視聽同步輸入模式對口譯質量的影響
——基于多模態理論的實證研究
2012-11-03 05:04:08李彬
長江師范學院學報 2012年9期
李彬
(徐州工程學院 外國語學院,江蘇 徐州 221000)
□翻譯學研究
視聽同步輸入模式對口譯質量的影響
——基于多模態理論的實證研究
李彬
(徐州工程學院 外國語學院,江蘇 徐州 221000)
基于多模態話語分析理論,探討多種信息輸入模式對口譯質量的影響。實驗對兩組各20名受試學生分別進行視聽/聽音口譯對比研究。研究采用統計軟件SPSS對實驗數據進行分析。研究結果顯示,視聽組學生的總體口譯質量比聽音組學生的口譯質量高,但并不是很明顯;同時,視聽同步輸入模式下視覺信息對受試的理解和記憶有積極的影響,還可提高受試對源語意義的整體理解和意義構建。
視聽同步輸入;多模態;口譯質量
傳統的以單一的文字形式獲取信息的方式通常被稱為單模態交流。隨著科學技術的進步,這種單一模態的運用已遠遠不能滿足當今人們獲取大量信息的需要,視覺信息的輸入也不再僅僅局限于傳統的書本文字的輸入,動畫、卡通、幻燈片等大大豐富了人們的視覺信息獲取方式。多媒體等視頻高科技產品更是集視聽多種模態于一體的信息傳遞和交流方式。多模態的應用方便了人們的交際,尤其是在語際交際中,交際雙方具有不同的文化背景和語言習慣,但他們之間的交流與生活在同一文化中的人們之間的交流沒有本質上的差異,相反,由于文化背景的不同,交際雙方為了能夠準確地表達自己的交際意愿,常常會運用許多多模態手段實現信息的準確傳遞,比如語速、語調、音高、手勢、表情以及其他的一些身體動作等。口譯作為 “人們跨文化跨語言的交往活動中由能運用交流各方面所使用語言的人,采取口語表達的方式,將一種語言所表達的思想內容以別種語言做出轉述的即時翻譯過程” (張文,韓常慧),是不同文化之間溝通和交流的橋梁。譯員在工作過程中可以通過捕捉交際雙方在交際過程中表現出多模態信息,準確把握交際意圖,實現交際過程的順利進行。因此,將多模態概念引入到口譯研究中是一個很好的切入視角。對近年來的相關研究回顧發現,多模態理論的研究雖已引起重視,但將多模態理論和口譯結合起來的研究并不多。本研究嘗試運用多模態話語分析理論,結合口譯實證研究,探討多模態信息輸入形式與口譯質量之間存在的關系,多模態情境對譯員的影響等問題。
1 多模態話語分析
多模態話語分析是近十年來發展并活躍于西方的一種新的話語分析理論,其理論基礎是系統功能語法。在多模態話語分析方面最早的研究者之一R. Barthes在 1977年發表的論文 “圖像的修辭”(Rhetoric of the Im age)中探討了圖像在表達意義上與語言的相互作用。之后,韓禮德(Halliday)的系統功能語法被運用到多模態話語分析中。該理論框架由五個部分組成:(1)文化層面;(2)語境層面;(3)意義層面;(4)形式層面;(5)媒體層面。其中,形式層面包括語言的詞匯語法系統、視覺性的表意形體和視覺語法系統、聽覺性的表意形體和聽覺語法系統、觸覺性的表意形體和觸覺語法系統等以及各個模態的語法之間的關系;媒體層面是話語最終在物質世界表現的物質形式,包括語言的和非語言的兩大類。語言的包括純語言的和伴語言的兩類;非語言的包括身體性的和非身體性的兩類。身體性的包括面部表情、手勢、身勢和動作等因素;非身體性的包括工具性的,如PPT、實驗室、網絡平臺、音響、同聲傳譯室等。系統功能語言學創立以來,被廣泛運用到語言語篇的分析中。從符號學看系統功能語法,其語篇分析的對象本質上講是語言符號,或是符號系統。對視覺圖像、聲音、印刷體式、建筑設計、身體動作、電子媒體和電影等多模態交際符號的關注也是系統功能語言學的研究范疇。因此,克瑞斯和勒文 (Kress and Leeuwen)將韓禮德的語言元功能的思想運用到視覺模式中,創立了視覺語法,用于分析視覺圖像。克瑞斯主要將系統功能語法理論運用到視覺藝術的分析;勒文第一次系統解釋了視覺語法,建立了視覺交流基于多模態符號的理論基礎。多模態話語分析的基礎是語篇,即多模態語篇。對于多模態語篇的研究,克瑞斯和勒文 (2001)曾指出多模態語篇 (m u ltim odal discourse)是一種融合了多種交流模態 (如聲音、文字、形象等)來傳遞信息的語篇。胡壯麟教授從符號學的視角研究了多模態,開創了我國多模態研究的先河。他在 “社會符號學研究中的多模態化”中討論了模態的符號學特性。依照他的研究,多模態語篇可以定義為多種 “符號資源”共同出現的語篇,或是由傳達同一意思的多種符號有機構成的 “符號系統”。在“多模態小品的問世與發展”一文中,他又提出了“多模態小品”的概念,這是對多模態語篇概念的概括、發展和延伸,極大地豐富了多模態語篇的研究,本文中所涉及的口譯實驗材料也可歸屬于 “多模態小品”范疇。
2 研究設計
2.1 研究問題
本實驗研究的主要問題如下:
(1)就所有受試的口譯表現 (成績)而言,多模態情景下的視聽信息輸入模式是否優于聽音信息輸入模式?是否會對個別受試的口譯表現造成顯著性影響?
(2)視聽輸入模式對實驗組整體表現的影響具體表現在哪些方面?
2.2 實驗對象
本次研究對象為南京某高校英語專業三年級學生,分為A、B兩組,每組各20名。所有學生均學習過一年的口譯課程,掌握了基本的口譯知識和口譯技能。兩組實驗受試的整體口譯水平基本一致,受試選取的參照標準為上一學年期末考試口譯成績。
2.3 實驗設備與材料
實驗地點為語音實驗室。所有受試對象都配有高保真耳機和電腦顯示器。實驗過程中,電腦屏幕顯示及實驗材料選取均由教師統一提供。實驗在口譯課上進行,測試形式為交替傳譯。
本實驗共分實驗一和實驗二兩部分。考慮到受試學生對演講材料整體風格相對比較熟悉,本實驗選取了語速適中、題材相對較容易的演講材料。實驗一的視頻材料為奧巴馬在上海復旦大學的演講。實驗時,對A組學生播放視頻,對B組學生只播放音頻,兩組材料實驗內容完全相同,根據播放形式不同分別記為m aterialA1,m aterialB1。為了更好保證實驗二中實驗材料難度和受試學生對測試材料的反應所選材料一致性,實驗二的音頻材料仍取自該演講材料,記為m aterialA2。所有測試材料時間均為兩分鐘,語速和長度基本一致。實驗前所有材料均被技術處理,放音過程中停頓一次,并留有時間供學生口譯。
2.4 實驗步驟
實驗一。本實驗中,A組為實驗組,B組為控制組。對A組學生播放m aterialA1,學生在信息聽辨過程中可以通過多媒體屏幕觀看視頻,獲取演講現場的信息,聽到口譯提示音后進行傳譯。本實驗只關注不同輸入模式對口譯最終結果的影響,因此對所有受試學生筆記不作任何要求。待所有學生口譯完成后,將所有口譯音頻進行存檔。
對B組學生播放m aterialB1。學生在口譯過程中,只能通過耳機獲取源語信息,然后根據提示音逐次傳譯。學生可以在必要的時候以筆記輔助記憶。實驗結束后,對該組學生的音頻也進行存檔。
實驗二。本實驗對象為A組所有學生。選用m aterialA2。本次除實驗材料外,其他實驗條件和實驗一中B組完全相同。實驗結束后,存檔所有學生的口譯音頻。
待所有實驗完成后,參照對原文信息的忠實程度、語言表達規范性、口譯技巧的運用、對語體基本特點的整體把握四個標準對不同實驗組的學生進行評分。本實驗需要分析的項目為:實驗一中A、B組學生測試成績比較;A組學生實驗一、二的測試成績比較。測試成績用SPSS做數據處理。
3 結果與討論
3.1 多模態情景下的視聽信息輸入模式與聽覺信息輸入模式的比較分析
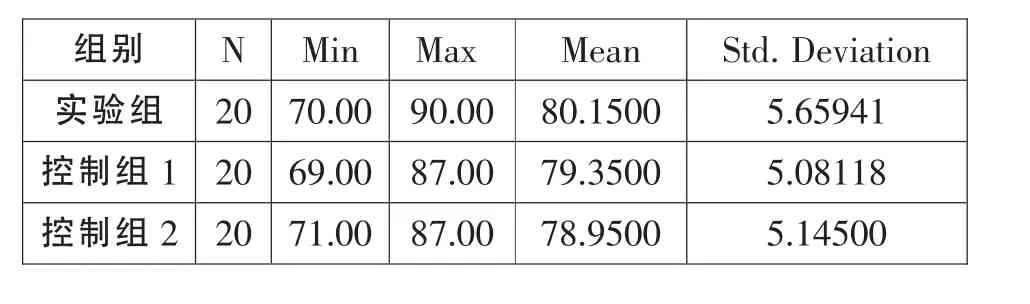
表1 實驗分組的平均分和標準差
所有受試成績均為有效數據,表1顯示三組實驗的平均分和標準差。通過比較發現,實驗組學生的平均分和標準差分別為80.15和5.66,均高于控制組1中的79.35和5.08,說明視聽同時輸入模式對受試口譯操作中的信息輸入、信息整合及譯語的表達起到了積極的作用,從而提高受試最終的口譯表現。但從標準差的結果看,實驗組受試高于控制組,說明視聽同時輸入的情況下,不同的受試由于各自不同的原因,在口譯時受到的不同影響比僅通過聽音信息輸入時要大,因此各受試的分數與平均分的偏離度變大。比較實驗組和控制組2,我們發現,對同一組受試先后采用視聽和聽覺信息輸入模式時,實驗結果也發生了變化。控制組2的標準差和平均分都低于實驗組。同時盡管實驗環境試驗材料難度基本相同,控制組2的標準差(5.14)略高于控制組1(5.08),但均分 (78.95)卻略低于控制組1(79.35),這主要是由于控制組2和實驗組受試群體相同,試驗一的視聽輸入對受試群體產生一定的影響,這也從側面說明視覺信息輸入模式對受試的影響。
結合三組實驗結果綜合分析發現,在聽音信息輸入模式下,受試的成績接近平均分,而在視聽信息輸入模式,受試的成績離散現象比較明顯。因此可以得出如下結論:由于兩組受試群體在平時的口譯學習和訓練中大都以聽覺信息輸入為主,因此對聽覺信息輸入都比較習慣,在兩組實驗中成績差異不會很大,但受試對于視覺信息的獲取各自具有不同的能力和技巧,因此最終的表現出現了明顯的差異。
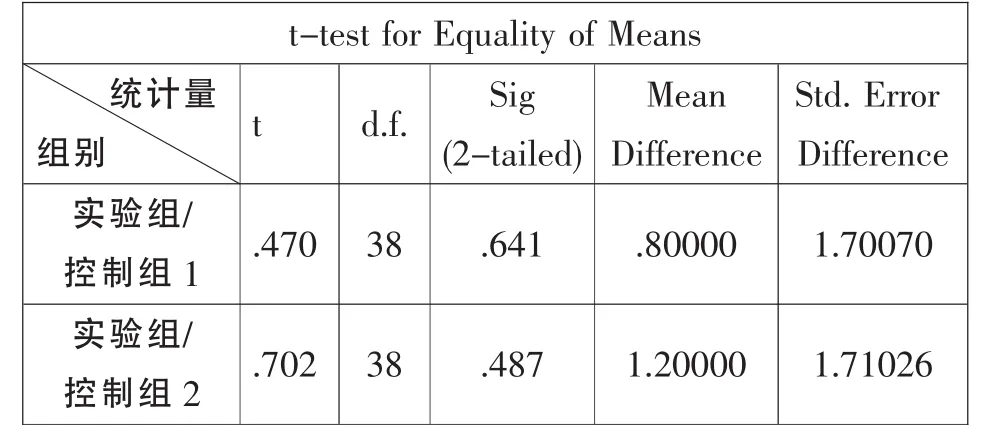
表2 實驗成績統計
對實驗組和控制組1的受試成績使用獨立樣本t檢驗,視聽同步輸入模式組與聽覺信息輸入模式組相比,測試成績不存在顯著性差異 (t=.47,d.f.=38,P=.641〉.05)。
對實驗組和控制組2的受試成績使用獨立樣本t檢驗,同一組受試在視聽同步信息輸入模式下與聽覺信息輸入模式下的成績也不存在顯著性差異 (t=.702,d.f.=38,P=.487〉.05)。
結合表1、表2的數據分析發現,實驗組成績均分高于控制組,但沒有顯著性差異。從標準差看,實驗組受試成績的標準差遠遠高于控制組,視聽同步信息輸入模式加大了口譯成績的離散度。因此,得出結論是,視聽同步輸入模式整體上提高了受試的口譯發揮 (成績)情況,大部分受試得益于視覺信息的輔助作用發揮良好,但個別受試在口譯過程中出現超常或失常發揮現象,因此造成了測試成績相對較高的離散度。我們可以推測,實驗組中大部分受試成績之所以略高于控制組中的受試,或者說差距不大主要是因為兩組受試平時的口譯訓練模式都是以聽覺信息輸入為主,但同時視覺信息的輸入不會對他們構成干擾。對于另外部分少數受試來說,視覺信息的輸入或構成干擾,或極大地刺激其視覺信息感知系統,與聽覺信息協同作用。
3.2 視聽輸入模式對實驗組整體影響的具體表現
本實驗中所選的視頻為奧巴馬2010年在上海復旦大學的演講。視頻畫面為實驗組受試提供了所選材料的背景知識、場景信息,方便了受試對發言人的身份、面部表情等信息的獲取,這對受試在實驗中的表現都起到積極的作用。
筆者將實驗材料中的信息依據意義的完整性標準切分為30個 “意義單位”(鮑剛,2005),每個意義單位都包含有完整的信息,其中數字、以數字標示的年份等和其他的語言單位分離出來,作為獨立的意義單位。本研究中,稱之為 “翻譯單位”或 “口譯單位”。我們分別對實驗組和兩個控制組受試的口譯情況進行統計,參照的標準是受試對每個 “口譯單位”的處理情況,統計的項目為各組受試處理 “口譯單位”時 “合格”的個數及占總數 (30)的比例。如表3所示。
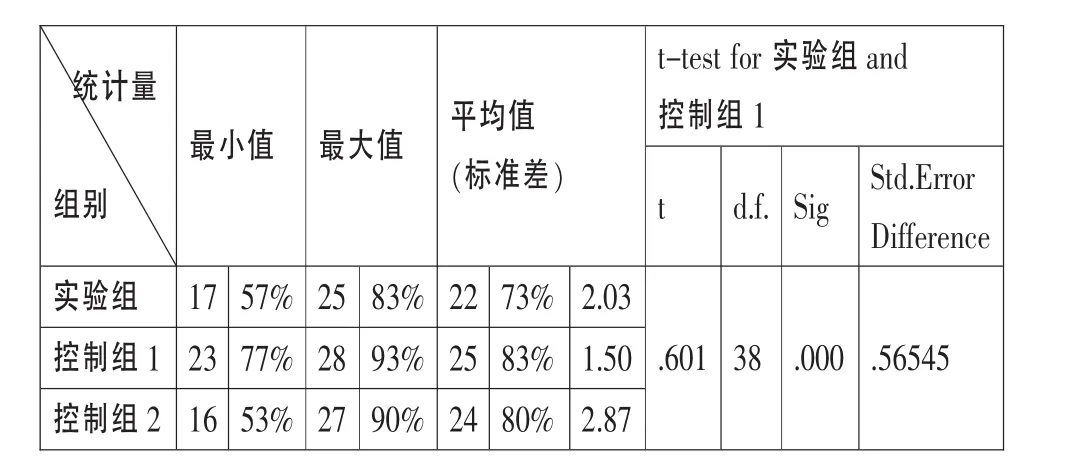
表3 受試對于 “口譯單位”處理的合格率
從表3可以看出,實驗組 (73%)受試對于 “口譯單位”處理的合格率低于控制組 (83%;80%),而3.1部分的數據表明實驗組受試口譯的總體表現是優于控制組的。實驗組中受試合格率標準差 (2.03)大于控制組1(1.50),說明視聽輸入模式增加了受試合格率相對于均值的偏離度,反映出受試在處理視聽信息時存在的個體差異要比控制組大。此外,實驗組和控制組1中的數據符合正態分布,獨立樣本t檢驗發現這兩組數據之間具有顯著性差異 (t=.601;d.f. =38;p=.000〈.05)。結合實驗后的訪談,得出如下結論:在視聽同步輸入模式下,受試的注意力重心放在對原文信息的整體把握上,因此翻譯的譯文文本邏輯性和連貫性都比較好;但同時對于數字、關鍵詞語的捕捉上存在問題,而對于聽音組來說,口譯時受試更專注于語言形式及信息單位的獲取。評價口譯的主要指標是譯員是否傳遞出了源語的交際意圖,之后再看譯員對于細節的把握是否到位,因此出現上述總體表現和合格率不一致現象。
此外,不同的信息輸入模式對受試的理解和記憶方面的影響是不同的。實驗組中,受試對待翻譯信息的獲取和理解要優于對照組。但信息量超過受試的信息處理能力后便給受試造成記憶負擔,導致受試分掉部分的注意力用于已聽信息的記憶而影響對后續信息的接收。相比之下,聽音輸入模式下受試注意力要相對集中于語言信息的聽覺接收和記憶,多偏于機械性記憶而非下意識的理解記憶,在口譯結束后,很難對剛傳譯的信息進行整體構建。但從表1中的平均分看,視聽信息輸入模式對于受試的理解和記憶的總體影響并不明顯。
4 結語
本研究對兩組各20名受試學生分別進行視聽/聽音口譯對比研究,并采用統計軟件SPSS對實驗數據進行分析。研究結果顯示,視聽組學生的總體口譯質量比聽音組學生的口譯質量高,但并不是很明顯;同時,視聽同步輸入對個別受試在一定程度上構成干擾。視聽同步輸入模式下視覺信息對受試的理解和記憶有積極的影響,但不是很明顯。視聽同步輸入可以提高受試對源語意義的整體理解和意義構建,但對源語中細節信息給予的關注度較對照組要小。
口譯質量是比較宏觀的概念,對其進行嚴格界定需要多維度的深度研究,受試的理解和記憶也是一個復雜的心理過程。此外,本研究數據處理對象為各組受試的口譯成績,盡管取多次打分的平均分,仍然無法排除打分過程中主觀性因素對最終結果的影響。另外受試對象僅為一所高校的學生,且由于設備所限,受試人數不多,因此所得結果缺乏一定的代表性。
將多模態理論用于口譯的研究目前尚處于起步階段,相關的文獻也很少。本文是運用多模態理論對口譯進行嘗試性研究。在高校口譯教學中,教師可根據學生水平,選擇適當難度的視頻作為口譯訓練材料,培養學生在視頻場境下獲取信息和理解能力,為今后的口譯實踐打下良好的基礎。鑒于此,本研究所得出的結論對現行的高校口譯教學實踐和口譯教學模式的革新具有一定的借鑒意義。
[1]Halliday,M.A.K.An Introduction to Functional Grammar[M].London:Oxford University Press,2004.
[2]Kress,G.amp;T.Wan Leeuwen.Mu ltim odalDiscourse:The Mode and Media of Contemporary Communication[M]. London:Arnold,2001.
[3]鮑 剛.口譯理論概述[M].北京:中國對外翻譯出版公司,2005.
[4]胡壯麟.社會符號學研究中的多模態化[J].語言教學與研究,2007,(1):1-9.
[5]胡壯麟.多模態小品的問世的研究與發展[J].外語電化教學,2010,(4):3-9.
[6]劉和平.口譯理論與教學研究現狀及展望[J].中國翻譯,2005,(2):17-18.
[7][法]賽萊斯科維奇.口譯技藝:即席口譯與同聲傳譯經驗談[M].黃為忻,錢慧杰譯.上海:上海翻譯出版公司,1992.
[8]葉起昌.超文本多語式的社會符號學分析[J].外語教學與研究,2006,(6):437-442.
[9]張 文,韓常慧.口譯理論研究[M].北京:科學出版社,2006.
H051
A
1674-3 652(2012)09-0 105-0 4
2012-07-24
李 彬,女,江蘇徐州人,主要從事英語語言文學和英漢翻譯研究。
[責任編輯:何 來]
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
中外會展(2014年4期)2014-11-27 07:46:46
計算物理(2014年2期)2014-03-11 17:01:39
外語學刊(2010年2期)2010-01-22 03:31:03
