聚類挖掘在高校圖書館管理系統中的應用
2012-06-02 09:32:08韓存鴿
重慶理工大學學報(自然科學) 2012年11期
韓存鴿
(武夷學院數學與計算機系,福建武夷山 354300)
目前,基本上所有的高校圖書館都建立了各自的業務處理系統和圖書館辦公自動化系統,這些系統對提高高校圖書館的工作效率、減少重復性工作起到了積極作用,推動了高校圖書館事業的發展。
但是大多數圖書館數據庫系統只能對現有數據進行查詢、錄入和存取等比較簡單的操作,不能發現數據中隱藏的關系和規則,不能對圖書館所存數據的潛在信息以及讀者的個人信息進行高效的分析,并比較準確地預測其發展趨勢,從而導致“數據豐富,但信息貧乏”的局面。本文使用聚類挖掘對武夷學院圖書館管理的流通數據進行分析,給廣大師生提供個性化的服務。
1 聚類挖掘基本理論
聚類分析是數據挖掘研究領域中一個非常活躍的研究課題。目前聚類分析已被廣泛應用于許多研究領域,包括數據挖掘、圖像分割、模式識別、市場研究等領域[1-6]。
1.1 概念及主要算法
所謂聚類就是將物理或抽象的集合分成相似的對象類的過程。簇是數據對象的集合,這些對象與同一個簇中的對象彼此相似,與其他簇中的對象相異[7]。在大多數情況下,一個簇中的對象可以被作為一個組來處理。作為數據挖掘的一個功能,聚類分析能作為一個獨立的工具來獲得數據分布情況,并觀察每個簇的特點,集中對特定的某些簇做進一步的分析。
目前文獻中存在大量的聚類算法。比較著名的有 K-MEANS、PAM、CLARANS、BIRCH、CURE、SCAN、OPTICS、CLIQUE CABOSFV 等。各類數據挖掘軟件中比較經典的為K-means模型。
1.2 聚類分析過程
首先,輸入樣本集合,然后對樣本進行預處理,通過對不同屬性的樣本進行選擇、抽取,根據聚類分析的數據類型要求形成樣本表示,再根據樣本間的相似性進行分組聚類。一般情況,聚類是一個循環漸近的過程,需要對樣本間的相似性進行比較,以改善不同的分組情況,使同組對象彼此更相似,而與其他組的對象更相異[8]。圖1為聚類分析的過程。
1.3 K-means算法
K-means算法是很典型的基于距離的聚類算法,采用距離作為相似性的評價指標,即認為2個對象的距離越近,其相似性就越大。
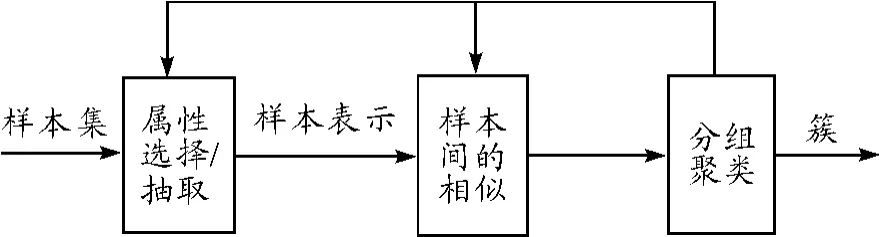
圖1 聚類分析的過程
1.3.1 K-means算法的處理流程
首先,隨機地選擇k個對象,每個對象初始地代表了一個簇的平均值或中心。對剩余的每個對象,根據其與各個簇均值的距離(一般用歐氏距離)將它派給最近的簇。然后計算每個簇的新均值。這個過程不斷重復,直到準則函數收斂。通常采用平方誤差準則,其定義為[8]其中:E是數據庫中所有對象的平方誤差總和;p是空間中的點,表示給定的數據對象;mi是簇Ci的平均值(p和mi都是多維的)。這個準則使生成的結果簇盡可能地緊湊和獨立。

1.3.2 K 均值劃分算法
Input:K(簇的數目),D(包含n個對象的數據集)
Output:K個簇的集合
方法:
1)從D中任意選擇k個對象作為初始簇中心;
2)repeat;
3)根據簇中對象的均值,將每個對象(再)指派到最相似的簇;
4)更新簇均值,即計算每個簇中對象的均值;
5)until不再發生變化。
2 聚類挖掘數據的采集及處理
2.1 聚類挖掘數據采集
武夷學院圖書館使用的是大連網信軟件公司研制妙思文獻管理集成系統。該系統全面覆蓋了圖書館自動化業務的功能需求,核心功能包括圖書和連續出版物的采購、編目、典藏以及流通管理系統,支持校園一卡通。
2.1.1 讀者聚類數據采集
從武夷學院圖書館管理系統中聚類挖掘所需的信息,分別形成ltxxb(流通信息表)、dzxxb(讀者信息表)、wxxxb(文獻信息表)、tmxxb(條碼信息表)4個表。本次研究是在Visual FoxPro 6.0環境下進行數據的處理,具體SQL查詢語句如下:
select ltxxb.讀者證號,ltxxb.讀者姓名,dzxxb.讀者單位,借出時刻,wxxxb.索取號;
from ltxxb,dzxxb,wxxxb,tmxxb into table alldata;
where ltxxb.條碼 =wxxxb.條碼 and tmxxb.索取號=wxxxb.索取號 and ltxxb.讀者證號=dzxxb.讀者證號 and借出時刻 between{^2006.08.01}and{^2007.07.31 23:00:00}
利用Visual FoxPro語言輸入SQL命令,統計每一位讀者1年內的借閱數量。在VFP6.0中具體SQL查詢語句如下:
select讀者證號,讀者單位,count(讀者證號)as借閱冊數;
from alldata into table jieyue;
group by讀者證號;
order by借閱冊數desc
讀者借閱數據共有9 826條記錄。
2.1.2 圖書流通量數據采集
先從 ltxxb中統計出每種書的流通量,在VFP6.0中具體SQL查詢語句如下:
select控制號,count(讀者證號)as流通量;
from ltxxb into table tushult;
group by控制號;
order by流通量desc
共有22 636條記錄。
然后從tushult和wxxxb中顯示每種借閱書籍的相關信息,此處使用wxxxb表和tushult表進行左連接,目的是找出一年未曾借出的書籍,SQL命令如下:
select流通量,復本數,索取號,正題名,出版日期,標準編號,文獻類型;
from wxxxb into table tushujl;
left join tushult on tushult.控制號 =wxxxb.控制號;
order by流通量desc
圖書流通數據共有235 869條記錄。
2.2 聚類挖掘數據的處理
2.2.1 空值作刪除處理
做聚類分析的2類數據讀者借閱量和圖書流通量中的所有屬性都不能為空,如果出現空值,則刪除這條記錄。如jieyue表中由于有些臨時讀者信息被刪除,出現讀者證號為空的現象,所以必需去掉這部分空值信息;又如在tushujl數據表中,描述圖書信息的正題名字段不能出現空值,如發現則應剔除。對于tushujl表中流通量為“.null.”的記錄,在刪除之前把一年來未流通的書籍信息保存在單獨的一個表中(后面要用),最終形成待挖掘的22 635條記錄。
2.2.2 噪聲處理
分析 wxxxb、tmxxb、ltxxb 、dzxxb四個數據表的記錄,發現存在一些影響挖掘結果的數據。如在流通量數據表中,一些復本數超過100的為非正常數據,轉換成20~30復本數。一些不流通的圖書,如工具書閱覽室內的圖書等應排除,以免影響聚類結果。在借閱數據表中,有的讀者“一卡通”借書證掛失補辦了,造成新舊證號都有借閱信息,影響了讀者借閱情況的挖掘,對這些記錄應合并為1條。
3 在Clementine中實施聚類挖掘及結果分析
使用 Clementine 挖掘工具[9-10]K-means模型進行聚類分析,從讀者的借閱冊數和圖書流通量2個角度進行聚類分析,聚類結果表示為圖書館的圖書推薦。
3.1 讀者聚類挖掘及結果分析
在Clementine中首先應該導入待分析數據jieyue.xls(在 Visual FoxPro 中將 jieyue.dbf導出成jieyue.xls),使用type節點對數據的屬性進行設置。這里針對讀者的借閱冊數進行分類,所以,只有借閱冊數字段方向為輸入,讀者證號、讀者單位、讀者姓名3個字段都為無。使用Clementine進行聚類分析,有3種模型可供選擇,分別是“神經網絡”、“K均值”、“兩步”聚類模型,本文選擇經典的“K-means”模型進行聚類挖掘。在該模型的屬性設置上,聚類數k=3,分別為“活躍讀者”“消極讀者”“一般讀者”,最后將聚類結果以表格形式顯示出來。從讀者借閱冊數角度進行聚類分析的整個流程如圖2所示。以表格形式顯示聚類結果,部分數據如圖3所示。
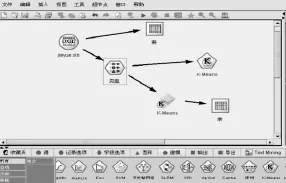
圖2 讀者聚類挖掘流程
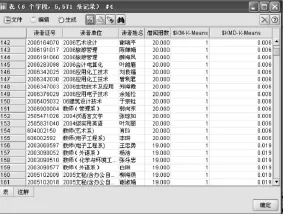
圖3 以表格方式顯示讀者聚類結果中部分數據
以上的挖掘僅從讀者的借閱冊數角度來衡量讀者的需求。根據聚類結果,可以適當為活躍型讀者提供一定的便利,比如增加這些讀者的允借冊數,而不是使用同一標準對待不同的讀者,為讀者提供更加便利的服務。對一般型讀者,可以進一步挖掘他們的借閱興趣,為他們提供更主動的推薦服務。而對那些消極讀者,圖書館可以適當地開展圖書宣傳,使他們轉消極為積極,提高圖書館的利用率。
3.2 圖書聚類挖掘及結果分析
在Clementine軟件中導入待分析數據tushujl.xls(在Visual FoxPro中將tushujl.dbf導出成tushujl.xls),使用type節點對數據的屬性進行設置,這里針對讀者的圖書流通量進行分類,所以,在type節點設置流通量字段方向為輸入,復本數、索取號、正題名、出版日期、標準編號、文獻類型6個字段方向都為無。使用Clementine進行聚類分析。本文繼續選擇“K-means”模型進行聚類挖掘。在該模型的屬性設置上,聚類數k=3,分別為“熱門書”“冷門書”“一般書”,最后將聚類結果以表格形式顯示出來。從圖書流通量角度進行聚類分析的整個流程與讀者聚類挖掘流程相似,這里不再列出。聚類挖掘的最終結果如圖4所示。
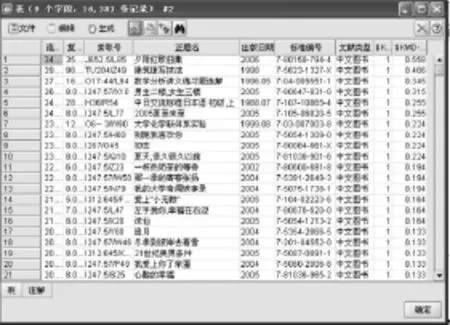
圖4 圖書流通量聚類結果中部分數據
根據對圖書聚類挖掘的結果,對那些熱門書(圖4中類別為1的圖書)建議圖書館可以專門設一個“熱門借書區”,方便讀者快速查找想借閱的圖書。而將一些“冷門書”可以做相關處理,比如文獻剔舊或下架,為圖書館節省藏書空間。同時那些復本量過大的”冷門書”(在聚類結果中類別為2的圖書)也可以為圖書采購部門提供參考。還有一部分未流通的書籍(流通量為.null.),圖書館工作人員可以做適當分析,對那些新采購的書籍可以多做宣傳,增加圖書利用率,而對那些舊的書籍,可以做適當剔除。
4 結束語
本文對武夷學院圖書館提供的流通數據進行了處理,主要采集讀者借閱冊數和圖書流通量2類數據。在Clementine中使用K-means模型進行聚類分析,從讀者的借閱冊數角度進行分類,將讀者劃分成“活躍讀者”“消極讀者”及“一般讀者”3類;根據圖書流通量進行分類,將圖書分成“熱門書”“冷門書”及“一般書”3類。根據聚類挖掘的結果,為不同類的讀者提供不同的服務,針對不同類的圖書采取相應的措施。
[1]蘇靜.基于聚類分析的河南城鄉一體化區域差異研究[J].安徽農業科學,2011(21):13224 -13225.
[2]楊軍,鞏玨,鄧文兵.火炮射擊精度的模糊等價關系聚類分析[J].四川兵工學報,2010(1):28 -29,37.
[3]余肖生,司新霞.基于聚類分析的元搜索引擎模型[J].重慶理工大學學報:自然科學版,2011(6):69-72.
[4]陳桂枝.湖北省縣域城鎮化水平的聚類分析[J].安徽農業科學,2011(29):18352-18354.
[5]李鳳蘭,樊逾,蘇理云.層次聚類的重慶市高校圖書館分類評估[J].重慶理工大學學報:自然科學版,2011(9):121-126.
[6]張林林,周毅,周瑞有,等.對空目標射擊有利度模糊聚類分析[J].四川兵工學報,2010(12):145-146.
[7]Han jiawei,Micheline,Kamber.數據挖掘概念與技術[M].范明,孟小峰,譯.北京:機械工業出版社,2006.
[8]陸云.聚類分析數據挖掘方法的研究應用[D].合肥:安徽大學,2007.
[9]岳小婷.數據挖掘工具Clementine應用[J].牡丹江大學學報,2007(4):103-105.
[10]劉利俊.利用Clementine進行試卷質量分析[J].現代計算機,2008(5):115-117.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
文苑(2019年20期)2019-11-16 08:52:12
文苑(2018年17期)2018-11-09 01:29:40
小太陽畫報(2018年1期)2018-05-14 17:19:25
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
信息通信技術(2015年6期)2015-12-26 01:16:46
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
小天使·一年級語數英綜合(2014年8期)2014-06-26 14:42:04
