基于關聯詞的主題模型語義標注
2012-09-24 13:45:14周亦鵬杜軍平
智能系統學報 2012年4期
周亦鵬,杜軍平
(1.北京工商大學計算機與信息工程學院,北京 100048;2.北京郵電大學智能通信軟件與多媒體北京市重點實驗室,北京 100876)
主題分析通常采用概率生成模型,如LDA、PLSA等方法,以語義詞概率分布的形式描述主題[1-2],這使得一般用戶較難理解主題的內容.通常的方法是取概率較高的若干個語義詞來表示主題含義[3],但這種方法也常常不能準確表示整個分布所覆蓋的全部語義.因此,提出一種主題模型的自動標注方法,提取具有一定語義覆蓋度和區分度的主題關聯詞來描述主題的內容.
1 主題模型的語義標注
主題模型的自動語義標注通常包括2個步驟:首先構造能夠表達各種主題語義的候選標簽集,標簽可以是詞、短語,也可以是句子;然后,為不同的主題模型選擇與其語義相關的一個或多個標簽進行標注.最常用的方法是最大概率主題詞標注[4],這種方法的標簽集由從文檔中抽取的單個詞語構成,標簽的選擇是根據詞語在主題模型當中的分布概率來決定的.
相對于單個詞語的標注方法,采用短語作為標簽進行標注更容易表達主題模型的語義,因此需要生成短語標簽集合.常用的短語生成方法是基于統計模型的短語抽取[5-6],即根據同現概率獲得同現詞,并通過互信息或χ2測試從文本集中抽取可能的短語.但是,這些方法會受到同義詞等問題的影響,因此抽取出的標簽會出現語義重復問題,并且僅僅根據概率統計獲得的標簽也存在語義相關性低或語義覆蓋性低的問題.此外,如果選擇多個標簽對主題模型進行標注,還存在如何比較多標簽與主題模型的語義相關度、語義覆蓋度以及標簽間的語義區分度等問題.本文提出一種基于關聯詞的主題模型自動語義標注方法,其框架如圖1所示.
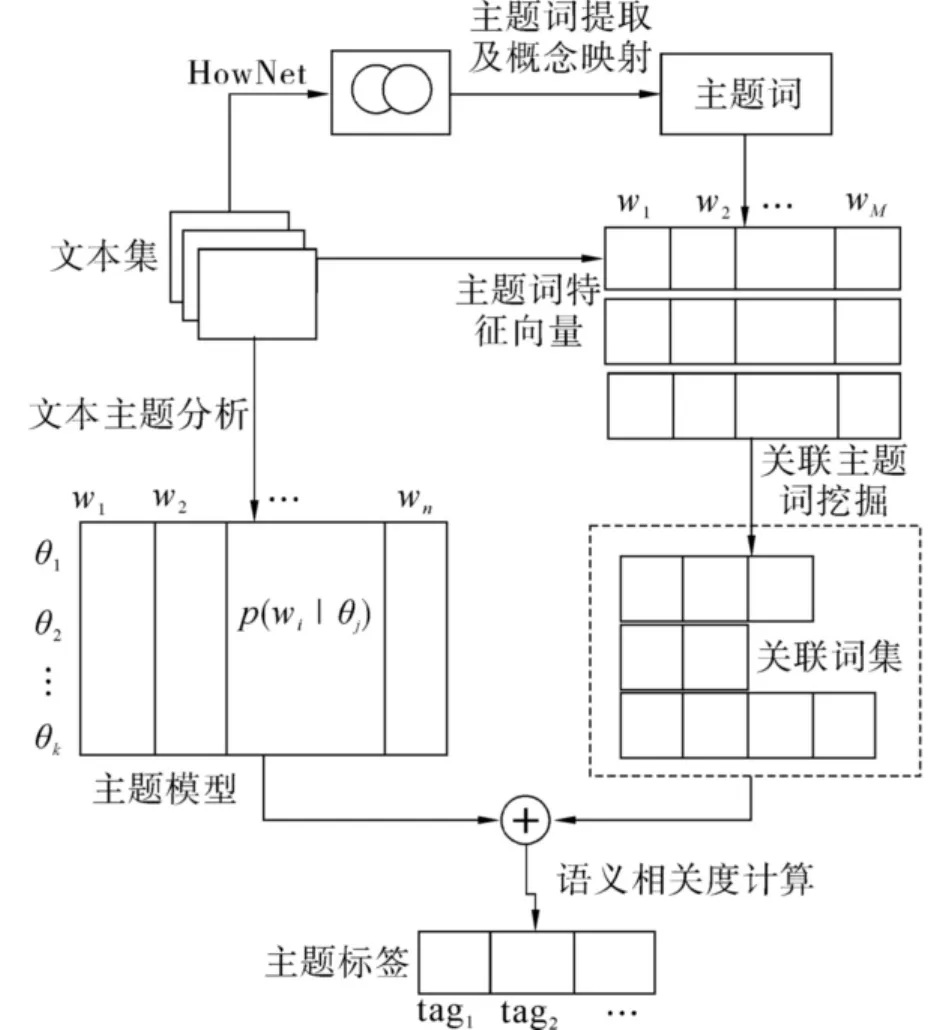
圖1 基于關聯詞的主題模型語義標注框架Fig.1 Framework of topic model tagging based on associated words
首先從參考文本集中抽取詞語,并根據語言本體將其映射為義原,實現詞語在概念上的歸并,從而獲得描述語義概念的主題詞,同時主題模型也從一般的詞語分布轉換為概念主題詞分布;然后根據實體、環境、活動等不同語義類別對概念主題詞進行分類,同時采用基于語義分類的關聯規則挖掘獲得具有語義關聯的主題詞,從而建立候選標簽集;最后,將標簽也以主題詞概率分布的形式進行描述,并計算其與主題模型的語義相關度,選擇具有高語義覆蓋度和區分度的多個標簽進行標注.
2 關聯主題詞的生成
2.1 主題詞的語義概念
關聯詞是依據上下文關系經常搭配使用的詞,在自然語言中,為了表達的需要,文本中常常會出現大量關聯詞.例如,在旅游信息中,“杭州”與“西湖”同時出現的幾率非常大,在食品安全事件中,“嬰兒”、“奶粉”與“三聚氰胺”同時出現的幾率較大.如果將這些關聯詞作為多個語義單元,一方面會增加主題模型的維數,另一方面也降低了主題模型對文檔的表達精度.雖然文本特征抽取可以通過預先設定的閾值來降低特征向量的維數,但它不是在保證語義精度的前提下,因此常常適得其反.
而在另一方面,為了解決主題的表達問題,也必須分析詞與詞之間的聯系,不單是對文本中詞的概率統計描述更應從語義上加以理解,此時就需要將具有語義關聯性的詞語抽取出來用于描述主題的內容.因此,利用關聯規則挖掘構造關聯詞集是一個簡單可行的方法,挖掘具有關聯性的詞語作為一個語義單元,既可以實現特征向量的降維,又可以增大主題表達的準確性.使用關聯詞集合可以有效地對文本特征空間的關聯詞進行歸并,改進主題標注的效率和精度.
構造關聯主題詞集合需要解決2個問題:
1)同義詞問題.由于中文文本存在語法修飾,不同的詞匯表示相同的概念,因此,關聯規則算法無法根據中文文本中的深層語義信息挖掘關聯詞,影響了關聯詞歸并的質量.
2)語義相關性問題.雖然關聯規則挖掘可以發現特征詞的同現關系,但因為主要反映的是一種統計規律,所以存在某些規則不能很好反映特征詞之間語義相關性的問題,即某些關聯規則在語義上是無效的.
因此,本文采用“知網”作為概念空間,將特征詞映射到概念空間,解決同義詞問題,同時提出基于語義概念分類的關聯規則挖掘方法來提高關聯詞的語義相關性.
“知網”[7](HowNet)是著名的采用漢語描述的本體論.它將漢語和英語的詞語所代表的概念作為描述對象,同時描述了概念之間、概念所具有的屬性之間的關系,并建立了反映這些概念和關系的知識庫.“知網”中,單個或復雜的概念以及各個概念之間、概念的屬性和屬性之間的關系是通過義原或義原的組合來進行標注的.這樣的好處是雖然新詞不斷出現,但義原的增加卻極少.因此,在“知網”中,詞義就被定義為各種義原的組合.
在主題的詞語概率分布模型中引入“知網”作為背景知識,將主題詞映射到義原,可以在一定程度上解決同義詞替換的問題,使得相同概念、不同描述的詞可以進行歸并.
為了獲得主題信息的概念集,首先對文本集D={d1,d2,…,dN}進行預處理,抽取每篇文本 di中權重較高的特征詞,構成基于特征詞集的特征向量:
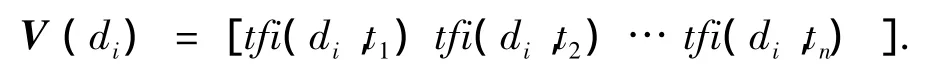
式中:tfi為特征詞ti在網頁di中出現的頻率,n為特征詞的數量.
然后引入知網,將特征詞映射到義原.在將文本di中的每個特征詞t映射為義原時,首先對具有2個或2個以上語義解釋的詞t進行語義排歧,獲取其對應每個語義解釋的概率p,然后以p作為權重為語義解釋涉及到的每個義原a所對應的特征向量賦值.由于目前知網收錄的詞條有限,有些特征詞沒有被知網收錄,對于這些特征詞予以保留,這樣就形成了義原加特征詞的特征向量:
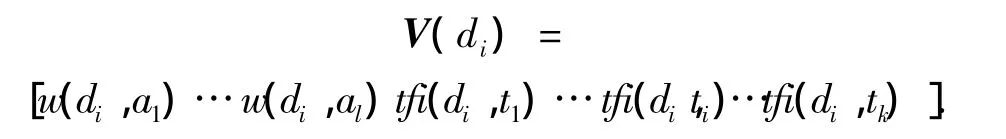
式中:ti(1≤i≤k)為沒有被知網收錄的特征詞,w(di,ai)為義原ai在文本di中的權值:
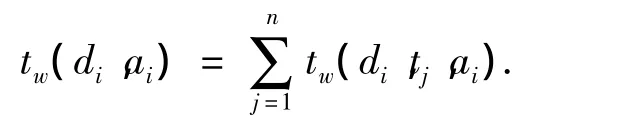
式中:tw(di,tj,ai)為文檔 di中詞條 tj對義原 ai的權重貢獻:
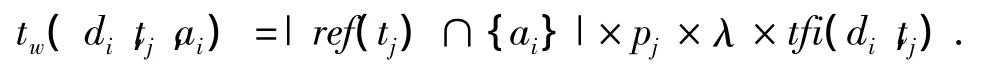
式中:ref(tj)為詞條tj對應的義原集合,λ為該義原類別的權重系數.
為了進一步縮減向量維度并提高關聯規則挖掘的支持度和置信度,通過計算義原間的相似度[8]可以進一步將相似義原進行歸并.義原相似度的計算方法如下:
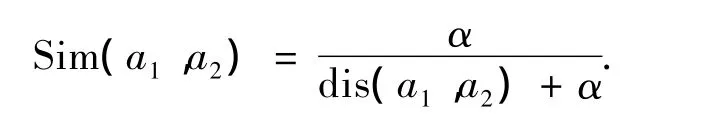
式中:dis(a1,a2)是義原a1和a2在知網層次結構中的語義距離,α是一個可調節的參數.
2.2 基于語義分類的關聯詞集構造
經過分析,各類事件信息中的主題詞根據語義可以分為5類,分別反映了信息中涉及的實體對象、環境、活動、事件和結果,它們從不同角度描述了事件信息的語義內容.因此,在建立主題詞的概念空間之后,文本特征向量中的義原和主題特征詞分量被分為實體對象、環境、活動、事件和結果5類,并且根據其概率分布,對主題語義的貢獻度賦予不同的權重系數.通過挖掘這5類特征分量間的關聯規則,在發現關聯詞的同時也有助于反映它們之間的語義聯系.為了避免同類特征項出現在關聯規則之中,定義基于語義分類的關聯規則如下.
設文檔特征空間中包含的所有義原和特征詞構成集合:W={a1,a2,…,al,t1,t2,… ,tk},其中每個元素屬于一個語義類別K.則定義基于語義分類的關聯規則 A→ B,其中A?W,B?W,A∩B=?,并且,對于規則左部A和右部B中包含的任意項u、v,滿足 Ku≠Kv.
對于文本集D,規則 A→ B的支持度為s=P(A·B),置信度為 c=P(B|A).
基于語義分類關聯規則的關聯詞集構造算法如下:
1)利用關聯規則算法[9]挖掘基于語義分類的關聯規則,獲得所有支持度和置信度分別大于s和c的關聯規則;
重復2)~5),對獲得的每一條關聯規則的左右部包含的關聯詞進行歸并;
2)將關聯規則右部包含的主題詞從主題詞集合中刪除;
3)在歸并后的主題詞集合中查找含有關聯規則任一邊的主題詞的歸并主題詞組合;
4)如果找到,則將另一主題詞加入到該歸并主題詞組合中;
5)如找不到歸并主題詞組合,則以關聯規則左右部的2個主題詞構造一個新的主題詞組合,并放入歸并后的主題詞集合中去;
6)在完成所有關聯規則的歸并后,得到新的主題詞集合,集合內包含多個關聯主題詞組合,即得到關聯詞集合.
3 關聯主題詞的語義相關度計算
3.1 語義相似性計算
在抽取出主題詞并得到關聯主題詞集合后,需要從其中選擇與主題語義相關性高的詞作為主題模型的標注詞——標簽,實現對主題模型的自動語義標注.而語義相關性計算的難點在于標簽和主題模型(主題詞的概率分布)之間的匹配.因此本文將標簽也以概率分布的方式表示,這樣就可以直接與主題模型相比較.
假設標簽l以語義詞分布{p(w|l)}來表示,則可以使用 Kullback-Leibler(KL)距離算法計算{p(w|l)}與主題{p(w|θ)}之間的相似度.為了獲得標簽l的語義詞分布{p(w|l)},本文采用一種近似方法,通過數據集D來估計{p(w|l,D)},以代替{p(w|l)}.標簽和主題之間的語義相似性通過式(1)進行計算.
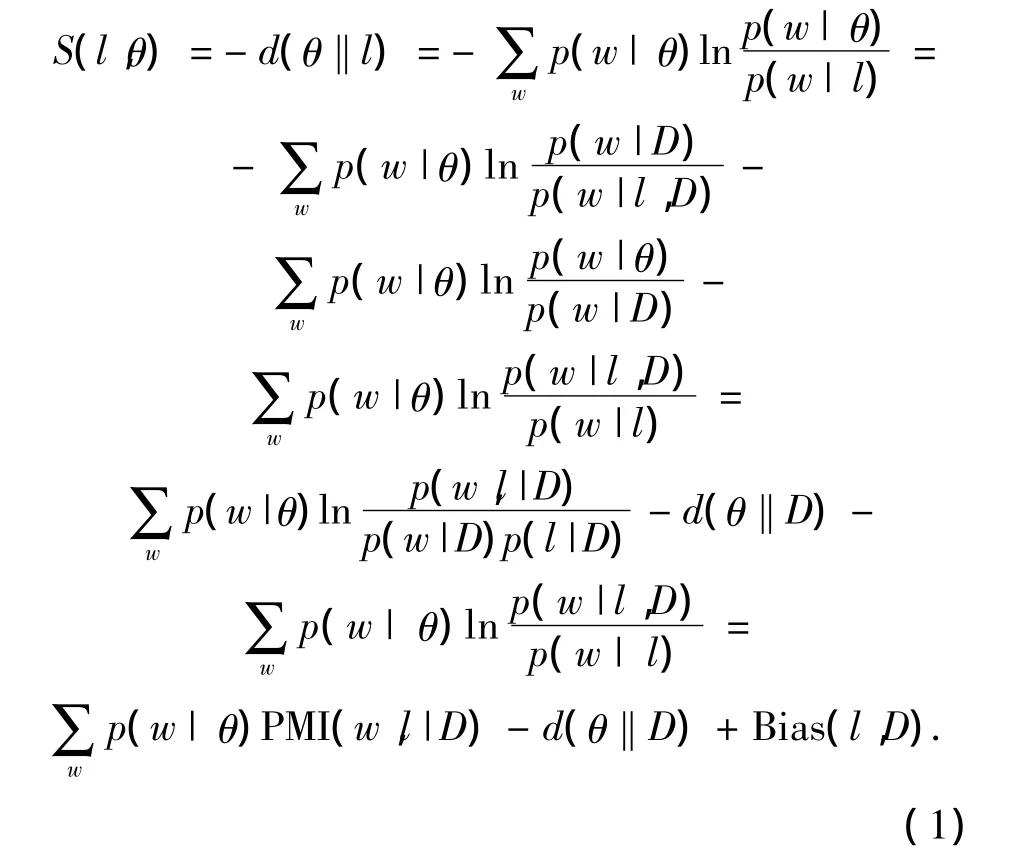
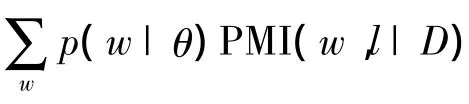
3.2 語義覆蓋度計算
好的標簽應該對主題的語義內容有較高的覆蓋度,語義相關性僅能保證所選擇的標簽與主題信息具有高相關性,但可能僅表達了該主題的部分語義.因此,當選擇多個標簽對主題進行標記時,希望選擇的新標簽能夠覆蓋主題其他的語義部分,而不是已有標簽已經涵蓋的內容.
本文采用最大邊緣相關(maximal marginal relevance,MMR)方法來選擇高語義覆蓋度標簽.MMR方法常常用于多文檔摘要問題,是一種十分有效的去冗余并且取得最大相關性和差異性的方法.本文對MMR進行了一定簡化以實現對標簽的選擇,通過最大化MMR來逐個選擇標簽,如式(2):
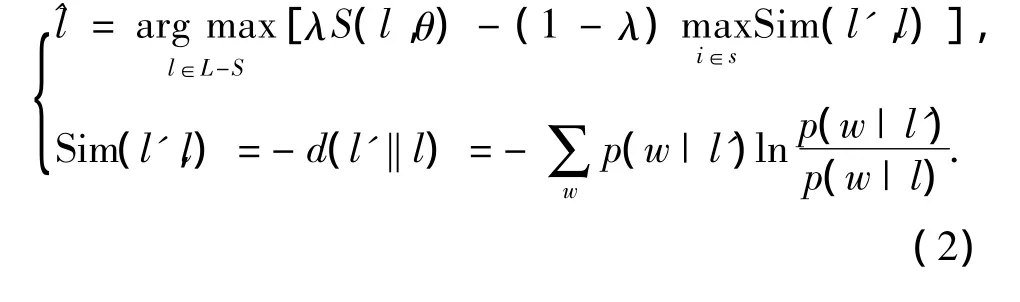
式中:S是已經選擇的標簽,λ是經驗參數.
3.3 語義區分度計算
以上標簽選擇方法僅考慮了對單一主題的標注,當對多個主題進行標注時,則需要考慮不同主題間的區分,因為如果一個標簽在多個主題內都具有較高的相關度,則該標簽對于人們區分不同的主題是缺乏幫助的,因此為多個主題選擇標簽既需要考慮相關度,也需要考慮區分度,在這種情況下,對式(1)進行修正,提出了考慮區分度的語義相似性計算方法:
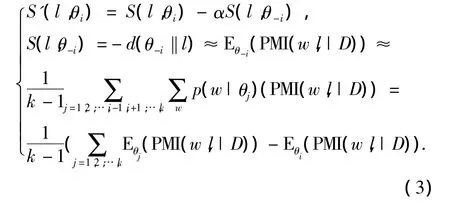
式中:θ-i表示除主題θi之外的其他k-1個主題,即θ1,2,…,i-1,i+1,…,k,k 為主題數.
式(3)通過S'(l,θi)計算跨主題的標簽語義相似度并進行排序,可以為多個主題生成語義相關且具有一定覆蓋度和區分度的標簽.
4 實驗結果及分析
4.1 實驗方案
實驗選擇旅游信息和食品安全事件信息中的4 200條文本數據構成訓練文檔集,采用LDA主題分析方法[10]在文本集上建立主題模型,利用快速Gibbs采樣進行參數估計,設定主題數K=30,超參數 α =50/K,β=0.1,迭代次數為1 000.
采用本文提出的主題詞生成方法進行主題詞的提取和關聯詞集構造,將其作為主題標注的候選標簽集,然后在候選標簽集合上,采用本文提出的語義相關度計算方法選取能夠描述主題語義的標簽進行自動標注.
實驗抽取主題詞數N=1 000,為了控制程序運行時間,設定概念空間維數為20,關聯歸并的支持度s=1%,置信度c=1.5%.最后選擇286個關聯主題詞,每個關聯主題詞對應1~3個主題詞,構成主題的候選標簽,該標簽集記為TagSet-1.同時,為了與本文的候選標簽生成方法進行對比,采用N-gram方法(n=1,2)抽取關鍵詞,并通過χ2測試選擇前300個主題詞建立另一個候選標簽集,記為TagSet-2,從而利用這2個標簽集分別進行主題標注,以評價標簽集的有效性.在食品安全和旅游信息領域采用以上2種方法分別建立的部分候選標簽如表1所示.
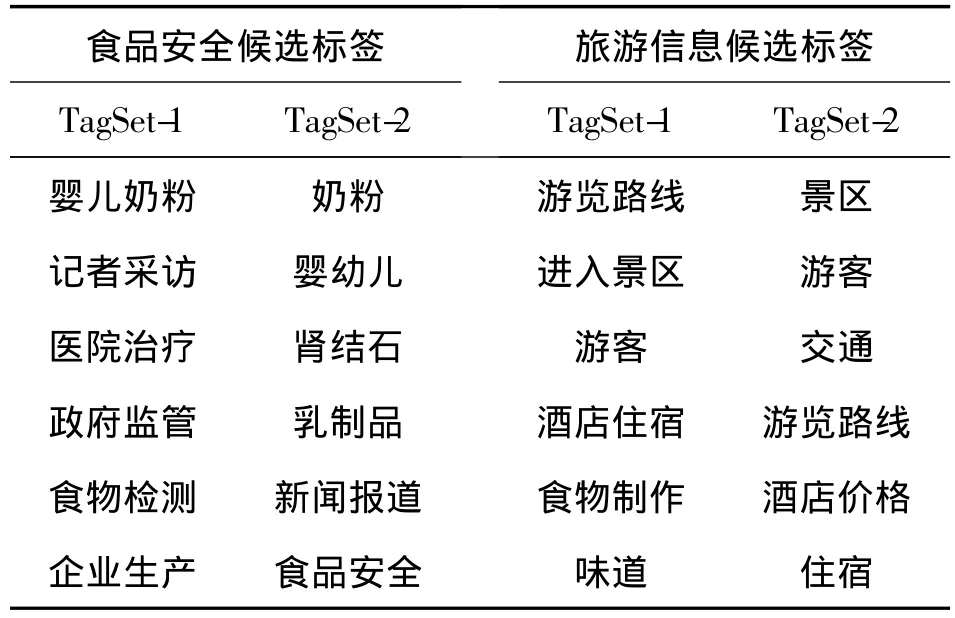
表1 部分候選標簽Table 1 Some candidate labels
4.2 主題標注結果
表2和表3分別列出了食品安全和旅游領域的部分主題的標注結果.
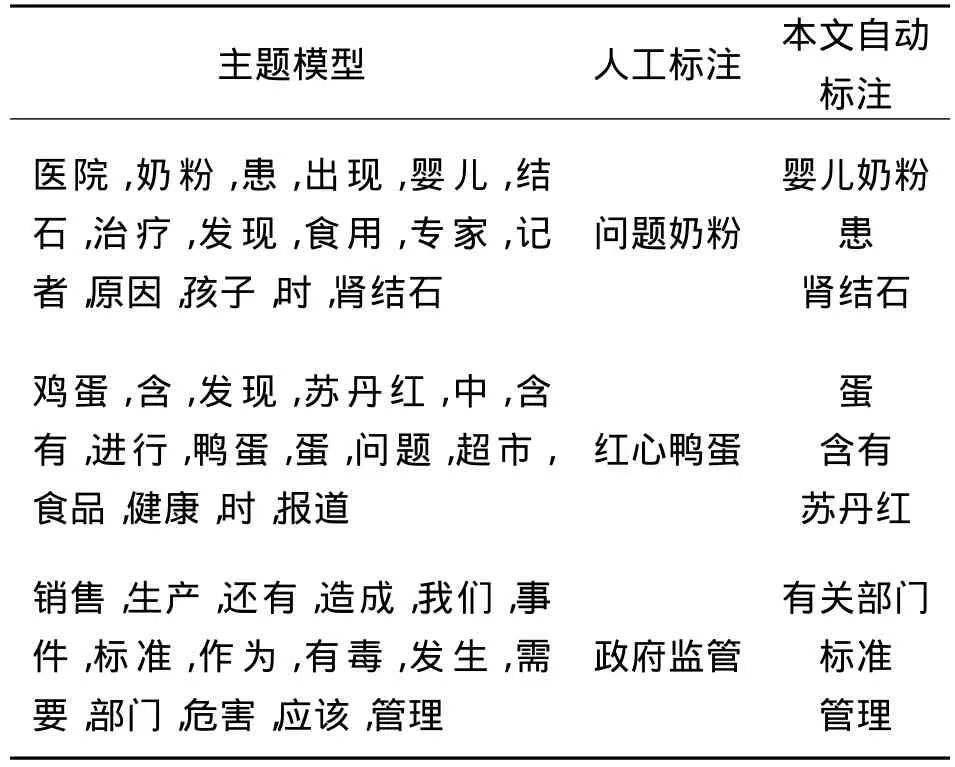
表2 部分食品安全主題及相應標簽Table 2 Some food safety topics and corresponding labels

表3 部分旅游主題及相應標簽Table 3 Some tourism topics and corresponding labels
表2、3中列出了每個主題模型中概率最大的前15個詞,以及根據本文方法自動標注的標簽.為了便于比較,表中也給出了每個主題模型的人工標注標簽.人工標注的具體方法是將每一主題的主題模型(主題詞概率分布)、代表性文檔及候選標簽集展示給志愿者,由他們選擇合適的標簽進行人工標注.
可以看出,自動標注的標簽基本涵蓋了主題的語義,尤其在食品安全領域,例如“嬰兒奶粉”、“患”、“腎結石”、“蛋”、“含有”、“蘇丹紅”等標簽已經很好地表達了主題語義,與“問題奶粉”、“紅心鴨蛋”等人工標注結果較為吻合.某些情況下比人工標注還要準確,例如志愿者因受媒體報道等的影響,將禽蛋類食品中發現蘇丹紅的主題標注為“紅心鴨蛋”,這是因為最早發現蘇丹紅是在鴨蛋中,所以媒體將此類事件報道為“紅心鴨蛋事件”;而實際上,主題模型中包括雞蛋和鴨蛋,本文標注方法將它們映射為義原“蛋”并據此生成標簽,因此語義上更為準確.
4.3 主題標注的有效性
為了能夠準確評價主題標注的有效性,采用評分法將本文標注方法與人工標注和最大概率主題詞標注方法進行比較.其中,最大概率主題詞標注根據主題模型中詞語的概率分布選擇概率最高的前3個詞作為主題標簽.
標注結果的具體評分方法是:通過5名志愿者對3種方法的標簽進行打分,即將隨機排序的主題及其主題詞分布、標簽和該主題的最相關文檔提供給志愿者,由志愿者對3種方法產生的標簽分別打分,然后統計平均得分.打分規則是總分為5分,由志愿者將這5分按照其對標簽準確性的評估分別分配給3種方法生成的標簽.并且,要求志愿者對僅使用1個標簽和使用3個標簽進行標注的情況分別打分,結果如表4所示.
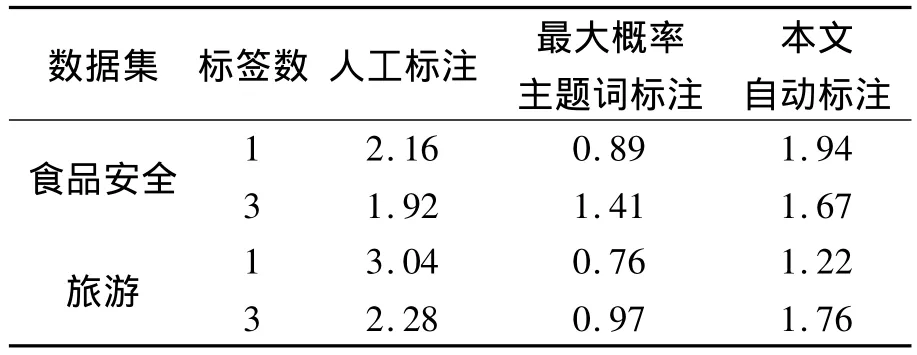
表4 主題標注的有效性對比Table 4 Comparison of topic labeling methods
從表4中可以看出,雖然在所有情形下人工標注的得分都是最高的,但本文標注方法的得分明顯高于最大概率主題詞標注方法.在食品安全領域,本文方法已經接近于人工標注的得分,這主要是因為在食品安全領域中,不同主題的主題詞之間具有更高的區分度,尤其是一些專有名詞和術語主要在特定主題中出現.
此外,在食品安全領域僅采用1個標簽的情況下,本文方法相比最大概率標注方法優勢明顯,但若采用3個標簽,則優勢不大.然而在旅游領域使用3個標簽的情況下,本文方法仍具有較大優勢,這主要是因為旅游領域除特定地點或景點主題外,主題詞多是一些通用詞,且某些高概率詞的語義類別單一,并不能充分表達主題語義.而通過概念映射和建立關聯詞,則可以將屬于不同語義類別且具有語義相關性的主題詞組織起來,從而提供更為豐富的語義.例如,“菜”、“肉”、“茶”等主題詞被映射為概念“食物”,與關聯詞“制作”共同構成標簽“食物制作”,這樣可以表達更明確的語義.
為了比較不同標簽集生成方法的有效性,采用本文提出的語義相似性計算方法,分別利用TagSet-1和TagSet-2 2個候選標簽集對主題進行標注,并對標注結果打分,總分2分,評分結果如表5所示.
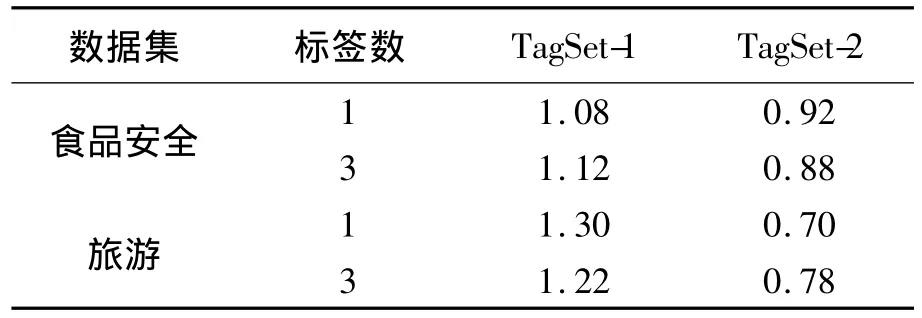
表5 標簽集的有效性對比Table 5 Comparison of tag sets
從表5可以看出,本文方法建立的關聯詞集TagSet-1在總體得分上均高于N-gram關鍵詞集TagSet-2,這主要是因為TagSet-2中存在的多個同義或同語義類別詞分散了語義相似度的計算結果,如“鴨蛋”、“雞蛋”和“禽蛋”被作為3個標簽分別計算語義相似度,導致計算結果偏低,影響了標簽的選擇.而且,TagSet-2中的標簽也存在語義類別單一的問題,降低了每個標簽的語義表達能力.
5 結束語
提出了一種概率主題模型的自動標注方法,通過主題詞提取和語義概念空間上的關聯詞挖掘方法來生成候選主題詞,并且給出了主題詞語義相關性計算以及高語義覆蓋度和區分度標簽的選擇方法,實現了主題模型的自動語義標注,解決了對主題詞模型進行語義理解的問題.該方法被用于食品安全主題和旅游信息主題的自動標注,實驗證明該方法的標注效果優于最大概率主題詞標注方法.尤其在食品安全等專業領域,由于充分考慮了專業術語與一般詞匯的語義區分度和語義覆蓋度,使得本文方法能夠取得更好的效果
[1]BLEI D M,NG A Y,JORDAN M I,et al.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003,3(7):993-1022.
[2]COHN D,HOFMANN T.The missing link—a probabilistic model of document content and hypertext connectivity[EB/OL].[2010-05-10].http://books.nips.cc/nips13.html.
[3]GILDEA D,JURAFSKY D.Automatic labeling of semantic roles[J].Computer Linguist,2002,28(3):245-288.
[4]石晶,李萬龍.基于LDA模型的主題詞抽取方法[J].計算機工程,2010,36(19):81-83.
SHI Jing,LI Wanlong.Topic words extraction method based on LDA model[J].Computer Engineering,2010,36(19):81-83.
[5]BANERJEE S,PEDERSEN T.The design,implementation,and use of the ngram statistics package[C]//Proceedings of the Fourth International Conference on Intelligent Text Processing and Computational Linguistics.Mexico City,Mexico,2003:370-381.
[6]劉銘,王曉龍,劉遠超.基于詞匯鏈的關鍵短語抽取方法的研究[J].計算機學報,2010,33(7):1246-1255.
LIU Ming,WANG Xiaolong,LIU Yuanchao.Research of key-phrase extraction based on lexical chain[J].Chinese Journal of Computers,2010,33(7):1246-1255.
[7]孫景廣,蔡東風,呂德新,等.基于知網的中文問題自動分類[J].中文信息學報,2007,21(1):90-95.
SUN Jingguang,CAI Dongfeng,Lü Dexin,et al.HowNet based Chinese question automatic classification[J].Journal of Chinese Information Processing,2007,21(1):90-95.
[8]夏天.漢語詞語語義相似度計算研究[J].計算機工程,2007,33(6):191-194.
XIA Tian.Study on Chinese words semantic similarity computation[J].Computer Engineering,2007,33(6):191-194.
[9]黃名選,嚴小衛,張師超.基于矩陣加權關聯規則挖掘的偽相關反饋查詢擴展[J].軟件學報,2009,20(7):1854-1865.
HUANG Mingxuan,YAN Xiaowei,ZHANG Shichao.Query expansion of pseudo relevance feedback based on matrixweighted association rules mining[J].Journal of Software,2009,20(7):1854-1865.
[10]石晶,范猛,李萬龍.基于 LDA模型的主題分析[J].自動化學報,2009,35(12):1586-1592.
SHI Jing,FAN Meng,LI Wanlong.Topic analysis based on LDA model[J].Acta Automatica Sinica,2009,35(12):1586-1592.
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
開放教育研究(2020年2期)2020-03-31 01:54:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年2期)2011-01-23 06:39:12
