文本自動分類新探究
2011-11-06 06:28:48陳可華
赤峰學院學報·自然科學版 2011年4期
陳可華
(寧德師范學院 計算機與信息工程系,福建 寧德 352100)
文本自動分類新探究
陳可華
(寧德師范學院 計算機與信息工程系,福建 寧德 352100)
文本自動分類是一種有效的組織信息和管理信息的工具.傳統分類方法一般在分類效果和運行效率兩者上不可兼得.通過綜合 Rocchio 和 KNN 兩種分類方法的優點,設計了一種基于多代表點的文本分類方法,該方法通過對各類挖掘出多個有效的代表點(真實或虛擬的),再使用基于這些代表點的 Rocchio 和 KNN 方法進行分類.實驗表明,該方法以較少的訓練時間達到令人滿意的分類效果,并且能很好解決不平衡類問題,實驗結果顯示該方法能達到與 SVM 相當的分類效果.
文本分類;多代表點;Rocchio;KNN
1 介紹
隨著因特網等信息技術的發展,各類信息資源的增長都呈現海量特征,而其中文本數據始終占據重要地位.如何有效地組織、管理和使用這些文本信息成為當前的迫切需求,這促進了文本自動分類技術的迅速發展和廣泛應用[1,2,4].
近年來,隨著如垃圾郵件過濾[3]等需求的激勵,基于機器學習的文本自動分類技術的研究取得了很大的進展,提出 了 很 多 有 效 的 分 類 模 型[4], 如 基 于 類 中 心 的 方 法 ,N a ?v e B a y e s算法,支持向量機 S V M,K N N,神經網絡,決策樹,B o o s t i n g等.
在這些分類方法中,基于類中心的 R o c c h i o方法由于其簡單快速而得到了廣泛的應用,但是該方法的精度常常不能令人滿意,其只適用于各個類之間差異比較明顯的簡單分類問題,而對于較復雜的情況,特別是遇到不平衡類問題時它的分類結果通常要相對差一些;K N N(k近鄰)也是一個常用的分類算法,并且在許多領域(簡單情況和復雜情況)都顯示出良好的性能,但是該方法是一種懶惰的方法,它不用經過任何的訓練學習過程,只是在分類時在所有實例中選擇最相近的k的實例,再根據這k個實例的類分布選擇最可能的若干的類別作為目標類別,所以該方法的一個致命弱點就是它分類時的計算量較大:當它為一個未見實例分類時,它通常要遍歷訓練實例空間以找到查詢實例的k個最近的鄰居.而其他大多數分類算法如決策樹等都因為計算復雜度太高而不適用于大規模的場合,而且當訓練樣本集增大時,都需要重新生成分類器,因而可擴展性差.
為了解決上述問題,提高分類效率但又不丟失分類的精度,需要研究新的分類算法.該工作不論在科學研究還是實際應用中都有重要的意義.本文通過對文本分類的研究,結合基于類中心和 K N N的優點,提出了一種新的簡單有效的文本分類方法,通過給各類提取多個代表點,這些代表點可能是實際存在的文本也可能是虛擬的類中心,然后基于這些代表點對待分類文檔使用 R o c c h i o和 K N N等方法進行分類.從而能夠利用較少的時間獲得較高的分類精度并且能很好的解決不平衡類分類問題.
2 基于多代表點的文本分類模型
2.1 文本分類模型
R o c c h i o算法來源于向量空間模型理論,在向量空間法中,每個文檔被看成一個詞袋,然后被表示成詞項權重的向量:di=(wi,1,wi,2,……,wi,n),其中 di表示文檔,n表示詞項空間的維數,wi,k表示文檔詞項 k在文檔 i中的權重,該權重表示該詞項 在文 檔中 的重要 程度 ,通常 使用 t f-i d f方法 或者 其 他 權重表示方法.兩文檔的相似度可使用對應文檔向量的余弦夾角 計 算(也 可 用 其 他 方 法 如 歐 氏 距 離 等).首先訓練分類模型時,每個類使用一 個中 心向 量(C e n t r o i d)代 表,然后在 分類 時通 過檢查 待 分類文檔和這些中心向量的相似度,把它分到最相似的中心向量所代表的類中.令表示預定義的類別 集合,每個類中包含所屬該類的文檔集合.
K N N是一種懶散的方法,即它沒有學習過程,只是存放所有的訓練例直到接到未知文本的時候才建立分類.對于每個待分類文檔,首先計算其于訓練集中所有文檔的相似度,然后按照相似度從大到小選擇前 K的文檔(k近鄰),最后返回包含這 k個文檔中最多的類標簽.令表示預定義的類別集合,每個類中包含所屬該類的文檔集合,l(d)表示文檔d的類標簽.
2.2 基于多代表點的文本分類模型
第二種方法類似于 K N N方法,不過此時待分類文檔不是與訓練實例表中的文檔進行相似度計算,而是與所有代表點進行計算,其他過程與 K N N類似,此處不累述.
2.3 多代表點挖掘方法
對類代表點的挖掘是本文所提出方法非常重要的一個步驟,我們使用兩種方法進行代表點的挖掘,一種是基于聚類的方式,另一種是基于文檔密度的方式.基于聚類的方式首先對每個類別都進行聚類,聚成若干個簇,使用簇中心作為類的代表點,我們使用 K-M e a n s[4]算法進行文檔聚類;基于文檔密度的方式認為類中密度大的文檔能代表該類的大部分性質,首先計算類中任意文檔間的余弦相似度,然后通過如下公式計算每個文檔的度其中 #C(di)表示文檔 di所屬類別的文檔數,最后返回度值較大的若干篇文檔為該類的代表點.
3 實驗與分析
3.1 文本分類數據集
現在用兩個數據集上驗證我們模型的效果,中文數據集選用復旦文本分類語料庫①,英文數據集選用 2 0-N e w sg r o u p s②.其中 2 0-N e w s g r o u p s共有 2 0個類別,各類別文本數大致相等,每個類別約有 1 0 0 0篇左右的文檔,我們隨機選擇若干篇文本為訓練集,保持訓練集與測試集比例約為 7:3.復旦文本分類語料庫提供者已分好訓練集和測試集.我們使用所提供的訓練集進行訓練分類模型,其類別總數也是 2 0,各類文檔數目不等(每類文檔數從 2 5到 1 6 0 0),是個不均衡類問題,并使用測試集驗證模型.實驗中使用中科院分詞軟件 I C T C L A S③對中文文本做分詞處理,英文詞項使用 P o r t e r算法進行詞干化處理,中英文文本同樣去除停用詞.使用L T C權重公式計算詞項的權重,D F作為特征選擇方法,刪除 D F小于 3的詞項.
3.2 評價指標
準確率和召回率是評價分類性能的兩種常用的指標.對于給定的某個類別,令a表示被正確分到該類的實例的個數,b表示被誤分到該類的實例的個數,c表示屬于該類但被誤分到其它類別的實例的個數,則準確率(p)和召回率(r)分別被定義為:r=a/(a+c),p=a/(a+b).一般使用 F-指標平衡準備率和召回率,其定義為
其中參數 β 用來為準確率(p)和召回率(r)賦予不同的權重.
為了評估算是每一個類的性能指標的算術平均值,而微平均是每一個實例(文檔)的性能指標的算術平法在整個數據集上的性能,一般使用兩種平均的方法,分別稱為宏平均和微平均.宏平均均.對于單個實例而言,它的準確率和召回率是相同的(要么都是 1,要么都是 0).因此準確率和召回率的微平均是相同的,對于同一個數據集的準確率、召回率和 F 1的微平均指標是相同的.
3.3 實驗設計及時間復雜度分析
我們使用 T R表示 2.2節中方法一的分類方法,T K表示方法二的分類方法,并且在代表點挖掘方法上我們分別用 K M 和 D B表 示 K-M e a n s和基 于密 度 (D e n s i t y B a s e d)兩種不同方法,所以通過組合我們有四種不同的分類方法,分別 用 T R+K M,T R+D B,T K+K M 和 T K+D B表 示 .我 們 使 用R o c c h i o,K N N,l i b S V M[6]作為基準模型進行比較.
在訓練階段,基于 K-M e a n s聚類算法的時間復雜度為O(I k n),其中 I為迭代次數,k為聚成的簇數目,n為該類中文檔總數,一般來說 K-M e a n s能很快達到收斂狀態.基于密度的方法的時間開銷主要用于計算文檔間相似度和選擇度最大的 k個文檔其時間復雜度大約為 O(n2+k n).在分類階段,方法一和方法二的時間復雜度都正比于代表點個數.幾個算法的時間復雜度比較可見表 1,m表示類數,k表示每類的代筆點數,N表示訓練集中文檔總數,一般 k*m遠小于 N.
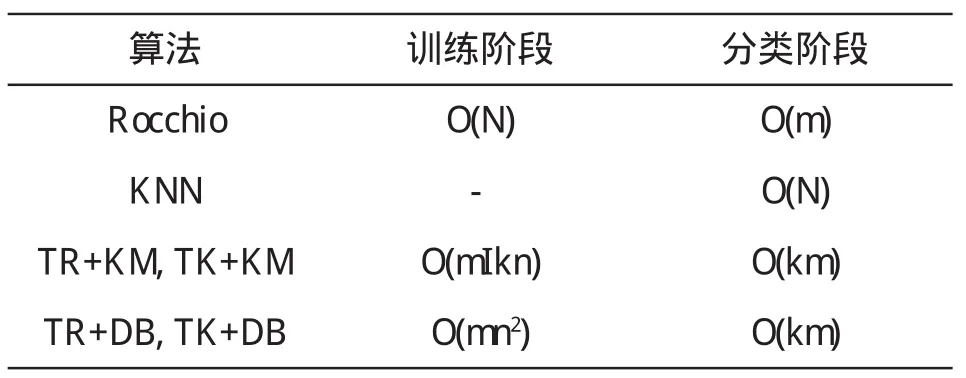
表1 三種算法的時間復雜度比較
3.4 參數選擇
該方法一個重要的步驟就是確定每個類的代表點,代表點個數的不同將會對分類結果產生很大的影響.下面分別通過實驗說明如何選擇以使結果更優,為了簡化過程,我們設每個類別的代表點個數相同,下一小節的實驗也表明這樣的設置(各類擁有相同的代表點數)使得該方法能很好的解決不平衡類問題.我們分別驗證代表點個數從 2到 1 0對分類結果的影響,由于方法 T K還有參數 k需要調整則此處省略.實驗數據隨機選擇 2 0-N e w s g r o u p s中的 3類和 4類,限 于 篇 幅 只 給 出 3類 數 據 (分 別 是 h a r d w a r e,f o r s a l e和m i d e a s t)的準確率結果.
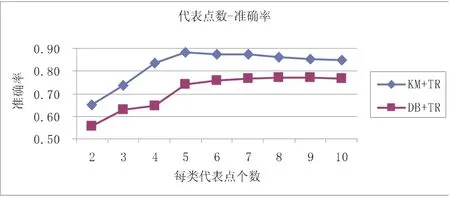
圖1 不同代表點個數對應的分類準確率
從圖1可看出,每類5個代表點分類結果即達到很好效果,并且隨著代表點個數的增加分類準確率不增反而有稍許遞減,我們認為5個左右的代表點就能夠很好的表示該類的性質,過多反而會帶來噪音.并且可以看到基于虛擬代表點的 K M方法效果大大好于基于真實代表點的 D B方法,這是因為 D B方法在選擇代表點后就丟失了該類其他文檔的信息,而 K M是通過綜合簇中所有點形成質心所以不會丟失過多關鍵信息.
3.5 結果及分析
我們使用 K M方法挖掘代表點并設置每類代表點個數為 5,對于 T K方法我們分別選擇了 k為 3和 5,并設置基準模 型 K N N中 k分別為 5、1 5和 3 0,l i b S V M 所 有 參 數 為 默 認值.表 2和表 3分別為這些方法在 2 0 N e w s g r o u p s和復旦數據集上的分類結果.從分類結果可以看出該方法能表現出很好的性能.對于兩種分類方法 T R和 T K,我們發現還是基于 K N N的改進方法(T K)效果更好,這也從另一方面說明了K N N方法比 R o c c h i o方法在分類效果上更好.由于每類只有5個代表點(共 5*2 0個代表點),對于 T K方法的 k值我們分別選擇了 3和 5,我們認為讓 k過大對分類效果不會有太大提高,反而會因為代表點的增加給分類器帶來更多干擾因素.另外,從宏平均(大小類對宏平均貢獻相同)結果可以看出,對于平衡類問題(2 0 N e w s g r o u p s),我們所提出方法最好表現與 S V M相當;而對于不平衡類問題(復旦數據集),我們的方法表現更優,我們認為原因是傳統方法在遇到不平衡類問題時會偏向大類別使得分類效果會急劇下降,而我們的方法通過對各個類提取相同數量的代表點,消除了大類會淹沒小類的可能.

表 2 算法在 2 0 N e w s g r o u p s上的分類結果

表3 算法在復旦數據集上的分類結果
4 總結與展望
本文通過對文本自動分類技術的研究,結合基于 R o cc h i o方法和 K N N方法的優點,提出了一種新的簡單有效的文本分類方法,通過基于聚類和基于密度兩種方法提取類的多個代表點,這些代表點可能是實際存在的文本也可能是虛擬的類中心,然后對這些代表點使用 R o c c h i o和 K N N的方法進行分類.從而能夠利用較少的時間獲得較高的分類精度并且能很好地解決不平衡類的分類問題.
該方法一個重要的步驟就是代表點的挖掘,本文使用了兩種基本的挖掘方法.近年來,概率主題模型得到了廣泛的研究和應用,我們將考慮使用更精確的概率主題模型挖掘文檔集中的主題信息,如 L D A[7].并且在 K M方法中我們設置各代表點權重相同,這也是我們需要加以改進的地方,不僅應該找到類中很好的代表點,還應該刻畫該代表的代表性,對該類性質描述的貢獻程度等.
注 釋:
① http://www.nlp.org.cn/docs/download.php?doc_id =294 http://www.nlp.org.cn/docs/download.php?doc_id=295
② http://www.cs.cmu.edu/afs/cs/project/theo -11/www/ naive-bayes/20_newsgroups.tar.gz
③http://ictclas.org/
〔1〕Sebastiani F.Machine learning in automated text categorization[J].ACM Computing Surveys,2002,34(1):1-47.
〔2〕蘇金樹,張博鋒,徐昕.基于機器學習的文本 分類技術研 究進展[J].軟件學報,2006,17(9):1848-1859.
〔3〕詹川.反垃圾郵件技術的研究[D].電子科技大學計算機 系統結構系博士畢業論文,2005:1-3.
〔4〕范明,范宏建.數據挖掘導論[M].北京:人民郵電出版社,2006.
〔5〕石志偉,劉濤,吳功宜.一種快速高效的文本分類方法[J].計算機工程與應用,2005,41(29):180-183.
〔6〕Chih-Chung Chang and Chih-Jen Lin,LIBSVM:a library for support vector machines,2001.Software available at http://www.csie.ntu.edu.tw/~cjlin/libsvm.
〔7〕Blei,D.M.,Ng,A.Y.,&Jordan,M.I.(2003).Latent Dirichlet Allocation.Journal of Machine Learning Research,3,993-1022.
T P 3 9 1
A
1673-260X(2011)04-0034-03
福建省教育廳 B 類科研項目(JB09235);寧德師范學院科研資助項目(2009303)
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
