雙曲正切函數在事故黑點鑒別中的應用
2011-09-03 06:13:00方守恩
哈爾濱工業大學學報 2011年10期
楊 軫,唐 瑩,方守恩
(同濟大學交通運輸工程學院,201804上海,yangzhen2276@263.net)
交通事故在道路上是非均勻分布的,道路路段中具有突出事故頻率的事故位置被稱為事故黑點.傳統的事故黑點鑒別方法有事故數法、事故率法、傳統貝葉斯法等,近年來,國內外交通安全領域學者對事故黑點鑒別作了很多深入的研究,提出了經驗貝葉斯法、質量控制法、累計頻率法等[1-7].
其中累計頻率法被廣泛地應用于公路事故黑點的鑒別中,它特別適應中國目前基礎數據相對缺乏,各地道路安全狀況差別大的實際情況[8].
在累計頻率法中,需要選取合適的公式對累計頻率散點圖進行擬合,擬合公式的選取對黑點鑒別有一定的影響.常用的擬合公式有多項式、指數函數和雙指數函數等,其中中華人民共和國公共安全行業標準《道路交通事故多發位置認定方法(征求意見稿)》提出采用雙指數函數作為累計頻率法的擬合公式.在實際使用中,這些擬合公式或多或少都存在一定的缺陷,多項式擬合單調性很差,指數函數和雙指數函數y=a×ebx+c×edx單調性較好,通常效果也不錯,但當路段事故集中程度很高或者事故統計時間很長時,曲線擬合的相關性變差,需要提出一種適應性更好的擬合函數.
此外,以往的事故黑點鑒別方法中,尚未有學者對鑒別結果的有效性進行研究,特別是定量分析不同累計交通量和不同檢測方法對事故黑點鑒定的檢出率和誤檢率的影響.《道路交通事故多發位置認定方法(征求意見稿)》中要求分析所用的事故數據時間為1~3 a,但并未就統計年限對檢出率和誤檢率的影響進行詳細說明,并且不同的道路其交通量和事故率差異很大,用單一的統計時間來限定值得商榷.
由于事故發生具有隨機性,僅從事故的統計結果不能直接推導出路段事故率的期望值.為此,本文提出了基于隨機仿真的黑點位置鑒別比較方法,其思路為:首先從多年運營的代表性道路的事故資料中分別統計獲得各路段單元的事故率;然后,根據該事故率組按照事故發生統計規律通過計算機模擬產生不同累計交通量下一系列事故數據,并根據這些數據采用不同的擬合方法進行黑點鑒別;最后,將擬合結果同期望事故黑點域進行比較,分析不同鑒別方法在曲線擬合相關性,不同累計交通量下事故黑點檢出率、誤檢率等方面的差異以推薦最佳的鑒別方法及適應條件.考慮到仿真的隨機性,可以采用多次仿真(一般不少于10次)進行綜合比較.
1 事故仿真
對于具有事故率為P0(車公里事故率)的路段,其發生交通事故的次數符合二項分布[4],即
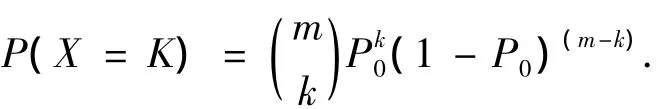
其中:k為發生的事故次數;m為道路上累計作用的交通量(車公里);P0為路網或某類道路的平均事故率(車公里事故率).
對于一段較長公路而言,各路段的道路設計指標和周邊環境有所差異,各路段的事故率也各不相同,事故率高的路段往往表明該路段存在缺陷.因此,在分析不同路段上一定累計作用交通量的事故發生次數概率時,應該采用該路段的事故率,其期望值可以從多年運營的道路事故頻數進行估計.而進行事故次數仿真時,該路段的事故發生次數符合其對應事故率的貝努利實驗.
對于一條100 km長的高速公路,采用傳統方法進行分段,以1 km為一個單元,把公路分為100段,以滬杭高速公路浙江段2005年至2009年的下行方向事故數據為基礎對每個路段取一個合適的事故率,如圖1所示.運用數理統計的原理,在Matlab中運用binornd函數對每個路段隨機產生一系列的事故數據,可以把這些事故次數看作是每個路段在對應統計年限內發生的事故次數.函數中累計交通量的不同代表事故統計年限的變化,統計年限越長,對應在路段上累計交通量就越大.3類典型統計時間分別定義為統計年限短(累計交通量取106),統計年限適中(累計交通量取5×106),統計年限長(累計交通量取5×107),按照高速公路單向平均日交通量為2.5×104計算,分別相當于1.5個月,7個月,5.5 a交通量.每類統計年限,隨機產生10×100=1 000個事故數.
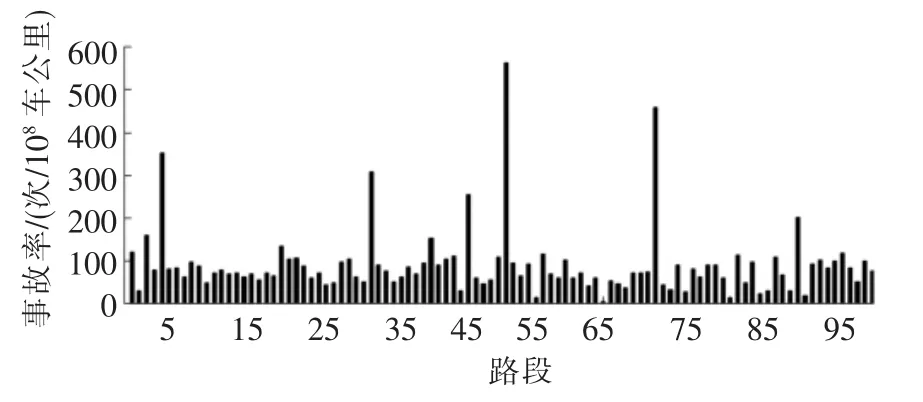
圖1 路段事故率
2 雙曲正切函數擬合分析
根據《道路交通事故多發位置認定方法(征求意見稿)》,對隨機仿真產生的事故數據進行分析,可繪制累計頻率散點圖.從散點圖的形狀方面進行分析,當事故統計時間較短時,累計頻率散點呈凸形,這與雙指數函數形狀比較接近,而當事故數據統計時間很長時,累計頻率散點呈現S型,而且具備明顯的漸進線,這與雙指數函數的形狀有一定的差異.為了完善累計頻率法,可以考慮選取與累計頻率散點圖變化趨勢近似的曲線作為擬合公式.考察雙曲正切函數y=a+b×tanh(cx+cd)的特點,通過平移和縮放該曲線,在[0,1]區間內可以產生不同的形狀,可較好適應不同條件下的累計頻率散點擬合.圖2為不同統計年限下事故黑點累計頻率曲線散點圖與雙曲線正切擬合.圖3為事故統計年限很長時雙指數函數與雙曲正切函數擬合的對比分析.
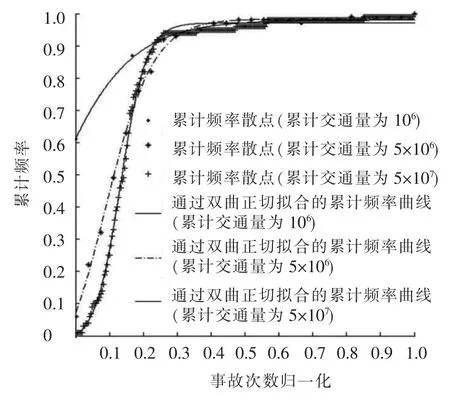
圖2 累計頻率曲線散點圖與雙曲正切擬合
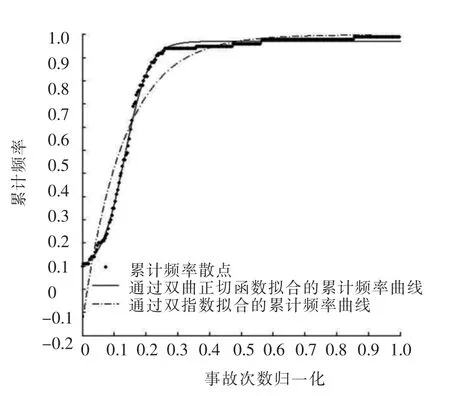
圖3 累計頻率擬合曲線對比圖
不難發現,雙曲正切函數能較好適應不同事故統計年限下的累計頻率曲線擬合,尤其對于統計年限較長的情況相對雙指數函數來講具有更好的適應性.
表1分別是3種不同交通年限下10次仿真后對累計頻率曲線采用雙曲正切函數擬合的參數統計結果.
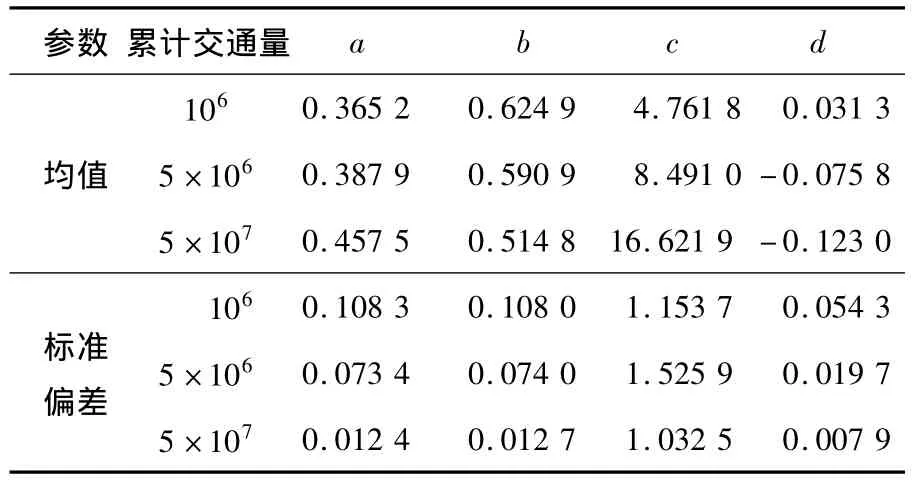
表1 雙曲正切函數擬合參數統計結果
分析可知:累計交通量越大(對應事故數據統計年限越長),a越大,b越小,c越大,d越小;當累計交通量小時,d值為正,當累計交通量適中時,d的符號不確定,當累計交通量大時,d值為負,d的正負可以反映事故數據的大概統計年限;統計年限越長,參數的相對標準偏差越小,說明黑點鑒別越穩定.
3 黑點鑒別方法有效性分析
為了分析雙指數函數與雙曲正切曲線擬合鑒別的差異性,將不同統計年限下的10次仿真數據產生的累計頻率分別按不同的擬合公式進行擬合,求出擬合曲線上的最小曲率半徑的位置作為事故黑點鑒別的臨界值,并根據該臨界值查找出相應的事故黑點的位置,與期望黑點位置進行比較.
期望黑點域表示真實的黑點位置.理論上,對于當道路上的累計交通量無窮大時,各路段發生的事故次數與其事故率成正比.為了便于分析,將各路段事故率×107作為路段的事故發生次數,并在整數區間進行累計頻率計算和黑點鑒別.由于采用雙指數函數擬合鑒別出的期望事故黑點數是6個,而采用雙曲正切函數鑒別出來的結果是8個,綜合兩者,取期望事故黑點個數取7個,分別對應的路段是 K51+000,K71+000,K5+000,K33+000,K46+000,K90+000 和 K3+000.若鑒別出來的事故位置個數在期望位置域中比重高,則表示檢測有效性高,如果檢測的位置不在期望域中,則代表誤檢情況.應該說明的是,誤檢情況發生不僅受檢測方法的影響,同時也受隨機數產生的影響,但是從統計的角度對比分析,仍能準確評價檢測方法的有效性.
表2為雙指數函數和雙曲正切函數擬合的鑒別結果.對上述事故黑點鑒別結果提取出檢出率和誤檢率,并作進一步的統計分析,如表3所示.
對比不同累計交通量下事故黑點鑒別結果可以發現:隨著累計交通量的增長,2種方法對事故黑點的檢出率均有不同程度的增加,但增加并不顯著;而交通量對誤檢率的影響非常顯著,在累計交通量小時,事故黑點的誤檢率非常高,甚至大于70%.這是因為盡管各路段的事故率有所差異,但交通事故的真實發生具有隨機性,當事故累計交通量不大時,路段發生的事故次數較少,該隨機數的方差與期望值的比值較大,故而各路段真實事故率表現不充分,誤檢率較高.當累計作用交通量增大,對應的事故次數增加,該隨機數的方差與期望值的比值降低,各路段真實事故率表現充分,誤檢率迅速降低.由于累計頻率曲線法是以較長范圍路段實際發生的事故為統計依據,是一種事后檢測方法而非預測法,因此在實際操作中若有控制誤檢率,應給出相應的事故次數.根據以實際事故數據為基礎的仿真分析,若以誤檢率20%左右控制,相當于5×106累計交通量下產生的事故次數,對應的全路段的平均每公里的發生的事故次數約為4~5次,這對滬杭高速公路來說相當于7個月的統計時間.對于交通量小或者平均事故率很低的道路,為獲得較低的誤檢率,必須有較長的統計年限的事故數據為基礎,使各路段的事故率表達充分.對比2種函數的累計頻率曲線擬合黑點鑒別結果可以得出:
1)在較低累計交通量下2種函數擬合的效果差別性不大,相關系數都較高.隨著交通量的增大,雙指數函數的擬合相關性有所降低,尤其是在曲率最大位置(黑點判別臨界值)與實際情況相差較大(見圖3),而雙曲正切函數仍然保持很高的相關性,曲線擬合效果也好.
2)雙曲正切函數在事故黑點的檢出率上稍高于雙指數函數,在誤檢率上略差于后者.這是因為兩者各自的期望事故黑點數有所差異,前者高于后者,而為了比較本文采用了兩者的平均值作為真實期望值.值得一提的是,雙曲正切函數擬合對于大累計交通量的情況下擬合相關性要顯著高于后者,理論上將前者期望值作為真實期望值更為合理,這時雙曲正切函數的誤檢率將能顯著提高,而雙指數函數的檢出率將明顯降低.
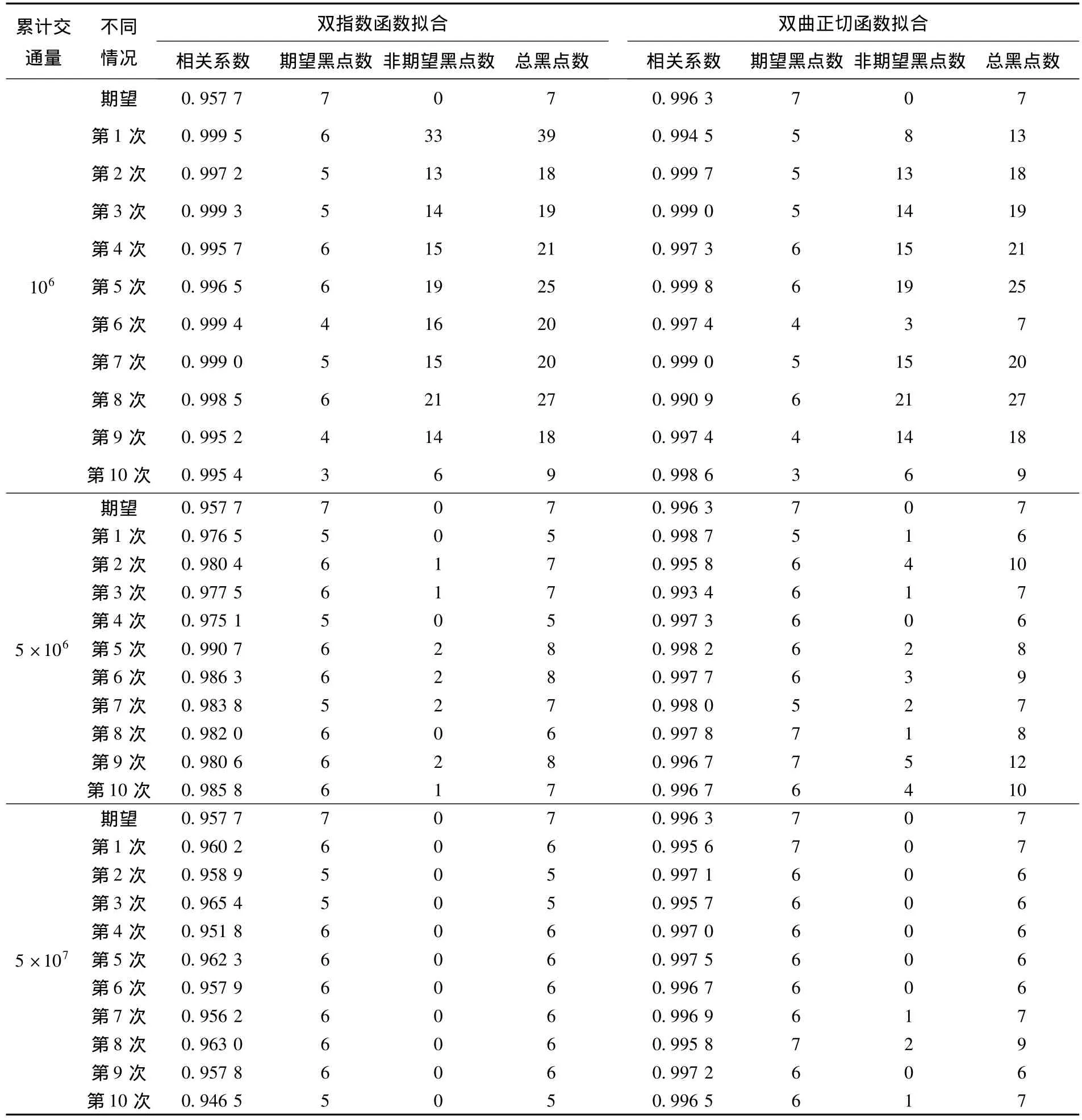
表2 雙指數函數擬合黑點鑒別結果
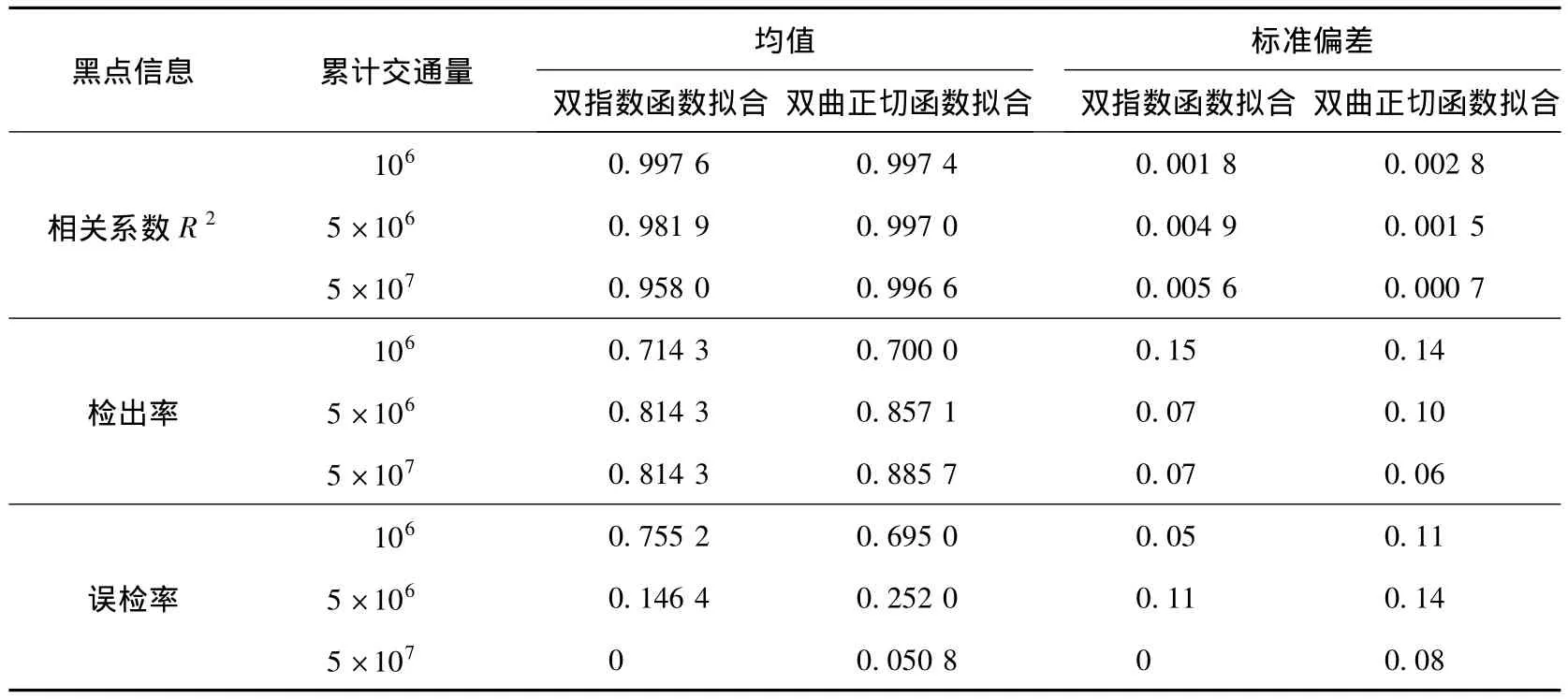
表3 2種擬合函數檢出率和誤檢率對比和分析
4 應用分析
以滬杭高速公路的上行方向嘉興段事故數據為基礎,應用雙曲正切函數對累計頻率曲線進行擬合和事故黑點鑒別分析,為比較不同年限的事故黑點鑒別結果,分別在2004年12月21至2008年6月20的事故數據抽取0.25、1、3.5 a的事故數據進行應用分析,曲線擬合情況如圖4所示.
求出擬合曲線上的最小曲率半徑的位置作為事故黑點鑒別的臨界值,該臨界值對應的黑點的事故臨界次數分別為6次、18次和76次.根據事故黑點的臨界次數,分別鑒定出的事故黑點位置如表4所示.
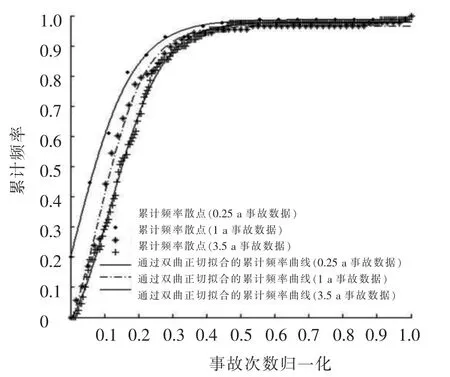
圖4 不同累計交通量作用下累計頻率曲線散點圖與雙曲正切擬合

表4 不同累計交通量作用下事故黑點鑒別結果
可見,不同累計交通量作用年限下的事故黑點鑒別結果有一定差異性,根據前面的分析可以推斷0.25 a事故黑點鑒別結果可靠性最低,3.5 a的事故黑點鑒別結果可靠性最高,1 a的事故黑點鑒別結果非常接近3.5 a的,具有較高的可靠性,其誤檢率低于20%,在一定程度上驗證了前面的結論.從事故鑒別的結果看,各事故黑點的特征如下:K75+000為大云主線收費站出口;K76+000為大云收費站主線入口;K99+000為滬杭高速與乍嘉蘇高速的互通立交;K109+000段為嘉興服務區;K117+000為桐鄉屠甸出口;K135+000為長安服務區,K138+000為長安出口.
其中K99+000處的事故次數達到了216次,其次是K109+000處,事故次數達到194次,顯著高于其他路段.可見,對于平原區高速公路,事故黑點位置主要發生在互通立交(特別是樞紐型互通)出入口,服務區出入口和主線收費站出入口等位置.
該方法同樣可用于一般等級公路或者其他地區高速公路,對改造前為山區二級公路的104國道上虞段K1545—K1569(1995年1月—1997年12月數據),原太高速公路K0—K95(2001年2月—2003年9月數據),漢宜高速公路荊州段K128—K226(1995年—1999年數據),太舊高速公路壽陽—舊關段K446—K508(2001年1月—2003年9月數據)進行黑點鑒別分析,雙曲正切函數曲線擬合情況如圖5所示,黑點鑒別結果如表5所示.
從表5可知,無論何種情況下,雙曲正切擬合相關系數R2都很高,對于不同的累計交通量具有很好的適應性.另外統計年限內漢宜高速荊州段上、下行方向的全路段每公里事故數都超過4次的最低要求,擬合曲線表現出一定的S形,事故黑點鑒別的誤檢率控制在20%左右.104國道上虞段的全路段每公里事故數接近4次,擬合曲線表現出向S形轉變的趨勢,事故黑點鑒別的誤檢率具有一定的保證.而原太高速上、下行方向,太舊高速壽陽—舊關段上、下行方向的全路段平均每公里事故次數都明顯小于4次的最低要求,所以為獲得較低的誤檢率,必須要有更長統計年限的事故數據為基礎.

圖5 累計頻率曲線散點圖與雙曲正切擬合

表5 黑點鑒別結果
5 結論
1)雙曲正切函數和雙指數函數在累計頻率曲線擬合的相關性方面前者要優于后者,并且對于不同的累計交通量具有很好的適應性.同時,在黑點的檢出率方面前者也具備一定的優勢,因此雙曲正切函數可替代雙指數函數進行事故黑點鑒別.
2)一定事故率下統計年限對事故黑點的誤檢率有非常重要的影響,當統計年限較低時,事故黑點的誤檢率非常高,甚至超過50%.為將誤檢率控制在20%左右,建議待鑒別道路的平均每公里事故次數不小于4次.
[1]ROBERT R V,VEERARAGAVAN A.Hazard rating scores for prioritization of accident prone sections on highways[J].Transportation Research Record:Journal of the Transportation Research Board,2004,1878:143-151.
[2]TARKO A P,KANODIA M.Effective and fair identification of hazardous locations[J].Transportation Research Record:Journal of the Transportation Research Board,2004,1897:64-70.
[3]ELVIK R.New approach to accident analysis for hazardous road locations[J].Transportation Research Record:Journal of the Transportation Research Board,2003,1953:50-55.
[4]肖慎,過秀成,宋俊敏.公路交通事故黑點診斷技術研究[J].公路交通科技,2003,20(4):95 -97.
[5]裴玉龍,丁建梅.鑒別道路交通事故多發點的突出因素法[J].中國公路學報,2005,18(3):99 -103.
[6]孟祥海,盛洪飛,陳天恩.事故多發點鑒別本質及基于BP神經網絡的鑒別方法研究[J].公路交通科技,2008(03):124-129.
[7]楊軫,方守恩,高國武.事故多發路段的研究[J].上海公路,2000(04):5-8.
[8]方守恩,郭忠印,楊軫.公路交通事故多發位置鑒別新方法[J].交通運輸工程學報,2001,1(1):90 -94.
