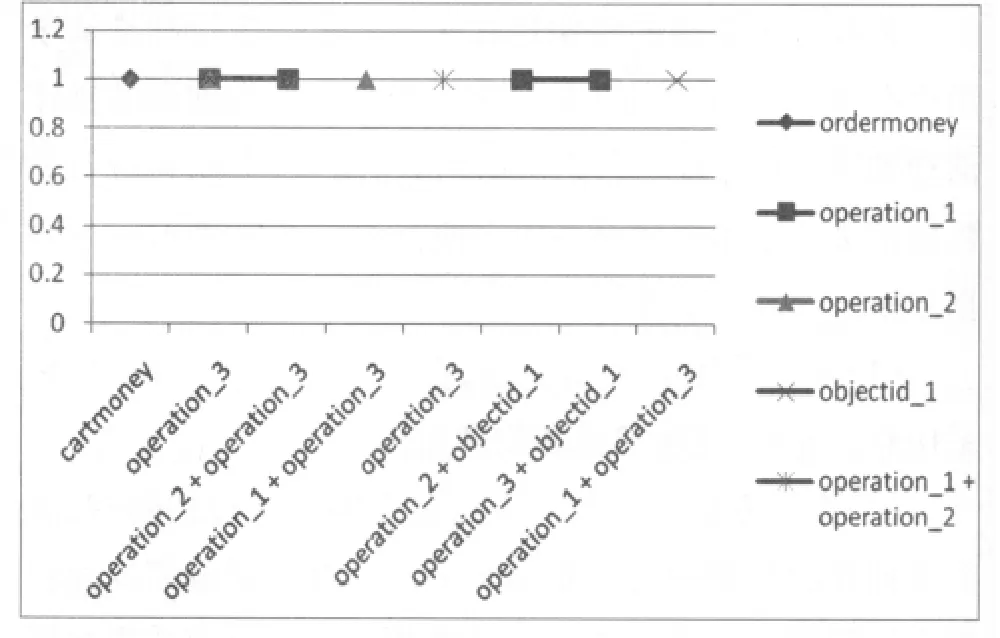
圖2 FileteredAssociator發現的關聯規則
在實驗中,根據 Apriori算法[6][7],枚舉出 10 個經過過濾的規則,在枚舉過程中,不斷減小最少支持度需找需要的并能滿足最小置信度的規則(實驗結果找到的前10條FilteredAssociator規則見圖2,其關聯項目標識定義見表1)。可以看出,具有很強的關聯關系的屬性是檢索類型、檢索方法、文獻類型和檢索內容,根據這些關聯規則預測更喜歡的推薦方式,將會更加吸引注冊用戶的興趣。同時發現,用戶一旦將訂購的文獻放入購物車,其購買項目的可能性就很大。可以推斷,此類用戶有很強烈的需求,在個性化推薦的時候,要重視推薦給此類用戶的質量,以維護其較高的客戶忠誠度。
通過關聯分析,能夠發現隱藏在定制Web日志數據里的操作對象和內容之間的關系,找到用戶的訪問興趣偏好、訪問習慣,預測用戶可能的需求。
2.2 分類
實驗采用J48算法生成剪枝的C4.5決策樹[8],以用戶操作類型為分類的類標,主要針對用戶操作進行分類(類標說明見表2,分類結果見圖3)。
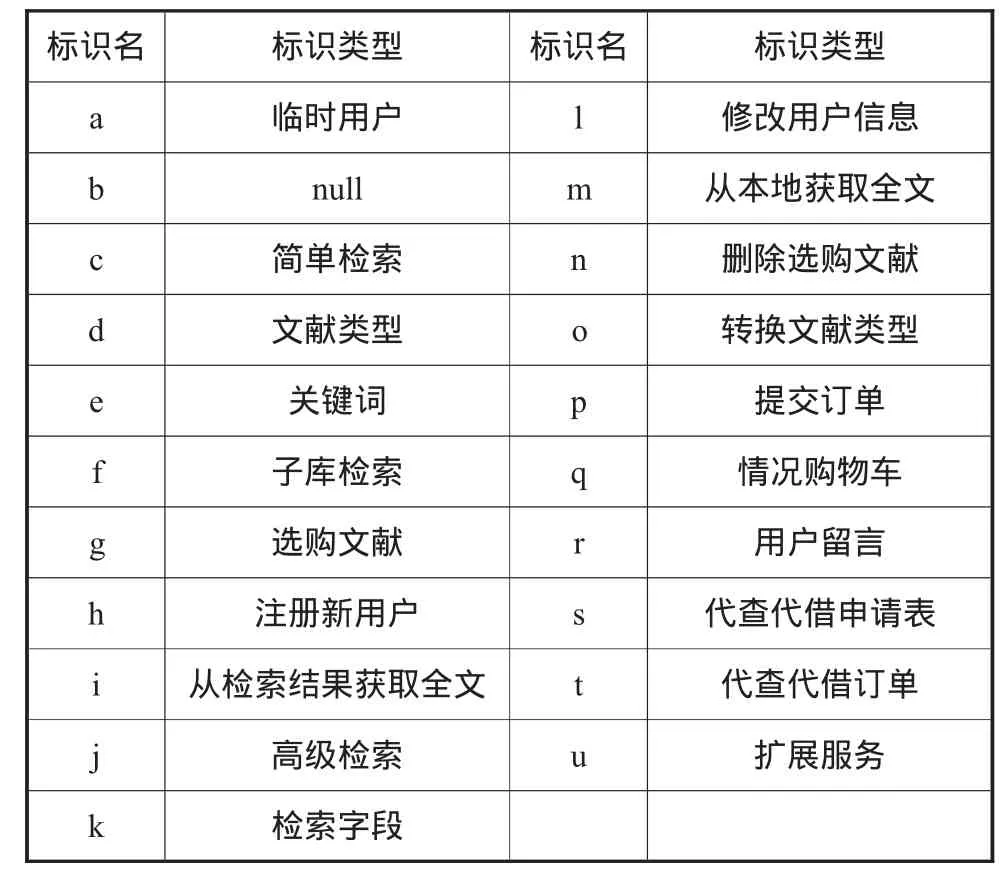
表2 用戶操作類型
從圖3實驗結果可以看出,用戶最常使用的方法是簡單檢索,分析原因可能有兩點:用戶不熟悉本系統的檢索方法或者是系統沒有提供個性化的服務功能。同時,還可以從圖中看出,有一些顯著的特征,分別是:高級檢索、從檢索結果獲取全文、選購文獻和提交訂單。從特征的顯著性程度看,高級檢索與選購文獻、提交訂單有著相似之處,因此,分析他們之間有較強的相關性,個性化推薦時候,可以考慮這種類別的用戶,重視推薦質量。相比較而言,用戶更喜歡直接從檢索結果中獲取全文,符合人們的常規習慣和方法。
通過分類挖掘,可以發現用戶感興趣的內容、類別、屬性,可以預測其潛在的客戶價值并實現個性化內容推薦。
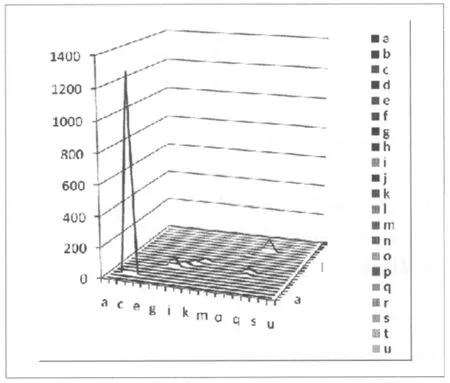
圖3 J48分類用戶操作類別
2.3 聚類
實驗采用 Cobweb 算法[9][10],其特點是:通過添加新葉子節點、合并或者分裂的方法實現聚類,是一種增量學習算法(對用戶和實例數目進行聚類實驗結果見圖4)。從圖中可以看出,聚類結果為4類典型的用戶特征。最顯著聚類用戶的特征是使用簡單搜索、訂購數量少和檢索期刊等,這是大多數用戶使用的方法。

圖4 Cobweb用戶-訪問實例聚類結果
找到為用戶推薦的內容是聚類分析的關鍵,將用戶訪問的內容進行聚類,為相似用戶推薦,實驗結果見圖5。圖5中橫向坐標表示檢索內容的領域,縱向坐標表示文獻類型。從圖中可以看出,用戶訪問的文獻領域分布比較廣泛,但是文獻類型主要分為兩種。出現這種情況的原因是,采集到的日志數據時間間隔較短,可能用戶研究方向各不相同,但是訪問的文獻類型較集中,再根據分類和關聯實驗結果分析,推測用戶具有類似的訪問行為。因此,推薦的時候,可以根據這些文獻類型進行推薦,例如,重點推薦期刊相關的文獻內容。
通過聚類分析,可以發現相似用戶的訪問行為和興趣偏好,通過系統對相似用戶的推薦,可以提高系統性能和效率,實現個性化推薦。定制的Web日志數據具有針對性強的特點,能夠準確地記錄用戶的訪問行為和操作內容,提高個性化推薦的精度。

圖5 Cobweb檢索領域—文獻類型聚類結果
2.4 性能評價
在實驗過程中,分別選取了幾個操作類型進行記錄日志前后計算時間的對比(實驗結果見圖6)。
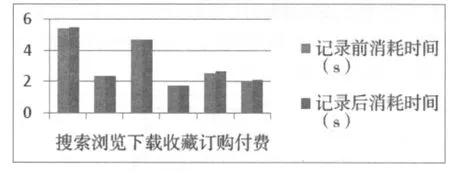
圖6 記錄日志前后時間對比
從圖中可以看出,記錄日志前后消耗的時間差別不明顯。實際上,由于記錄是在用戶客戶端收集信息,不消耗服務器的資源。同時,寫回到服務器端的數據庫表執行的是在表的尾部插入操作,不需要執行查找的操作。因此,記錄日志的代價很小。
Web日志分類實驗中,主要檢驗記錄的操作對象屬性完整性、準確性和唯一性,是否能夠提高日志的數據質量。其中,完整性體現在用戶操作過程是否連貫、完全,這些必要的信息缺失或者缺省會導致生成的日志數據無法識別用戶偏好內容;信息準確或者精度不夠,可能導致推薦精度不夠,無法滿足用戶需求;數據的唯一性是數據庫中該文獻是否存在及存在情況等信息。
實驗中,采用傳統的關聯、分類和聚類算法的目的有兩個:一是保證實驗的算法在成熟的情況下,實驗結果具有普遍意義;二是利于發現實驗中的Web日志模型存在的問題,促進該模型以后進一步完善。根據實驗結果分析,生成的關聯規則具有可用性,實驗結果與人工分析進行比較,能夠發現數據中存在的關聯規則。用戶操作方法的分類結果也基本與實際情況相符。聚類分析實驗中,分別對用戶訪問的實例和操作對象進行分析,實驗結果基本能夠識別出用戶所在類別,但是存在聚類不集中的情況。
根據以上分析,定制的Web日志數據能夠同時滿足發現關聯規則、內容分類和用戶聚類分析的需求,可以更好地滿足個性化推薦精度的需求。同時,定制Web日志還具有簡化數據預處理、多用途的優點。
3 結語
本文對數據建模技術進行研究,分析定制Web日志數據的建模方案。通過基于NSTL的日志數據模型原型的實驗結果及分析,驗證提出定制的Web日志數據建模方法和步驟。根據實驗結果分析,該模型具有一定的可行性。但是,原型系統中還存在諸多問題需要進一步解決。如方案中還沒有對捕獲的日志數據如何進行具體結構化問題進行深入探討,捕獲的對象的命名方式還要進行標準化處理。此外,實驗使用日志數據的完整性、準確性和唯一性問題,還需要進一步詳細化、具體化和準確性解決。
[1]蘇玉召,趙妍.個性化關鍵技術研究綜述[J].圖書與情報,2011,137(1):59-65.
[2]蘇玉召等.一種基于智能過濾的Web個性化推薦模型[J].圖書情報工作,2011,55(13):112-115.
[3]Sharon Allen,Evan Terry.Beginning Relational Data Modeling(Second Edition)[M].New York:Apress,2005.
[4]Reingruber,M.,W.Gregory.The Data Modeling Handbook[M].New York:Wiley,1994.
[5]Alan Chmura,J.Mark Heumann.Logical data modeling-What it is and How to do it[M].New York:Springer,2005:35-55.
[6]R.Agrawal,R.Srikant.Fast Algorithms for Mining Association Rules in Large Databases[C].The 20th Internatio nal Conference on Very Large Data Bases,1994:478-499.
[7]Bing Liu,Wynne Hsu,Yiming Ma.Integrating Classification and Association Rule Mining[C].the Fourth International Conference on Knowledge Discovery and Data Mining,1998:80-86.
[8]Ross Quinlan.C4.5:Programs for Machine Learning[M].San Mateo:Morgan Kaufmann Publishers,1993.
[9]D.Fisher.Knowledge acquisition via incremental conceptual clustering[J].Machine Learning,1987,2(2):139-172.
[10]J.H.Gennari,P.Langley,D.Fisher.Models of incremental concept formation[J].Artificial Intelligence,1990,(40):11-61.
