基于復(fù)合分類器的網(wǎng)絡(luò)入侵檢測模型
2011-06-06 06:34:10劉克文張賁王宇飛
電力建設(shè) 2011年11期
劉克文,張賁,王宇飛
(1.中國電力科學(xué)研究院,北京市,100192;2.華北電網(wǎng)有限公司,北京市,100053;3.華北電力大學(xué)控制與計算機工程學(xué)院,北京市,102206)
0 引言
隨著信息技術(shù)和互聯(lián)網(wǎng)的飛速發(fā)展,國家電網(wǎng)公司的信息化水平日益提高,信息系統(tǒng)也已滲透到整個公司的生產(chǎn)、經(jīng)營、管理等各環(huán)節(jié),并支撐了國家電網(wǎng)公司各項業(yè)務(wù)開展。但隨著公司網(wǎng)絡(luò)規(guī)模的擴大,網(wǎng)絡(luò)信息安全問題日益突顯,入侵檢測作為網(wǎng)絡(luò)信息安全的基礎(chǔ)性研究逐漸引起研究人員關(guān)注。入侵檢測是對入侵行為的檢測,入侵檢測系統(tǒng)通過收集網(wǎng)絡(luò)及計算機系統(tǒng)內(nèi)所有關(guān)鍵節(jié)點的信息,檢查網(wǎng)絡(luò)或系統(tǒng)中是否存在違反安全策略行為及被攻擊跡象。因而設(shè)計高效、準確的入侵檢測模型,現(xiàn)實意義重大。
解決入侵檢測問題的思路一般是將入侵檢測問題抽象成一個復(fù)雜的多分類問題,通過構(gòu)造分類器來實現(xiàn)對入侵檢測的判別。常用的入侵檢測算法有:核主成分分析(kernel principal component analysis,KPCA)結(jié)合前饋(back propagation,BP)神經(jīng)網(wǎng)絡(luò)構(gòu)造分類器[1];KPCA結(jié)合支持向量機(support vector machine,SVM)構(gòu)造分類器[2-3];粒子群算法(particle swarm optimization,PSO)優(yōu)化權(quán)重矩陣和閾值的BPNN構(gòu)造分類器[4];主 成 分 分 析 (principal component analysis,PCA)、線性判別分析 (linear discriminant analysis,LDA)和 K-最近鄰居法 (knearest neighbor,KNN)構(gòu)造分類器[5];PCA、KPCA等方法構(gòu)造分類器[6]。上述常用入侵檢測算法中存在數(shù)據(jù)冗余高、分類精度低、運算時間長和迭代次數(shù)多等問題。為更好地解決上述問題,本文設(shè)計了一種基于復(fù)合分類器的入侵檢測模型。復(fù)合分類器由KPCA、BP神經(jīng)網(wǎng)絡(luò)和量子遺傳算法(quantum genetic algorithm,QGA)組合而成。復(fù)合分類器通過對原始數(shù)據(jù)降維并優(yōu)化分類器參數(shù)的方式完成大量樣本的訓(xùn)練、分類模型生成,再使用分類模型對待測樣本做出準確分類,最后通過實驗證明了基于復(fù)合分類器的入侵檢測模型的有效性。
1 復(fù)合分類器
1.1 KPCA 算法
KPCA是一種高效的非線性特征選擇算法,適用于高維原始數(shù)據(jù)的主成分分析,即原始數(shù)據(jù)降維處理。KPCA改進自線性的PCA[7],KPCA的核心思想是將原n維歐氏空間Rn的數(shù)據(jù)通過核函數(shù)映射到Hilbert特征空間,在Hilbert空間作線性PCA。KPCA算法流程為:先引入從空間Rn到Hilbert空間的變換x=Φ(xi),并認為Φ(xi)已經(jīng)中心化,計算Hilbert空間中各點的協(xié)方差矩陣C

式中:m代表Hilbert空間維數(shù)。
設(shè)C的特征值為λ及非零特征值對應(yīng)的特征向量為υ,可證明υ一定處于由Φ(x1),…,Φ(xm)構(gòu)成的空間中,則υ可表示為

此時原問題變?yōu)榍蠼猞羒,則有

式中:K代表Φ(xi)和Φ(xj)的內(nèi)積,Kij=<Φ(xi),Φ(xj)> 是 Gram 矩陣。令 λn<αn,αn>=1,即 λn正交化,計算各Φ(xi)在υ上的投影gi(x),其中g(shù)i(x)是對應(yīng)于Φ(xi)的非線性主成分分量,

則g(x)=[g1(x),…,gn(x)]T為樣本的特征向量。比值 λ表示了分量gi(x)對樣本總體方差的貢獻度,最終選取若干個最大的特征值對應(yīng)的特征向量υi構(gòu)成實驗所需的特征子空間。
1.2 BP 神經(jīng)網(wǎng)絡(luò)
BP神經(jīng)網(wǎng)絡(luò)是一種典型的前饋網(wǎng)絡(luò),通過網(wǎng)絡(luò)結(jié)構(gòu)正向傳遞計算結(jié)果、使用訓(xùn)練函數(shù)反向修正網(wǎng)絡(luò)權(quán)重矩陣和閾值,完成樣本的訓(xùn)練模型的構(gòu)造,再使用構(gòu)造好的訓(xùn)練模型完成對待測樣本處理[8]。
下面幾個參數(shù)決定了BP神經(jīng)網(wǎng)絡(luò)最終精度:隱含層數(shù)目、每層神經(jīng)元個數(shù)、訓(xùn)練函數(shù)、學(xué)習(xí)函數(shù)、傳遞函數(shù)、權(quán)重矩陣和閾值。其中,除權(quán)重矩陣和閾值以外的其他參數(shù)均根據(jù)實際問題設(shè)定,而權(quán)重矩陣和閾值一般選[0,1]之間隨機數(shù)[9]。
1.3 QGA 算法
QGA是遺傳算法和量子計算相結(jié)合的算法[10]。與普通遺傳算法相比,QGA的特點是使用量子位編碼來表示染色體,并通過量子旋轉(zhuǎn)門和染色體交叉來完成種群進化,因而QGA種群規(guī)模更小,且收斂速度快,抗早熟能力強。
QGA中的染色體用量子位來描述,即隨機概率的方式。1個量子位既可以表示0或者1兩種狀態(tài),又可以表示0、1之間的任意中間態(tài)。設(shè)有m個量子位,則可以有2m種狀態(tài),所以QGA的種群規(guī)模遠小于普通遺傳算法(genetic algorithm,GA)。設(shè)a、b分別為狀態(tài)|0〉和|1〉的概率幅,在滿足|a|2+|b|2=1的情況下,則[0,1]之間任意量子狀態(tài)可表示為
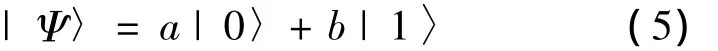
即狀態(tài)Ψ為狀態(tài)|0〉和|1〉的疊加。
在QGA中進化過程是由量子門旋轉(zhuǎn)和染色體交叉共同作用完成。量子門公式(6)中θ是旋轉(zhuǎn)角,U是量子門旋轉(zhuǎn)矩陣,公式(7)是量子位更新公式,
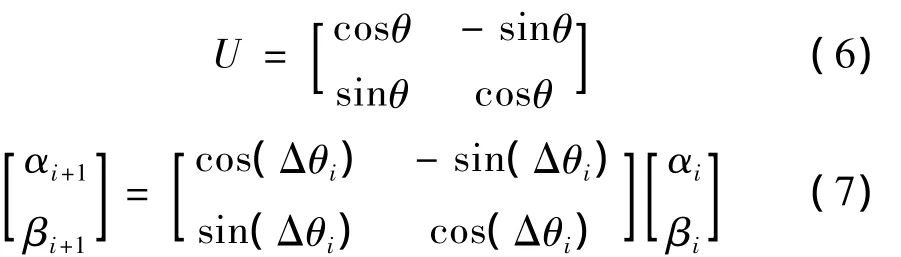
公式(7)中Δθi的大小直接決定了算法收斂速度,Δθi取值太小算法收斂很慢,Δθi取值太大種群易早熟,通常 Δθi∈[0.001π,0.005π]。染色體交叉的作用是防止種群早熟,通常采用全干擾交叉操作[11]。
2 基于復(fù)合分類器的入侵檢測模型設(shè)計
2.1 復(fù)合分類器模塊結(jié)構(gòu)
復(fù)合分類器由KPCA模塊、BP神經(jīng)網(wǎng)絡(luò)模塊和QGA模塊組成。其中KPCA模塊負責(zé)原始樣本數(shù)據(jù)降維處理,QGA模塊負責(zé)向BP神經(jīng)網(wǎng)絡(luò)傳遞訓(xùn)練參數(shù)并計算適應(yīng)度函數(shù)Fitness,由BP神經(jīng)網(wǎng)絡(luò)模塊完成最后的數(shù)據(jù)訓(xùn)練、分類,具體結(jié)構(gòu)見圖1。
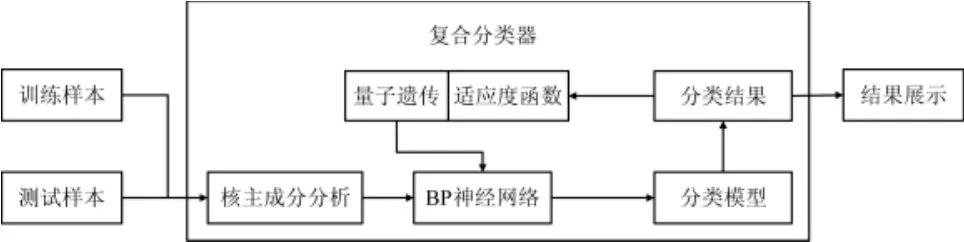
圖1 復(fù)合分類器結(jié)構(gòu)Fig.1 Construction of hybrid classifier
2.2 復(fù)合分類器模塊設(shè)計
2.2.1 KPCA 模塊設(shè)計
通常用于入侵檢測的原始數(shù)據(jù)均來自入侵檢測系統(tǒng)等網(wǎng)絡(luò)安全設(shè)備的日志,并且國家電網(wǎng)公司由于所屬各機構(gòu)具體使用的網(wǎng)絡(luò)安全設(shè)備品牌、功能各異,因而需要對各子機構(gòu)上報的日志做融合處理,即合并各類日志的不同數(shù)據(jù)字段。所以入侵檢測模型需要處理、分析的原始數(shù)據(jù)具有數(shù)據(jù)量大、維數(shù)高等特點,通常合并后的日志文件都以MB,甚至GB為存儲單位,并且日志中每條記錄的維數(shù)都有幾十維,甚至上百維。因而在針對入侵檢測問題設(shè)計復(fù)合分類器時,首要考慮的是對原始數(shù)據(jù)做降維處理,又因為每條記錄中不同維度之間常常是復(fù)雜的非線性關(guān)系,所以復(fù)合分類器使用KPCA做降維工具,具體選用Gauss徑向基函數(shù)作為KPCA核函數(shù)
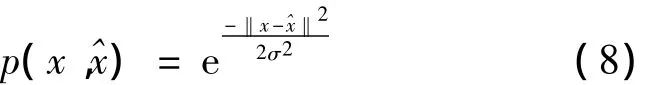
2.2.2 BP 神經(jīng)網(wǎng)絡(luò)模塊設(shè)計
復(fù)合分類器選用2層BP神經(jīng)網(wǎng)絡(luò)。設(shè)原始IDS的n維數(shù)據(jù)經(jīng)KPCA降維后得到m維新數(shù)據(jù)樣本,則在BP神經(jīng)網(wǎng)絡(luò)中選用m維數(shù)據(jù)做為BP神經(jīng)網(wǎng)絡(luò)的輸入數(shù)據(jù),即BP神經(jīng)網(wǎng)絡(luò)輸入層有m個神經(jīng)元。又因為待求解問題為分類問題,所以BP神經(jīng)網(wǎng)絡(luò)的輸出層是1個神經(jīng)元。BP神經(jīng)網(wǎng)絡(luò)的隱層神經(jīng)元個數(shù)為

式中:m、m′分別是輸入層、輸出層神經(jīng)元個數(shù),d是[1,10]之間的隨機整數(shù)。BP神經(jīng)網(wǎng)絡(luò)中傳遞函數(shù)均采用S型函數(shù)tansig。權(quán)重矩陣和閾值由QGA迭代給出。
2.2.3 適應(yīng)度函數(shù)
設(shè)測試樣本的總體分類準確率為Θ,則PSO的適應(yīng)度函數(shù)為

適應(yīng)度函數(shù)的閾值為Fθ,當F(i)<Fθ時,迭代結(jié)束。Fθ=1.0152 時,Θ =0.985。
3 實驗研究
為充分證明本文基于復(fù)合分類器的入侵檢測模型的有效性,設(shè)計2組實驗分別就入侵檢測模型的準確率和泛化能力給予驗證。其中:實驗一主要為驗證本文入侵檢測模型在國家電網(wǎng)網(wǎng)絡(luò)安全告警中的實用性;實驗二主要為驗證本文入侵檢測模型的泛化能力,并且與當前常用入侵檢測算法進行性能橫向比較。
3.1 實驗1
選用連續(xù)100天的網(wǎng)絡(luò)安全日志構(gòu)成實驗樣本,其中每條樣本的檢測時間間隔為1 s,并且每條樣本由72維數(shù)據(jù)字段構(gòu)成,其中2個特定字段分別定義了網(wǎng)絡(luò)攻擊大類和具體攻擊子類其余70個字段分別表示記錄的不同特征。其中日志共包含5大類告警,分別為“惡意軟件類”、“網(wǎng)絡(luò)攻擊類”、“信息破壞類”、“信息內(nèi)容安全類”和“其他告警”等。連續(xù)100天的日志共有8226217條記錄,從中隨機抽取10%的原始數(shù)據(jù)822622條做實驗數(shù)據(jù),并從實驗數(shù)據(jù)中隨機抽取70%的數(shù)據(jù)575835條做訓(xùn)練樣本,其余30%的數(shù)據(jù)246787條做測試樣本,再隨機抽取10%的數(shù)據(jù)82262條用于KPCA降維,詳細樣本抽取情況如表1所示。
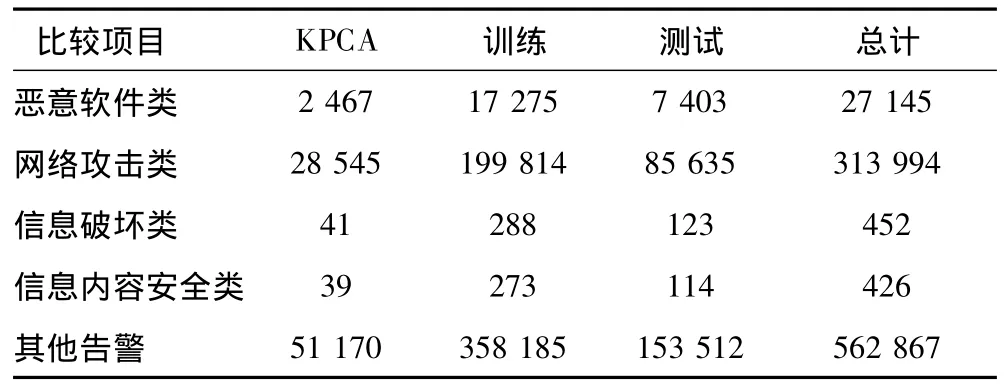
表1 實驗1樣本Tab.1 No.1 experimental samples
在確定實驗樣本后,需對原始實驗樣本做降維處理。對原始樣本記錄中除表示入侵分類的2個特殊字段以外的70維字段用KPCA做降維處理,KPCA核函數(shù)參數(shù)取10,得到70維特征對應(yīng)的λi。取其中λi最大的前10項構(gòu)成新數(shù)據(jù)樣本,每項的λi如表2所示,可以根據(jù)算出新樣本分量(x)對樣本總體方差的貢獻度大于85%。

表2 KPCA計算結(jié)果(實驗1)Tab.2 Results of KPCA algorithm for No.1 experiment
將KPCA降維后的訓(xùn)練樣本送入BP神經(jīng)網(wǎng)絡(luò),得到訓(xùn)練模型,訓(xùn)練模型權(quán)重矩陣和閾值由QGA迭代得到,QGA最大迭代次數(shù)1500,BP神經(jīng)網(wǎng)絡(luò)訓(xùn)練次數(shù)10000,實驗結(jié)果見表3。設(shè)某一類樣本是正樣本,則其他類別樣本統(tǒng)稱為負樣本,可得漏報率(正樣本出錯個數(shù)/正樣本總數(shù))和誤報率(負樣本出錯個數(shù)/負樣本總數(shù))。
由表3可知,國家電網(wǎng)實驗樣本最終的分類正確率達到98.5002%,與入侵檢測模型設(shè)定的收斂閾值0.985非常接近,但對于小類別樣本的誤報率和漏報率偏高。其原因在于:(1)因為實驗樣本采集自真實公司網(wǎng)絡(luò)環(huán)境,因此數(shù)據(jù)壞點和噪聲不可避免;(2)使用KPCA降維雖然大大減少了實驗運算量,但也忽略了部分影響因素(略去的60維數(shù)據(jù));(3)神經(jīng)網(wǎng)絡(luò)對于小類別樣本的不敏感性也造成了較高的漏報率和誤報率。但從入侵檢測整體上衡量實驗一的結(jié)果,其入侵檢測模型可信度較高,能達到事先設(shè)定的期望值0.985。

表3 QGA&BPNN實驗結(jié)果(實驗1)Tab.3 Results of QGA & BPNN for No.1 experiment
3.2 實驗2
選用 KDDCUP99數(shù)據(jù)集[12]做實驗數(shù)據(jù),KDDCUP99數(shù)據(jù)集中將樣本數(shù)據(jù)分為Normal(正常)、DoS(拒絕服務(wù))、R2L(遠程主機的未授權(quán)訪問)、U2R(未授權(quán)的本地超級用戶特權(quán)訪問)、Probe(端口掃描)等。因 KDDCUP99原始數(shù)據(jù)接近5000000條,為方便實驗本文在保持原始數(shù)據(jù)類別比例結(jié)構(gòu)不變情況下,隨機抽取10%的原始數(shù)據(jù)494021條做實驗數(shù)據(jù),并從實驗數(shù)據(jù)中隨機抽取70%的數(shù)據(jù)345815條做訓(xùn)練樣本,其余30%的數(shù)據(jù)148206條做測試樣本,再隨機抽取10%的數(shù)據(jù)49405條用于KPCA降維,詳細樣本抽取情況如表4所示。

表4 實驗樣本(實驗2)Tab.4 No.2 experimental samples
在確定實驗樣本后,需對原始實驗樣本做數(shù)據(jù)結(jié)構(gòu)分析處理,即降維處理。KDDCUP99原始數(shù)據(jù)有42維,其中前41維是樣本特征,最后1維是樣本的分類,因此對樣本前41維用KPCA做降維處理,KPCA核函數(shù)參數(shù)取80,得到41維特征對應(yīng)的λi。其中前10維的λi也是41個λi中值最大的10項,如表5所示,其他31維的 λi取值范圍均在[9.51×10-8,2.65 ×10-4],所以取 λi最大的前10 項特征構(gòu)成新樣本,根據(jù)算出新樣本分量對樣本總體方差的貢獻度大于96%。

表5 KPCA計算結(jié)果(實驗2)Tab.5 Results of KPCA algorithm for No.2 experiment
將KPCA降維后的訓(xùn)練樣本送入BPNN,得到訓(xùn)練模型,訓(xùn)練模型權(quán)重矩陣和閾值由QGA迭代得到,QGA最大迭代次數(shù)2000,BPNN訓(xùn)練次數(shù)15000。QGA的Fitness曲線見圖2。從圖2可知,在第400代左右適應(yīng)度函數(shù)基本趨于穩(wěn)定,最終在第810代收斂于Fθ,即總體分類正確率不小于0.985,實驗結(jié)果見表6。

圖2 適應(yīng)度函數(shù)曲線Fig.2 Curve of fitness function

表6 QGA&BPNN實驗結(jié)果(實驗2)Tab.6 Results of QGA & BPNN for No.2 experiment
橫坐標為進化代數(shù)(0,100,200,),縱坐標為適應(yīng)度函數(shù),為進一步體現(xiàn)本文入侵檢測模型的算法優(yōu)勢,現(xiàn)選取 KPCA 結(jié)合 BP 方法[1]、SVM 方法[2]、PSO結(jié)合BP方法[4]做橫向比較,結(jié)果見表7。

表7 實驗結(jié)果比較Tab.7 Comparison of experimental results
由表7可知,其他分類算法在準確度上并不理想,特別是FPR偏高。其原因為:文獻[1]使用未經(jīng)參數(shù)優(yōu)化的BPNN做分類器,因而不可避免神經(jīng)網(wǎng)絡(luò)易陷于局部極小點、權(quán)重和閾值選取困難等固有弱點;文獻[2]沒有使用群智能優(yōu)化算法為SVM尋參,因而造成訓(xùn)練模型精度低;文獻[4]沒有對原始數(shù)據(jù)降維,所以算法分類時間遠高于其他分類算法,并且PSO的局部尋優(yōu)能力不如QGA,因而誤差較大。
4 結(jié)論
本文設(shè)計了一種由KPCA、BPNN和QGA 3種人工智能算法組合而成的入侵檢測模型,克服了原有入侵檢測算法中普遍存在的數(shù)據(jù)維數(shù)高、分類器參數(shù)選取困難、分類器準確率低等問題。相比于其他常見入侵檢測算法,本文的基于復(fù)合分類器的入侵檢測模型在分類準確率方面優(yōu)勢明顯。又因本文實驗數(shù)據(jù)集隨機抽取自海量原始樣本,并且訓(xùn)練樣本集和測試樣本集不存在交集,即完全獨立,從而保證了100%開集分類測試,所以復(fù)合分類器的泛化能力得到保證。最后通過實驗證明了復(fù)合分類器的有效性。
[1]劉完芳,黃生葉,常衛(wèi)東.基于KPCA入侵檢測特征提取技術(shù)[J].微計算機信息,2007,13(9):81-83.
[2]Bao P Q,Yang M F.Intrusion detection based on KCPA and SVM[J].Computer Applications and Software,2006,23(2):125-127.
[3]Sun Z B,Sun M S.A Multi-classification intrusion detection system based on KPCA and SVM[J].Information Technology,2007,7(11):29-31.
[4] Lin Z M,Chen G L,Guo W L,et al.PSO-BPNN-based prediction of network security situation[C]//The 3rd International Conference on Innovative Computing Information and Control.Fuzhou,China:IEEE,2008:37-41.
[5] Zhang R X,Wang Y.Fusion of PCA and LDA for intrusion detection[J].Computer Technology and Development,2009,19(11):132-135.
[6]Gao H H,Yang H H,Wang X Y.PCA/KPCA feature extraction approach to SVM for anomaly detection[J].Journal of East China University of Science and Technology:Natural Science Edition,2006,32(3):321-326.
[7] Martinez A M,Kaka A C.PCA versus LDA[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2001,23(2):228-233.
[8] Bilski J,Rutkowski L.A fast training algorithm for neural networks[J].IEEE Trans on Circuits and System II:Analog and Digital Signal Processing,1998,45(6):749-753.
[9] Purucker M C.Neural network quarterbacking[J].IEEE Potentials,1996,15(3):9-15.
[10] Li B B,Wang L.A hybrid quantum-inspired genetic algorithm for multiobjective flow shop scheduling[J].IEEE Trans on Systems,Man,and Cybernetics,Part B:Cybernetics,2007,37(3):576-591.
[11] Narayanan A,Moore M.Quantum-inspired genetic algorithm[C]//Proc.of IEEE International Conference on Evolutionary Computation.Piscataway,USA:IEEE,1996:279-294.
[12] Hettich S,Bay S D.KDD cup 99 task description[EB/OL].http://kdd.ics.uci.edu/databases/kddcup 99/task.html.1999.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
