多響應線性模型的Bayes E-最優設計
2011-09-05 02:48:02岳榮先
統計與決策 2011年15期
王 帥,岳榮先,付 清
(上海師范大學 數理學院,上海 200234)
0 引言
對于單響應線性模型的Bayes E-最優設計的等價定理,Pilz已經給出了詳細的討論,但對于最優設計的算法,文章并沒有給出。本文擬在單響應模型的基礎上,將其理論推廣到Bayes多響應線性模型中,并建立Bayes E-最優設計的等價定理和相應的迭代算法,這將更有利于應用到實際當中。
考慮有r個響應的線性模型,它可以表示為如下形式:
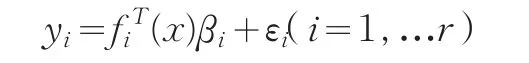
χ為設計區域,fi(x)是pi維的列向量,βi是pi×1維的未知參數向量,εi是與第i個響應yi有關的隨機誤差,且當i≠j時,εi與εj相關。我們假定隨機誤差滿足下列關系:

記Xi=(fi(x1),fi(x2),…,fi(xn))T為n×pi階 矩 陣 ,X=diag(X1,X2,…,Xr)為nr×p階矩陣。則模型可以表示為Y=Xβ+ε。
1 Bayes估計與設計準則
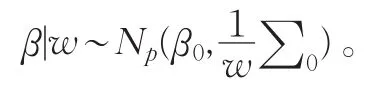
若vn=(x1,x2,…,xn)表示n個點的試驗設計,且每個點的實驗測度都相同為1n,則在精確設計和后驗密度下,我們定義信息陣為:
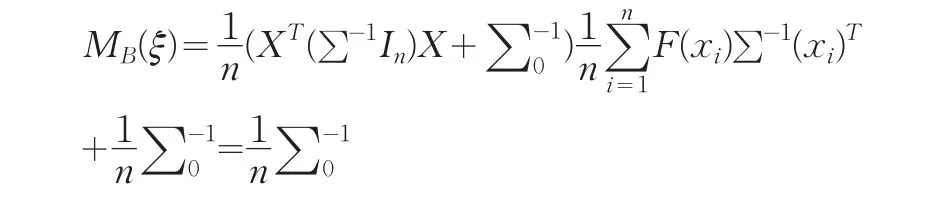
記Ξ為定義在設計區域χ上的概率測度的全體,ξ∈Ξ為連續設計,則其對應的信息陣為:

2 Bayes最優設計的等價定理
對任意ξ∈Ξ ,令λξ=λmin(MB(ξ)),即λξ為對應的Bayes信息陣的最小特征值,假定它為簡單特征值,且它對應的特征向量為Vξ。

定理1對于Bayes情況下的E最優準則,我們簡記為EB最優準則,它對應的Frechet導數記為FEB,則:
(1)FEB是線性的;
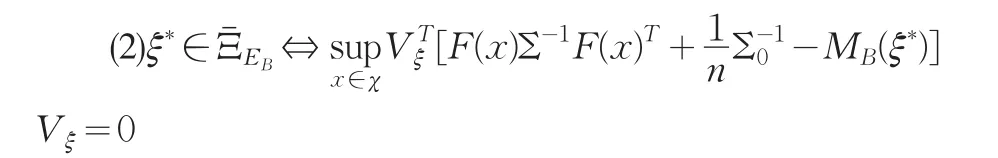
證 明 :(1) 因 為λmax(MB(ξ)-1)=1/λξ,所 以 ,使EB(·):=λmax(MB(·)-1) 達 到 最 小 就 等 價 于 使B(·):=-λmin(MB(·))達到最小。求解的Frechet導數如下:

得證。
(2)因為Bayes信息陣是正定的,所以它的特征值全為正,所以將(i)兩邊同除以EB(ξ),不等號的方向不變,即有:
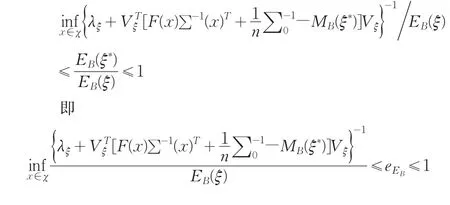
3 Bayes E-最優設計的迭代算法
假設任意選取n0個點,(x1,x2,…,xn0)∈χ作為初始設計點,則


(2)計算設計ξn0的效率的下界:

(3)預先給定常數e0,判斷,若en0<e0則進行第二步;若en0>e0則初始設計的效率已滿足要求,但這種情況通常不會發生。
第二步:對n≥n0,令n=n+1。
(1)尋找第n+1個點,使它滿足:
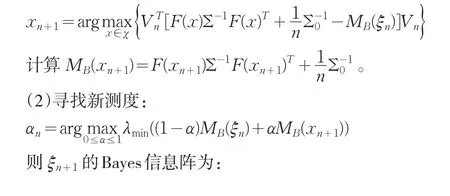
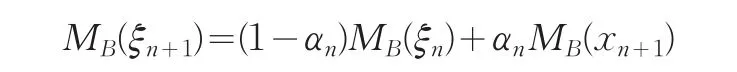
第三步:(1)令λn+1=λmin(MB(ξn+1)),即為第n+1 步Bayes信息陣的最小特征值,而Vn+1為λn+1對應的標準特征向量;
(2)計算
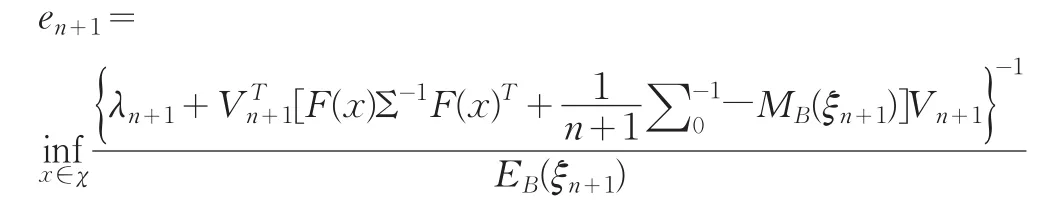
若en+1<e0則繼續進行第二步,否則停止迭代。
例:考慮兩個響應的可控變量模型,假設實驗區域為χ={x=(x1,x2): ||xi≤1,i=1,2},給定e0=0.9,建立模型:

β服從先驗分布N(β0,Σ0),這里β的先驗協方差矩陣為Σ0=diag(Σ01,Σ02),其中
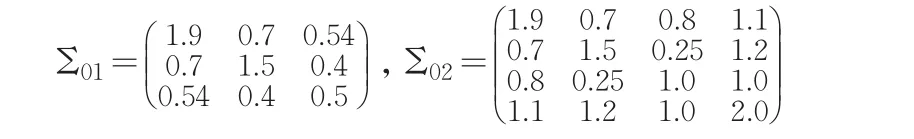

應用上述算法迭代之后,得到的設計點和它們對應的測度為:

這個例子得到的設計點均在設計區域的端點處取得,符合最優設計的理論。同時也證明了以上算法的可行性,通過不斷的增加設計點,使得EB最優設計效率的下界0.5012增加到0.9749,并且效率的增加也比較穩定。在更加復雜的實際運用中,迭代算法同樣也有其適應性。
[1]Pilz J.Bayesian Estimation and Experimental Design in Linear Regression Models[M].Feiberg:Tenbuer Leipzig,1983.
[2]汪倩菁,岳榮先.多響應線性回歸模型Bayes最優設計的等價性定理[J].上海師范大學學報(自然科學版),2008,37(3).
[3]Zellner A.An Efficient Methodof Estimating SeeminglyUnrelated Regressions and Tests for Aggregation Bias[J].J.Amer.Statist.Assoc,1962,(57).
[4]張丹,岳榮先.多響應線性模型最優設計的迭代算法[D].上海:上海師范大學,2008.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代裝飾(2020年7期)2020-07-27 01:27:42
數學物理學報(2020年2期)2020-06-02 11:29:24
流行色(2020年1期)2020-04-28 11:16:38
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
