語料庫語言學視角下的語塊自動提取研究
2012-11-01 05:53:30石志亮
天津外國語大學學報 2012年6期
關鍵詞:心理
石志亮
(中原工學院 外國語學院,河南鄭州 450007)
一、引言
語塊類似于詞匯和語法之間的橋梁,是一個完整的詞匯和語法單位,Wray(2002)認為,語塊具有心理上的現實性、結構上的完整性和語義上的一致性。上述特點使得語塊在交際中可以整存整取,減輕了交際者大腦處理的負擔,節約語言處理的時間和精力,獲得像本族語者一樣的流利性,增加語言輸出的準確性、流利性和地道性。近二十年來,隨著認知語言學、心理語言學和構式語法理論的興起,語塊(lexical chunks)在二語產出過程中的重要作用日益凸顯。語料庫語言學的興起為語塊的研究開創了新的視角,近年來語塊已經成為語言學研究和教學研究的一個熱點,且研究視角呈現出多元化趨勢。本文主要從語料庫語言學的角度對語塊的提取方式進行論述,以此來深化我們對語塊這一語言現象的理解。
二、語塊的界定與特征
目前語塊的研究呈現出三種視角:語法學、語料庫語言學和心理語言學。由于覆蓋范圍及研究重點不同,這三種視角對語塊的定義表述不一。語法學家將其看作“充當句子成分、具有句法功能的詞的組合”;語料庫語言學家更多地“關注那些出現頻率超過提取頻點的重現詞叢,而忽略其地道性和結構特征”;心理語言學家則認為,語塊是“一串預制的連貫或不連貫的詞或其他意義單位,整體存儲于記憶中,使用時直接提取,無需經過語法生成和分析”(Wray,2002:9)。這就是語塊儲存和提取的整體性(即心理現實性)。詞的組合能否作為整體被儲存和提取是決定詞的組合是否為語塊的重要指標。
由此可見,人們尚未對語塊給出一致的明確定義,國外創造和使用的術語多達57個,如formulaic sequence, chunk, lexical chunk,prefabricated chunk, collocation, colligation,N-gram等,國內對它的翻譯也是名稱繁多,尚無定論。中國期刊全文數據庫文史哲輯專欄目錄(1997-2011)檢索的結果為:語塊、組塊、套語、多詞單位、預制語塊、搭配、習語、成語、慣用語、類聯結等,如此大量的術語說明了語塊研究的重要意義和語塊現象的多面性和復雜性(段士平,2008)。簡單地說,語塊是真實言語交際中以高頻率出現的大于單個單詞的整體的多詞單位。基于語法學、語料庫語言學和心理語言學三個視角的研究發現,語塊具有心理現實性和結構上的連續與非連續性特征。
1 語塊的心理現實性
語塊是心理學概念組塊(chunking)的結果,組塊就是記憶對信息的加工過程,也就是把單個信息組成更多的信息單位。心理學家通過分析短時記憶與長時記憶的差別,發現語塊具有組塊效應,對記憶及語言學習至關重要。心理學家Miller的研究表明,短時記憶所能加工與處理的信息容量非常有限,其容量大約為5~9個組塊或者有意義的信息單元(Miller,1956)。長時記憶中加工與存儲的信息容量巨大,以語義方式進行編碼與儲存,信息儲存的時間長,甚至可以保持永久。Simon(1974)的研究也驗證了Miller的短時記憶容量的觀點,認為語塊是人類記憶的基本單位。因此,人們可以通過加強語塊內部信息單位之間的意義聯系來擴大短時記憶的容量,重新編碼后的信息單位變為有意義的語塊即可進入長時記憶,以語塊的形式整體儲存、整體提取,這就是語塊的組塊效應,即心理現實性。McClelland的連通理論發現,人類大腦中無數的節點及其相互之間的連接構成了一個巨大的網絡,知識就儲存在這些聯結線上,聯結的強度決定知識掌握的程度(陳萬會,2008)。由于語塊中各個組成部分共現的頻率較高,所以它們之間的聯結會不斷增強。語言輸出時,語塊更容易從心理詞庫中提取出來,使交際變得流暢、高效。因此,Wray(2002)認為,詞塊是指出現頻率高、作為整體儲存和使用的詞語程式。二語習得研究也表明,語言學習是通過規則學習和范例學習兩種途徑發展的,后者就是預制語塊的構建(Skehan,1998 :49)。
2 語塊的結構特征
語塊從結構上可分為四類(Nattinger &DeCarrico,1992:33):多元詞語塊(polywords)、習俗語語塊(institutionalized expressions)、短語架構語塊(phrasal constraints)、句子構建語塊(sentence builders)。Lewis(1993) 從 結 構和功能上把語塊分為四種情況:聚合詞,指具有習語性質的固定詞組,比如on the one hand,on the other hand;搭配詞,指共現頻率很高的詞語,如動詞+名詞、形容詞+名詞搭配,如put forward a suggestion;慣用話語,指形式固定或半固定的具有語用功能的單詞組合,如If I were you;句子構架和引語,這一類僅指書面語詞匯,如firstly... and finally。此外,還可以按照語塊成分間連續情況將其分為:連續性、固定語塊,如once upon a time, on the other hand等;非連續性可變語塊,如firstly...and finally,it occurred to sb.to do...基于語塊的心理現實性和結構方面的特征并結合語料庫研究的方法,本文把語塊界定為:以整體形式儲存在大腦中,并可作為預制組塊供人們提取使用的多詞單位,這就把名稱為語塊、搭配、類聯結和預制語塊等多詞單位統統包括在內。也就是說,語塊的概念模糊了原有的詞匯搭配之間的界限,它不僅包括多詞的搭配、句子框架,還可以擴大到句子甚至語篇。
三、語料庫語言學視角下的語塊提取
要研究語塊,首先必須快速識別和提取語塊,目前主要通過機器自動識別和人工多方驗證兩種方式。人工識別主觀性強,速度太慢。語塊提取的經典方法是基于語料庫的方法,這是語料庫語言學和自然語言結合的產物。語料庫的優勢在于能快速檢索和統計大量語料,注重頻數信息是語料庫方法的一個顯著特征。事實上,現有的從大規模語料庫中自動提取語塊的方法多是以統計為主,輔之以詞性、句法等語言學規則(謝家成,2008)。隨著人們對語塊認識的深入,語料庫的方法也不斷改進。語料庫除了通過檢索行凸顯搭配外,還可實現搭配的自動提取在自然語言處理領域,語言檢索的工具和技術進展很快。語塊識別的技術也從人工識別進入了機器識別。語塊檢索技術的起點是從語料庫中提取連續的、固定的詞串,經過幾年的發展,已可以提取非連續的可變語塊。
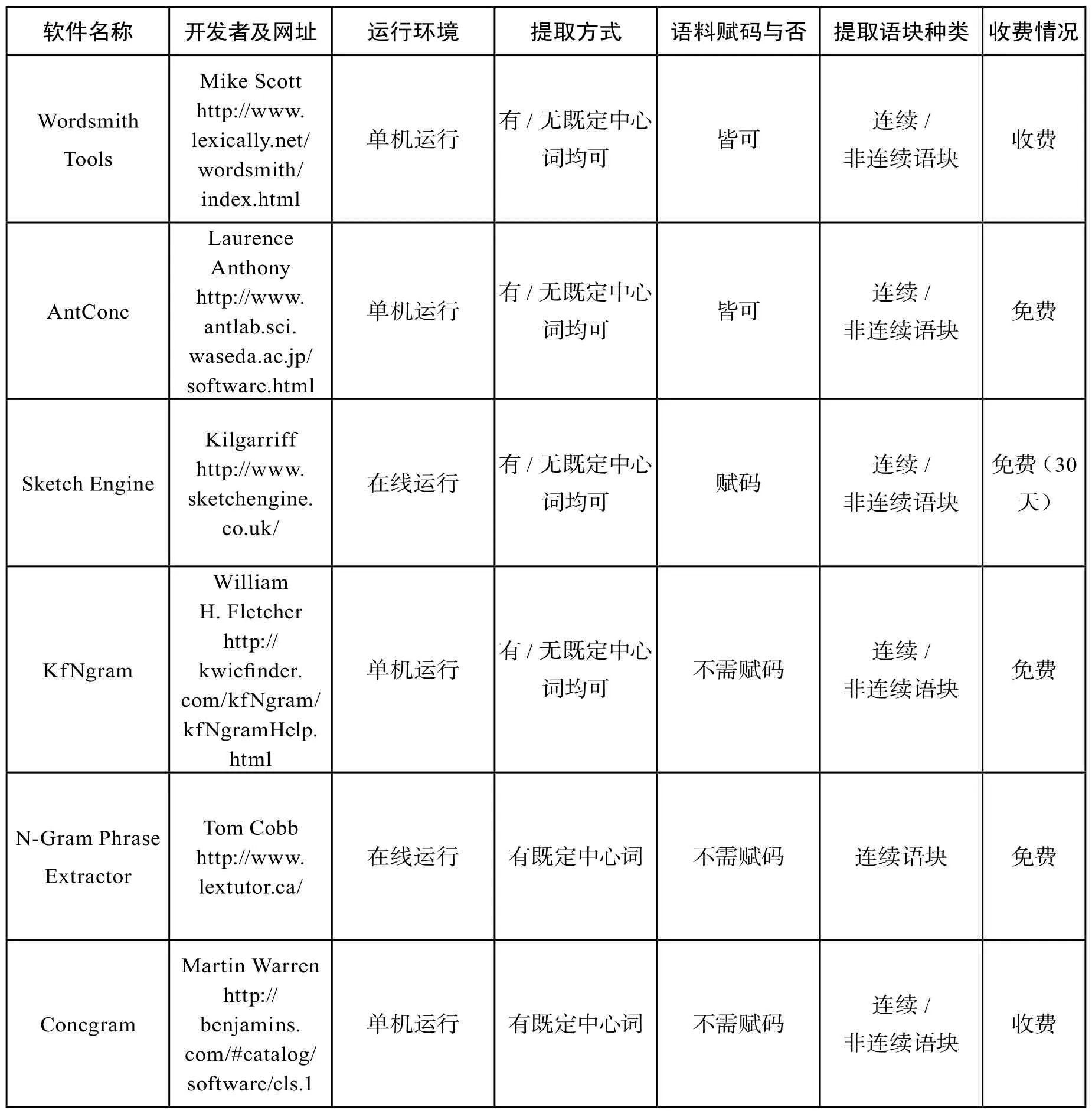
語塊提取軟件
上表為六個語塊提取軟件的概貌,下文主要從以下三個方面對語塊提取軟件進行分項闡述:語塊提取軟件的運行方式與收費情況,語塊的提取方式,即有無既定的中心詞及語塊的種類。
1 語塊提取軟件的運行方式與收費情況
軟件的運行方式主要分為單機運行和在線運行兩種方式,一般情況下單機運行的軟件多為收費的商業軟件,功能也較全面,如Wordsmith Tools,在線運行的軟件多為免費軟件,功能相對單一,如N-Gram Phrase Extractor,Sketch Engine,Concgram。AntConc是免費的,功能強大,界面友好,支持正則表達式檢索等因素,國內研究者多傾向于使用它,目前是語料庫檢索的主流軟件。
2 語塊的提取方式
語料庫提取語塊可分為基于既定中心詞和無既定中心詞兩種情況,本文將《新概念英語3》全部60篇文章作為檢索語料,以AntConc軟件為例進行語塊提取的演示。
2.1 基于既定中心詞的連續語塊提取
以既定中心詞possible為例提取《新概念英語3》中相關的連續語塊。第一步,通過點擊菜單欄File下拉菜單中的Open File(s), 導入要提取的語料《新概念英語3》,再點擊軟件主界面上方的Clusters(詞叢)按鈕,然后在主界面下方的Search Term(搜索輸入框)中輸入檢索詞possible。第二步,設置Cluster Size, 通常提取的語塊長度范圍為2~6個詞。由于不同長度的語塊重疊,因此語塊的邊界的確定也是困擾研究者的一個問題。我們可以采取從長到短的順序提取語塊,并依次屏蔽已經提取的語塊,這樣可以最大限度地避免語塊重疊問題。本文中語塊長度范圍設置,最小為4,最大也為4, 表示要提取包含檢索詞在內的4詞短語。第三步,設置Min. Cluster Frequency(出現的最小頻數)為默認值1,設置Sort by為Sort by Fre (按頻率顯示)。第四步,點擊Start即可提取出包含possible在內的所有連續4詞語塊來。語塊提取結果如下:

2.2 無既定中心詞的連續語塊提取
如果需要了解某篇文章中的語塊總體使用情況,可以如下操作:第一步,導入要提取的語料《新概念英語3》,點擊主界面上方的Clusters按鈕,勾選主界面下方的N-grams(N元結構); 第二步,設置N-gram Size, 一般設置Min. Size 為2, Max. Size為6。本文把二者皆設置為4;第三步,設置Min. Cluster Frequency為默認值1,設置Sort by為Sort by Fre;第四步,點擊Start即可提取出語料中的所有連續的4詞語塊來。語塊提取結果如下:

以這種方式提取的語塊多是基于詞形的外在物理毗鄰進行人為切分,統計共現頻數,忽視了詞語序列的內部黏著力。因此,提取的數據中含有大量結構不完整、語義不清晰的強干擾序列,識別的準確率稍低,還需人工運用語言學知識進行篩選,但是這種機切語塊往往能凸顯容易被忽略的語言適用范式(何安平,2011;林維燕,2011)。
3 語塊的種類
根據語塊的結構,可以將其分為連續性和非連續性語塊。連續性語塊的提取較為容易,非連續語塊的提取方法相對比較復雜。這種檢索主要是圍繞某個既定中心詞提取其相關的搭配模式,一次檢索只能針對一組詞語。可以利用Wordsmith工具中的Concordance檢索工具中Context word語境詞功能,也可運用ConcGram(框合結構)或Sketch Engine進行檢索。下文仍以AntConc軟件為例,檢索in...of構成的非連續語塊在新概念英語第三冊中出現的情況。
第一步,導入要提取的語料《新概念英語3》,在軟件主界面下方的Search Term中輸入in; 第二步,點擊其右側的Advanced(高級),在隨后彈出的界面上勾選Use Contexts Words and Horizons(使用語境詞和設置語境詞左右范圍),在Contexts Words(語境詞)框中輸入of,點擊Add,接著把Context Horizon(語境詞左右范圍)設置成From2R to 4R(右2至右4),表示of必須出現在檢索詞in 右邊的第二到第四的位置上;第三步,點擊Apply,自動回到主界面,再點擊Start即可提取出在in...of 這個短語框架下的所有的非連續性語塊。語塊提取結果如下:

從上面的檢索結果可以看出,AntConc的局限性在于它只能檢索既定中心詞之間的單向搭配,即“in在前,of在后”的這個方向的搭配,而不能檢索“of在前,in在后”的反向搭配的語塊。ConcGram(框合結構)可以克服AntConc的這一局限性,檢索由多個中心詞構成的非連續語塊,且不考慮這些詞的先后順序(即任意方向的強搭配)。ConcGram的具體操作步驟詳見詹宏偉 (2011)的《語料庫中語塊提取的工具與方法》,在此不再贅述。
四、結語
綜上所述,語塊是語言中高頻共現的多詞組合。在結構特征上,可以分為連續和非連續兩類;在語塊提取的方式上,又可分為基于既定中心詞和無既定中心詞兩種情況。并且語塊具有整存整取的心理現實性和統計上的顯著性。因此,語塊的提取應充分考慮上述特征。基于語料庫自動提取出的大量語塊,雖然頻率較高,但不一定都具有心理現實性,尚需結合心理語言學的相關知識進行人工篩選。因此,我們相信心理語言學與語料庫語言學兩大研究視角的融合,將更能夠實現二者的優勢互補,達到人工篩選和自動識別的高度彌合,加深人們對語塊這一語言現象的認識,提高語塊研究的效率和深度。
[1]Lewis, M. The Lexical Approach[M]. Hove: Language Teaching Publications, 1993.
[2]Miller, G. a.The Magical Number of Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information[J].Psychological Review,1956,(63).
[3]Nattinger, J & J. DeCarrico. Lexical Phrases and Language Teaching[M]. Oxford: Oxford University Press, 1992.
[4]Simon, H. a.How Big Is a Chunk? [J].Science, 1974, (183).
[5]Skehan, P. A Cognitive Approach to Language Learning[M]. Oxford: Oxford University Press, 1998.
[6]Wray, a.Formulaic Language and the Lexicon[M]. Cambridge: Cambridge University Press,2002.
[7]陳萬會. 詞塊的心理現實性及其特征[J]. 外語學刊,2008,(6).
[8]段士平. 國內二語語塊教學研究述評[J]. 中國外語,2008,(4).
[9]何安平. 短語理論視角下的英語教師課堂話語探究[J]. 外語教學理論與實踐,2011,(3).
[10]林維燕. 機切語塊立場標識特性的理論與實證研究[J]. 中國外語,2011,(5).
[11]謝家成. 搭配的多視角透視[J]. 解放軍外國語學院學報,2008,(2).
[12]詹宏偉. 語料庫中語塊提取的工具與方法[J]. 外語教學,2011,(2).
猜你喜歡
光明少年(2024年5期)2024-05-31 10:25:59
當代陜西(2022年4期)2022-04-19 12:08:54
International Journal of Nursing Sciences(2022年1期)2022-02-08 03:23:58
中老年保健(2021年10期)2021-08-24 06:43:04
中老年保健(2021年8期)2021-08-24 06:24:28
閱讀(快樂英語高年級)(2020年3期)2020-07-16 03:41:38
娃娃畫報(2019年11期)2019-12-20 08:39:45
人生十六七(2016年14期)2016-12-01 05:24:26
文理導航·科普童話(2015年6期)2015-07-29 16:53:22
健康之家(2006年1期)2006-01-01 00:00:00
