模糊學習算法機器人相互協作模型研究
2012-08-26 08:05:38吳永琢
制造業自動化 2012年18期
吳永琢
WU Yong-zhuo
(青島酒店管理職業技術學院,青島 266100)
0 引言
在多機器人系統中逐漸采用多智能體技術,例如足球機器人就是其典型。它要求在復雜環境下,實現機器人的控制和相互協作。行為學習能夠有效提高機器人的適應能力,傳統的方式得到的信號并不理想。決策體系結構是整個系統的關鍵,本文選擇了強化學習算法,同時引入了具有專家經驗的模糊推理來彌補Q學習收斂性較差的缺點。通過建立模糊規則庫,并且根據狀態和動作不斷調整Q學習參數,提高決策系統的自適應能力和速度。通過仿真實驗,證明模糊Q學習算法的效果。
1 決策結構模型
決策系統通過感知器接收視覺系統收集的賽場的綜合信息,并分析信息、建立規則庫、Q學習、決定策略,最后將它們發送給通信系統。機器人的決策系統結構如圖1所示,包括:模糊化模塊、模糊規則庫、Q學習單元、行為融合等。它主要負責決策進攻、防守,分析實時的現場環境、對方策略,利用模糊的Q學習算法對決策模塊進行優化,然后將指令發送給機器人,控制它們的行動方式是進攻或避障。

圖1 決策模型結構圖
2 Q學習算法
強化學習是一種機器學習方法,是從環境到行為的映射學習,在機器人、智能控制等領域有許多應用。強化學習通過動作-評價獲取知識,不斷改進方案來適應周圍環境。Q學習算法是強化學習中的一種,它和模型無關。
Q 學習方法的待學習目標函數用Q(s, a)表示,計算公式為:

其中0≤g≤1,r(s, a)表示立即回報,V×(s)是最優策略值。
在 Q學習中選擇動作采用概率方法,選擇動作ai的概率表示為:

將評估函數推導后得到:
進入老齡化社會以來,福利國家的經驗促使中國政府也認識到國家必須為日益增多的老年人提供適當的生活保障,承擔起必要的照顧和幫助老年人的責任。2000年開始采取一系列措施解決老年人的養老問題,其中最重要的就是調動和引導社會力量提供老年服務。而這個階段與改革開放初期福利化改革的根本區別在于強化國家責任和推進社會化進程的并行及有效平衡。養老服務業管理體制的核心是理順和規范政府和社會的關系,既要充分發揮政府的主導作用,又要充分發揮社會力量的主體作用;政府部門職責權限邊界明確,社會力量權利義務具體清晰。
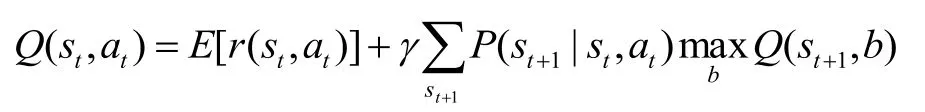

當Agent 應用在空間連續的環境,Q學習算法在連續的狀態空間和動作空間的離散化, 效率低、收斂慢,因此本文提出基于模糊的Q學習算法來處理例如足球機器人比賽等多人相互協作的狀態。
3 模糊Q學習算法和實現
足球賽場情況瞬息萬變,因此狀態空間數據量龐大,用Q學習算法會需要比較長的學習過程,因此本文在Q學習算法上將其優化,通過建立一個模糊規則庫,將龐大的實際狀態轉化成為數不多的模糊狀態,大大降低了狀態空間數據的大小,從而提升學習速度。
3.1 算法設計
采用IF_THEN的模糊規則,在agent受到狀態向量x后,利用模糊推理方法計算輸出空間的每一分量權值:
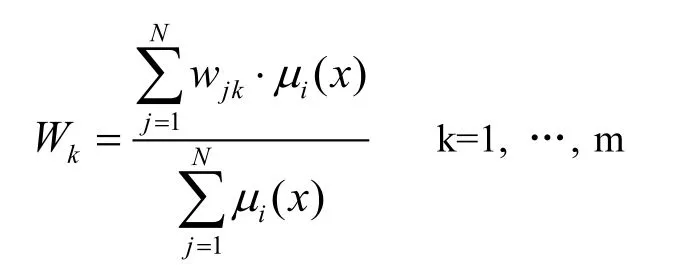
mi(x)表示IF_THEN規則里x的隸屬度。動作選擇采用模糊推理的方法,實行利用策略。當動作由agent執行以后,環境會給agent提供獎懲信號。假設收到獎勵信號r,那么模糊規則的權值表示:
其中r表示受到的獎勵,wmax是wk的最大值,a'jk表示自適應學習率。
建立的模糊規則表如表1所示。
3.2 算法的執行
Q學習的過程為:
1)觀察目前的狀態s;
2)通過計算狀態被選中的概率,選擇確定并且執行一個動作a;

公式中,T表示溫度,其值的大小表示隨機程度,值越大表示隨機性就大。初始學習時,T值偏大,隨著學習的深入,T值就逐漸降低來保證學習的良好效果。
3)觀察下一個新狀態s';
4)從環境中收到一個回報、強化的信號r;
5)根據狀態和動作相應的調整Q值;
a表示狀態動作被選頻率,系數g=0.9。根據Q值來調整行為融合的加權值l。等到學習結束以后,l就按照貪婪策略來取值,Q值最大的就是對應l的加權值。
6)新狀態滿足條件,則結束本次學習;否則返回第2步執行。
4 仿真實驗及結果
該方法的實驗是在機器人足球仿真平臺Robot Soccer上。在實驗時的主要參數設為:學習率初始設為0.8,折扣因子0.9,選擇動作時按照隨機策略。

圖2 Q學習曲線圖

表1 模糊規則表
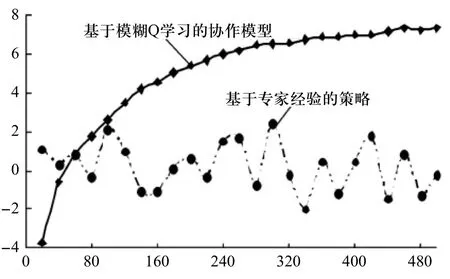
圖3 凈勝球統計對比圖
圖2表示的是機器人的進攻策略Q值,可以發現學習步數的增加,Q值迅速上升,到300步左右時,Q值就基本穩定在0.35。可見,模糊Q學習效果好、速度快。
接著分別采用傳統的經驗策略和模糊Q學習算法策略兩種方式進行凈勝球比賽統計,結果如圖3所示。
在圖3中進行了500場次的比賽,統計結果表明,傳統的按照專家經驗的凈勝球明顯沒有優勢和規律性,基本上在0上下震蕩。而模糊Q學習模型就呈上升趨勢,剛開始學習的階段,輸的比較多,沒有經驗的策略來得好。這說明系統還在學習,但隨著比賽場次的增加,Q學習的不斷改進開始逐漸顯示其優勢了,曲線明顯上升,凈勝球開始變成正值。到后來曲線走向開始變得平緩,是因為采用模糊Q學習方法后已經學到了比賽對方的大部分策略。實驗結果表明,模糊Q學習策略很有效。
5 結束語
多機器人相互協作問題是機器人技術中的重要課題,本人設計了一個決策系統模型,首先分析了傳統Q學習算法并指出其學習速度慢、收斂性差的不足,提出了模糊Q學習算法,建立了模糊規則庫,將眾多的實際狀態映射成不多的模糊狀態,減小了狀態空間又提高了速度;然后設計了算法的學習過程等;最后通過仿真平臺Robot Soccer將傳統的經驗策略和模糊Q學習策略比較,實驗結果表明模糊Q學習算法的速度比較快、效果更好。
[1]張汝波, 楊廣銘. Q學習及其在智能機器人局部路徑規劃中的應用研究[J]. 計算機研究與發展, 1999, 36(12):1430-1436.
[2]劉金餛. 機器人控制系統的設計與Matlab仿真[M]. 北京:清華大學出版社, 2008.
[3]vincente Feliu, Jose A.Somolinos, Andres Garcia.Inverse Dynamics Based ControI System for a Three-Degree-of-reedom Flexible Arm[J]. IEEE Trans.on Robotics and Auomation. 2003. 12(6): 1007-1014.
[4]Chang Deng. Meng Joo Er. Automatic generation of fuzzy inference systems by dynamic fuzzy Q-learning[C].Systems, Man and Cybernetics,2003. IEEE International Conference on, Volume:4, Oct. 5-8, 2003, 3206-321.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學大世界(2018年1期)2018-04-12 05:39:14
Coco薇(2017年11期)2018-01-03 20:59:57
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
