面向互聯網輿情的熱詞分析技術
2011-10-15 01:36:44李渝勤孫麗華
中文信息學報 2011年1期
關鍵詞:模型
李渝勤,孫麗華
(1.北京信息科技大學,北京100101;2.北京拓爾思信息技術股份有限公司,北京100101)
1 概論
隨著互聯網的普及,中國網民超過3.38億人,已經成為世界第一大網民國家。Web2.0時代,網絡具有傳播快、成本低、聯動性強等特點,使得傳播環境與傳播者都發生了天翻地覆的變化。網絡論壇、博客、SNS等給人們提供了眾多可以盡情表達的渠道,從以前只能看與聽,變成現在的可以評論,甚至還可以有自己的讀者。大多全國性乃至世界性影響事件的傳播,均首先來自于網絡。網絡輿論熱點層出不窮,如上海市戶籍新政、陜西神木縣全民免費醫療、做俯臥撐、躲貓貓、樓脆脆、替誰說話、周久耕事件等等,都是通過網絡進行第一時間傳播。互聯網已經成為政府了解民情的直接渠道,也是新形勢下政府部分的重要輿論陣地。只有及時發現互聯網的熱點信息,快速發現、快速處理有較大影響的重要事件,并進行快速識別和定向跟蹤,才可能更快更全面地掌握輿情動向,從而進行正面引導輿論和宣傳。
互聯網的熱點信息包括熱點事件、熱點專題、熱點詞語(簡稱熱詞)等方面,其中熱詞作為一種詞匯現象,反映了某一特定時空范圍內人們普遍關注的問題和事物,反映一個時期的熱點話題及民生問題。近幾年,網絡的的確確制造了許許多多的網絡熱詞。它們不僅僅吸引了網民的注意,同樣還得到了眾多媒體的關注。這應該是一種值得關注的網絡文化現象。
本文探討如何對互聯網的信息進行實時分析、挖掘,從而獲取近期流行熱詞的相關技術問題。概括地說,熱詞分析技術包括熱詞發現、熱詞關聯技術,熱詞關聯技術又稱為詞群關系技術,下節將詳細闡相關的技術內容。
2 熱詞發現技術
熱詞挖掘是從互聯網不斷更新的信息中尋找一定時期熱度高的那些短語,比如人名、地名、機構名和其他常見短語,很多網絡熱詞是詞典中未收錄的新詞語。按領域可分為政治、經濟、軍事、娛樂、體育、衛生、科技、社會生活等各個領域的熱詞。
2.1 互聯網熱詞呈現特點
互聯網無時不在源源不斷地產生熱詞。新聞留言板、論壇、博客、微博等內容豐富的網絡傳播媒介和渠道已經成為熱詞展示魅力的舞臺。然而,這些熱詞的傳播往往呈現出無序、散亂的狀態,如何在海量信息海洋中準確地找到熱詞的來龍去脈并非易事,這也是自然語言處理和文本挖掘領域學者們不斷研究和探索的方向。本文通過分析互聯網熱詞的呈現特點,綜合詞語本身的詞頻信息和詞語與時間因素的關聯性,研究得出熱詞發現算法模型,及時發現互聯網熱詞。
互聯網熱詞呈現的主要特點之一主要表現為詞語在互聯網上出現的頻度高、分布范圍廣、涉及領域多,即在新聞網站、論壇、博客、微博客等新興網絡載體上都有非常廣泛的傳播,這些詞演變為熱詞的可能性非常大;此外,互聯網熱詞呈現的另一顯著特點是詞語隨時間推移而出現突然的異動,即時間因子對熱詞具有非常明顯的影響。
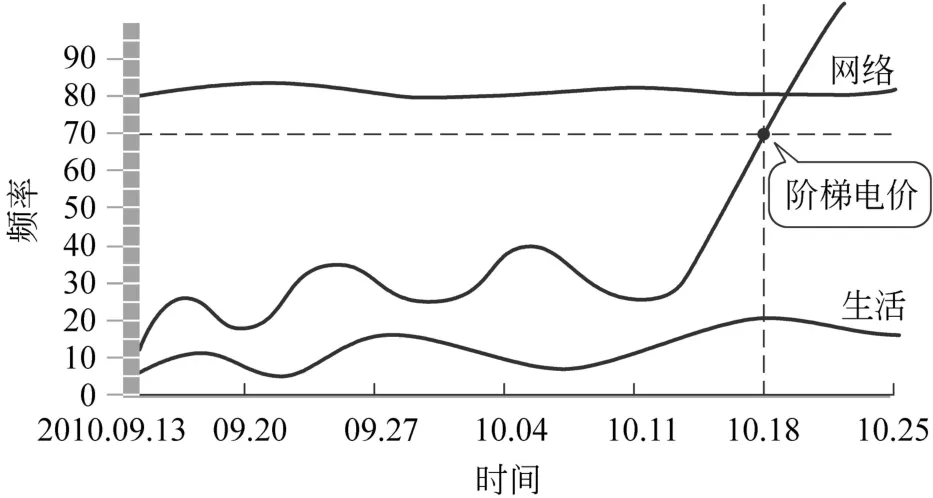
圖1 熱詞的呈現特點示意
從圖1我們可以看出,例如我們常見的詞語“網絡”一詞,雖然該詞的出現頻度較高,但是歷史波動與近期波動比較平穩,因此不屬于熱詞范疇,屬于高頻詞匯。而“階梯電價”一詞在10月份詞頻出現頻率開始升高,到十月中旬該詞的出現頻率呈現迅速增長的態勢,
歷史波動與近期波動表現為突發性的異動增長,則判斷該詞屬于熱詞范圍的詞語;“生活”一詞屬于波動變化較小,頻率出現不是很高的詞匯,屬于一般網絡詞匯。
2.2 候選短語獲取技術
候選短語識別分為命名實體短語和非實體短語識別兩部分。命名實體短語包括人名、地名、機構名的識別。非實體短語指的是除了人名、地名、機構名的其他短語串。實體短語識別采用的是基于隱馬爾科夫模型的命名實體識別技術[1-2]。非實體短語目前采用Nagao算法,進行高頻串的識別及其串頻統計工作,后續準備采用C-valule值等多詞串抽取方法,進行對比試驗[8],以期獲得更好的識別精度。
2.2.1 命名實體識別
隱馬爾可夫模型是一種在自然語言處理領域中被廣泛應用的統計模型。中文命名實體識別中的人名識別、地名識別、譯名識別以及機構名識別等都可以用隱馬爾可夫模型來解決。本文采用了的層疊隱馬爾可夫模型[3-4](Cascaded Hidden Markov Model,簡稱Cascaded HMM)在統一的隱馬爾可夫模型中來識別各類命名實體,并在這些隱馬爾可夫模型中建立起一定的聯系,形成一個一體化的命名實體識別系統。
整個命名實體識別的層疊隱馬爾可夫模型由三級互相聯系的隱馬爾可夫模型構成,自底向上分別為人名識別HMM,地名識別HMM和機構名識別HMM,每一級都是以隱馬爾可夫模型作為基本的算法模型,整個算法的時間復雜度和隱馬爾可夫模型的時間復雜度相同,分析時間隨著輸入串長度的增長而線性增長,速度非常快。各層隱馬爾可夫模型之間以下兩種方式互相關聯,形成一種緊密的耦合關系:
每一層隱馬爾可夫模型都采用N-Best策略,將產生的最好的若干個結果送到詞圖中供高層模型使用;低層的隱馬爾可夫模型通過詞語的生成模型為高層隱馬爾可夫模型的參數估計提供支持。
其中第一層人名識別的輸入為粗切分的分詞序列,每一層隱馬爾可夫模型都采用改進的Viterbi算法(N-Best),輸出最好的若干個結果作為高一級隱馬爾可夫模型的輸入。最高級隱馬模型將在人名識別和地名識別的基礎之上進行機構名識別。
2.2.2 非實體串的識別
采用Nagao算法進行字串頻率統計[5-7],統計出現頻率大于一定值的N到M元的字串;然后以一定策略進行子串歸并,長串歸并掉短串,初步過濾掉候選串中的垃圾;最后綜合三種策略,對候選串進行最后的過濾,得到高頻詞串,對高頻詞串進行實體串的帥選之后得到非實體串。
數據源是通過網絡爬蟲采集的互聯網數據,存儲到文件中,把此文件看成一個很長的字符串讀入內存,并以Unicode編碼。每個字符占2字節空間。如果待處理語料包括m個字符,則需要2m字節的存儲空間。以下用Ci表示C中第i個字符。
接著構造一個長為m的P表(pointer table)。P表的每一項Pi保存一個指向C中子串Si的指針。Pi指向的子串Si定義為從Pi所指字符Ci到C中最后一個字符Cm中的m-i+1個字符所組成的字符串。這樣S1,S2,…,Sm的串長依次遞減,最后一個子串Sm只包括一個字符Cm。P表構建好以后就可以根據P表項所指的子串對P表進行升序排序,在使用快速排序算法的情況下排序時間復雜度為O(nlogn)。
接下來可以在已排序的P表的基礎上構建記錄相鄰子串相同最長左子串長度的L表。L表與P表大小相同,其中的表項Li記錄排序后相鄰子串Spi-1和Spi相同最長左子串長度,即從串首開始相同字符的個數(L1=0)。例如:若Pi指向的子串Spi=“吸收外資最多的國家”,Pi-1指向的子串Spi-1=“吸收外資最多的一年”,則 Li=6。
在構建好P表和L表之后,可使用如下算法對長度為N(1≤N≤255)的統計串進行串頻統計:
算法:長度為N(1≤N≤255)的統計串串頻統計算法。輸入:P表,L表,N。
輸出:所有N元統計串及其頻次。
1. P1指向的N元串賦給X,X的頻次置為1
2. for i=2 to m
3. if Li≥N
4. X的頻次加1
5. else
6. 輸出X及其頻次
7. Pi指向的N元串賦給X,X的頻次置為1
8. 輸出最后的X及其頻次
經過串頻統計之后,可獲得長度不小于m1且不大于m2(m1,m2∈N且m1<m2)的高頻串集合Ω。Ω中仍包含許多“垃圾”不宜都用來作為候選短語串。如漢語字串“斯特洛夫斯”出現10次,“奧斯特洛夫斯基”出現9次,則前者也可能為“垃圾”。我們把從高頻串集合中刪除同頻子串的過程稱為等頻子串歸并,刪除近頻子串的過程稱為近頻子串歸并,統稱為子串歸并。經過子串歸并后的統計串即是我們要獲取的候選串。
采用通用度過濾、IWP過濾、互信度濾以及首尾字過濾等手段進行垃圾串的過濾工作,最后得到候選的子串,在候選子串中進行實體串的過濾即得到非實體串。
2.3 短語熱度排序方法
候選實體短語和非實體短語串很多,需要進行熱度排序,取大于設定閾值的詞語為熱詞。排序是根據詞語的熱度權值高低進行的排序。根據熱詞的定義,熱度權值分成兩個部分:基礎權值和波動權值。基礎權值由在標題出現頻率和文檔頻率組合計算來確定。該頻率不僅僅指出現次數,另外還考慮了該詞的上下文信息,如“記者:張曉霞”中“張曉霞”雖出現于很多文章,但由于它的上下文只有一個,所以頻率為1。
波動權值則考慮了長、中、短期三種時間長度中基礎權值的變化過程,短期頻率與長期頻率比值越高,則波動權值越高。最后賦予波動權值更高的權值,因為我們更看重的是該詞的新穎程度,最終的歷史波動權值越高,則新穎度越高,更符合熱詞的含義。
具體熱度權值計算公式如下:
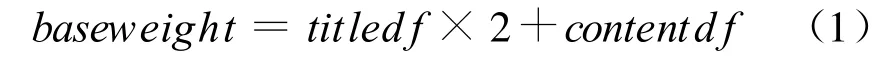
式(1)為詞語的原始基本權值計算公式,baseweight值為原始基本權值,titledf短語在標題出現的頻率,contentd f為短語在正文出現的文檔頻率。計算原始基本權值以天為單位,公式中標題中詞語的詞頻數乘2,強調詞語在標題出現的重要程度要高于正文出現。
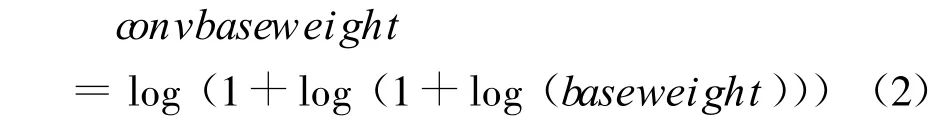
式(2)是對原始基礎權值做的數值平滑處理,目的是平衡低頻、高頻短語的。baseweight為原始基礎權值,convbaseweight為平滑后的基礎權值。
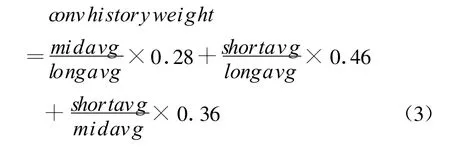
式(3)為詞語的歷史權值的計算公式,longavg為基礎權值的長時期的平均值,shortavg為基礎權值的短時期的平均值,midavg為基礎權值的中時期的平均值。式中midavg與longavg的比值是中時期與長時期的一個比值,系數為0.28;shortavg與longavg的比值是短時期與長時期的比值,系數為0.46;shortavg與midavg的比值是短時期與中時期的比值,系數為0.36。該公式中更強調短時期與長時期的比值的重要性。系數值的選取都是大量試驗之后,總結得出的一個經驗值。
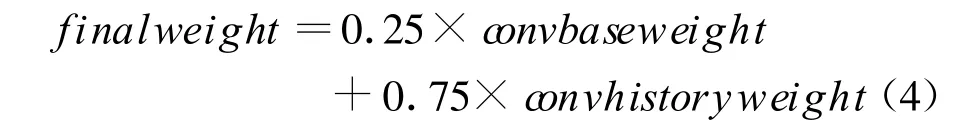
式(4)為詞語的最終熱度權值計算公式,f inalweigth為詞語的最終熱度權值,convbaseweight為平滑處理后的基礎權值,convhistoryweight為歷史權值。公式中0.25和0.75分別為基礎權值和歷史權值的系數,是強調兩個權值不同的重要程度,此公式中更強調歷史權值的重要性,因此歷史權值的系數設定更高一些。系數值的選取,主要依靠大量的實驗測試,根據大量的測試結果來選取此系數值。
通過上述詞語的熱度權值計算之后,按權值的大小對詞語進行熱度排序。得到一段時間的熱點人名、熱點地名、熱點機構名及熱點非實體詞語。
2.4 實驗測試
在TRS輿情監測系統中對熱詞進行自動發現,計算熱詞的時間區間可以隨機設定,例如計算1天熱詞、3天熱詞和7天的熱詞。數據來源通過T RS InfoRadar對互聯網的信息進行采集。數據源除選擇互聯網新聞外,還選擇網絡論壇和博客的信息,尤其重點選取論壇的信息。論壇信息是所有網絡信息中,信息量最大的,也是網民關注度,參與度最大的、它的影響力也是不容低估的,選擇了主流的論壇如新華網論壇、人民網論壇、天涯論壇、貓撲和凱迪等。對采集的數據過濾、抽取之后,存儲到T RS數據庫中。參與分析的歷史數據集的范圍,也可隨機設定,通過熱詞分析配置文件來設定。熱詞分析的配置文件的配置參數如表1所示。
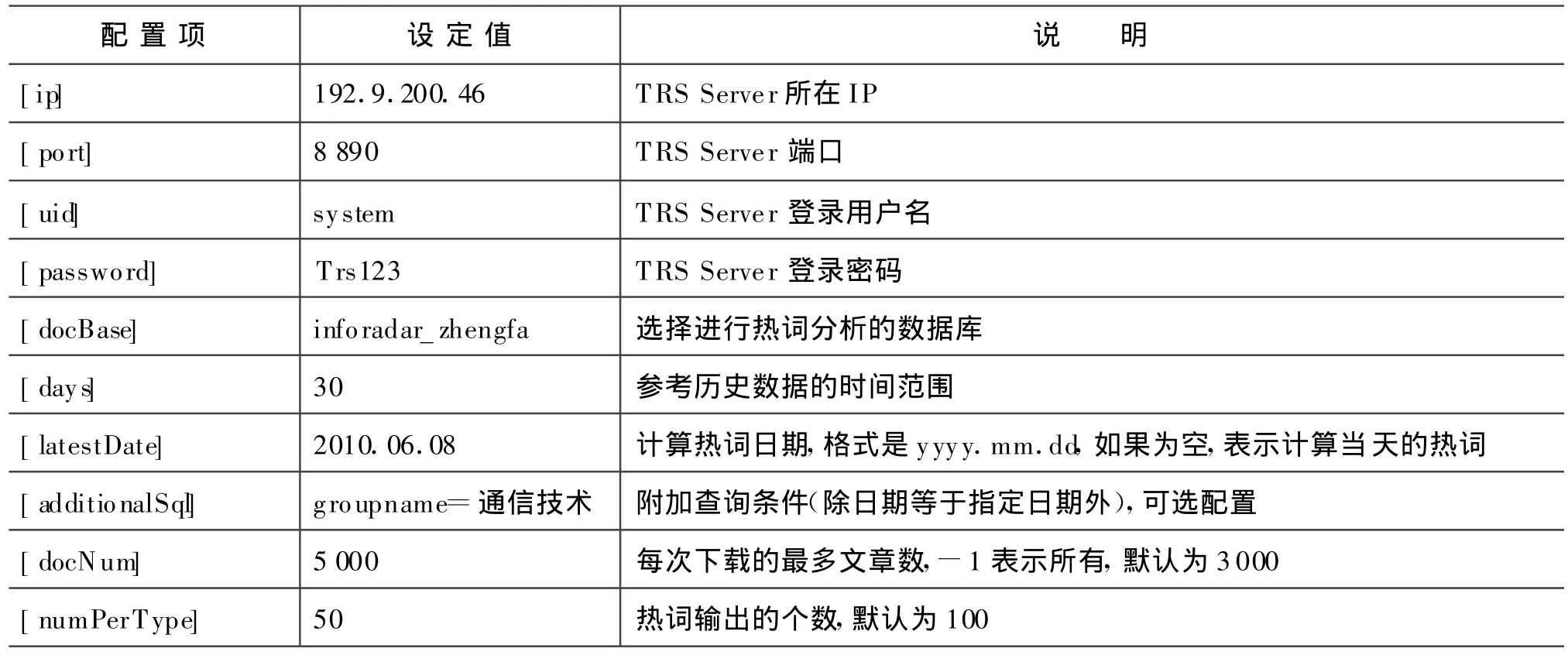
表1 熱詞分析的配置參數表
表1為TRS熱詞分析模塊識別的2010-6-10當天的熱詞,包括熱點人、地名及其非實體熱詞。歷史數據的參考時間范圍是半個月。命名實體識別的性能目前為每秒500k左右的識別速度,從熱詞應用的角度,目前的識別速度可以滿足工程需求,識別性能還有一定的提升空間,后續還需不斷的改進。非實體串的識別速度非常快,每秒達到2M左右的識別速度,目前還存在很多誤識的垃圾串,需要優化過濾算法,提高非實體串的識別精度。
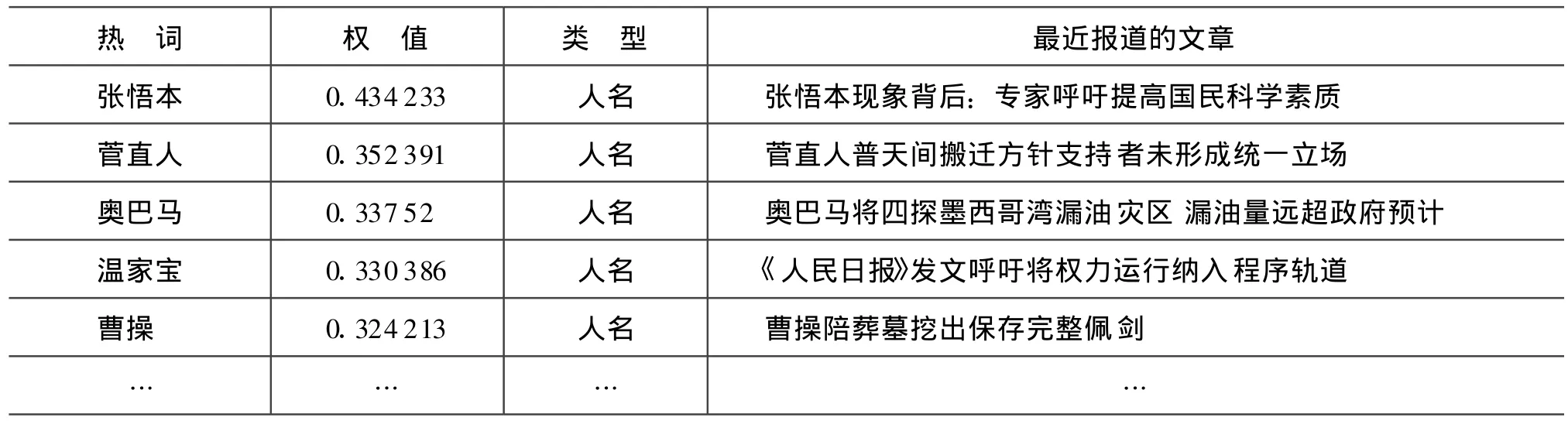
表2 熱點人名表
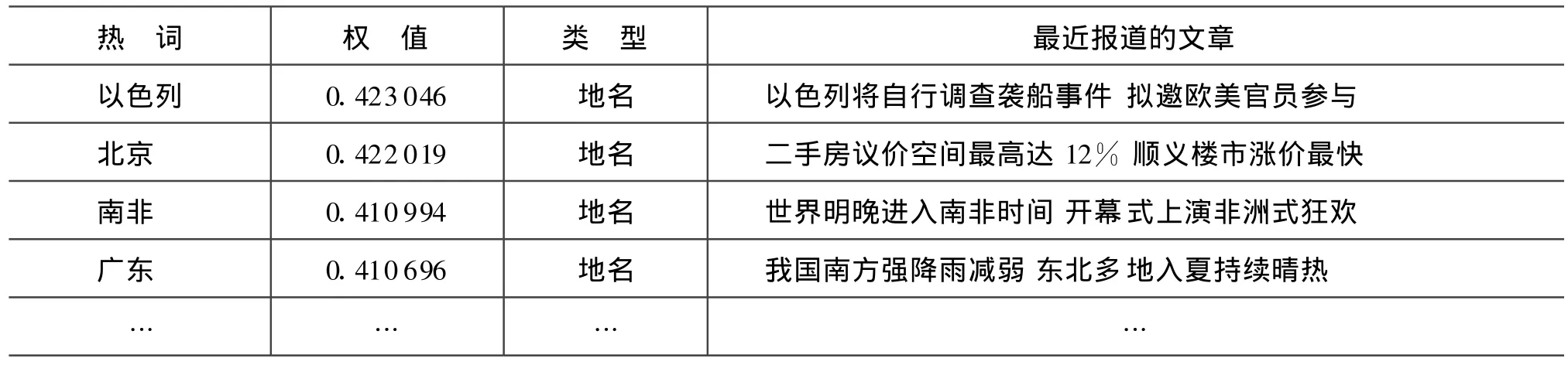
表3 熱點地名表
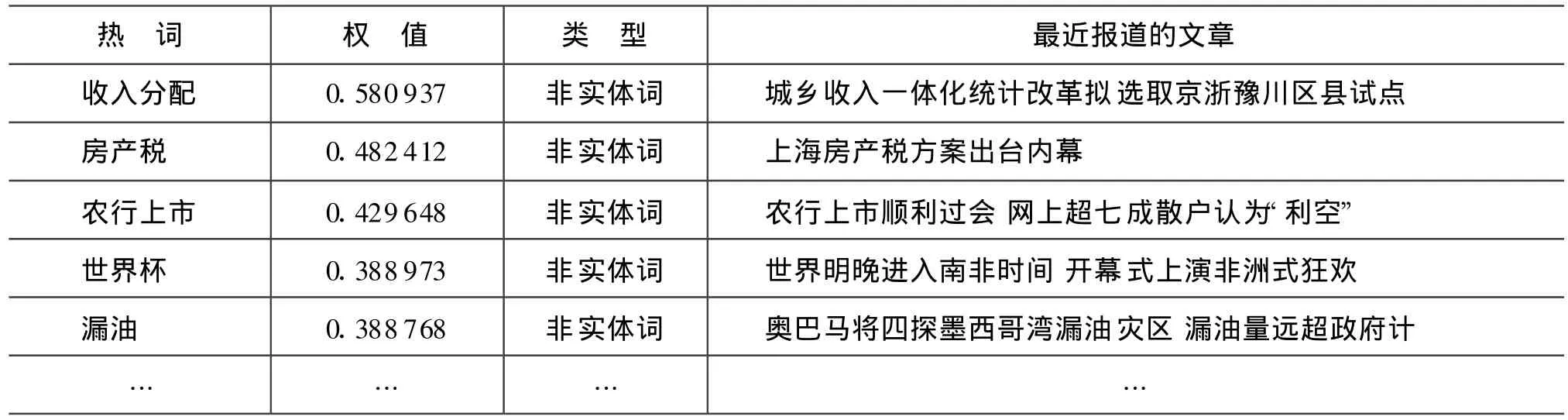
表4 熱點非實體表
3 熱詞關聯展示
熱詞關聯技術包括兩部分。第一部分為熱詞類信息的確定,第二部分為熱詞類之間的關聯性計算。
3.1 熱詞關系分析
第一部分熱詞類信息的確定方法。對所有備選熱詞短語根據權重高低進行排序,取權重高的形成熱詞類,同時把同現程度很高的熱詞短語合并成一個類。熱詞短語出現的文章確定為類內的文章,第二部分為熱詞類關聯性的確定,通過同現率等特點確定類之間的關聯性,采用詞群關系圖展現。關聯信息在詞群關系圖中表現為連接類與類之間的連線,生成最終詞群聚類結果。
形成詞群關系圖的具體步驟為首先把所有類分成組,分組的過程為:首先計算所有類兩兩間的相似度,相似度的計算方法為兩個類的文檔同現率,然后每次取相似度最大的兩個類所在的組合并形成一個新的大組,為了防止出現過于極端的情況,這里強制一個組中最大的類數目為10。合并過程中,所用的相似度最大的兩個類之間就形成一個關系,最終就形成這樣一個局面:所有的類被分成幾個組,每個組之間的關系形成一個無環圖。
3.2 詞群關系圖坐標點的計算
組形成之后,計算各組內各個類點的坐標信息。關系并不需要計算坐標,因為類點坐標確定了,線也就確定了。詞群關系圖中點坐標的計算方法如下:
假設畫布是個正方形,首先根據組數目計算畫布分塊,比如7~9個組會分成3×3,5~6個組會分成3×2等等,力爭分布最美觀。然后,在每個分塊內繪制一個組(有的塊內會沒有組),由于組內類數目不同,所以有的塊會擁擠,而有的塊會比較空曠,現在沒有更好的辦法處理這個問題,后期不斷優化。
塊內類分布計算如下:
如果組內類數目為1個,則在塊內中心附近隨機產生一個位置;
否則,如果組內類數目小于6,則,選擇一個最大的類作為中心,其他類均勻分布在周圍。如圖2所示。
為了美觀而不死板,周圍點的分布有一定的隨機旋轉。
如果組內數目大于6,則,選擇最大的兩個類,作為雙中心,分布在矩形塊的對角線上,然后分別以這兩個類為中心,其他類半圓分布,典型的情況如圖3所示。
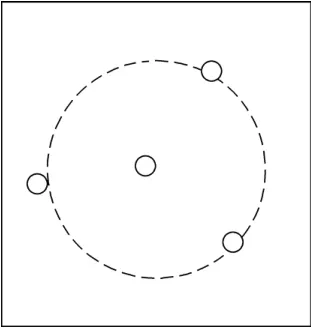
圖2 組內單圓心點坐標的示意圖
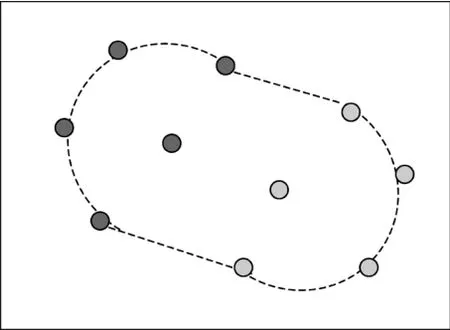
圖3 組內雙圓心點坐標的示意圖
3.3 試驗
實驗數據最近七天的熱詞分析及其詞群關系展示情況,歷史參比數據選擇30天的數據規模大約百萬級。圖4中近七天的熱詞形成的詞群關系分成8個大組,例如:組1中“金融機構”、“債務危機”和“歐元區”為一組;組2中“分析師”和“創業板”為一組 ;組 3 中“認貸” 、“房貸”、“二手房” 、“調控政策”和“中國新聞”為一組等。
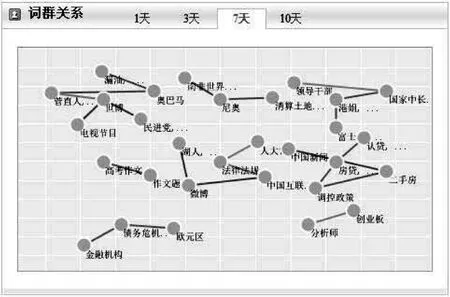
圖4 七天的詞群關系圖
實驗數據中,每一個節點點擊之后都可以看到該熱詞所在的文章標題列表,點擊標題列表可以看到熱詞在文章出現的具體位置,采用標紅顯示。熱詞識別方法已經成功應用到T RS輿情監測系統的熱點發現模塊,熱詞發現模塊包括熱點事件、熱點專題、熱點詞語識別等。TRS熱點發現模塊已經取得很好的工程實踐效果,在很多輿情項目中得到成功應用。
4 結束語
互聯網信息有復雜多變信息量大等特點,目前的熱詞分析模塊效果不是很理想,需要提升的空間還很大,需要改進的方面還很多。例如熱詞的權值計算方法,還需要分析考慮詞語在正文中出現位置、詞性、短語長度等特征信息;人名、地名、機構名的識別的準確率還有待提高,目前系統中還有一定的誤識問題;非實體串識別中,還有很多垃圾串,有待于提高垃圾串的過濾工作;詞熱類的劃分方法以及計算類之間的關聯性還不是很準確,需要更精確的劃分熱詞類,繼續探索除了貢獻特征以前的其他方法來計算關聯性,比如間接關聯性等。總之,輿情熱詞串的識別效果還不是很理想,需要不斷的改進、優化識別策略及其算法等。
[1]呂雅娟,趙鐵軍,等.基于分解與動態規劃策略的漢語未登錄詞識別[J].中文信息學報,2001,15,(1):28-33.
[2]L.R.Rabiner(1989)A Tutorial on Hidden Markov M odels and Selected A pplications in Speech Recognition[C]//Proceedings of IEEE.77(2):257-286.
[3]張華平,劉群.基于角色標注的中國人名自動識別技術[J].計算機學報,2004,(1):85-91.
[4]沈嘉懿,李芳,等.中文組織結構名稱與簡稱識別[J].中文信息學報,2007,21(6):17-21.
[5]Satoshi S.,Nagao M.Toward memory-based translation[C]//Proceedings of the 13th International Conference on Computational Linguistics(COLING-90).Helsinki,Finland,1990:247-252.
[6]呂學強.面向機器翻譯的E-Chunk獲取與應用研究[D].博士畢業論文.東北大學.2005:27-52.
[7]Nagao M.,Mori S.A new method of n-gram statistics for large number of n and automatic extraction of words and phrases from large text data of Japanese[C]//Proceedings from the 15th International Conference on Computational Linguistics,Kyoto 1994:611-615.
[8]李超,王會珍,等.基于領域類別信息C-value的多詞串自動抽取[J].中文信息學報,2010,24(1):94-98.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
