面向文本拷貝檢測的分布式索引
2011-10-15 01:36:50俞昊旻黃萱菁
中文信息學報 2011年1期
張 玥,俞昊旻,張 奇,黃萱菁
(復旦大學計算機科學技術學院,上海201203)
1 引言
在互聯網中存在大量內容重復的相似網頁。根據Broder等人1997年統計的結果,大約有41%的網頁是重復的[1],在Fetterly等人2003年統計的結果中這個比例大約是29.2%[2]。很多Web應用,例如文本聚類[1],網頁去重[3],抄襲檢測[4],社區發現[5],協同過濾[6]等任務,都依賴于高效的文本拷貝檢測。
為了減少比較次數,提升性能,倒排索引是拷貝檢測任務中常用的數據結構。但隨著文檔集規模的增大,基于單臺電腦的索引結構已經不能有效處理大規模文檔集上的拷貝檢測任務。為此需要采用分布式索引,通過并行計算提高處理能力。同時,因為數據集的規模將一直增大,一個好的分布式索引,不僅要能提升拷貝檢測算法的效率,而且還必須具有良好的可擴展性。
Map-Reduce是一種并行編程范式,基于此范式可以實現具有良好可擴展性的算法[7]。本文中,我們采用Map-Reduce范式,對基于索引的文本拷貝檢測進行如下幾個方面的研究:
?第一,分析比較了兩種分布式索引結構:Term-Split索引和Doc-Split索引,并給出了Map-Reduce范式下的建立這兩種索引的算法。
?第二,基于上述兩種索引結構,分別給出了Map-Reduce范式下的拷貝檢測算法。并且通過實驗,比較了兩種算法性能上的差異。
?第三,探討了Map-Reduce范式下,中間結果數量對整個算法性能的影響,并進一步討論如何更好的利用Map-Reduce范式實現算法的并行化。
本文的其余部分將按如下方式進行組織:第2節中,將說明基于索引的拷貝檢測方法的基本思想。第3節中,將簡要介紹Map-Reduce范式的相關內容。第4節將具體闡述如何在Map-Reduce范式下實現基于索引的拷貝檢測方法。第5節和第6節分別介紹實驗和結論。
2 基于索引的拷貝檢測方法
給定一個文檔集,在其之上進行文檔間兩兩比較的拷貝檢測,需要對n(n-1)/2個文檔對進行相似度計算。這是一個O(n2)的算法。因此拷貝檢測算法中,一般會采用倒排索引來減少所需比較的次數。因此索引結構的實現對拷貝檢測算法的性能有至關重要的影響。不同的索引結構還會直接決定拷貝檢測算法的實現。
另一方面可以看出,傳統的單機索引結構已經難以適應越來越大的數據規模,需要引入分布式索引,以適應并行處理的需求。為此本文中將比較兩種分布式索引結構,在此基礎上,提出了兩種基于分布式Index的拷貝檢測算法。
為了方便討論,本文中將整個算法分成三步:
?第一步,Tokenize:遍歷文檔集中所有文檔,對每個文檔抽取特征。
?第二步,建立分布式索引:在Tokenize基礎上,建立分布式索引。
?第三步,基于索引的拷貝檢測:基于分布式索引,進行文檔兩兩之間的相似度計算,得到內容重復的文檔對。
2.1 文本特征與相似度計算
進行有效的文本拷貝檢測,首先必須考慮兩個問題,第一,從文本中抽取何種的特征來表征一個文檔;第二,采用何種相似度的度量來表征兩篇文檔間的相似程度。本文中采用 Theobald等人提出的SpotSig算法對文檔進行特征抽取,將文檔表示成SpotSig(Si)的集合[8]。此外本文中將采用J accard相似度來表征文檔的相似度。給定兩個集合 A和B,集合 A、B的J accard相似度定義為[9]:
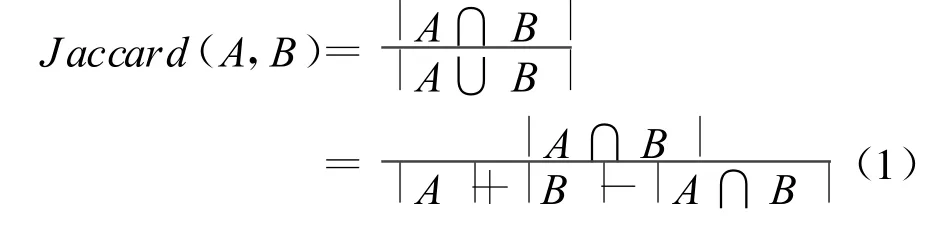
2.2 分布式索引
完整的索引一般包括兩個部分:由詞(Term)組成的詞典和包含某個詞的所有文檔(Doc)的ID列表(Posting List)[10]。要實現分布式索引,就需要按照某種方式將一個完整的索引分割開來。有兩種基本的分割方法,一種是按照詞分割(Term-Split),另一種是按照文檔分割(Doc-Split)。
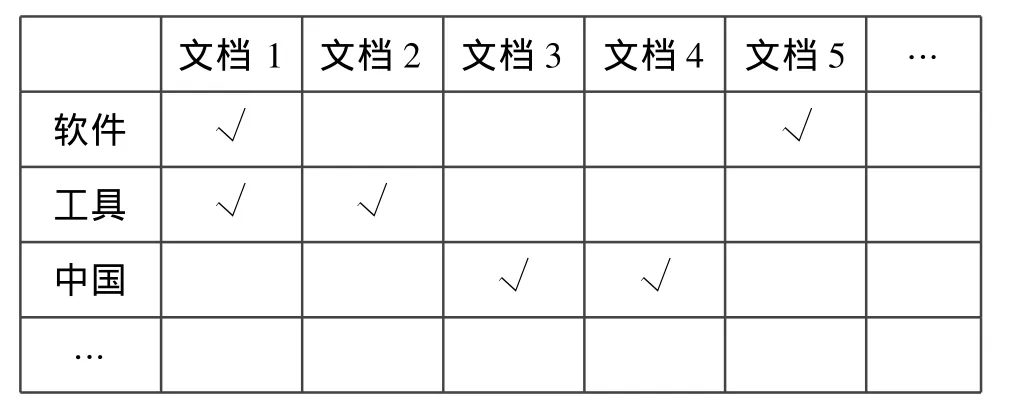
圖1 一般索引結構
如圖1所示,一個索引可以看成一個二維表格,表格的行表示不同的詞,表格的列表示不同的文檔。Term-Split相當于將表格“按行橫向分割”,首先將詞典中的詞劃分為若干子集,每個節點只保存一個詞子集以及相應的Posting List。Doc-Split則相當于將表格“按列縱向分割”,將整個文檔集劃分為若干個子集,對每個子集分別建立獨立的索引,存儲在不同節點上。
2.3 基于索引的拷貝檢測方法
Lin提出了Map-Reduce范式下進行兩兩文檔間相似度計算的算法Postings Cartesian Product(PCP)[11]。本文中將基于此思想提出基于Term-Split索引的拷貝檢測方法。此外,本文將提出另外一種基于Doc-Split索引的拷貝檢測方法。
2.3.1 Term-Split方法
對于Term-Split索引,每個索引分塊中包含詞典中的一部分詞以及這些詞所對應的Posting List。因此 Term-Split方法,首先從每個詞的 Posting List出發,計算兩篇文檔在這個詞上的“部分相似度”(partial contributions)[11],再對這些“部分相似度”進行綜合,得出兩篇文檔間完整的相似度。在Lin的方法中采用的是向量點積作為相似度。而本文中采用J accard相似度。
如公式(1)所示,已知|A|、|B|,是兩個文檔的長度,所以只需要計算 A,B的交集大小,|A∩B|。亦即 A,B兩篇文檔共有的詞數量即可。結合Term-Split索引,若兩篇文檔出現在同一個Posting List中,表明這兩篇文檔在該詞上的“部分交集大小”為1。遍歷所有詞后,對所有文檔對的“部分交集大小”進行綜合,得到兩篇文檔的完整相似度,再與相似度閾值進行比較,決定是否為“拷貝”。
如圖2(a)所示,對于每一個詞所對應的Posting List,將Posting List中的Id兩兩組合,作為一個可能相似的候選文檔對(candidate_pair)。考慮到兩篇文檔之間,每出現一個相同詞,就會產生一個這樣的文檔對。因此只需要對于每一個候選文檔對維護一個計數器(accumulator),統計該文檔對出現的次數,得到的結果就是這兩篇文檔共有的詞數量。最后根據計數器的值,計算所有候選文檔對的相似度。
2.3.2 Doc-Split方法
對于Doc-Split索引,每個索引分塊中包含一部分文檔的完整索引。因此基于Doc-Split索引的方法,是把每一篇文檔作為一次查詢,在所有的索引分塊中查找與其相似的文檔。因為索引分塊和文檔內容都分別分散在不同的節點上,具體實現時可以有兩種解決方式。一種方式是每次把作為查詢的文檔分發到各個節點上,在該節點上的索引中進行查重,另一種方式是每次把一個索引分塊分發到各個節點上,把該節點上的所有文檔作為查詢進行查重。考慮到索引比文檔本身更容易壓縮,且壓縮后體積較小,本文中采用后一種實現方式。
如圖2(b)所示,每次首先將一個索引分塊復制到所有節點上。然后在每個節點上,將該節點中的所有文檔作為查詢,在索引分塊中查找拷貝。對每個作為查詢的文檔(doc_q)維護一組計數器,記錄所有索引分塊中文檔(doc_i)與 doc_q的交集大小。每當doc_q與doc_i有一個相同詞時,就將 doc_i對應的計數器加1。最后根據計數器的值,計算doc_q與所有doc_i的相似度。

圖2 基于索引的拷貝檢測方法
3 Map-Reduce范式
Map-Reduce范式是J.Dean等人在2004年提出的分布式編程范式[7]。它通過面向函數的抽象使得分布式程序的開發變得簡單。在Map-Reduce編程范式下,數據被抽象為<key,value>的形式。而針對數據的操作被抽象為Map和Reduce兩個操作。用戶只需要提供自定義的兩個函數實現Map和Reduce。剩余的工作,諸如數據分發,任務調度,容錯,任務同步等工作可以交由框架處理。
如圖3所示,一個Map-Reduce的任務包括兩個階段。第一個階段為Map操作,首先將輸入分割為小塊,每一個小塊都包含若干個<key,value>對。在這些數據分塊上執行map操作,得到中間結果。中間結果同樣以<key,value>的形式表示。接著,中間結果按照key進行sort和group,使key相同的結果合并在一起。第二階段為Reduce操作,對相同key的中間結果進行合并得到最終結果,以<key,value>的形式輸出。
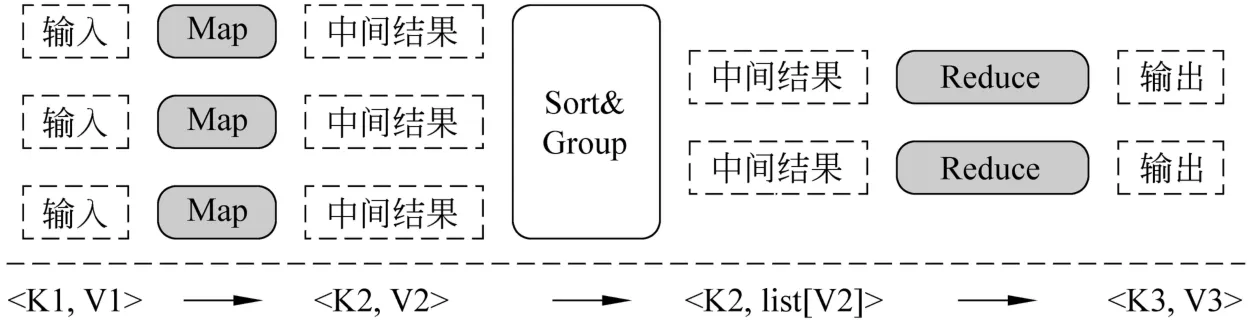
圖3 M ap-Reduce范式
4 實現細節
本節中將詳細介紹本文所述方法在Map-Reduce范式下的實現細節。本節共分為三部分,分別討論基于索引的拷貝檢測方法的三步。
4.1 Tokenize
第一步,Tokenize所有文檔。對于每個文檔的操作可以完全并行,實現起來相對簡單,僅需Map操作即可。如圖4所示,每個Map任務接受一批文檔作為輸入,其中文檔Id為key,文檔內容為Value,對每個文檔,抽取SpotSigs特征,將文檔Id作為key,特征集合作為Value輸出。
4.2 建立分布式索引
第二步,對文檔建立索引。本文中分別給出兩種分布式索引在Map-Reduce范式下的實現。
如圖5(a)所示,Term-Split索引需要Map、Reduce兩步操作。在Map過程中以文檔 Id(Di)為Key,文檔的SpotSigs特征(Si)集合為Value輸入,輸出的中間結果以Si為Key,Di為Value。在Reduce過程中,將相同Si的中間結果收集在一起,將對應的Di合并成列表。
如圖5(b)所示,Doc-Split索引相對簡單,只需一步Map即可。每個Map任務在整個文檔集的一個子集上迭代,只對子集中的文檔建立索引,不考慮其他子集中的文檔。
4.3 基于索引的拷貝檢測
第三步是基于索引的拷貝檢測。針對 Term-Split索引和 Doc-Split索引將分別給出Map-Reduce范式下的實現。

圖4 Tokenize文檔
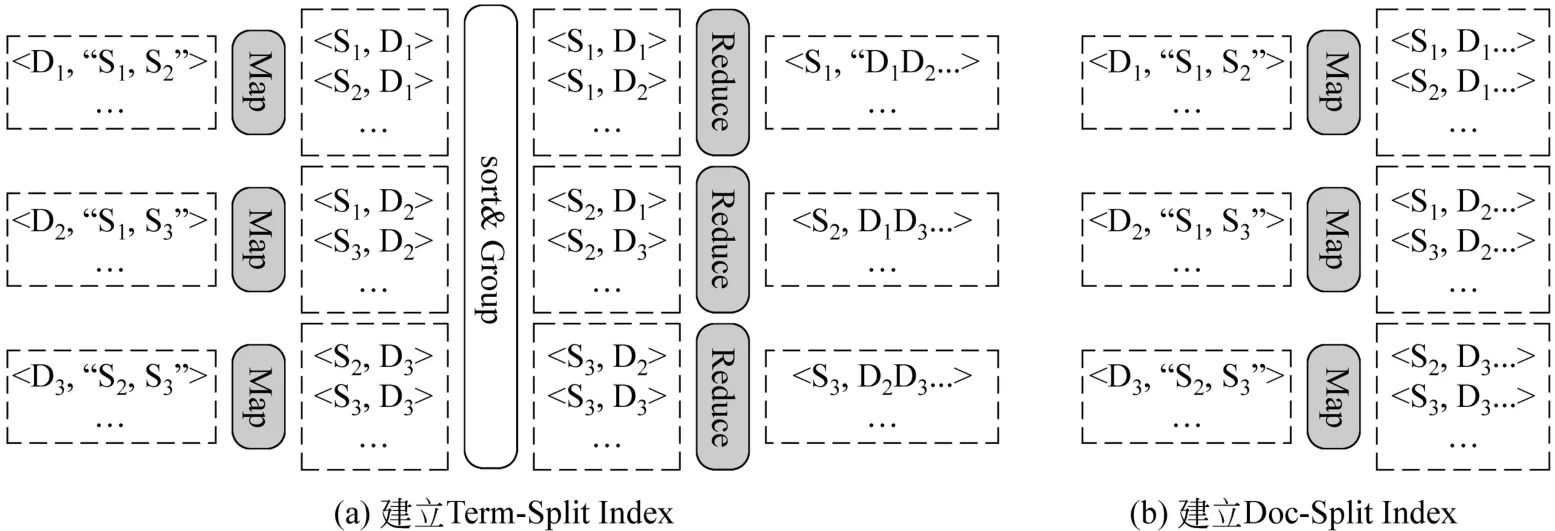
圖5 建立分布式索引
Term-Split方法如圖6所示,在Map操作中,接收以 Term(Si)為 Key,Posting List(D1,D2,…)為Value的輸入,將Posting List中的文檔Id(D1,D2,…)兩兩組合作為中間結果輸出,其中文檔Id對(Di_Dj)作為Key,Value為該pair出現的次數。在Reduce操作中,將相同的Di_Dj收集在一起,將出現的次數相加得到文檔Di和文檔Dj之間相同的Term數量,再根據公式(1)計算得到Di與Dj之間的相似度,如果相似度超過閾值,則將結果以Dj_Dj作為Key,相似度作為Value輸出。
Doc-Split方法如圖7所示,初始化Map任務時,將這次迭代所需的索引分塊讀入內存。Map操作以文檔Id(Di)為key,以文檔的SpotSigs特征(Si)集合為 Value,將輸入的文檔作為“Query”(Dq)在Index中查找拷貝。具體的做法是,根據文檔中的 Term在索引分塊中找到同樣包含這個Term的其他文檔(D1,D2,…)。然后統計這些文檔與(Dq)共有的Term數,之后使用公式(1)計算相似度。最后,將相似度超過某個閾值的文檔對(Dq_Di)作為Key,相似度作為Value輸出。
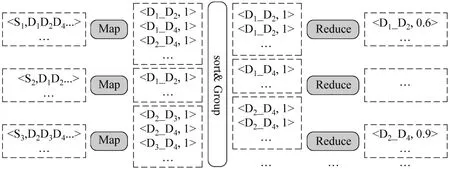
圖6 Term-Split方法
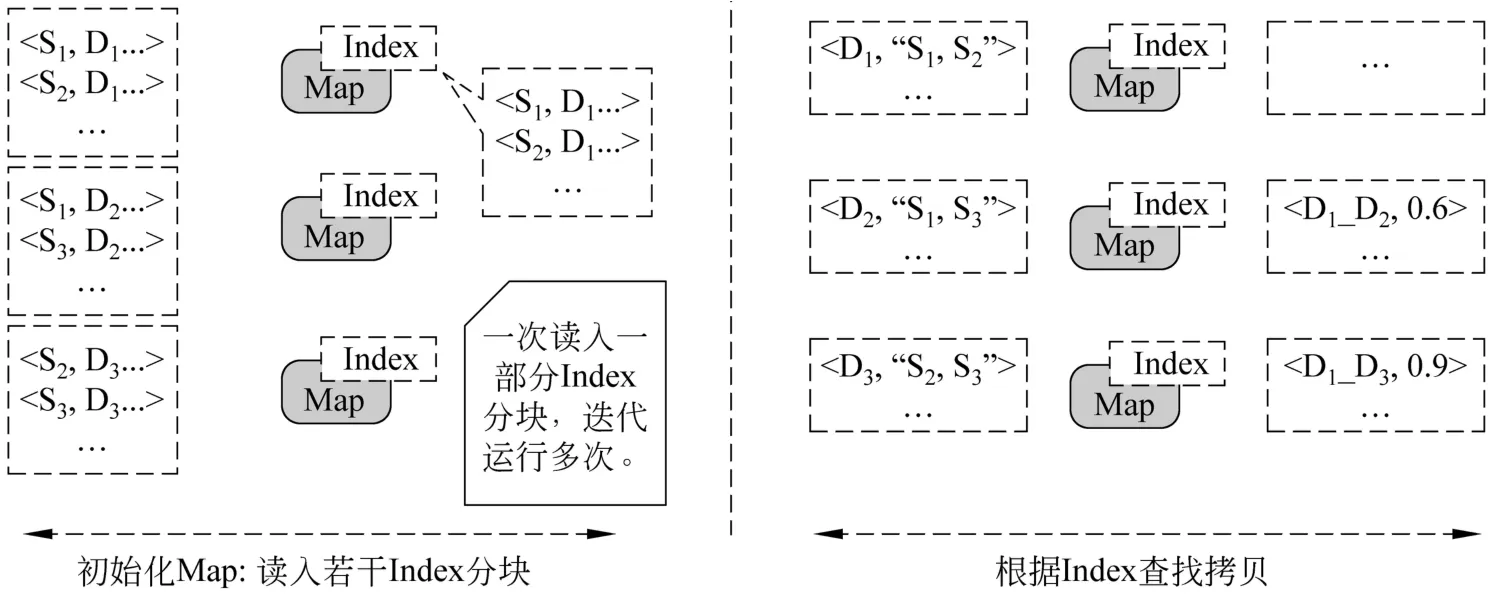
圖7 Doc-Split方法
5 實驗
實驗使用了開源的 Map-Reduce框架 Hadoop①http://hadoop.apache.org/。實驗將使用由10個節點構成的集群。每個節點配置2個單核主頻為2.8GHz的4核CPU和32GB的內存。本文將使用WT10G作為實驗數據。WT10G包含約160萬個文本文件,總大小約為10GB。本節中,將首先考察兩種文本拷貝檢測算法的精度,以確定算法的參數。然后在最優精度的參數下,對兩種算法的性能進行比較。
5.1 精度
在文本拷貝檢測算法中,相似度閾值(τ)對結果的精度有比較大的影響。此外,在通過索引進行相似度計算時,往往會設置IDF值限制條件,忽略掉IDF值過高或過低的Term,這也會對精度產生影響。本實驗的主要目的是,在不同的IDF限制條件下,找出使得精度最好的τ。為此,本實驗將在人工標注的Golden Set上進行。該文檔集是從WT10G中隨機抽取出來,經過人工標注得到的,包含1000篇文檔。此外,試驗中所采用的IDF值是在整個WT10G文檔集上統計的結果。考慮到本文所述兩種算法的實現在精度方面具有完全一致的特性。因此,在下面論述中對這兩種算法不作區分。
如圖8所示,當IDF值為0.0~1.0以及 0.1~0.95時,τ取 0.4可以使F1 Score達到最大,均為0.953。τ過小會導致Precision值的下降,τ過大會導致Recall值急劇下降。當IDF值為0.2~0.85時,因為更多的詞在計算時被忽略,因此需要將τ設得略低一些,當τ取0.3時,F1 Score達到最大,為0.954。該實驗結果與 Theobald等人報告的τ取0.44時,F1 Score為0.94的結果基本相符[8]。
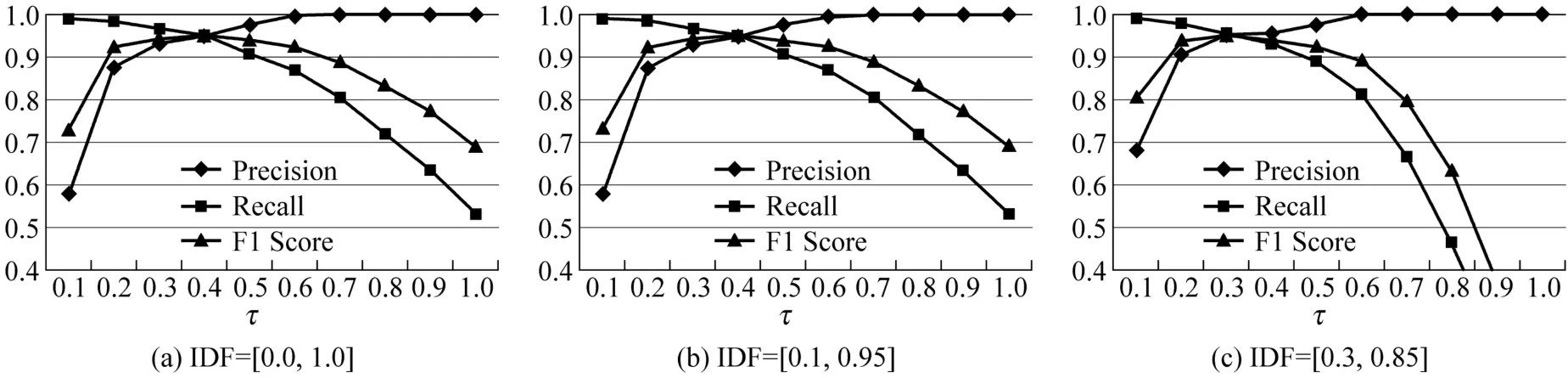
圖 8 算法精度 V.S.相似度閾值(τ)
5.2 效率
通過前面的實驗已經得到在不同IDF值設定下使得精度最優的τ:IDF為[0.0,1.0]時,τ取0.4;IDF為[0.1,0.95]時,τ取 0.4;IDF為[0.3,0.85]時,τ取0.3。在本實驗中,將在上述三種不同參數配置下,對Term-Split和Doc-Split拷貝檢測方法進行比較。本實驗使用WT10G的八分之一作為測試集合,約包含20萬篇文檔。
由表1可見,Doc-Split方法的效率要明顯好于Term-Split的方法。這主要是因為在Term-Split索引中,每個節點只包含一部分詞信息,只能計算文檔對之間的“部分交集大小”,在最終匯總前不能確定兩個文檔是否相似。為此必須維護大量的計數器,產生大量的中間結果。
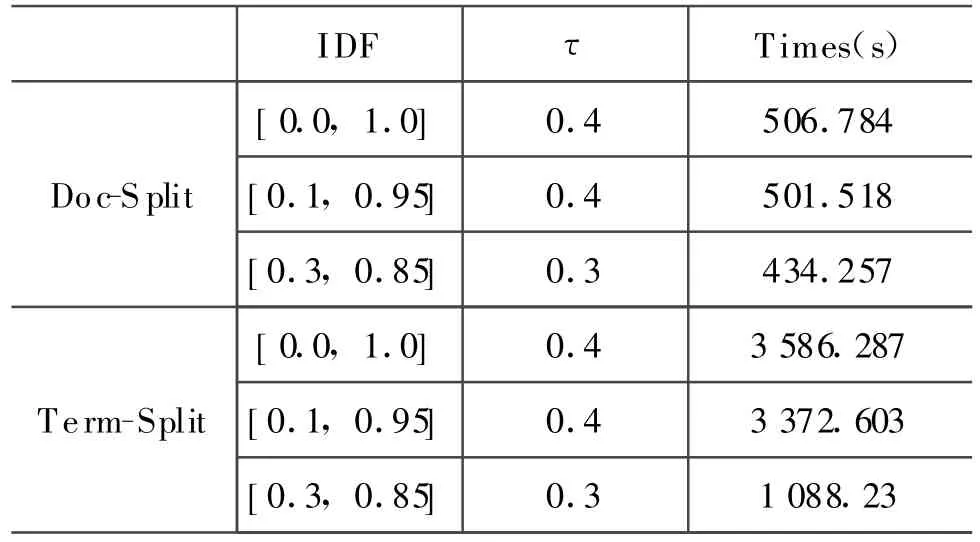
表1 Term-Split V.S.Doc-Split
5.3 可擴展性
在本實驗中,將驗證兩種拷貝檢測算法的可擴展性。首先,將考察數據集規模與運行時間的關系。以檢驗兩種算法在數據集規模不斷增加的情況下的適應性。然后,將考察集群中CPU數量與運行時速度的關系。以檢驗兩種算法的加速性能。實驗中IDF取[0.3,0.85],τ取0.3。
如圖9(a)所示,當文檔數量達到 80萬時,Term-Split方法在本次實驗的硬件條件下已經無法進行(因為128GB的硬盤被中間數據耗光,算法在運行了4個多小時后終止)。因為中間數據的數量太大,當數據集規模很大時,Term-Split方法只能通過Lin提出的近似方法[11]計算非精確解。而相比之下 Doc-Split方法則表現出良好的性能。使用Doc-Split方法對整個WT10G數據集進行實驗的時間為5627.457秒。同時如圖9(b)所示,在加速性方面Doc-Split方法也優于Term-Split方法。在CPU數量增加4倍的情況下,達到了2.56倍的速度提升。這是因為Map-Reduce范式下的程序,具有天然的可擴展性,可以通過增加節點數量提高處理能力。
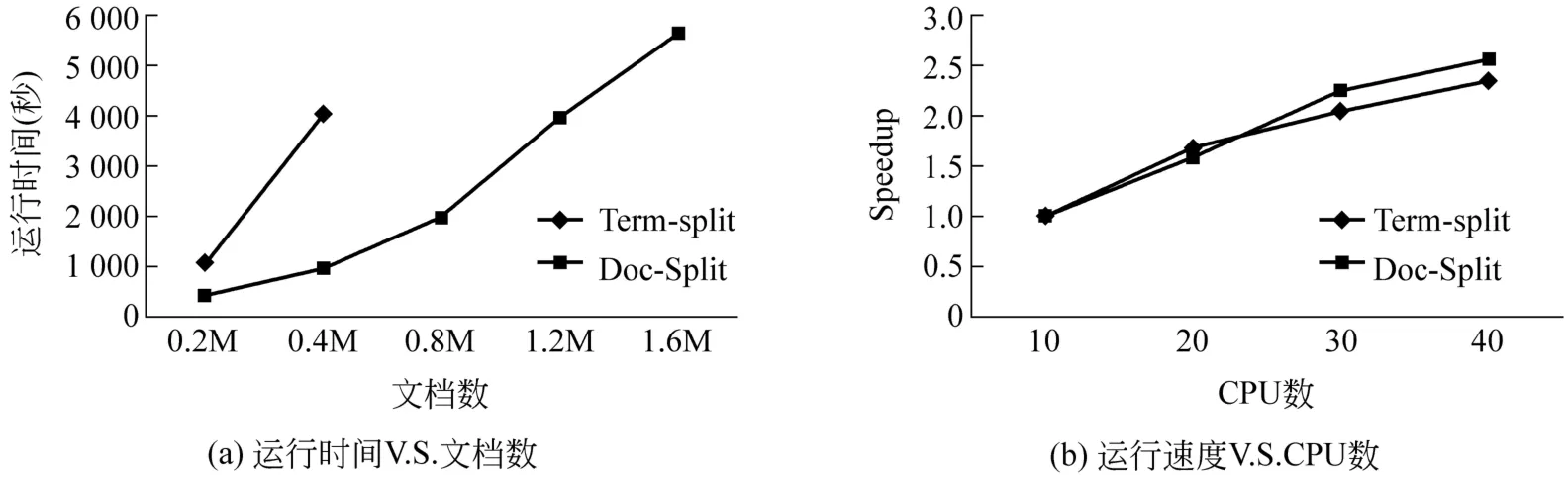
圖9 可擴展性實驗
6 結論
本文對Term-Split和Doc-Split兩種不同的分布式索引結構進行了比較,并分別給出了Map-Reduce范式下建立這兩種索引的算法,以及基于這兩種索引的拷貝檢測算法。最后通過實驗比較了上述兩種算法的性能。
實驗表明Doc-Split方法在進行拷貝檢測任務時更有效,而Term-Split方法因為產生了大量中間結果使得效率大大降低。因此中間結果數量的多少,直接影響了采用兩步并行(Map,Reduce)的Map-Reduce程序的運行效率。當中間結果數量過多時,對中間結果進行排序,分組以及分發的操作代價已經遠遠超出了兩步并行的好處。因此不適合采用兩步并行,應該改為一步并行。比如本文所述的Doc-Split方法,沒有采用Reduce操作,而是每次將一部分索引分塊復制到所有節點上。因為僅憑單個節點上的信息已經可以得到結果,就無需進行Reduce操作,也回避了中間結果的問題。
綜合來看,Map-Reduce范式可以有效地解決算法并行化的問題。但因為不同算法的差異性,在實現并行化時,需要結合算法本身的特性進行考慮,才能最大限度的發揮Map-Reduce范式的好處。
[1]A.Z.Broder,S.C.Glassman,M.S.Manasse et al.Syntactic clustering of the web[J].Computer Networks,1997,29(8-13):1157-1166.
[2]D.Fetterly,M.Manasse,and M.Najork.On the E-volution of Clusters of Near-DuplicateWeb Pages[C]//Proceedings of the 1st Latin American Web Congress.Washington,DC,USA:IEEE Computer Society,2003:37.
[3]J.Cho,N.Shivakumar,and H.Garcia-Molina.Finding replicated web collections[C]//ACM SIGMOD Record.New York,NY,USA:ACM,2000:355-366.
[4]T.C.Hoad and J.Zobel.Methods for identifying versioned and plagiarized documents[J].JASIST,2003,54(3):203-215.
[5]E.Spertus,M.Sahami,and O.Buyukkokten.Evaluating similarity measures:a large-scale study in the orkut social network[C]//Proceedings of the 11th ACM SIGKDD.New York,NY,USA:ACM,2005:678-684.
[6]R.J.Bayardo,Y.Ma,and R.Srikant.Scaling up all pairs similarity search[C]//Proceedings of the 16th WWW.New York,NY,USA:ACM,2007:131-140.
[7]J.Dean and J.Ghemawat.Map-Reduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM,2004,51(1):107-113.
[8]M.Theobald,J.Siddharth,and A.Paepcke.Spotsigs:robust and efficient near duplicate detection in large web collections[C]//Proceeding of 31th SIGIR,New York,NY,USA :ACM,2008:563-570.
[9]Pang-Ning Tan,Michael Steinbach,Vipin Kumar.Introduction to Data Mining[M].Addison-Wesley,2005.
[10]C D Manning,P Raghavan,H Schutze,An Introduction to Information Retriveval[M].Cambridge University Press,2008.
[11]J.Lin.Brute force and indexed approaches to pairwise document similarity comparisons with mapreduce[C]//Proceedings of 32th SIGIR,New York,NY,USA :ACM,2009:155-162.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
