分布式P2P網(wǎng)絡中基于方向搜索算法研究
2011-09-27 01:41:02劉金嶺
電子設計工程 2011年24期
劉 衛(wèi),劉金嶺
(1.昆明理工大學 計算機中心,云南 昆明 650024;2.淮陰工學院 計算機工程學院,江蘇 淮安 223003)
分布式P2P網(wǎng)絡中基于方向搜索算法研究
劉 衛(wèi)1,劉金嶺2
(1.昆明理工大學 計算機中心,云南 昆明 650024;2.淮陰工學院 計算機工程學院,江蘇 淮安 223003)
針對Flooding算法及其改進算法的理念提出了P2P網(wǎng)絡中基于方向的搜索算法,該算法動態(tài)生成一棵以搜索源點為根的搜索樹,在每一次的搜索過程中,每個節(jié)點都能沿著搜索方向進行,這樣可以避免節(jié)點被重復地搜索。有效地避免了搜索過程中冗余搜索報文的產(chǎn)生,節(jié)省了網(wǎng)絡帶寬,提高了效率和網(wǎng)絡性能。通過二維空間的數(shù)字數(shù)據(jù)和圖像數(shù)據(jù)這兩種實驗結果的分析并進行了仿真實驗,該算法充分體現(xiàn)了在搜索過程中的有效性及可操作性。
分布式;P2P網(wǎng)絡;拓撲結構;方向搜索
目前人們已經(jīng)意識到P2P技術[1]在網(wǎng)絡信息交流、文件交換、分布計算等方面大有前途。在P2P網(wǎng)絡上,閑散資源有機會得到利用,所有節(jié)點的資源總和構成了整個網(wǎng)絡的資源,整個網(wǎng)絡可以被用作具有海量存儲能力和巨大計算處理能力的超級計算機。P2P技術的另一個優(yōu)勢是開發(fā)出強大的搜索工具,使用戶深度搜索成為可能,為互聯(lián)網(wǎng)的信息搜索提供了全新的解決方法。運用P2P技術進行深度搜索,無需通過WEB服務器,可以不受信息格式和計算機設備的種種限制,達到傳統(tǒng)目錄式搜索引擎無可比擬的深度,理論上將包括網(wǎng)絡上所有開放的信息資源。采用P2P技術,搜索范圍將在幾秒鐘內以幾何級數(shù)增長,幾分鐘內就可搜遍幾百萬臺PC上的資源。文獻[2]中給出了分布式結構化網(wǎng)絡中的Chord搜索算法,其優(yōu)點是算法簡單,性能較好,缺點是隨著節(jié)點規(guī)模的不斷增大,節(jié)點的性能差異會影響系統(tǒng)效率。Flooding算法[3]是分布式P2P網(wǎng)絡中的一個基本搜索算法。Flooding搜索算法的優(yōu)點是路由算法簡單且易于實現(xiàn);缺點是每一次路由都要進行全網(wǎng)遍歷,從而加重網(wǎng)絡負擔,降低搜索效率,限制網(wǎng)絡擴展,使得路由算法容易受到攻擊。正是由于目前P2P網(wǎng)絡搜索中存在的一系列缺陷,很多研究人員在該領域中做了大量工作,在Flooding算法基礎上出現(xiàn)了一些改進算法,如文獻[4]中提到的Modified-BFS、PartialMinFlood等。這些改進后的算法在某些特定條件下確實提高了搜索效率,進而提高了網(wǎng)絡的整體性能。然而,這些改進算法中為了實現(xiàn)某些方面的改進而在其他方面付出了昂貴的代價,主要體現(xiàn)在如下幾個方面:1)算法過于復雜,難以實現(xiàn);2)算法限制條件太多,實際網(wǎng)絡中難以滿足要求;3)對算法的改進非常有限。這些算法在目前P2P網(wǎng)絡中均沒有得到應用。文中在現(xiàn)有的研究基礎上,給出了一種基于方向的搜索算法 (記為:Direct_Search),該算法充分利用了網(wǎng)絡中鄰居節(jié)點的信息,從源節(jié)點到網(wǎng)絡拓撲空間的每一個方向做平行搜索。在Direct_Search算法中,搜索樹[5]的生成要求網(wǎng)絡中各節(jié)點知道P2P網(wǎng)絡的拓撲信息,因此該算法的實現(xiàn)需要相應的P2P網(wǎng)絡拓撲結構的支持。
1 Direct_Search算法的P2P網(wǎng)絡拓撲結構構建
分布式結構化 P2P網(wǎng)絡研究的重點在如何有效地查找信息上。大部分結構化P2P網(wǎng)絡都采用分布式散列表DHT[6]的資源定位方式。
為了將分布式 P2P網(wǎng)絡中的資源分布結構化,以利于有效地查找信息,分布式散列表 DHT采取了以下的方法[6]:
1)按照一定的規(guī)則為每個網(wǎng)絡節(jié)點分配一個唯一的節(jié)點標示符(Node ID),按照散列算法為每個節(jié)點的資源對象產(chǎn)生一個唯一的資源對象標識符(Object ID);
2)Node ID與Object ID通過散列函數(shù)將被映射到同一個分布式散列表中;
3)將分布式散列表分割成不連續(xù)的散列塊,每個節(jié)點配置一個散列塊,并且每個節(jié)點要負責維護屬于自己的散列塊;
4)通過分布式散列表來查找節(jié)點所需要的資源,定位到資源所在的節(jié)點位置;通過特定的路由算法在節(jié)點之間建立連接路徑。
Direct_Search算法在執(zhí)行搜索過程中,會動態(tài)的差生一棵搜索樹,搜索樹的產(chǎn)生要求網(wǎng)絡中的每個節(jié)點知道自身在P2P網(wǎng)絡中的拓撲信息。文中算法的實現(xiàn)設計了一個基于笛卡爾坐標的P2P網(wǎng)絡拓撲結構。該結構的拓撲空間S與n維向量空間V十分相似。
筆者對于加入P2P網(wǎng)絡的節(jié)點按一定的算法映射成n拓撲空間S中的一個點。S中的每個點都有自己的坐標(x1,x2,…,xn),任意兩點 N1(x1,x2,…,xn)和 N2(y1,y2,…,yn)的歐式距離d定義為:
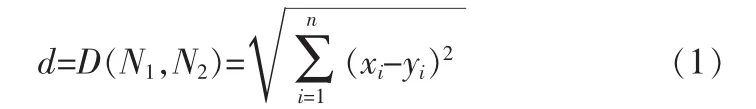
對于加入P2P網(wǎng)絡中的每個節(jié)點分配一個坐標,該坐標唯一對應P2P網(wǎng)絡拓撲空間S中的一個點,節(jié)點與節(jié)點之間的距離定義為與節(jié)點對應的點與點之間的歐式距離d。在區(qū)域分布中充分考慮節(jié)點分布的均勻性,所以被添加到P2P網(wǎng)絡中的節(jié)點將會在n維空間S中通過Hash算法被映射成相應的點。
1.1 基本概念
由于在網(wǎng)絡節(jié)點的加入和退出過程中,需要維護網(wǎng)絡的拓撲結構,為此引出如下超級節(jié)點的定義。
定義1在網(wǎng)絡拓撲結構中確定唯一個節(jié)點Super-Node來存儲了該網(wǎng)絡拓撲結構中所有節(jié)點的坐標、id、ip地址、端口信息等,則稱該節(jié)點Super-Node為該網(wǎng)絡拓撲結構的超級節(jié)點。
由于在搜索過程中,節(jié)點的搜索信息量會不斷地增加,這樣會加重Super-Node的負載量,本文中Super-Node只負責存儲節(jié)點加入和離開的信息。
定義2設N是拓撲空間S中的一個節(jié)點,稱與N相距最遠鄰居節(jié)點間的距離r為N的視覺搜索半徑;與節(jié)點N之間的距離小于視覺搜索半徑的節(jié)點集合所在區(qū)域稱為N的視覺搜索區(qū)域。如果在某個搜索區(qū)域內,沒有鄰居節(jié)點的存在,則定義這個搜索區(qū)域的視覺半徑為0。
n維坐標的拓撲空間 S中節(jié)點N的搜索區(qū)域是一個圓錐體,該圓錐體的頂點即為搜索源節(jié)點,每個進入該搜索區(qū)域的節(jié)點在進行搜索的過程中都要對這個圓錐體搜索區(qū)域負責。二維空間的搜索區(qū)域是個扇形區(qū),該扇形的頂點為搜索源節(jié)點。
1.2 網(wǎng)絡拓撲結構的節(jié)點加入和移出
當節(jié)點Nj申請加入網(wǎng)絡時,首先要訪問超級節(jié)點Super-Node,并將自己的信息告知Super-Node。Super-Node隨即為節(jié)點Nj在網(wǎng)絡空間S中分配位置坐標,同時將節(jié)點Nj的位置信息和鄰居列表信息發(fā)給節(jié)點Nj。Nj加入網(wǎng)絡后,要判斷是否在其鄰居節(jié)點Ni的搜索區(qū)域內,如果節(jié)點Nj在其鄰居節(jié)點Ni的視覺搜索區(qū)域內,節(jié)點Nj的信息將會被加入到進該視覺搜索區(qū)域的鄰居列表中。如果鄰居列表中的節(jié)點個數(shù)大于m個(其中m為鄰居列表存儲搜索信息的最大節(jié)點數(shù)),那么該視覺搜索區(qū)域內遠離節(jié)點Nj的節(jié)點信息將會被超級節(jié)點刪除,隨即超級節(jié)點將通知相應的節(jié)點修改其自身的鄰居節(jié)點信息。
當節(jié)點要申請移出網(wǎng)絡時,該節(jié)點首先要告知Super-Node。Super-Node隨即移去節(jié)點的信息,這時移去節(jié)點在視覺搜索區(qū)域內的鄰居節(jié)點所保存的信息將會有所變動。因為一個節(jié)點的移去,網(wǎng)絡需要進行調整,意味著在視覺搜索區(qū)域內的其他節(jié)點會被加入,來保證二叉樹的網(wǎng)絡結構。Super-Node會為被加入的節(jié)點分配新的位置坐標,同時Super-Node存儲的鄰居列表信息也要實時地做出更新來保持網(wǎng)絡拓撲的準確性。
1.3 搜索方向機搜索區(qū)域
基于方向搜索設計的目的是避免節(jié)點被重復搜索。在每一次的搜索過程中,每個節(jié)點都要沿著搜索方向進行。一個節(jié)點沿著其搜索方向進行搜索的區(qū)域我們稱為該節(jié)點負責的搜索區(qū)域。n維拓撲空間S中的節(jié)點N的搜索區(qū)域是一個以搜索源點為頂點的錐體,在搜索過程中,每個參與節(jié)點分別負責一個錐體搜索區(qū)域。下面以二維空間為例,說明搜索方向和搜索區(qū)域的確定。在二維拓撲空間S中,搜索區(qū)域是一個以搜索源點為中心的扇形,搜索沿著遠離搜索源點的方向進行。如圖1所示。

圖1 搜索方向和搜索區(qū)域示意圖Fig.1 Schematic diagram of direction search and searching area
1.4 下一跳基于方向搜索節(jié)點的選擇
當前節(jié)點的下一跳基于方向搜索節(jié)點的計算是比較關鍵的步驟。計算的方法是:從當前節(jié)點的鄰居列表里取出一個鄰居節(jié)點N,根據(jù)該鄰居節(jié)點的坐標和當前節(jié)點的搜索區(qū)域的邊界平面方程,計算出該鄰居節(jié)點是否在當前節(jié)點的搜索區(qū)域中。如果該鄰居節(jié)點N在當前節(jié)點的搜索區(qū)域中,則進一步根據(jù)該鄰居節(jié)點的坐標和當前節(jié)點的搜索方向直線方程判斷該鄰居節(jié)點K是否在當前節(jié)點的搜索方向上。如果在搜索方向上,則該鄰居節(jié)點符合條件,是當前節(jié)點的下一跳搜索節(jié)點。否則,該鄰居節(jié)點不是當前節(jié)點的下一跳搜索節(jié)點。
2 分布式P2P網(wǎng)絡中基于方向的搜索算法Direct_Search
Direct_Search的設計思想是把 P2P網(wǎng)絡中的節(jié)點映射到二維空間坐標的平面上,在這個二維空間坐標上的每個節(jié)點都會被分配一個二維空間坐標,以此來標注其在空間中的位置。在整個算法中只設置一個超級節(jié)點,想要進入 P2P網(wǎng)絡的每一個節(jié)點首先要和超級節(jié)點進行通信,在通信的過程中超級節(jié)點會為該節(jié)點在 P2P網(wǎng)絡的應用層分配一個二維坐標。同時,Direct_Search在P2P網(wǎng)絡中的資源定位也是以節(jié)點被分配的坐標為基礎的。把這個二維空間坐標平面分成4個象限,該算法是以搜索源節(jié)點作為根節(jié)點,以4個象限內的節(jié)點作為葉節(jié)點,并在每個象限內生成一棵二叉樹,搜索過程根據(jù)二叉樹模型進行搜索,這一想法在 Direct_Search能夠有效地避免發(fā)送重復的搜索消息而造成冗余所帶來的網(wǎng)絡高負載。同時網(wǎng)絡中的每個節(jié)點都被設置了若干個鄰居節(jié)點,其只能從它的鄰居節(jié)點獲取搜索消息,并不需要整個網(wǎng)絡中節(jié)點的所有消息,這一想法使得 Direct_Search具有很好的可擴展性和穩(wěn)定性,同時能夠很好地適應 P2P網(wǎng)絡的動態(tài)變化。在整個搜索過程中,搜索的起點是搜索的源節(jié)點。該算法充分地利用網(wǎng)絡中鄰居節(jié)點的信息,從源節(jié)點到網(wǎng)絡拓撲空間的每一個方向做平行搜索。Direct_Search算法流程如圖2所示。

圖2 Direct_Search算法執(zhí)行的流程圖Fig.2 Direct_search algorithm on execution flowchart
Direct_Search算法在二維空間內的搜索算法描述如下:
1)從搜索源節(jié)點出發(fā),搜索開始。搜索源節(jié)點根據(jù)其鄰居節(jié)點的存儲信息和一些搜索參數(shù)計算下一個被搜索的節(jié)點,下一個被搜索的區(qū)域以及下一個被搜索節(jié)點所負責的搜索方向,然后跳轉至步驟2)。
2)如果經(jīng)過步驟1)計算出的下一跳節(jié)點的數(shù)量為0,則跳轉至步驟4);如果經(jīng)過步驟 1)計算的下一跳節(jié)點的數(shù)量不為 0,則搜索消息將被發(fā)送給這些“下一跳節(jié)點”,然后跳轉至步驟3)。
3)接收到搜索消息的節(jié)點進行本地文件搜索,搜索到符合條件的文件,搜索結果將被返回至搜索源節(jié)點,然后跳轉至步驟4);搜索不到符合條件的文件,那么就會執(zhí)行步驟1)中的搜索操作,計算出的結果生成搜索文件,發(fā)送給下一跳節(jié)點。
4)搜索在現(xiàn)有節(jié)點負責的搜索區(qū)域內結束。
5)搜索在各個搜索區(qū)域內都被完成時,整個搜索結束。
3 Direct_Search 算法在二維空間內的模擬實驗及結果分析
本次模擬實驗的主要目的是對Direct_Search算法在搜索執(zhí)行過程中的覆蓋率進行定量分析,從而驗證該算法的正確性和可行性,同時因為在算法執(zhí)行的整個過程中沒有涉及到P2P網(wǎng)絡通信協(xié)議的模擬情況,為了達到簡潔高效更加直觀的驗證該算法,文中是Intel Core i3主頻為2.93 GHz的雙核處理器、內存為4 GB、操作系統(tǒng)為Windows XP Server Pack3、開發(fā)語言C++的機器上進行的,通過編寫程序來模擬算法搜索執(zhí)行過程,獲取實驗數(shù)據(jù)的。
3.1 模擬實驗結果分析
在對Direct_Search算法的五次模擬實驗過程中,不考慮網(wǎng)絡的邊緣節(jié)點,在網(wǎng)絡中設置了10 000個搜索節(jié)點,每個節(jié)點設定存儲了48個鄰居節(jié)點的信息,即取m=48。實驗數(shù)據(jù)如表1所示。搜索覆蓋率S_C用式(2)表示。


表1 Direct_Search算法的五次模擬實驗數(shù)據(jù)Tab.1 Direct_search algorithm of five times simulation experiment data
表1中的實驗數(shù)據(jù)說明了Direct_Search算法的搜索覆蓋率在95%左右。
3.2 Direct_Search算法的搜索過程仿真實驗
圖3顯示了采用Direct_Search算法進行搜索的仿真過程。圖中的星號代表網(wǎng)絡節(jié)點,星號下邊的數(shù)字是該節(jié)點的id。該圖顯示的是從圖的右上方節(jié)點向左下方節(jié)點進行的搜索過程。兩個節(jié)點之間有連線,表示在搜索過程中,其中一個節(jié)點是另一個節(jié)點的下一跳節(jié)點。圖中有些節(jié)點是孤立節(jié)點,既沒有直線把它和別的節(jié)點連起來。這些孤立節(jié)點就是在搜索中被忽略的節(jié)點。在圖3中,許多節(jié)點只有上一跳節(jié)點,沒有下一跳的節(jié)點。這表示在搜索過程中,這些節(jié)點沒有在自己的搜索區(qū)域中找到符合條件的下一跳節(jié)點,搜索在這些節(jié)點處中斷。在搜索過程中,參與搜索的節(jié)點所負責的搜索區(qū)域為扇形。在搜索中斷處,那些比當前節(jié)點距離搜索源點更遠的、在搜索區(qū)域中的節(jié)點,是無法被搜索到的。
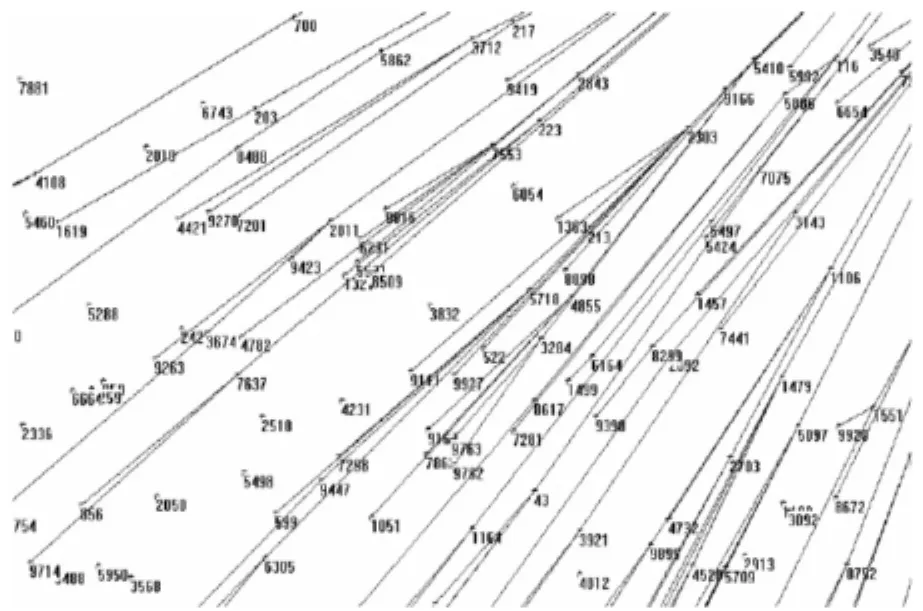
圖3 Direct_Search搜索過程仿真實驗圖Fig.3 Experimental graph of direct_search process in simulation
4 結束語
最近幾年,P2P技術得到了極大的發(fā)展,P2P技術作為一種應用日益廣泛的技術,其功能﹑性能逐漸得到人們的重視。由于P2P運行環(huán)境比較復雜,所以到目前為止,在國際上還沒有一個通用P2P搜索方法。筆者根據(jù)Flooding算法及其改進算法的理念提出了P2P網(wǎng)絡中基于方向的搜索算法—Direct_Search算法,講述了Direct_Search算法的基本思想,設計的詳細過程,并對其進行了模擬實驗以及實驗結果分析。由于P2P網(wǎng)絡的搜索是現(xiàn)今研究的一個熱點,P2P網(wǎng)絡的搜索方面的研究還在探索中,尤其在資源搜索效率和準確定位方面還有很大的改善空間。
[1]劉金嶺.基于P2P網(wǎng)絡的AVL索引樹范圍查詢研究[J].微電子學與計算機,2011,28(2):11-14.
LIU Jin-ling.Study of the AVL-index tree range query based on P2P networks[J].Microelectronics and Computer,2011,28(2):11-14.
[2]劉金嶺.基于Chord覆蓋網(wǎng)絡索引結構的多屬性查詢[J].微電子學與計算機,2011,28(3):104-107.
LIU Jin-ling.An index structure based on chord overlay network of multi-attribute query[J].Microelectronics and Computer,2011,28(3):104-107.
[3]Kim H,Kim Y.Restricted path flooding scheme in distributed P2P overlay networks[C]//ICISS 2008:International Conference on Information Science and Security Proceedings,2008:58-61.
[4]Gkantsid I S C,Miha I LM,Saber I A.Hybrid search schemes for unstructured peer-to-peer networks[C]//Proc of IEEE INFOCOM.Miami:IEEE Press,2005:1526-1537.
[5]吳艾,劉心松,郝堯,等.P2ST:基于帶權搜索樹的P2P搜索模型[J].計算機科學,2007,34(8):64-68.
WU Ai, LIU Xin-song, HAO Yao, et al.P2ST:A weighted search tree based P2P searching model[J].Computer Science,2007,34(8):64-68.
[6]李士寧,夏貽勇,杜艷麗.對等網(wǎng)絡中DHT搜索算法綜述[J].計算機應用研究,2008,25(6):1611-1615.
LI Shi-ning, XIA Yi-yong, DU Yan-li.Survey of DHT search algorithm in peer-to-peer network [J].Application Research of Computers,2008,25(6):1611-1615.
Based on research of direction algorithm research in distributed P2P network
Flooding algorithm and its improved algorithm based on the concept of P2P networks is proposed based on the direction of the search algorithm,which dynamically generate a source point to search for the root of the search tree,the search along the search tree,the search process effectively avoided redundant search packets in the production,save network bandwidth and improve the efficiency and network performance.By two-dimensional digital data and image data analysis of the two experimental results fully reflected the algorithm in the search process for effectiveness and feasibility
distributed; P2P networks; topology; direction search
TP393
A
1674-6236(2011)24-0078-04
2011-10-12 稿件編號:201110048
武漢工程大學青年基金(Q200802)
劉 衛(wèi)(1965—),女,云南昆明人,副教授。研究方向:網(wǎng)絡結構/數(shù)據(jù)挖掘。LIU Wei1,LIU Jin-ling2
(1.Computer Center,Kunming University of Science and Technology,Kunming650024,China;
2.Computer Engineering Faculty,Huaiyin Institute of Technology,Huaian223003,China)
猜你喜歡
計算機應用(2022年2期)2022-03-01 12:33:42
計算機應用(2021年4期)2021-04-20 14:06:36
計算機應用(2021年1期)2021-01-21 03:22:38
中華手工(2017年2期)2017-06-06 23:00:31
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
小天使·一年級語數(shù)英綜合(2015年2期)2015-01-14 06:35:05
中外會展(2014年4期)2014-11-27 07:46:46
民生周刊(2012年10期)2012-10-14 09:06:46
