幀間差分相位譜幀長和幀移的最優設置方法
2013-04-12 00:32:38王金芳聶新禮
吉林大學學報(工學版) 2013年1期
王金芳,虢 明,聶新禮
(吉林大學通信工程學院,長春130012)
說話人識別是一種利用語音識別人身份的技術,處理過程分為訓練和測試。訓練是指從語音中提取出能表征說話人個性的特征并建立模型的過程,測試是指將待測試語音與已建立的模型匹配以判斷此說話人身份的過程。說話人識別分為說話人鑒定和說話人確認。由于相位卷繞(Wrapping)等問題[1-3],目前大多數特征的提取都是利用語音的幅度信息,很少顧及相位。最近可懂度測評實驗[4]表明了語音相位的重要性,在合理選擇幀長(100~1000 ms)的條件下,短時相位譜對人類感知有不可忽視的作用[5-8],且在相位分析方面矩形窗明顯優于其他窗函數[8-10]。分別對短時相位譜取時間、頻率微分得到兩種常用參數,瞬時頻率[11-12]和群時延[13]。無論何種參數,幀長和幀移的選取極大地影響語音信號短時相位譜。McCowan等[14]提出從相鄰幀間相位譜差中提取特征,指出幀長和幀移參數的設置需在相位突變檢測能力和相位噪聲兩方面進行折中考慮,但其參數設定僅依靠經驗分析。
利用互信息理論[15]選擇說話人識別特征,已進行了一定的研究[16-17],在此基礎上,本文提出利用短時幅度譜和Mel頻率Delta相位倒譜系數(Mel-Frequency Delta-Phase Cepstral Coefficients,MFDPs)間互信息確定幀長和幀移的方法。這里雖以MFDP特征為例,但同樣適用于其他基于短時相位譜的特征提取,仿真實驗驗證了其可靠性。
1 Mel頻率幀間差分相位倒譜系數
語音信號為s(n),其短時離散傅里葉變換定義為

式中:m是幀索引;w(n)表示長為的窗函數;D指幀移(滿足D≤T)。與幅度不同的是,窗函數對相位有影響,并且同一語音信號各幀間無共同時間參考點,解決方法是對短時相位譜進行補償。定義幀間差分相位譜

以幀間差分相位譜的絕對值|ΔΨm(k)|代替幅度譜按照Mel頻率倒譜處理方法提取MFDP特征,其性能僅略低于基于幅度譜的MFCC特征[14]。
2 相位譜參數確定
2.1 互信息
離散隨機變量的信息熵H(X)定義為

式中:p(xi)=p{X=xi}表示隨機變量X取值為xi的概率。
在隨機變量Y條件下X的平均條件熵定義為
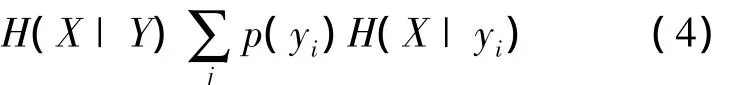

兩個隨機變量X、Y所構成的信息集合間的相關性可用互信息來衡量,定義為

互信息具有非負性MI(X;Y)≥0,對稱性MI(X;Y)=MI(Y;X)和有界性MI(X;Y)≤H(X) +H(Y)。
2.2 幀長和幀移選擇
為度量說話人自身與語音特征間的相關性,文獻[16]將聲學空間到特征空間映射過程捕獲的信息量用互信息表示,當互信息量達到最大時,識別錯誤率最低。
離散瞬時頻率是對相鄰時刻點之間的相位作差,而幀間差分相位是對相鄰幀相位作差,幀移可以不是一個采樣點,因此可以看作是瞬時頻率基礎上的延展。幀移增大,相位變化的分布范圍展寬,導致檢測相位突變的能力提高,但同時在遠端FFT頻率間隔內引入相位噪聲。最優的幀移與幀長比(D/T)在增大相位檢測突變能力和抑制噪聲之間達到平衡。依據互信息理論確定最優幀長和幀移的準則函數可定義為

式中:X是傅里葉變換幅度譜(Fourier Transform Magnitude Spectrum,FTMS),作為參考譜表征說話人聲學空間,Y表示MFDP特征。圖1為基于互信息準則的參數選擇算法框圖。

圖1 基于互信息準則的參數選擇算法框圖Fig.1 Parameter selection scheme based on mutual information criterion
3 實驗結果與分析
實驗選用的語料庫為TIMIT庫,是語音信號處理的標準語料庫,共有630個說話人,語音為16 kHz采樣、16 bits量化。從庫中選取114位參錄者的語音用于實驗,每人10條,每條語音長約3 s。其中9條語音串接起來用于訓練,1條用于測試。設計實驗與文獻[14]中參數設置實施對照,使用矩形窗T=4096,D=160,Mel濾波器數量取24,模型選用高斯混合模型,共進行如下3組實驗。
實驗1 確定高斯混合度。圖2給出特征維數取12時,混合度為4~48的5次說話人識別實驗結果。當混合度為12~24時,系統平均識別正確率最大,獲得相對最好的性能。綜合考慮計算代價和準確率,混合度選定為16。

圖2 不同混合度的說話人識別性能Fig.2 Speaker recognition performance of differentmixtures
實驗2 分析所提出算法的性能,并確定最優參數。實驗采用矩形窗,T分別取2048、4096、8192,并且20<D<T,Mel濾波器數量為24,特征維數為22。圖3是某說話人的互信息與D/T關系曲線。實驗結果表明,隨著T增加,互信息曲線逐漸呈現單峰性。由不同T的曲線形態可知,改變幀長導致基于相位譜的MFDP特征對說話人表征能力存在差別。經統計發現,T不小于2048點時,最優D/T都介于0到0.1之間,且隨T增加,最優D/T呈現減小趨勢。圖3(c)較之于圖3(b),當D/T大于0.4時,曲線出現“階梯性”,變得不平滑。因此,綜合考慮性能和運算代價,最優幀長確定為4096。圖4給出基于最大互信息準則的不同幀長的最優D分布曲線,最優D取值如表1所示。


圖3 某說話人不同T的互信息與D/T關系Fig.3 Relation between M I and D/T for some speaker w ith different T s


圖4 不同T下最優D的分布Fig.4 Distribution of optimal D w ith different T s

表1 不同T下的最優D取值Table 1 Optimal D w ith different T s
實驗3 在說話人識別系統上檢驗上述幀長和幀移參數的有效性。下面給出以干凈語音訓練說話人模型,分別用干凈和帶噪語音進行測試的結果。
實驗按圖4(b)改變最優D,5次干凈語音測試結果如圖5所示,其中D取值20~160,平均識別率總體趨勢先增大后降低,D=60處識別率達到峰值,其變化趨勢與圖4(b)中最優D分布曲線相吻合。最優D的其他取值識別結果明顯優于作為對照D=160的情況。實驗驗證了所提出算法的準確性和可靠性,同時說明通過經驗分析得到的參數存在缺陷。

圖5 不同D下以干凈語音測試的識別性能Fig.5 Test performance of clean speech w ith different D s
將干凈語音按5~40 dB疊加高斯白噪聲生成帶噪語音進行測試,D取60的識別性能如圖6所示。40 dB帶噪語音與干凈語音對系統的測試結果接近。識別性能隨信噪比降低而急劇惡化。由此可見,訓練和測試條件不匹配導致MFDP特征對說話人個性表征能力減弱。

圖6 D=60用帶噪語音測試的識別性能Fig.6 Test performance of noisy speech w ith D=60
4 結束語
本文提出一種利用最大互信息準則確定幀間差分相位譜幀長和幀移的參數設置方法。首先依據相位信息提取特征矢量集,然后計算此特征矢量集與幅度譜的互信息,按照最大化互信息準則確定幀長和幀移。實驗結果表明,本文方法較經驗分析方法更準確,有效彌補后者的缺陷,而且本文方法的有效性和正確性得以充分驗證。由實驗過程發現,訓練和測試條件不匹配對系統識別率產生極大影響,這將是下一步需要著重解決的主要問題。
[1]Al-Nashi H.Phase unwrapping of digital signals[J]. IEEE Transactions on Acoustics,Speech and Signal Processing,1989,37(11):1693-1702.
[2]Murthy H A,Madhu Murthy K V,Yegnanarayana B. Formant extraction from phase using weighted group delay function[J].Electronics Letters,1989,25(23): 1609-1611.
[3]Yegnanarayana B,Murthy H A.Significance of group delay functions in spectrum estimation[J].IEEE Transactions on Signal Processing,1992,40(9):2281-2289.
[4]Alsteris L D,Paliwal K K.Further intelligibility results from human listening tests using the short-time phase spectrum[J].Speech Communication,2006,48(6): 727-736.
[5]Liu L,He J,Palm G.Effects of phase on the perception of intervocalic stop consonants[J].Speech Communication,1997,22(4):403-417.
[6]Oppenheim A V,Lim JS.The importance of phase in signals[J].Proceedings of the IEEE,1981,69(5): 529-541.
[7]Schroeder M R.Models of hearing[J].Proceedings of the IEEE,1975,63(9):1332-1350.
[8]Alsteris L D,Paliwal K K.Short-time phase spectrum in speech processing:A review and some experimental results[J].Digital Signal Processing,2007,17(3):578-616.
[9]Reddy N,Swamy M.Derivative of phase spectrum of truncated autoregressive signals[J].IEEE Transactions on Circuits and Systems,1985,32(6):616-618.
[10]Alsteris L D,Paliwal K K.Importance of window shape for phase-only reconstruction of speech[C]∥ in Proc. IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP '04),Montreal,Quebec,Canada,2004:573-576.
[11]Wang Y,Hansen J,Allu GK,etal.Average instantaneous frequency (AIF)and average log-envelopes (ALE)for ASR with the Aurora 2 database[C]∥ in Proc.Interspeech 2003,Geneva,Switzerland,2003:25-28.
[12]Stark A P,Paliwal K K.Speech analysis using instantaneous frequency deviation[C]∥in Proc.Interspeech 2008,Brisbance,Australia,2008:2602-2605.
[13]Murthy H A,Gadde V.Themodified group delay function and its application to phoneme recognition[C]∥in Proc.IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP'03),Hong Kong,China,2003:68-71.
[14]McCowan I,Dean D,McLaren M,et al.The deltaphase spectrum with application to voice activity detection and speaker recognition[J].IEEE Transactions on Audio,Speech,and Language Processing,2011,19(7): 2026-2038.
[15]McEliece R J.信息論與編碼理論(第二版)[M]:北京:電子工業出版社,2003.
[16]Eriksson T,Kim S,Hong-Goo K,et al.An informationtheoretic perspective on feature selection in speaker recognition[J].IEEE Signal Processing Letters,2005,12 (7):500-503.
[17]Rajan P,Hegde R M,Murthy H A.Dynamic selection ofmagnitude and phase based acoustic feature streams for speaker verification[C]∥in Proc.European Signal Process.Conf.,Glasgow,Scotland,2009:1244-1248.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
