校園網Web搜索引擎的設計與實現
2011-12-27 09:18:04夏敏捷
中原工學院學報 2011年5期
夏敏捷,徐 飛,夏 冰
(中原工學院 ,鄭州450007)
校園網Web搜索引擎的設計與實現
夏敏捷,徐 飛,夏 冰
(中原工學院 ,鄭州450007)
在研究Web搜索引擎發展的基礎上,結合對校園網搜索引擎具體需求的分析,介紹了校園網搜索引擎系統整個框架的設計及關鍵技術.應用該搜索系統可以有效提高站內搜索效率.
搜索引擎;網絡爬蟲;Lucene
隨著校園網建設的迅速發展,校園網內的信息內容正在以驚人的速度增加著.如何更全面、準確地獲取最新、最有效的信息,已經成為我們把握機遇、迎接挑戰和獲取成功的重要條件.目前雖然已經有了像Google、百度這樣優秀的通用搜索引擎,但是它們并不能適用于所有的情況和需要.對學術搜索來說,一個公平的排序結果是非常重要的.另外,由于互聯網上信息量巨大,遠遠超出哪怕是最大的一個搜索引擎可以完全搜集的能力范圍.因此,本著整合校園網資源的目的,為方便廣大師生對校園網信息的獲取和使用,本文設計并實現了一個靈活、可配置、具有良好可擴展性的校園網搜索引擎.
1 搜索引擎的發展
在國內,很多基于主題領域的小型搜索引擎得到很好的發展.例如,一些音樂搜索引擎以及醫藥方面的搜索引擎都有很好的應用;越來越多的學校、企業及比較大型的網站如BBS都開始建立了自己的搜索引擎.在國外,比較著名的有美國教育資源信息搜索的Ask-ERIC,實現醫藥文獻搜索的Highwire等.Google公司在2007年決定向小型網站提供專門的搜索服務.這些都表明,小型專用的搜索引擎將在人們獲取Web信息中發揮更重要的作用[1].
在小型搜索引擎快速發展的同時,越來越多的人致力于研究和開發這些小型搜索引擎技術,Lucene和Nutch是其中的代表成果.Lucene是一個高性能、純Java的全文檢索引擎,完全免費、開源;Lucene幾乎適合于任何需要全文檢索的應用,尤其是跨平臺的應用.Lucene為Nutch提供了文本索引和查詢服務的API,而Nutch在Lucene的基礎上實現了網頁收集與搜索[2].
小型搜索引擎與通用搜索引擎相比有很多優點,然而,由于它本身的信息量小,它不可能取代通用搜索引擎.但是,它是對通用搜索引擎的很好補充.隨著Web上信息的進一步擴大,小型搜索引擎也將會進一步發展,其中已經引起人們關注的垂直搜索引擎將在未來的信息搜索中發揮更大的作用.
2 校園網搜索引擎系統設計
本文旨在使用Lucene建立一個適合校園網使用的Web搜索引擎系統,實現對校園網上常用信息的檢索,能在較短時間內更新頁面信息,實現有效準確的中文分詞功能.本系統使用網絡爬蟲對校園網的網絡資源進行采集和周期性更新,利用Lucene對采集的信息資源進行索引和檢索,從而開發實現一個校園網Web搜索引擎系統.
系統主要由4個模塊組成:信息采集模塊、信息更新模塊、索引模塊、搜索模塊.其中索引模塊又分為3個部分:解析器(Parser)、分析器(Analyzer)和索引器(Indexer).
信息采集模塊主要是利用網絡爬蟲實現對校園網網頁信息的抓取.
信息更新模塊負責對已有Web信息資源進行周期性更新,以保證索引信息與 Web網站信息的一致性.
索引模塊負責對存儲到數據庫的網頁文本內容進行索引.
搜索模塊負責從索引庫中搜索包含查詢關鍵詞的文檔內容,并負責用戶從界面輸入查詢關鍵詞以及搜索結果信息的返回.校園網搜索引擎系統設計如圖1所示.
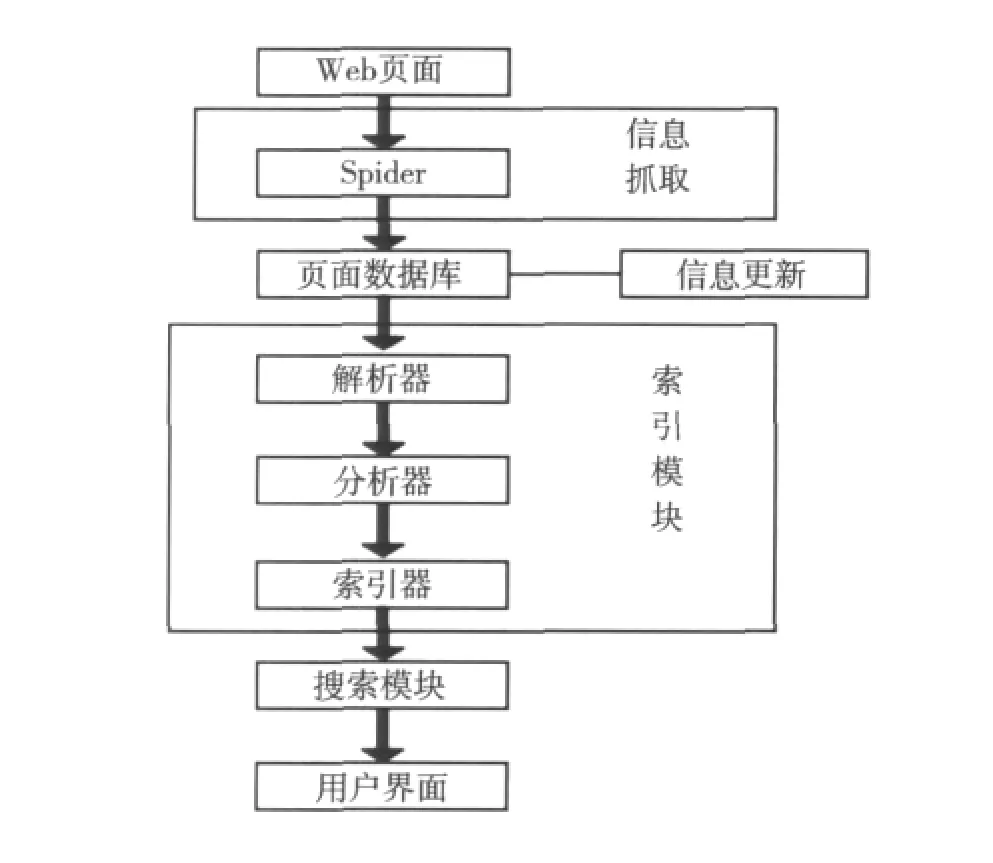
圖1 系統設計圖
3 校園網搜索引擎模塊設計
3.1 信息采集模塊設計
網絡爬蟲對整個校園網網站的網頁進行抓取,生成新的頁面集合并存儲到MySQL數據庫中.在抓取頁面的同時,獲取頁面的文本內容.由于Lucene只能對文本文件進行索引,要想將網頁內容加入到索引庫中,必須使用網絡爬蟲從校園網上抓取網頁URL、網頁文本內容、網頁標題,并保存在MySQL數據庫中,然后從MySQL數據庫中將網頁文本內容讀取出來以進行索引.
在使用網絡爬蟲抓取校園網的URL時,會發現重復URL抓取的現象,一個網頁會在多個網頁中含有對它的連接.為了避免在抓取網頁中出現死循環現象,我們在設計數據、存儲URL時使用唯一存儲,只存儲一次URL,如果有重復的URL出現,就不再往下抓取此網頁以及以下目錄的鏈接.頁面去重放在抓取之前,可以減少重復的索引,從而提高索引效率.
3.2 頁面更新模塊設計
在進行搜索時,人們總是希望能準確獲取最新的信息.而每次搜索結果里面總是有死鏈接或者信息明顯過時的頁面存在,也有一些新出現的頁面不能被搜索到.頁面更新的功能就是盡量保證本地頁面內容和實際頁面內容的一致性.做法就是在信息提取完成后的一段時間(例如3天)后,搜索引擎調用網絡爬蟲對整個校園網網站的網頁重新抓取,生成新的頁面集合來取代舊的頁面集合.
3.3 索引模塊設計
索引模塊運行過程分為3個階段:文本提取、分析文本和建立索引,如圖2所示.
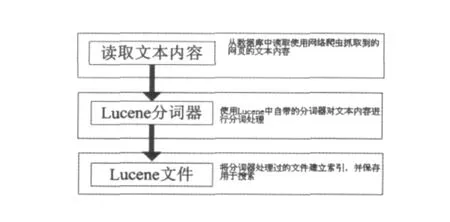
圖2 索引模塊流程
(1)文本提取.文本提取從MySQL數據庫中將網頁文本內容、網頁URL、網頁標題等讀取出來并轉換成Lucene的Field.提取網頁文本之后,就要對文本內容進行分析了.
(2)文本分析.文本分析在Lucene中是指將Field文本轉換成最基本的索引單元項Term.對于不同的語言,分析器要完成的功能是不同的.譬如對英文來說,要將字母轉換成小寫、除去符號等.在校園網 Web搜索引擎中,主要針對的是中文搜索,分析器需要實現的主要是中文分詞.在英文中,單詞之間是以空格作為自然分界符的.而中文只是字、句和段可以通過明顯的分界符來簡單劃分,唯獨詞沒有一個形式上的分界符.雖然英文也同樣存在短語之間的劃分問題,但是在詞這一層上,中文比英文要復雜的多.
分詞就是將連續的字序列按照一定的規范重新組合成詞序列的過程.分詞是網頁分析索引的基礎,分詞的準確性對搜索引擎來說十分重要.但是如果分詞速度太慢,即使再準確,對于搜索引擎來說也是不可用的,因為搜索引擎需要處理很多的網頁,如果分詞消耗的時間過長,會嚴重影響搜索引擎內容更新的速度.因此,搜索引擎對于分詞的準確率和速率都提出了很高的要求[3-4].
使用Lucene時,選擇一個合適的分析器是非常關鍵的.對分析器的選擇沒有唯一的標準.本系統采用的分詞器是極易分詞器mmseg4j.從網站上下載極易分詞包,它包含詞庫和分詞jar包.使用時在Tomcat Web服務器的安裝目錄下找到Webapps下本系統所在文件夾,在其下新建一個classes文件夾,用來存放詞典和字庫,將分詞包中的data和dic文件復制到classes文件中,接著在 WEB-INF下的lib中添加jeanalysis-qw-1.5.3.jar文件.
最后用文本編輯器打開schema.xml文件,在<types></types>中加入新的字段類型--text_chinese,并在分詞屬性中加入類文件的名稱"jeasy.analysis.MMAnalyzer",表示在創建索引和查詢索引時都使用的是極易中文分詞器.
schema.xml文件如下:
<fieldType name="text_chinese"class="solr.TextField">
<analyzer class="jeasy.analysis.MMAnalyzer"/>
</fieldType>
(3)索引的建立.索引就是為了快速搜索大量的文本.先將文件轉化成一個快速搜索的數據結構,從而不需要進行緩慢的順序掃描,這個轉化過程稱為建立索引.
Lucene采用的是倒排索引結構[5],將輸入字符流存儲在一個反索引的數據結構中.這個數據結構在允許關鍵詞查詢的同時,有效地利用了磁盤空間.這個結構使用從輸入中提取的單詞而不是處理的文檔作為查詢的入口.也就是說,這個結構為提供快速查詢做了優化,即形成關鍵詞到文檔號的映射.僅僅知道關鍵詞在哪些文檔中還不夠,還需要知道關鍵詞在文檔中出現的次數和出現的位置.通常有2種位置:字符位置和關鍵詞位置.字符位置是記錄關鍵詞在文檔中是第幾個字符(優點是關鍵詞高亮顯示時定位快);關鍵詞位置是記錄關鍵詞在文檔中是第幾個關鍵詞(優點是節約索引空間、詞組查詢快).Lucene同時使用了這2種位置.
以上就是Lucene索引結構中最核心的部分.關鍵詞是按照字符順序排列的,Lucene可以用二元搜索算法快速定位關鍵詞.
為了減小索引文件的大小,Lucene對索引還使用了壓縮技術.首先,對文檔中的關鍵詞進行壓縮,將關鍵詞壓縮為前綴長度加后綴;其次,大量用到的是對數字的壓縮,數字只保存與上一個值的差值,這樣也減小數字的長度,進而減少保存該數字需要的字節數.在這種索引結構下,文檔通常非常小,因而,整個過程的時間是毫秒級的.
3.4 搜索模塊的設計
對需要的網頁文件索引完畢以后,就可以對用戶提供搜索服務了.搜索模塊負責接受用戶提交的檢索請求,并根據請求訪問相應的Lucene索引數據庫,最后將結果集按照相關度排序后返回給用戶.搜索的處理流程如圖3所示.
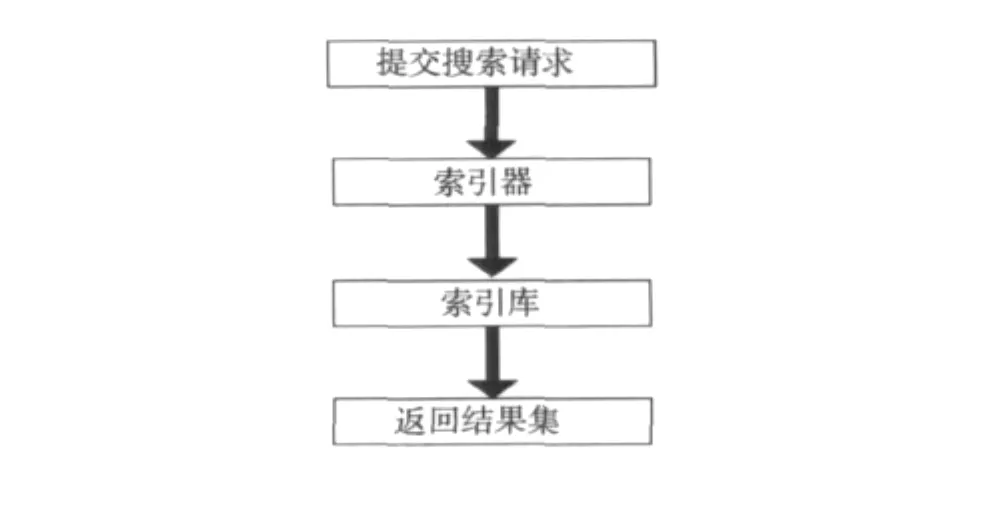
圖3 搜索流程圖
用戶通過用戶界面提出搜索請求,Lucene索引器接受用戶請求,查找本地索引庫,找到與輸入相關的內容,按照某種算法排序后將相關結果信息返回給用戶.這里主要利用Servlet技術實現,用戶通過POST方法從客戶端向服務器端提交查詢條件,服務器端通過Tomcat的Servlet容器接收并分析提交的參數,再調用系統的搜索模塊進行搜索操作.最后把搜索的結果以HTTP消息包的形式發送給客戶端,從而完成一次搜索操作.搜索結果頁面如圖4所示.
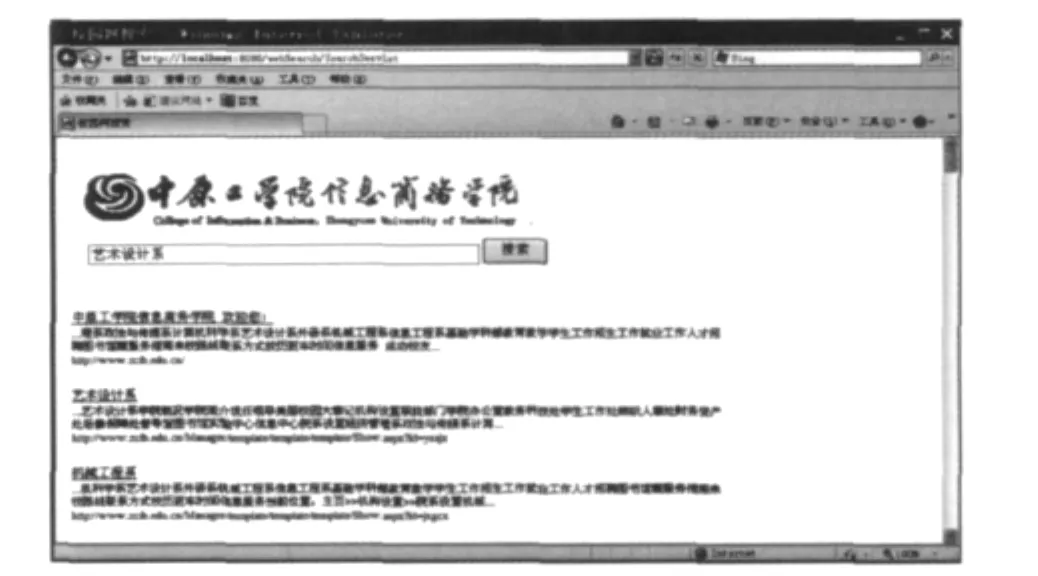
圖4 搜索結果頁面
4 結 語
本校園網Web搜索引擎在配置Tomcat服務器后即可投入使用,但要成為一個好的和有用的校園網搜索引擎和教育信息搜索引擎,還面臨著許多挑戰.首先,為進一步提高檢索準確性,針對中文的特點,需解決人名、地名、專業詞匯、新生詞匯的識別問題,實現一個自動更新的詞典,提高中文分詞的準確度;其次需要為校園網用戶提供個性化檢索、個性化排序等功能,滿足用戶多樣的信息需求;其他如網頁重要性評估、結果得分算法、用戶行為分析等問題.這些問題有待進一步研究和改進,從而提高校園網Web搜索用戶獲取知識與信息的效率.
[1] 孟曉明.淺談搜索引擎及其發展趨勢[J].計算機應用,2004(8):34-36.
[2] 馮斌.基于Lucene小型搜索引擎的研究與實現[D].武漢:武漢理工大學,2008.
[3] 陳康,滕育平.中文信息檢索引擎的分詞與檢索技術[J].計算機應用,2004(7):30-33.
[4] 蔡勇智.基于最大匹配分詞算法的中文詞組粗分模型[J].計算機應用,2006(9):12-15.
[5] 胡俊,李星.校園網信息資源搜索引擎的研究與實現[J].計算機工程與設計,2006(7):22-26.
The Design and Implementation of Campus Web Search Engine
XIA Min-jie,XU Fei,XIA Bing
(Zhongyuan University of Technology,Zhengzhou 450007,China)
This paper studies the development of Web search engine.Based on the combination of the specific needs of the campus network search engines,the framework design of campus network search engine system and key technologies are introduced.Application of the search system can effectively improve the efficiency of the web site search.
search engine;Web crawler;Lucene
TP391
A
10.3969/j.issn.1671-6906.2011.05.007
1671-6906(2011)05-0027-04
2011-07-30
河南省科技攻關計劃項目(092102310038;092102210029)
夏敏捷(1974-),男,河南三門峽人,副教授.
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生(2015年12期)2015-11-10 05:13:38
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
語文知識(2014年1期)2014-02-28 21:59:13
電腦愛好者(2011年11期)2011-06-22 08:20:18
