基于ML-pLSA模型的目標識別算法
2011-09-19 11:29:36盧湖川
電子與信息學報 2011年12期
陳 琳 盧湖川
(大連理工大學信息與通信工程學院 大連 116024)
1 引言
在圖像分類和圖像檢索技術應用越來越廣泛的今天,圖像目標識別技術成為了最熱門的研究方向之一。圖像大小、目標尺度、場景內容及光照、角度等因素的不確定性,對目標識別算法構成了很大的挑戰。現有的目標識別方法盡管取得了一定的成功,但是也存在一定的問題:(1)由于目標尺度和形狀的不確定性,基于滑動窗的方法會引入大量的背景噪聲,且計算量太大。(2)在一系列先分割再識別的方法框架下,當分割結果很不理想時,后續的工作(無論邊界/形狀匹配)都是很難進行的。
針對以上問題,Russell等人[1]將多次改變計算參數的多分割方法用在了圖像識別中,其優點是多尺度分割可以避免目標尺度、圖像大小的變化問題;區域可以包含更豐富的特征信息。但是該方法的假設往往不成立,因為即使分割的次數再多,也有無法得到正確目標的情況發生。文獻[2]提出了分割-識別-再分割的一個識別過程,該算法避免了因為某一步分割結果的錯誤而導致整個識別結果失敗的現象。但是該方法對格外突出的物體部分比較敏感(比如天鵝的脖子,蘋果商標的葉子等),當突出部分形變較大時匹配困難且此方法對一般物體推廣性還不夠強。通過以上分析,要做好目標識別必須解決以下幾個問題:(1)盡量避免圖像大小、目標尺度變化對識別的影響;(2)在盡量多的特征空間上描述目標;(3)能夠穩定地對圖像庫的類別結構進行建模;(4)識別過程與分割過程既要相互依賴又要相對獨立。
鑒于此,本文提出一種基于多尺度的概率潛在語義分析(ML-pLSA)模型的目標識別算法。該算法選取多種分割方法對圖像進行多尺度分割,然后利用詞袋方法(BOW)結合pLSA模型及分類器對每一個分割區域進行類別估計,最終將多個尺度、多個方法的區域估計結果結合到一起,根據這一綜合結果提取出目標,達到目標識別的目的。本文方法不需要假設分割出的區域至少有一個是正確的,也允許分類器有判斷的錯誤。我們的每一步都是弱分類、弱學習,但是數據的疊加和相互依賴可以不斷增強目標的位置信息和類別信息。
2 概率潛在語義分析(pLSA)
概率潛在語義分析(pLSA)模型[3]原本是用于文本檢索的概率生成模型。相比標準潛在語義分析(LSA),pLSA模型來自線性代數和執行奇異值分解共生表,是基于一個(從潛在的類模型的)混合體的分解,具有更牢固的數學基礎。如圖1所示。

圖1 pLSA圖形化模型
圖1(a)中,節點被包含在的某個框中,表示該節點被迭代左上角的符號所標識的次數。實心圓表示觀測到的隨機變量;空心圓表示未觀測到的隨機變量。pLSA的目的是找到特定主題中字的分布P(w|z),以及使特定文件中字的分布P(w|d)組合起來的相應的特定文件的混合比例P(z|d),如圖1(b)。pLSA模型已在檢索和信息過濾、自然語言處理、機器學習的文本和相關領域廣泛應用[4,5]。
3 基于ML-pLSA模型的目標識別算法
基于 ML-pLSA模型的目標識別算法示意圖如圖2所示。其中,圖2(a)表示在不同的特征空間原圖像突出不同的特征。圖2(b)用多種分割方法對圖像進行分割,可以盡量多地利用不同特征空間信息。圖2(c)利用pLSA模型和分類器得到每個區域的置信值。圖2(d)表示多種分割方法的置信圖的合并圖。圖2(e)根據合并圖提取的目標。從方法示意圖可以看出,圖2(b)-(c)在簡單分割的基礎上進行識別判斷。圖2(d)-(e)在一定識別的基礎上進行提取、分割。整個識別過程中分割與識別相互依賴,位置與類別的信息在不斷的增強。
3.1 特征提取
為了建立圖像局部區域的描述,使其對視角、光照等的變化具有一定的魯棒性,本文選擇快速SIFT(quick Scale Invariant Feature Transform,SIFT)描述符[6],結合BOW進行直方圖視覺詞描述。本文以局部區域為樣本,對區域內的像素點密集提取 SIFT特征,然后形成區域特征直方圖,這樣可以更完整地描述局部特征。
3.2 多種分割算法的選擇及改進

圖2 ML-pLSA方法示意圖
本文給每個輸入圖像產生足夠的分割,為了能夠產生盡量多樣的好的區域(所謂的好區域就是指盡量多的包含目標)。但是有的圖像偏重于顏色特征,而有些圖像則更偏重的是紋理特征,若只用一種分割方法對圖像庫進行分割的話,得到的分割效果參差不齊。所以本文決定選擇多種分割方法對圖像庫的每張圖像進行分割,利用每種方法依賴的特征(cues)不同來彌補這方面的不足;還選擇在不同尺度上進行分割,這樣會防止由于目標大小不同而對分割產生的影響。這樣一來,得到的分割區域大小形狀各有不同、依據的特征各有不同,可以很好地克服因為不同圖像庫目標尺度變化大、圖像特征復雜而帶來的問題。
文獻[7]中給出了目前較流行的分割方法的比較。綜合數據,本文選擇歸一化分割(Normalized cuts,Ncut)[8]、快速漂移算法(Quick shift)[9]、簡單線性迭代聚類算法(SLIC)[7]3種分割方法。Ncut方法是基于全局最優的分割算法,已被成功用于人體模型估計等領域[10,11]。它對一次性分割出整個目標的可能性是最大的,所以選擇Ncut方法進行大尺度分割;SLIC算法是3種方法中速度最快的,而且由于他產生的超像素大小、形狀基本相同,不會過分注意一些沒意義的拐角/線,所以選擇SLIC方法進行小尺度分割;至于中間尺度的分割則由快速漂移算法來完成,這樣既可以發揮它的特點(把不規則的、有意義的區域分割出來),又不會產生過小的超像素。快速漂移算法已廣泛應用于圖像識別和視頻識別[12,13]。根據他們的特點,本文設定超像素的個數分別為K_ncut=[5,9,13,17,21,25],K_quick=[43,41,39,37,35,33](分割塊數大概是 30-60),K_slic=[70,80,90,100,110,120],使分割塊數基本覆蓋了每張圖片5-120塊左右。
在快速漂移算法中,本文將用于聚類的濾波器組[14]用于提取局部紋理特征。濾波器組由3個高斯濾波器(方差σ分別為1,2,4),4個拉普拉斯高斯濾波器(方差σ分別為 1,2,4,8),以及 4個高斯一階導數濾波器。首先,對輸入圖像進行顏色空間轉換;將輸入圖像由RGB顏色空間轉換到CIE-LAB顏色空間;(1)用上述3個不同尺度的高斯核對L,A,B 3個顏色通道分別進行卷積產生9組濾波響應;(2)用4個不同尺度的拉普拉斯高斯濾波器僅僅對L通道進行卷積產生4組濾波響應;(3)4個高斯一階導數濾波器對L通道進行濾波產生4組濾波響應;所以最終每幅圖像的每一個像素會得到一個 17維的特征向量。濾波器的形狀如圖3所示。

圖3 17維濾波器組形狀示意圖
3.3 ML-pLSA模型
pLSA模型原本是用于文本檢索的概率生成模型。通過利用視覺詞(量化的顏色特征,紋理特征以及SIFT特征等區域描述子),pLSA模型可以被應用于圖像領域。本文嘗試利用pLSA模型對分層分割區域進行分析并發現其中的“主題”,把對象類別作為發現的“主題”(如草,屋),把圖像包含多個對象實例建模為主題的混合物。對于每張圖片可能存在多目標類的這種情況,pLSA提供了正確用于聚類的統計模型。
下面,運用圖像處理的語言對 ML-pLSA模型進行一下描述。ML-pLSA模型中的原始術語“文件-d”對應區域樣本,“字-w”對應區域樣本特征,“主題-z”對應目標類別,它是一個潛在的中間變量。
假設有一組M個訓練樣本{d1,…,dM},每個樣本對應一個局部區域,這些區域被量化為包含W個視覺單詞的詞匯表{w1,…,wW},因此訓練圖像的集合就可以由一個單詞圖像的互共現矩陣Nij=n(wi,dj)來表示,其中n(wi,dj)表示的是文件dj中字wi出現的次數。假設共有K個潛在主題變量{z1,…,zK},那么每個文件dj中的每個字wi的出現都有一個潛在的主題變量zk與之相關聯。
我們假設聯合概率P(wi,dj,zk)擁有圖1(a)所示的圖模型的形式。對主題zk進行邊緣求和確定出條件概率P(wi|dj):

其中P(zk|dj)為主題zk在文件dj中出現的概率;P(wi|zk)為字wi在特定主題zk中出現的概率。
式(1)將每個文件表示為K個主題向量的凸合并。這相當于進行一次圖1(b)所示的矩陣分解,其中要求對向量和混合系數進行歸一化從而使他們依概率分布。本質上說,每個文件d都是不同主題z的混合體,某個特定文件d的直方圖是由每個主題z所對應的直方圖相混合而組成的。
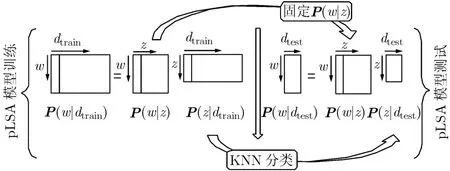
圖4 ML-pLSA算法模型
在具體實現過程中,如圖4,本文首先對P(w|dtrain)進行奇異值分解,得到降維后矩陣P(z|dtrain)和概率P(w|z)。然后采用迭代操作,固定概率P(w|z),計算測試圖像的潛在主題表示P(z|dtest)。最后對P(z|dtest)與P(z|dtrain)進行相似性的度量。
4 實驗結果
本文在常用的 GRAZ-02數據庫進行了一系列的實驗。GRAZ-02數據庫包含 3個類別:車類共300張圖片;人類共 311張圖片;自行車類共 365張圖片。每張圖片大小480×640。示例圖片如圖5所示。可見,GRAZ-02圖像庫中包括大目標、小目標、目標遮擋、多目標、光照變化、角度旋轉(分別對應圖5中第1列至第6列)等一系列圖片,對目標識別具有很大的挑戰。

圖5 GRAZ-02數據庫實例圖
我們選擇圖像庫每類單數的150張圖像來生成字典,同時總共取出100張圖像作為驗證集合。在驗證集合上我們得到的最優字典大小是 70萬至80萬左右。本文每張圖片提取 5000個樣本點(正負各半)的SIFT特征,然后對矩陣進行k-means聚類,K=400。
選擇每類圖像的單數150張圖片進行訓練,雙數的所有圖片進行測試。對于訓練圖像,先以一種分割的一種參數(以分割塊數Ncut_p=5為例)對圖片進行分割,然后在每一個區域中提取SIFT特征,將每一個區域的 SIFT特征直方圖投影到字典上,得到K×5維的區域特征直方圖。通過計算每個區域中正/負像素點的個數給出每個區域的標簽。每張圖片選出正/負區域個數相等的共n個區域,那么Ncut_ p=5時的訓練樣本矩陣P(w|dtrain)維數就是K×N,其中N是訓練圖片提取的區域總個數。對于一張測試樣本,我們使用同樣的方法得到K×5維的區域特征直方圖P(w|dtest)。我們利用ML-pLSA模型(如圖4)對訓練樣本矩陣P(w|dtrain)進行分解,得到K×Z維矩陣(w|z)和Z×N維矩陣(z|dtrain)。其中變量Z表示潛在主題個數。然后采用迭代操作,固定(w|z)矩陣,計算出測試圖片的Z×5維矩陣P(z|dtest)。最后利用近鄰方法對(z|dtest)與P(z|dtrain)進行相似性的度量。
接下來,本文將不同參數下得到的帶有標簽的圖片以每個像素為單位進行疊加,這樣就得到了一張圖片的帶有位置信息、類別信息的權值圖。最后通過閾值法將置信值高的部分提取出來。
在本文中使用了3種評價方法,一是像素準確率,即所有判斷正確的像素點個數除以圖片像素總個數。二是平均像素準確率,即目標被正確分類的像素個數除以真值像素個數與目標被錯誤分類的像素個數之和(即,其中R表示識別結果區域,G表示真值區域)。三是像素查準查全率曲線(簡稱 pr曲線),其中精確率(Precision)p=/G,回歸率(Recall)r=/R。本文將最終得到的權值圖量化到0-255上,然后分為30層對整個圖像庫識別結果進行度量。當為l層時,所有大于256/l的灰度值都被當做是前景,其余的為背景,此時p=r的值即為l層時pr曲線取值。
本文分別做了3組實驗:
實驗 1以自行車類為例,先分別用每一種分割方法對測試圖片進行實驗。然后又使用ML-pLSA方法對150張測試圖片進行實驗。4組數據的平均像素準確率比較見圖6,pr曲線結果比較見圖7。
從圖6,圖7實驗數據可以看出,ML-pSLA算法在測試時的平均像素準確率和pr曲線都要好于用單一方法的實驗結果。進一步說明多種分割方法的使用是合理的、有效的,不論單張圖片的識別率還是整個圖像庫的整體表現都要好于使用單一分割方法。

圖6 ML-pLSA與X-pLSA平均像素準確率比較曲線圖

圖7 ML-pLSA與X-pLSA pr曲線比較結果

表1 ML-pLSA與X-pLSA識別率比較(%)
表1列出了實驗1的相關識別率,ML-pSLA算法的平均像素準確率和pr曲線分別比X-pLSA算法(X代表單獨一種分割方法)高出17.25%,5.04%。
實驗2ML-pLSA算法在GRAZ-02數據庫的結果。圖8給出了部分測試圖片中間結果圖。其中第1列為原圖,第2列為真值圖像,第3至5列分別為Ncut,Quick shift,SLIC分割方法對應的權值圖,第6列為本文方法得到的最終結果圖。其中原圖包含了大目標、小目標、多個目標、角度旋轉及光照變化的圖片,對算法具有一定的挑戰。但從結果圖可見,ML-pLSA算法的效果還是很理想的。

圖8 ML-pLSA算法在GRAZ-02數據庫的部分過程示意圖
ML-pLSA算法在GRAZ-02數據庫3類目標識別率見表2。從表中可見,ML-pLSA算法在自行車類中識別效果是最好的。
圖9為利用ML-pLSA算法得到的目標識別結果。
實驗3ML-pLSA算法與其他算法的比較這里將ML-pLSA算法分別與Marszalek[15]得出的結果和 ECCV2008 Fulkerson[16]得出的結果進行了比較。這兩篇文章評價標準與本文平均像素準確率標準相同,數據庫也是GRAZ-02數據庫(見表3)。
結果表明,ML-pLSA算法在車類和人類的識別結果都要遠遠高于其他目標識別方法;ML-pLSA算法在自行車類的識別率也接近其他算法的最優值。

圖9 ML-pLSA方法結果圖
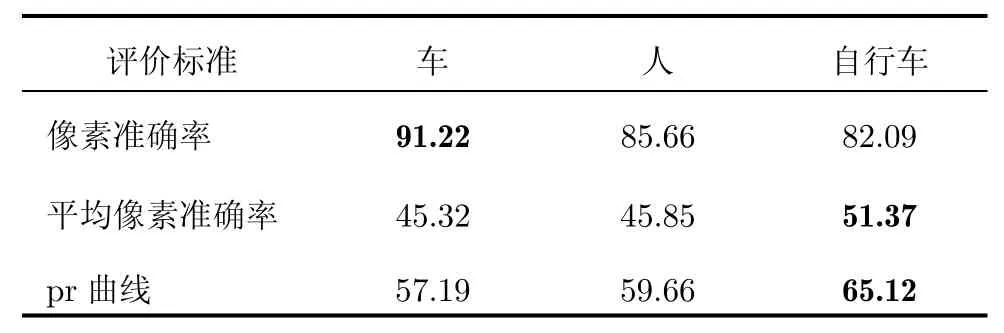
表2 本方法在圖像庫中的識別率(%)

表3 ML-pLSA算法與其他算法的比較(%)
5 結束語
本文提出的 ML-pLSA模型的目標識別算法是一種魯棒性很強的算法。首先,相對其他識別算法來說本方法識別率高,因為它將不同尺度的、豐富的特征空間結合在一起,更充分地利用了圖像的特征信息;第二,本方法不局限于先分割再識別的順序,而是使整個過程的分割與識別即相互依賴又相互獨立,避免了分割誤差對識別過程的影響。第三,由于使用了多種分割和 SIFT特征,所以對目標尺度的變化和光照角度變化也有很好的魯棒性。本文在 GRAZ-02數據庫做了大量實驗,取得了不錯的效果。
在本方法中,如何提高算法速度、如何更好的融合多特征是本文作者以后要研究的內容。
[1]Russell B C,Freeman W T,Alexei A,et al..Using multiple segmentations to discover objects and their extent in image collections[C].IEEE Conference on Computer Vision and Pattern Recognition,NY,USA,June 17-22,2006:1605-1614.
[2]Gu Chun hui,Lim J J,Arbelaez P,et al..Recognition using regions[C].IEEE Conference on Computer Vision and Pattern Recognition,Florida,USA,June 20-25,2009:1030-1037.
[3]Hofmann T,et al..Probabilistic latent semantic analysis[C].Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence,Stockholm,Sweden,July 30-August 1,1999:289-296.
[4]Hofmann T,et al..Unsupervised learning by probabilistic latent semantic analysis[J].Machine Learning,2001,42 (1/2):177-196.
[5]Bosch A,Zisserman A,Munoz X,et al..Scene classification via pLSA[C].European Conference on Computer Vision,Graz,Austria,May 7-13,2006:517-530.
[6]Csurka G,Dance C,Fan L,et al..Visual categorization with bags of keypoints[C].European Conference on Computer Vision,Prague,Czech Republic,March 27,2004,(1):1-22.
[7]Achanta R,Shaji A,Smith K,et al..SLIC superpixels[R].EPFL Technical Report,June 2010.
[8]Shi Jianbo,Malik J,et al..Normalized cuts and image segmentation[J].IEEE Transaction on Pattern Analysis and Machine Intelligence,2000,22(8):888-905.
[9]Vedaldi A,Soatto S,et al..Quick shift and kernel methods for mode seeking[C].European Conference on Computer Vision,Marseille,France,October 12-18,2008:705-718.
[10]Levinshtein A,Sminchisescu C,Dickinson S J,et al..Optimal contour closure by superpixel grouping[C].European Conference on Computer Vision,Heraklion,Crete,Greece,September 5-11,2010:480-493.
[11]Sapp B,Jordan C,Taskar B,et al..Adaptive pose priors for pictorial structures[C].IEEE Conference on Computer Vision and Pattern Recognition,San Francisco,CA,USA,June 13-18,2010:422-429.
[12]Fulkerson B,Vedaldi A,Soatto S,et al..Class segmentation and object localization with superpixel neighborhoods[C].International Conference on Computer Vision,Kyoto,Japan,September 27-October 4,2009:670-677.
[13]Ravichandran A,Favaro P,Vidal R,et al..A Unified approach to segmentation and categorization of dynamic textures[C].Asian Conference on Computer Vision,Queenstown,New Zealand,November 8-12,2010:425-438.
[14]Winn J M,Criminisi A,Minka T P,et al..Object categorization by learned universal visual dictionary[C].International Conference on Computer Vision,Beijing,China,October 17-20,2005:1800-1807.
[15]Marszalek M,Schmid C,et al..Accurate object localization with shape masks[C].IEEE Conference on Computer Vision and Pattern Recognition,Minneapolis,Minnesota,USA,June 18-23,2007:1-8.
[16]Fulkerson B,Vedaldi A,Soatto S,et al..Localizing objects with smart dictionaries[C].European Conference on Computer Vision,Marseille,France,October 12-18,2008:179-192.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
河南科技(2014年23期)2014-02-27 14:19:15
