神經網絡前向傳播在GPU上的實現*
2011-11-27 01:46:08劉進鋒
網絡安全與數據管理 2011年18期
劉進鋒,郭 雷
(西北工業大學 自動化學院,陜西 西安710129)
GPU(圖形處理器)是處理計算機圖形的專用設備。近十年來,由于高清晰度復雜圖形實時處理的需求,GPU發展成為高并行度、多線程、多核的處理器。目前主流GPU的運算能力已超過主流通用CPU,從發展趨勢上看將來差距會越來越大。GPU卓越的性能對開發GPGPU(使用GPU進行通用計算)非常具有吸引力。最初GPGPU需要將非圖形應用映射為圖形應用的方式,這個處理過程與圖形硬件緊密相關,程序實現非常困難。近年來,GPU的主要供應商NVIDIA提出了新的GPGPU模型,稱為 CUDA(統一計算設備架構)[1]。
CUDA是一種在NVIDIA公司的GPU上進行計算的新型的硬件和軟件架構,可以將GPU視為一個并行數據計算的設備,對所進行的計算給予分配和管理。在CUDA的架構中,這些計算不再像過去的GPGPU架構那樣必須將計算映射到圖形API中,開發者不需要去學習艱澀的顯示芯片的指令或是特殊的結構,因此開發門檻大大降低。CUDA的GPU編程語言基于標準的C語言,開發CUDA的應用程序較為方便。
在CUDA架構下,一個程序分為兩個部分:host端和device端。host端是指在CPU上執行的部分,而device端則是在GPU上執行的部分。device端的程序又稱為Kernel。通常host端程序會將數據準備好后,復制到顯卡的內存中,再由GPU執行device端程序,完成后再由host端程序將結果從顯卡的內存中取回。
在CUDA架構下,GPU執行時的最小單位是線程(thread)。幾個線程可以組成一個線程塊(block),每個線程都有自己的一份寄存器(register)和本地內存(local memory)空間。同一個線程塊中的每個線程則可以共享一份共享內存(shared memory)。此外,所有的線程都共享一份全局內存(global memory)、常量內存(constant memory)和紋理內存(texture memory)。
自從CUDA發布以來,大量應用問題使用CUDA技術取得了令人驚奇的效果,加速十幾倍甚至上百倍的實例很多。參考文獻[2]對這些應用有一個綜合介紹。
最適合利用 CUDA處理的問題,是可以大量并行化的問題,這樣能有效利用顯示芯片上的大量執行單元。使用 CUDA時,上千個線程同時執行是很正常的。如果問題不能大量并行化,使用 CUDA就不能達到最好的效率。參考文獻[3]通過許多成功應用CUDA加速的實例探討了CUDA的高效實現策略及應用范圍問題。
1 本文使用的神經網絡簡介
本文實驗選用的是一個較為復雜的用于手寫漢字識別的神經網絡[4-6]。該網絡是一種五層卷積神經網絡,結構如圖1所示。選擇這樣一個神經網絡基于兩點考慮:其一,過于簡單的神經網絡結構不易體現GPU計算的優勢;其二,此網絡的結構比較全面,在它上面實現的算法有一定的代表性,做一些修改就可以用在其他不同的神經網絡結構上。
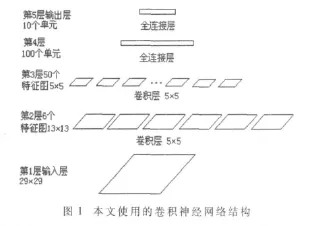
該神經網絡第一層輸入層是手寫數字的灰度圖像,圖像大小為29×29像素,這樣輸入層有 29×29=841個神經元。第二層是卷積層,由6個特征圖組成,每個特征圖的尺寸是13×13個神經元,每個神經元的值是由輸入圖像的13×13個位置(輸入圖像水平和垂直方向的29個位置間隔選擇13個)上作5×5的卷積得到。一個特征圖的卷積核相同,各特征圖的卷積核不同。這樣第二層有13×13×6=1014 個神經元,有(5×5+1)×6=156 個權值(每個5×5多加一個偏向權值,后面各層中權值數量計算公式中+1都是加一個偏向權值)。另外,因為1 014個神經元每個都有26個與輸入層的連接,所以從輸入層到第二層共有1014×26=26364個連接。這里就能看出卷積神經網絡共享權值的好處了:雖然有26 364個連接,但只需要156個權值來控制。第三層也是一個卷積層,它有50個特征圖構成,每個特征圖是 5×5大小,是從第二層的 6個 13×13的特征圖的相應區域作 5×5卷積得到。這樣第三層就有 5×5×50=1250 個神經元,(5×5+1)×6×50=7800個權值,1250×26=32500個與第二層的連接。第四層是有100個神經元的全連接層,因為是全連接,本層的每個神經元都與第三層的全部1 250個神經元連接,這樣所有的連接就有100×(1250+1)=125100個,有125 100個權值。第五層是輸出層,該層有10個全連接的單元,每個單元都與第四層的所有100個神經元連接,這樣本層就有 10×(100+1)=1010個連接,有 1010個權值。這10個神經元對應10個數字 ,其中對應于識別結果的一個神經元的輸出值為+1,其他9個神經元的輸出值為-1。
整個網絡總共有3 215個神經元,134 066個權值,184 974個連接。輸入層神經元數據和各層神經網絡的權值已知。
2 算法的實現
神經網絡前向傳播算法可以表示為:
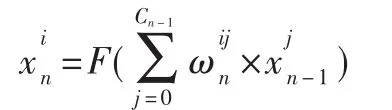
GPU上神經網絡前向傳播算法基本過程是逐層計算各層的所有神經元的值。
輸入層神經元值已知,其余每層有一個Kernel函數來計算該層的所有神經元的值,上述的神經網絡需要4個Kernel函數。并行計算只能體現在一層中,不同層之間沒有并行性。
首先將輸入層的神經元值和每層的權值保存在5個數組中,并從host內存傳遞到device內存。由于每層的權值是不變的,所以可以將這些權值傳遞到device的常量內存中,由于常量內存有cache,這比放到全局內存的存取速度要快很多。在device中為第二到第五層的神經元值分配內存空間,第一個Kernel函數根據輸入層的神經元值和權值計算第二層神經元值,第二個Kernel函數根據第二層的神經元值和權值計算第三層神經元值,如此往下,第四個Kernel函數計算出第五層即輸出層的值,然后將該值從device內存傳遞到host內存。神經網絡的連接體現在每個Kernel函數處理計算過程里。
計算第二層神經元值的基本Kernel函數的偽代碼如下:


該函數的輸入為第一層的神經元值數組Gn1和權值數組Gw1,輸出為第二層的神經元值數組Gn2。
因為第二層由6個特征圖構成,每個特征圖有13×13個神經元,所以這個函數在host端調用時,線程塊參數設置為6,線程參數設置為13×13,這樣一個線程塊處理一個特征圖,每個神經元值由一個線程處理,由第一層中取25個神經元乘以權值再加上一個偏向權值的累加得到。
這個函數的第1、2行得到線程塊號和線程號,第4行的templet數組是為了在輸入層中選擇25個值的模版。第5、6行的循環計算出激活值,第7行對該值進行激活運算,第8行將結果送到第二層的神經元值數組Gn2。
上述函數還可以修改的效率更高些,第4行的templet數組是默認分配在全局內存中的,而訪問全局內存需要相對較長的時間,因此有必要消除這種訪存時間消耗。通過將第 5、6行的for循環展開,templet[i]的值直接寫在代碼里,就既可以在程序中不要templet數組,又減少了循環判斷的時間代價。
對函數的4~6行進行修改,其他行不變。改變了的部分代碼如下:

第4行定義了一個在共享內存中的數組s1。將Gn1數組中的數據先傳到s1中,第6行就不再需要引用Gn1數組,而是使用數組s1。由于存取共享內存的速度比存取全局內存快得多,這種改進進一步提高了速度。
計算第三層神經元值的Kernel函數,基本結構與上述的函數類似。也可以使用類似處理方式進一步提高速度。該函數在host端調用時,線程塊數參數設置為50,線程參數設置為5×5。一個線程塊處理一個特征圖,每個神經元值由一個線程處理。
第三層到第四層是全連接層,計算第四層的Kernel函數可以有兩種實現方案。方案1:由于第四層有100個神經元,可以設計成有100個線程塊,每個線程塊只有一個線程,一個線程計算一個神經元的值。這樣一個線程計算量還是很大的,大約需要作1 250個乘法和加法。另外,每個線程塊只有一個線程,無法充分利用CUDA的Warps切換能力[1]。這種方案沒有完全發揮GPU的能力,因而效率不太高。方案 2:還是有 100個線程塊,每個線程塊有250個線程,250個線程計算一個神經元的值,每個線程作5次乘法和加法,最后由第一個線程將這些和累加,得到最終的值。這種方案效率較高。
計算第五層的神經元值需要約1 010次浮點乘法和加法,實驗證明該層由于計算量相對較小,體現不出在Kernel端計算的優勢,計算時間甚至比在host端更長。
3 實驗結果
本試驗使用機器的CPU是Intel Core 2 Duo E7400,時鐘頻率為2.8 GHz,內存為1 GB。GPU是NVIDIA GeForce GTX9800+,該GPU有128個頻率為1.836 GHz的流處理器,分為 16個SM,512 MB顯存。
GPU上算法實現采用上文描述的最優化的方案,即每層的權值放入device端的常量內存,函數中的循環展開,利用共享內存,計算第四層神經元值時采用方案2。
試驗結果如表1所示,分別給出了使用CPU和GPU計算本文神經網絡前向傳播時各層所用時間對比,這是經過三次試驗求得的平均值。GPU實現采用最優化的方案,CPU上的實現方法就是通常的神經網絡前向傳播算法,這里不再贅述。CPU上計算整個神經網絡前向傳播需要1.851 ms,GPU計算需要 0.272 ms,比CPU上計算快了約7倍。
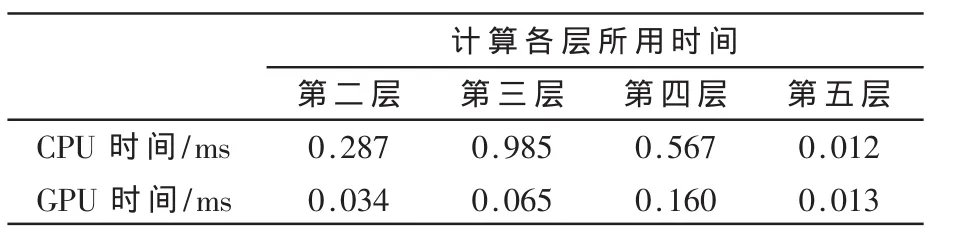
表1 試驗結果
本文對神經網絡的前向傳播在GPU上計算進行了研究,得到了比較滿意的結果。使用本方法需要注意以下幾個方面:
(1)GPU算法前期處理時要把一些數據從CPU裝入GPU,還需要在GPU上給一些數據分配內存空間,這些前期處理都要花費時間,所以如果只做一次神經網絡前向傳播運算,GPU上的實現可能比CPU上的還要慢,但由于前期處理只做一次,所以多次神經網絡前向傳播運算能體現出GPU運算的好處。這種情況可能出現在多個測試數據的驗證或計算神經網絡后向傳播時。
(2)當神經網絡規模較小時,可能GPU方法會比CPU方法慢,比如本網絡的最后一層的規模。
(3)有些應用問題在GPU上計算時速度能提高上百倍[3],而神經網絡在GPU上運算速度提高有限,這是因為神經網絡的并行性主要體現在同一層,總體并行性不太高。要想充分發揮GPU的運算能力,那些應用問題應該具有計算復雜度高、數據傳輸量少的特點,或者能修改原來的算法,使得計算-內存訪問比提高。
[1]NVIDIA Corporation.NVIDIA CUDA programming Guide Version 2.2[EB/OL],2009-04.http://developer.nvidia.com/cuda.
[2]RYOO S,RODRIGUES C I,BAGHSORKHI S S,et al.Optimization principles and application performance evalua-tion of a multithreaded GPU using CUDA[J].In Proceedings of ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming,2008:73-82.
[3]HWU W M,RODRIGUES C,RYOO S,et al.Compute unified device architecture application suitability[J].Computing in Science and Engineering,2009,11(3):16-26.
[4]LECUN Y,BOTTOU L,BENGIO Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[5]SIMARD P Y,STEINKRAUS D,PLATT J.Best practices for convolutional neural networks applied to visual document analysis[C].International Conference on Document Analysis and Recognition(ICDAR),IEEE Computer Society,Los Alamitos,2003:958-962.
[6]Mike O′Neill.Neural network for recognition of handwritten digits[EB/OL],2006-12.http://www.codeproject.com/KB/library/NeuralNetRecognition.aspx.
