多格式文檔搜索引擎索引系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
2012-11-21 11:38:04方躍勝姚宏亮
長(zhǎng)江大學(xué)學(xué)報(bào)(自科版) 2012年19期
方躍勝 董 輝 姚宏亮
(安徽水利水電職業(yè)技術(shù)學(xué)院電子系,安徽 合肥 231603) (亳州職業(yè)技術(shù)學(xué)院信息工程系,安徽 亳州 236800) (合肥工業(yè)大學(xué)計(jì)算機(jī)與信息學(xué)院,安徽 合肥 230009)
多格式文檔搜索引擎索引系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
方躍勝 董 輝 姚宏亮
(安徽水利水電職業(yè)技術(shù)學(xué)院電子系,安徽 合肥 231603) (亳州職業(yè)技術(shù)學(xué)院信息工程系,安徽 亳州 236800) (合肥工業(yè)大學(xué)計(jì)算機(jī)與信息學(xué)院,安徽 合肥 230009)
隨著Internet和計(jì)算機(jī)的迅猛發(fā)展,搜索引擎應(yīng)需而生,越來越多的企業(yè)利用計(jì)算機(jī)處理運(yùn)營(yíng)過程中產(chǎn)生的大量電子文檔。如何從這些網(wǎng)絡(luò)和多格式文檔資源中迅速、方便而準(zhǔn)確地檢索出企業(yè)用戶所需的信息已成為越來越重要的問題。索引系統(tǒng)是搜索引擎的核心,為提高系統(tǒng)的查全率和查準(zhǔn)率,設(shè)計(jì)了一種適用于文檔檢索的數(shù)據(jù)庫(kù)存儲(chǔ)的索引結(jié)構(gòu)并建立索引庫(kù)來降低索引組織的復(fù)雜度,通過布爾邏輯和向量空間的組合模型實(shí)現(xiàn)對(duì)檢索結(jié)果排序,以返回最優(yōu)文檔列表。該系統(tǒng)在Windows環(huán)境下采用PHP開發(fā)組件實(shí)現(xiàn),能夠提高檢索文檔的查全率和查準(zhǔn)率。
文檔搜索引擎;索引同步;檢索模型
隨著Internet和計(jì)算機(jī)的日益發(fā)展,搜索引擎已成為人們獲取海量網(wǎng)絡(luò)信息的主要工具。按照“快、全、準(zhǔn)、穩(wěn)”的評(píng)測(cè)標(biāo)準(zhǔn),目前的許多搜索引擎已經(jīng)不能滿足人們的需求[1]。此外,越來越多的企業(yè)開始利用計(jì)算機(jī)處理企業(yè)的運(yùn)營(yíng)過程中產(chǎn)生的大量電子文檔。如何從網(wǎng)絡(luò)和多格式的文檔資源中迅速準(zhǔn)確地檢索出企業(yè)用戶所需的信息已成為越來越重要的問題。因此,開發(fā)快速準(zhǔn)確和智能化的搜索引擎是目前的研究熱點(diǎn),而搜索引擎設(shè)計(jì)中的重要工作是建立索引系統(tǒng),其目的是能夠快速地響應(yīng)用戶的查詢。為此,筆者對(duì)多格式文檔搜索引擎的索引系統(tǒng)進(jìn)行了研究。
1 索引構(gòu)建
1.1索引數(shù)據(jù)庫(kù)設(shè)計(jì)

圖1 倒排表結(jié)構(gòu)
1)文檔表 文檔表包含文檔編號(hào)(File_ID)和文檔名稱(File_Val)2個(gè)字段。
2)關(guān)鍵詞表 關(guān)鍵詞表包含關(guān)鍵詞編號(hào)(KeyWord_ID)和關(guān)鍵詞(KeyWord_Val)2個(gè)字段。
3)倒排表 倒排表是索引數(shù)據(jù)庫(kù)的核心部分,其結(jié)構(gòu)如圖1所示。
1.2索引組織設(shè)計(jì)
1)倒排表存儲(chǔ) 針對(duì)倒排表存儲(chǔ)的問題,提出了以下3種設(shè)計(jì)方案:①直接將倒排表放入內(nèi)存;②將倒排表存入硬盤上的文件;③將倒排表及必要的文件存入數(shù)據(jù)庫(kù)(此處使用MySQL)。由于數(shù)據(jù)量很大,綜合考慮各個(gè)方面的算法,決定采用方案③,同時(shí)在具體實(shí)現(xiàn)過程中,對(duì)二維數(shù)組采用分組的方法來實(shí)現(xiàn)對(duì)索引文件的存儲(chǔ)。使用數(shù)據(jù)庫(kù)來代替文件流,可使插入、刪除、查詢等操作更加方便、高效。
在具體實(shí)現(xiàn)倒排表存儲(chǔ)時(shí)基于以下思想[2]:建立多個(gè)數(shù)據(jù)表,其中每個(gè)表有2001個(gè)字段,每篇文檔作為一個(gè)數(shù)據(jù)插入,其中第一個(gè)字段作為文檔編號(hào),后面所有的數(shù)據(jù)以0作為標(biāo)志,為0則該文檔不含有對(duì)應(yīng)的詞,否則含有。數(shù)據(jù)庫(kù)中的倒排表有多個(gè)數(shù)據(jù)表組成,具體設(shè)計(jì)時(shí)應(yīng)注重以下幾個(gè)方面:①表與表之間的聯(lián)系。將所有的文檔都作為數(shù)據(jù)量插入表中,各個(gè)表唯一的不同是關(guān)鍵詞編號(hào),因而可將2000作為一個(gè)單位標(biāo)志分別將表命名為Inverted_0、Inverted_1、…,使得各個(gè)表互相聯(lián)系。②處理文檔與關(guān)鍵詞在數(shù)據(jù)庫(kù)中的存儲(chǔ)方式。對(duì)于文檔,在存儲(chǔ)的時(shí)候直接存儲(chǔ)其在服務(wù)器中的位置信息,以數(shù)據(jù)庫(kù)自動(dòng)為其添加的ID作為主鍵;對(duì)于關(guān)鍵詞,使用ID和關(guān)鍵詞本身來存儲(chǔ)關(guān)鍵詞。③對(duì)文檔和關(guān)鍵詞的插入和刪除的處理。對(duì)關(guān)鍵詞的插入和刪除就是對(duì)字段的插入和刪除處理,而對(duì)文檔的插入和刪除即為對(duì)數(shù)據(jù)的插入和刪除處理。
2)建立關(guān)鍵詞表 建立關(guān)鍵詞表的流程如圖2所示。

圖2 建立關(guān)鍵詞表流程圖
3)插入關(guān)鍵詞 插入關(guān)鍵詞的步驟如下:①將所有的關(guān)鍵詞讀入數(shù)據(jù)庫(kù);②將文檔插入文檔表,同時(shí)運(yùn)用已經(jīng)寫好的倒排算法將文檔插入上一步形成的空的倒排表;③在查找過程中首先讀取關(guān)鍵詞,查到其在關(guān)鍵詞表中的ID,然后在倒排表中讀取該詞的ID遍歷這一行,最終得到該詞所在文檔的編號(hào)。具體實(shí)現(xiàn)算法[3]:對(duì)于給定的關(guān)鍵詞,如果不為空,首先將關(guān)鍵詞插入關(guān)鍵詞表;判斷關(guān)鍵詞標(biāo)志量flag_word 是否為“1”,若是則建立新的倒排表,否則進(jìn)入下一步;將當(dāng)前的關(guān)鍵詞插入當(dāng)前的倒排表中的列屬性中,同時(shí)使關(guān)鍵詞標(biāo)志量flag_word 加“1”;如果關(guān)鍵詞標(biāo)志量flag_word越界,將關(guān)鍵詞標(biāo)志量flag_word量置“1”,同時(shí)使倒排表標(biāo)志量flag_table加“1”。
4)建立多個(gè)倒排表 建立多個(gè)倒排表的具體流程如圖3所示。
5)建立文檔表 建立一個(gè)文檔表,向其中添加文檔,同時(shí)在數(shù)據(jù)庫(kù)中形成了一些類似二維數(shù)組的多個(gè)倒排表。在向表中插入文檔的同時(shí),對(duì)每一個(gè)文檔進(jìn)行遍歷。
6)向倒排表插入數(shù)據(jù) 向倒排表中插入數(shù)據(jù)的流程如圖4所示。
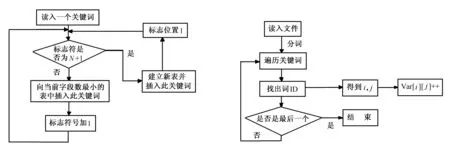
圖3 建立多個(gè)倒排表流程圖 圖4 向倒排表中插入數(shù)據(jù)流程圖
1.3索引同步設(shè)計(jì)
1)關(guān)鍵詞同步 對(duì)所有的關(guān)鍵詞用ELFHash()函數(shù)[4]運(yùn)算,計(jì)算出每個(gè)關(guān)鍵詞的散列碼。將相同散列碼的關(guān)鍵詞存在散列表的同一個(gè)位置,并記錄其所在文檔信息。在關(guān)鍵詞同步的存儲(chǔ)結(jié)構(gòu)中建立了2個(gè)數(shù)組,其中1個(gè)用來存儲(chǔ)關(guān)鍵詞,另1個(gè)用來存儲(chǔ)與關(guān)鍵詞索引值相同的文檔編號(hào),使其一一對(duì)應(yīng)。在程序運(yùn)行的過程可以直接通過array_search()函數(shù)[5]來查找到相應(yīng)的關(guān)鍵詞及其對(duì)應(yīng)的文檔信息。在程序運(yùn)行的過程中,首先初始化關(guān)鍵詞數(shù)組并建立文檔類的數(shù)組并使其一一對(duì)應(yīng),然后遍歷所有的文檔并將關(guān)鍵詞所在文檔添加進(jìn)入文檔類數(shù)組。在遍歷文檔時(shí),得到該文檔分詞后的某一個(gè)關(guān)鍵詞,判斷關(guān)鍵詞所在文檔是否在文檔數(shù)組中的對(duì)應(yīng)位置。若在其對(duì)應(yīng)的位置則證明該文檔已經(jīng)添加進(jìn)入其對(duì)應(yīng)位置,不再作任何處理;若不在其對(duì)應(yīng)位置,則將其信息添加進(jìn)文檔數(shù)組。同步流程圖如圖5所示。
2)文檔同步 對(duì)于文檔同步,應(yīng)建立一個(gè)關(guān)鍵詞類的數(shù)組,用數(shù)組的下標(biāo)作為文檔的編號(hào),存儲(chǔ)關(guān)鍵詞在該文檔中出現(xiàn)的次數(shù)、位置等信息。在程序運(yùn)行的過程中,對(duì)分詞后的關(guān)鍵詞數(shù)組進(jìn)行遍歷得到某一個(gè)關(guān)鍵詞,然后判斷該關(guān)鍵詞是否在該篇文檔的關(guān)鍵詞數(shù)組中,如果在數(shù)組中就添加其位置信息,如果不在數(shù)組中則添加本關(guān)鍵詞及其位置信息進(jìn)入關(guān)鍵詞數(shù)組中。
2 索引檢索
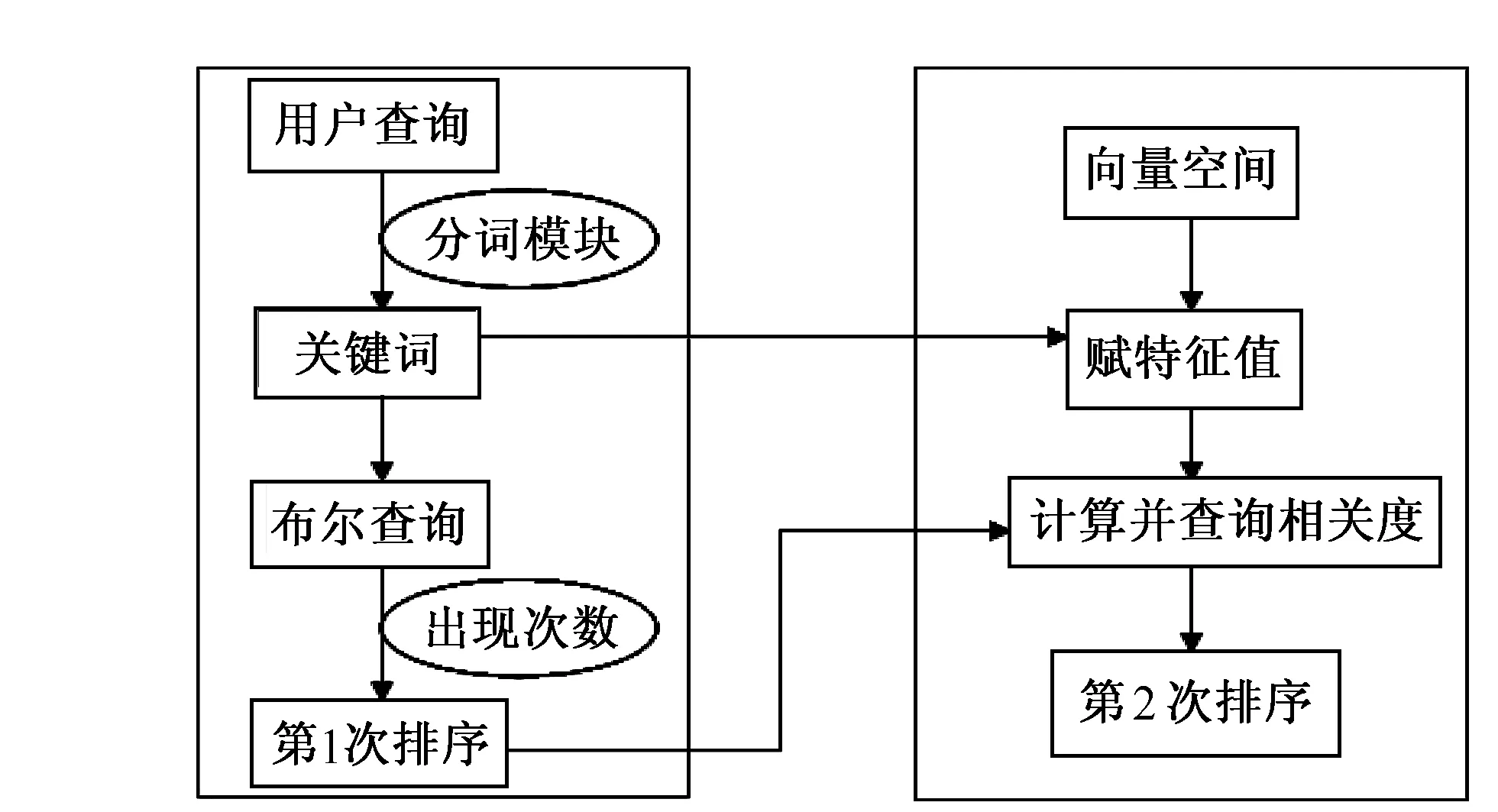
圖5 信息檢索組合模型
該系統(tǒng)采用基于詞索引的中文全文檢索,信息檢索模型采用布爾邏輯和向量空間的組合模型,設(shè)計(jì)思想如下(以法律文檔查詢?yōu)槔?:①首先用布爾邏輯檢索模型將用戶查詢通過基于Memcached的動(dòng)態(tài)四字雙向詞典機(jī)制的分詞系統(tǒng)切分成關(guān)鍵詞序列;②將這些關(guān)鍵詞組成布爾查詢語(yǔ)句;③利用數(shù)據(jù)庫(kù)查詢,到索引庫(kù)中取出包含這些關(guān)鍵詞的所有案例,并按照關(guān)鍵詞在每一個(gè)案例中出現(xiàn)的次數(shù)對(duì)所有的案例進(jìn)行第1次排序,取出關(guān)鍵詞出現(xiàn)次數(shù)最高的前50個(gè)案例作為第2次排序的依據(jù);④建立一個(gè)向量空間;⑤對(duì)上一步分出來的關(guān)鍵詞作為向量空間的特征表示集,形成1個(gè)N維向量,其中每1維作為1個(gè)特征;⑥對(duì)第1次排序中的前50個(gè)案例利用TFIDF公式[6]分別計(jì)算其與查詢的相關(guān)度;⑦根據(jù)相關(guān)度高低對(duì)這50個(gè)案例進(jìn)行第2次排序,并與其它案例一起返回給用戶。組合信息檢索模型如圖5所示。該模型不僅能解決布爾邏輯檢索模型對(duì)查詢結(jié)果排序不準(zhǔn)確的問題,而且能提供比向量空間模型更快的查找速度,滿足用戶對(duì)系統(tǒng)響應(yīng)速度的要求,同時(shí)還可以降低系統(tǒng)運(yùn)行成本。
3 系統(tǒng)實(shí)現(xiàn)
該系統(tǒng)在Windows環(huán)境下采用Apache+PHP+MySQL黃金搭檔來實(shí)現(xiàn):類Inverted函數(shù)Create_DB()實(shí)現(xiàn)數(shù)據(jù)庫(kù)功能,Create_KeyWord_Table()函數(shù)實(shí)現(xiàn)初始的關(guān)鍵詞表功能,Create_File_Table()實(shí)現(xiàn)初始的文檔表功能,Create_InvertedTable($var)實(shí)現(xiàn)倒排表的功能,從而實(shí)現(xiàn)數(shù)據(jù)庫(kù)的初始化。當(dāng)更新數(shù)據(jù)庫(kù)時(shí),調(diào)用Insert_Dir()函數(shù),將文件夾中所有文檔都輸入數(shù)據(jù)庫(kù),文檔為經(jīng)過分詞后的txt文件。函數(shù)Insert_Dir()首先將文件名插入file表,然后讀取文件將其中的詞插入關(guān)鍵詞表,同時(shí)更新倒排表內(nèi)容,記錄關(guān)鍵詞在文檔中的出現(xiàn)次數(shù)與位置。檢索時(shí),對(duì)輸入內(nèi)容首先進(jìn)行分詞和去停用詞處理,然后對(duì)數(shù)據(jù)庫(kù)中文檔運(yùn)用綜合模型分析、計(jì)算以確定輸出。
4 結(jié) 語(yǔ)
隨著Internet和計(jì)算機(jī)的迅猛發(fā)展,許多企業(yè)利用計(jì)算機(jī)處理運(yùn)營(yíng)過程中產(chǎn)生的大量電子文檔。為了從網(wǎng)絡(luò)和多格式文檔資源中迅速準(zhǔn)確地檢索出所需信息,設(shè)計(jì)了一種適用于文檔檢索的數(shù)據(jù)庫(kù)存儲(chǔ)的索引結(jié)構(gòu),通過建立索引庫(kù)來降低索引組織的復(fù)雜度,利用布爾邏輯和向量空間的組合模型對(duì)檢索結(jié)果排序并返回最優(yōu)文檔列表,系統(tǒng)在Windows環(huán)境下采用PHP開發(fā)組件實(shí)現(xiàn)。實(shí)際運(yùn)行表明,該系統(tǒng)能夠提高檢索文檔的查全率和查準(zhǔn)率。
[1]鄭榕增,林世平. 基于Lucene的中文倒排索引技術(shù)的研究[J].計(jì)算機(jī)技術(shù)與發(fā)展,2010(3):55-56.
[2]楊安生.基于倒排表的中文全文檢索研究[J].情報(bào)探索,2009(7):77-80.
[3]陳海波.基于自動(dòng)分詞的企業(yè)文檔搜索引擎設(shè)計(jì)與實(shí)現(xiàn)[D].西安:西北工業(yè)大學(xué),2007.
[4]肖麗.哈希查找中散列函數(shù)的運(yùn)用[J].技術(shù)與市場(chǎng),2009,16(8):18-19.
[5]曹衍龍,趙斯思.PHP網(wǎng)絡(luò)編程技術(shù)與實(shí)例[M].北京:人民郵電出版社,2006.
[6]熊回香,夏立新.基于詞索引的中文全文檢索關(guān)鍵技術(shù)及其發(fā)展方向[J].中國(guó)圖書館學(xué)報(bào),2007,33(4):47-51.
10.3969/j.issn.1673-1409(N).2012.07.038
TP391
A
1673-1409(2012)07-N111-03
2012-04-24
國(guó)家自然科學(xué)基金資助項(xiàng)目(60705015)。
方躍勝(1975-),男,1999年大學(xué)畢業(yè),講師,碩士生,現(xiàn)主要從事中文分詞與索引關(guān)鍵技術(shù)方面的教學(xué)與研究工作。
[編輯] 李啟棟
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
中國(guó)衛(wèi)生(2015年12期)2015-11-10 05:13:38
新疆大學(xué)學(xué)報(bào)(自然科學(xué)版)(中英文)(2014年2期)2014-11-06 07:49:12
