基于非線性關系的稅務自發任務分發應用的算法分析與Oracle 實現
2013-03-20 08:24:54朱愛民
稅收經濟研究 2013年3期
◆孫 利 ◆朱愛民
一、引 言
稅務任務分發應用是工作流的一種,工作流的概念源自企業的生產經營管理與辦公自動化領域。稅務任務分發應用通過記錄對稅務機關在稅收征管活動中具有上下層級順序的若干涵蓋多部門、多人員的工作流及工作流變化過程,監督與控制稅務機關的整個任務落實過程諸如上傳下達完成等環節流程的執行時間、效率與結果。通過對任務分發過程與結果的信息分析利用,進行稅收征管業務流程再造,實現高水平的稅務信息化建設。
二、非線性的稅務任務分發應用與一般稅務任務應用的區別
一般稅務任務應用是按照始于納稅人需求的納服體系建設要求設計的業務流程,通常是從納稅人的申請與納服部門的受理開始,中間經過調查、核實、報批、審批等節點,最終回到納服部門反饋納稅人結果為結點的過程。如圖1 所示:
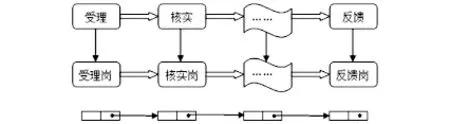
圖1 一般稅務任務應用
圖1 顯示了一般稅務任務應用中節點與崗位的關系。在實際運用中,通過設計不同事項途經不同的節點以及不同的操作人員對應的崗位,實現從對納稅人申請的受理開始任務的傳遞流程。這種業務流程實現的是一種線性關系,其結構是鏈表式的基本數據結構,流程按順序訪問一組數據項的集合,這些數據項形成一個鏈表,每個元素都含有訪問下一個元素所需的信息。要訪問鏈表的信息,只需要引用鏈表的指針和結構體的成員名即可。
從稅務機關內部發起的自發任務分發應用則不同。一項從內部發起的征管任務,從發起者開始,到最終履行者,任務逐級推送,涉及人員逐級增長,內容逐步明晰,其業務流程實現的是非線性關系,所呈現的樹圖如圖2 所示。
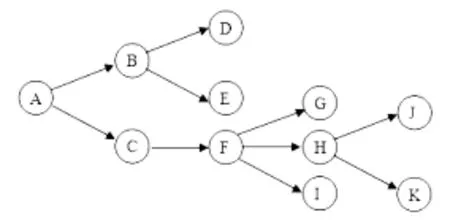
圖2 稅務機關自發任務分發應用的樹圖
其基本特征有:
特征1.1 稅務自發任務分發應用是樹的應用。
稅務自發任務分發應用是由n 棵互不相交的樹組成的集合,即森林;每一棵樹是一棵有向樹,每棵樹的每個節點有零或多個子節點,每個子節點有且僅有一個父節點,在樹的根與其他節點之間、父節點與子節點之間有且僅有一條路徑。
特征1.2 稅務自發任務分發應用是有序樹。
有一個結點的入度為0,其余所有結點的入度都為l,是一個有根樹,雖不是自由樹,但作為一個為每個子結節規定從左到右次序的有序樹,則在實際中未必有必要性。
特征1.3 稅務自發任務分發應用是M 叉樹。
作為一個M 叉樹,每一個節點的出度小于或等于m,子節點的數目并不確定。 從行業應用來看,稅務自發任務分發應用有以下特征:
特征2.1 樹的根、層數、不同層數的節點均存在不確定性。
不同層級的稅務機關下發任務時,其根、層數與不同層數的節點均不確定。不同的任務,也產生同樣的不確定性。以節點落實到具體數據的不確定性為例:有的任務是指定數據的,例如對全國重點稅源納稅人的管理任務,表現為數據量固定不變;有的任務是從一批指定數據到另一批指定數據,如從風險識別->風險推送->風險應對,呈數據量衰減趨勢;有的任務是從文字描述發起到具體數據的落實過程,呈數據量增長趨勢。
特征2.2 目標是實現以任務自身為核心的柔性的任務分發功能。
基于特征2.1,稅務自發任務分發應用的目標是實現以任務自身為核心而非任務內容為核心的、柔性的而非剛性的任務分發功能。在核心功能實現的基礎上,兼顧任務內容所落實的具體數據信息,實現系統的完整性。
三、基于實際稅務應用的表設計
如果從存取類似稅務任務分發這樣的應用來說,無疑一些NoSQL 數據庫,例如文檔型數據庫是更好的解決方案。NoSQL 數據庫與關系型數據庫相比,更偏重于數據存取和問題的解決,而非像關系型數據庫那樣基于關系模型、側重于分析數據與數據之間的關系和結構。關系型數據庫雖然不是唯一的高級數據庫模型,也不是性能最優的模型,但是因為功能兼顧,易于理解和使用,已成為目前使用最廣泛的主流數據庫,包括在稅務系統的應用。本文也以關系數據庫為例說明。
稅務自發任務分發應用需要的基本信息有:
1.任務信息
任務有發起時間、發起部門、類型、完成任務的數量要求、質量要求、時限要求等信息,因此,需要一個任務表(tasks),如表1:

表1 任務表
2.任務狀態信息
在業務流程設計上,任務分發的正常流程包括:生成->下發->未讀->已讀->(轉發)->申請完成->完成,其業務邏輯為從任務制訂為起點,把任務下發給指定對象,指定對象是否閱讀的狀態用于監控接收任務對象的工作流。指定對象收到任務后,決定是否要轉發任務,對轉發的任務,原任務處于轉發狀態,再重新生成新的任務。接收任務方完成任務后,向任務發起方提交任務完成申請,由任務發起方設定任務完成狀態。
非正常的業務邏輯有申請退回、刪除、凍結等。
任務狀態表(states)用于保存任務的狀態,如表2:

表2 任務狀態表
3.任務分發人員信息
由于稅務任務分發時,常常需要分發同一任務給多個接收人員,因此需要任務分發人員信息表(operators)記錄任務分發人員的信息,對下發人員、接收人員進行記錄,如表3:

表3 任務分發信息表
4.任務內容/附件信息
在解決了核心問題后,通過任務內容或附件表(attachments)的形式,記錄任務相關的內容與附件,為精細化處理任務保存信息,如表4:

表4 任務附件表
稅務自發任務分發應用的E-R 圖如圖3 所示。

圖3 表設計的E-R 圖
為便于描述,以上數據表設計均以單樹為例,未加入總任務號字段來標識區分多樹。
四、任務分發應用的算法
對以上通過保存任務號+父任務號信息的形式實現的最基本的稅務任務分發應用的數據表結構,我們運用的最基本的算法即是任務的遍歷。通過任一任務的節點,系統地處理任務里的每一節點。有三種基本的順序來遍歷節點:
先序:先訪問根節點或父節點,再訪問子節點。
中序:通過父節點得到所有同層子節點,然后訪問子節點。
后序:先訪問子節點,再訪問父節點直至根節點。
通過遞歸可以實現以上遍歷方法,如圖4 所示(圖左為先序遍歷,右為后序遍歷):
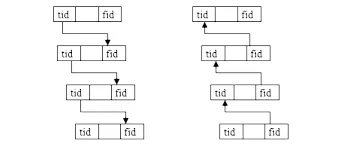
圖4 遞歸遍歷圖示(tid/fid 分別為子節點與父節點)
在最簡數據表結構的基礎上實現的遍歷,雖然可以采取三個遍歷方法,但實際使用以后序法為主。因數據表結構中保存的信息僅有父信息與子信息,要從任一節點出發,只能跟蹤鏈接逐一從一個節點移到上一節點。從數據庫運行來說,即每次節點的移動就是對數據庫的一次檢索,如果一個任務有N 個節點,對該任務的一次遍歷訪問數據庫也不會少于N 次。
因此,我們還可以看到在基本數據表結構的基礎上,為解決遍歷效率問題而衍生的另外幾種擴充數據表結構,用于實現任務分發應用的參考:
1.加路徑信息
例如在前面的tasks 表中增加路徑信息字段paths,定義為AA(-BB-CC……)的結構,如00-00-00 為根節點(或00),第一層的左節點為00-01-00(或00-01),右節點為00-02-00(或00-02),依次類推,也可不補零。在檢索時,通過SQL 語句SELECT * FROM tasks WHERE paths LIKE SUBSTR(@path,1,2) ORDER BY paths 在任一節點可以僅訪問數據庫一次即可檢索整棵樹。但其缺點也很明顯,即路徑字段寬度受到層數和子節點個數的限制,僅適用固定層數的樹遍歷。
2.加層數信息
通過增加層數和根節點信息,有利于提高中序檢索的效率。如在前面的tasks 表中增加層數信息字段layer 和根節點信息字段root,通過SQL 語句SELECT * FROM tasks WHERE root=@root AND layer=@layer AND father_id=@father_id 在任一節點訪問數據庫可以得到中序遍歷的結果。其缺點是數據冗余嚴重。
3.設置左右代碼信息。
在tasks 表中增加表示左右信息的字段left 和right,left 數據以根節點為1 開始,從根節點沿子節點路徑向下,每個節點加1,到樹葉后,再沿子節點向上,right 數據在每個節點加1,通過SQL 語句SELECT * FROM tasks WHERE left>@left AND right<@right 可以得到中序遍歷的檢索結果。從算法上是一種新穎的設計,但目前僅適用二叉樹,且不適應節點的刪改變更。
綜上幾種數據表結構設計,從算法來看可以獲得不同的遍歷效率,但從實際運用來看,則是耦合度越高,容錯度就越低。
五、Oracle 實現舉例
Oracle 數據庫是關系型數據庫,不能像層次型數據庫那樣存放層次關系。但Oracle 數據庫提供了強有力的層次查詢(Hierarical Retrival)功能,可以高效地獲得層次關系信息。以Oracle10g 為例,可以實現用先序、中序、后序各種方法遍歷樹,其實現方法為:通過查詢子句START WITH 確定起始節點位置;通過查詢子句CONNECT BY 確定遍歷方向,先序或后序。
SQL 語句語法為:

Oracle 提供了一個用于層次檢索的虛擬列level,與CONNECT BY 子句共用,通過level 列可以獲得樹的層數值。
檢索的遍歷方向根據CONNECT BY 后的PRIOR 在哪個節點前確定。如在子節點前,則為先序;如在父節點前,則為后序。如子句為CONNECT BY PRIOR son_id=father_id 或CONNECT BY father_id=PRIOR son_id 時,則其方向為先序遍歷,按START WITH 子句指點的節點按路徑逐一向下遍歷;如子句為CONNECT BY son_id= PRIOR father_id 或CONNECT BY PRIOR father_id=son_id 時,則其方向為先序遍歷,按START WITH 子句指點的節點按路徑逐一向上遍歷,但遍歷的范圍僅限于同一父節點為止。
例如在表tasks 中,從father_id 為空處(表示根節點)開始進行先序檢索:

檢索結果如表5:

表5 檢索結果
使用DELETE 語句結合START WITH 和CONNECT BY 子句,實現對指定節點的子節點刪除。
Oracle10g 在層次查詢上的一個新增功能是引入了CONNECT_BY_ISLEAF 函數,通過函數值判斷指定節點是否為樹的葉子。函數值為0 時,非葉子;函數值為1 時,為葉子。
如按先序檢索tasks 表中father_id=1 開始的子節點信息,并顯示其是否為葉子:

Oracle10g 對層次查詢中可能發生的遞歸死循環,即互為父子節點的情況,使用NOCYCLE 關鍵字進行干預,而且可以通過CONNECT_BY_ISCYCLE 關鍵字的值查詢在哪個節點發生了死循環。
六、結語
本文分析基于非線性關系的稅務機關自發任務分發應用的算法,并在實際稅務應用的基礎上,給出了基本的數據表設計,通過Orcale 實例,說明了應用的實現效果。文章表明了非線性關系的稅務機關自發任務分發系統的實現可能性、可靠性與可維護性,為最終實現該應用提供了堅實的基礎。
[1][美]塞奇威克.算法Ⅰ-Ⅳ 基礎、數據結構、排序和搜索[M].張銘澤等譯.北京:中國電力出版社,2004.
[2][美]科曼.算法導論[M].潘金貴等譯.北京:機械工業出版社,2006.
[3]Iggy Fernandez.Beginning Oracle Database 11g Administration[M].USA CA:APRESS,2009.
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
財經(2010年20期)2010-10-19 01:48:32
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
