論網(wǎng)絡(luò)爬蟲(chóng)搜索策略
2013-04-27 03:32:30李耀華楊海燕
山西廣播電視大學(xué)學(xué)報(bào) 2013年2期
□李耀華,楊海燕
(1.山西大學(xué)繼續(xù)教育學(xué)院,山西 太原 030006;2.山西廣播電視大學(xué),山西 太原 030027)
網(wǎng)絡(luò)爬蟲(chóng)是搜索引擎的重要組成部分。搜索引擎借助于網(wǎng)絡(luò)爬蟲(chóng)才能在互聯(lián)網(wǎng)海量數(shù)據(jù)中有效搜集到相關(guān)的網(wǎng)頁(yè)信息。如何提高網(wǎng)絡(luò)爬蟲(chóng)的搜索效率,是該領(lǐng)域研究的熱點(diǎn)。本文將分別對(duì)目前常用的網(wǎng)絡(luò)爬蟲(chóng)的搜索策略進(jìn)行初步分析研究。
一、網(wǎng)絡(luò)爬蟲(chóng)基本工作原理
網(wǎng)絡(luò)爬蟲(chóng)Web Spider又叫Web Crawler或者Robot,是一個(gè)沿著鏈接漫游web文檔集合的程序。它一般駐留在服務(wù)器上,并且利用標(biāo)準(zhǔn)的http協(xié)議根據(jù)超鏈接和web文檔檢索的方法遍歷整個(gè)Internet網(wǎng)信息進(jìn)行搜索。
(一)網(wǎng)絡(luò)爬蟲(chóng)的基本結(jié)構(gòu)。傳統(tǒng)的網(wǎng)絡(luò)爬蟲(chóng)包括一個(gè)協(xié)議處理模塊。URL(統(tǒng)一資源定位符,Uniform Resource Locator的縮寫,也被稱為網(wǎng)頁(yè)地址,是因特網(wǎng)上標(biāo)準(zhǔn)的資源的地址。它最初是由Tim Berners-Lee發(fā)明用來(lái)作為萬(wàn)維網(wǎng)的地址的)由兩部分構(gòu)成:協(xié)議模塊和檢測(cè)模塊。其中,協(xié)議模塊用來(lái)提供網(wǎng)絡(luò)爬蟲(chóng)所需的網(wǎng)絡(luò)協(xié)議,解決如何獲取網(wǎng)頁(yè);檢測(cè)模塊負(fù)責(zé)對(duì)采集的URL信息進(jìn)行排序,處理網(wǎng)絡(luò)上重復(fù)內(nèi)容,以提高網(wǎng)絡(luò)爬蟲(chóng)的搜索效率。
(二)網(wǎng)絡(luò)爬蟲(chóng)的工作流程。網(wǎng)絡(luò)爬蟲(chóng)也是一個(gè)自動(dòng)提取網(wǎng)頁(yè)的程序,是搜索引擎的重要組成部分,其作用是為搜索引擎從Internet網(wǎng)上下載頁(yè)面。網(wǎng)絡(luò)爬蟲(chóng)在獲取網(wǎng)絡(luò)信息時(shí),通常會(huì)從一個(gè)“種子集”出發(fā),獲得初始網(wǎng)頁(yè)上的URL,下載頁(yè)面并提取已下載頁(yè)面中的連接,抽取新的URL放入隊(duì)列,然后訪問(wèn)提取出的連接所對(duì)應(yīng)的網(wǎng)頁(yè),如此不斷重復(fù)便可遍歷整個(gè)網(wǎng)絡(luò)信息,直到滿足系統(tǒng)的一定停止條件。其中,種子集指種子鏈接集合,通常為幾個(gè)知名網(wǎng)站主頁(yè)連接地址。工作流程如圖1所示。但通用爬蟲(chóng)搜索有以下幾方面不足:
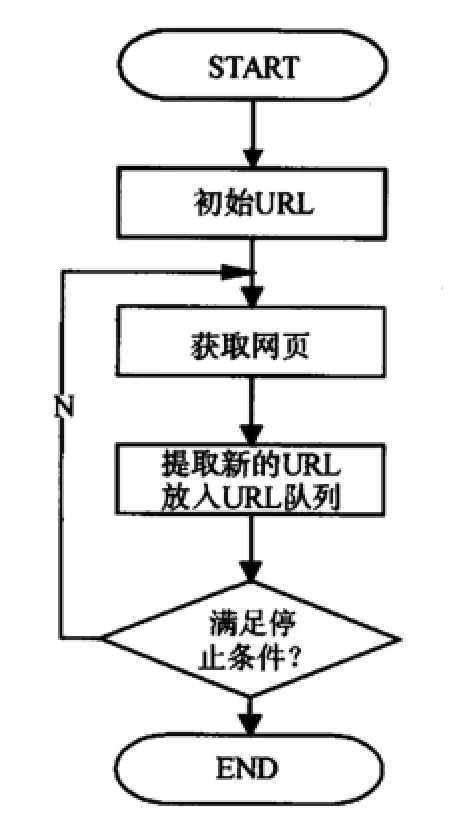
圖1 通用網(wǎng)絡(luò)爬蟲(chóng)工作流程圖
(1)因?yàn)樽ト〉哪繕?biāo)是覆蓋盡可能大的網(wǎng)絡(luò),所以爬行的結(jié)果中必然會(huì)包含大量用戶不需要的網(wǎng)頁(yè);
(2)無(wú)法很好地搜索和獲取信息含量密集而且具有一定結(jié)構(gòu)的數(shù)據(jù);
(3)通用搜索引擎大多是基于關(guān)鍵字的檢索,對(duì)于支持語(yǔ)義信息的查詢和索引擎智能化的要求則難以實(shí)現(xiàn)。
由此,通用爬蟲(chóng)想在爬行網(wǎng)頁(yè)時(shí),既保證網(wǎng)頁(yè)的質(zhì)量和數(shù)量,又要保證網(wǎng)頁(yè)的時(shí)效性是很難實(shí)現(xiàn)的。
(三)網(wǎng)絡(luò)爬蟲(chóng)的搜索策略。為提高網(wǎng)絡(luò)爬蟲(chóng)的搜索效率,網(wǎng)絡(luò)爬蟲(chóng)需要在既定時(shí)間內(nèi)搜索到盡可能多的高質(zhì)量網(wǎng)頁(yè),這是其面臨的主要技術(shù)難題。
一般而言,有五種方式表示頁(yè)面質(zhì)量的高低:Similarity(頁(yè)與爬行主題之間的相似度)、Backlink(面在Web圖中的入度大小)、PageRank(指向它的所有頁(yè)面平均權(quán)值之和)、For-wardlink(頁(yè)面在Web圖中的出度大小)、Location(頁(yè)面的信息位置);Parallel(并行性問(wèn)題)。
搜索策略就是指提取出頁(yè)面鏈接后如何訪問(wèn)。通用的搜索引擎往往希望得到較高的網(wǎng)絡(luò)覆蓋率,所以常采用遍歷的方式進(jìn)行訪問(wèn),見(jiàn)圖2。相反,主題搜索引擎的服務(wù)范圍則是限制在特定的人群和主題范圍內(nèi),通常采用“最好優(yōu)先”的原則,選擇最有價(jià)值的連接進(jìn)行訪問(wèn),見(jiàn)圖3,其關(guān)鍵就在于如何評(píng)價(jià)最有價(jià)值的連接。
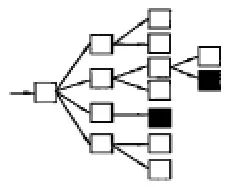
圖2
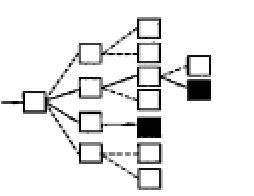
圖3
二、遍歷搜索策略
該搜索策略對(duì)所有提取出的鏈接都一一進(jìn)行爬取,目的在于遍歷網(wǎng)絡(luò)上的所有信息資源。
(一)寬度優(yōu)先策略。寬度優(yōu)先搜索(Breadth-First Search)是一種簡(jiǎn)便常用的搜索算法(又稱廣度優(yōu)先搜索)。這一算法也是其他很多重要算法之原型,其主要用來(lái)解決最優(yōu)解問(wèn)題。其基本思想是:從起始網(wǎng)頁(yè)源頂點(diǎn)p開(kāi)始,沿著樹(shù)的寬度遍歷樹(shù)的每一個(gè)節(jié)點(diǎn),獲取相關(guān)所有鏈接網(wǎng)頁(yè),進(jìn)而再沿這些節(jié)點(diǎn)繼續(xù)抓取該網(wǎng)頁(yè)中的所有鏈接頁(yè)面,最終遍歷所有頂點(diǎn)。即,首先完成一個(gè)層次的搜索,其次再進(jìn)行下一層次的搜索,也稱之為分層處理。該算法的設(shè)計(jì)模式和技術(shù)實(shí)現(xiàn)比較簡(jiǎn)單且能獲得較高的網(wǎng)頁(yè)覆蓋率,但該算法的設(shè)計(jì)和實(shí)現(xiàn)相對(duì)簡(jiǎn)單,屬于盲目搜索,因而效率較低。換句話說(shuō),它并不考慮結(jié)果的可能位置,徹底地搜索整張圖,直到找到結(jié)果為止。為盡可能覆蓋較多網(wǎng)頁(yè),寬度優(yōu)先搜索方法是較好的選擇。
(二)深度優(yōu)先策略。深度優(yōu)先搜索(Depth-First Search),也是一種早期在開(kāi)發(fā)爬蟲(chóng)過(guò)程中使用較多的方法。其設(shè)計(jì)思路是盡量“深”入地搜索信息資源。在深度優(yōu)先搜索中,針對(duì)最新發(fā)現(xiàn)的網(wǎng)頁(yè)源頂點(diǎn)p,如果它還有以此為起點(diǎn)而尚未搜索到的路徑,則沿此路徑繼續(xù)搜索下去。反之,如果當(dāng)頂點(diǎn)p的所有路徑均己被搜索過(guò),則回溯到初始點(diǎn)。這一搜索過(guò)程將一直持續(xù)到已發(fā)現(xiàn)的從源頂點(diǎn)p可達(dá)到的所有頂點(diǎn)為止。但是如果仍然存在未被發(fā)現(xiàn)的頂點(diǎn)p’,則繼續(xù)選擇其中一個(gè)作為源頂點(diǎn)并重復(fù)以上過(guò)程,最終實(shí)現(xiàn)所有頂點(diǎn)都被遍歷。
但是深度優(yōu)先策略不足之處是,深度優(yōu)先策略在很多情況下會(huì)導(dǎo)致網(wǎng)絡(luò)爬蟲(chóng)的陷入問(wèn)題(trapped),導(dǎo)致盲目搜索。
三、最好優(yōu)先策略
“最好優(yōu)先”(Best-First Search)的爬蟲(chóng)也稱聚集爬蟲(chóng),是根據(jù)相關(guān)網(wǎng)頁(yè)分析算法,預(yù)測(cè)候選URL與目標(biāo)網(wǎng)頁(yè)的相似度,根據(jù)“最好優(yōu)先”原則進(jìn)行訪問(wèn),選取評(píng)價(jià)最好的一個(gè)或幾個(gè)URL,以便快速、有效地獲得更多的與目標(biāo)網(wǎng)頁(yè)相似度高的頁(yè)面進(jìn)行抓取。最好優(yōu)先策略只訪問(wèn)經(jīng)過(guò)網(wǎng)頁(yè)分析算法預(yù)測(cè)為“有用”的網(wǎng)頁(yè)。專業(yè)的搜索引擎網(wǎng)絡(luò)爬蟲(chóng)通常會(huì)采用“最好優(yōu)先”原則訪問(wèn)WEB。但由于所有搜索鏈接均包含在相關(guān)網(wǎng)頁(yè)中,因此頁(yè)面價(jià)值往往與頁(yè)面內(nèi)鏈接價(jià)值存在正相關(guān)關(guān)系,于是對(duì)鏈接價(jià)值的評(píng)價(jià)有時(shí)也可轉(zhuǎn)換為對(duì)頁(yè)面價(jià)值的評(píng)價(jià)。
但最好優(yōu)先策略存在一個(gè)問(wèn)題:因最佳優(yōu)先策略只是一種局部最優(yōu)搜索算法,所以網(wǎng)絡(luò)爬蟲(chóng)在抓取有用信息的過(guò)程路徑上會(huì)有很多相關(guān)網(wǎng)頁(yè)被忽略。因此該策略在應(yīng)用時(shí)應(yīng)結(jié)合具體情況進(jìn)行必要改進(jìn),以跳出局部最優(yōu)點(diǎn)。
(一)基于內(nèi)容評(píng)價(jià)的搜索策略。互聯(lián)網(wǎng)上不良信息、不安全信息日益增多已成為危害社會(huì)的嚴(yán)重問(wèn)題,對(duì)互聯(lián)網(wǎng)信息內(nèi)容進(jìn)行必要的監(jiān)控成為一項(xiàng)迫切任務(wù)。而網(wǎng)絡(luò)爬蟲(chóng)在信息搜索中起著明顯的作用。
基于內(nèi)容評(píng)價(jià)的搜索策略是根據(jù)搜索內(nèi)容的主題與被鏈接網(wǎng)頁(yè)文本的相似度來(lái)評(píng)價(jià)鏈接價(jià)值的高與低,進(jìn)而決定搜索策略。其中,相似度評(píng)價(jià)通常一般采用以下公式:

其中,di為新獲取文本的特征向量值,dj為第j類鏈接文本的中心向量值,m為特征向量di的維數(shù),wk為向量w的第k維。
基于內(nèi)容評(píng)價(jià)的搜索策略并不只有這一種計(jì)算方法,除上述公式外,還有 Best-First Search,F(xiàn)ish Search和 Shark Search算法。
(二)基于鏈接結(jié)構(gòu)評(píng)價(jià)的搜索策略。基于鏈接結(jié)構(gòu)評(píng)價(jià)的搜索策略屬于web頁(yè)面的半結(jié)構(gòu)化設(shè)計(jì),通過(guò)對(duì)頁(yè)面間的超鏈接進(jìn)行關(guān)聯(lián)分析其引用關(guān)系來(lái)確定鏈接的重要性,由此確定鏈接訪問(wèn)的次序。因此這種結(jié)構(gòu)化特征使文本鏈接的重要性可通過(guò)鏈接分析來(lái)加以確定,主要根據(jù)文獻(xiàn)計(jì)量學(xué)的引文分析理論來(lái)進(jìn)行。常規(guī)認(rèn)為有較多入鏈或出鏈的頁(yè)面具有較高的價(jià)值。PageRank算法和Hits算法是其中具有代表性的算法。
1.PageRank(網(wǎng)頁(yè)級(jí)別)算法。PageRank算法是Google創(chuàng)始人Larry Page和Sergey Brin于1997年構(gòu)建早期的搜索系統(tǒng)原型時(shí)提出的鏈接分析算法。該算法隨著Google在商業(yè)上獲得巨大成功后成為其它搜索引擎和學(xué)界所關(guān)注的計(jì)算模型。可以說(shuō)PageRank算法是后來(lái)很多鏈接分析算法的基礎(chǔ)。
例如Google搜索引擎信息檢索中對(duì)查詢結(jié)果的排序過(guò)程。其對(duì)web頁(yè)面的排序,在揉合了諸如Title標(biāo)識(shí)和Keywords標(biāo)識(shí)等所有其它因素之后,根據(jù)搜索的信息內(nèi)容在頁(yè)面中的出現(xiàn)次數(shù),并用頁(yè)面長(zhǎng)度和html標(biāo)簽的重要性提示等進(jìn)行權(quán)重修訂。使那些更具等級(jí)的網(wǎng)頁(yè)在搜索結(jié)果中的排名獲得提升,最終提高搜索結(jié)果相關(guān)性和搜索質(zhì)量。近年來(lái)被應(yīng)用于網(wǎng)絡(luò)爬蟲(chóng)對(duì)鏈接重要性的評(píng)價(jià)。Google通過(guò)PageRank來(lái)調(diào)整結(jié)果,其級(jí)別從0到10級(jí),10級(jí)為滿分。鏈接提供的頁(yè)面越重要?jiǎng)t此鏈入值越高。此外,還可通過(guò)其它文檔鏈接到當(dāng)前頁(yè)面的鏈接數(shù)量來(lái)確定當(dāng)前頁(yè)面的重要性,這樣可以有效地抵制那些被人為加工過(guò)的頁(yè)面欺騙搜索引擎的手法。
該算法中,通常用PageRank值表示頁(yè)面的價(jià)值,若設(shè)頁(yè)面p的PageRank值為PR(p),則PR(p)用如下公式表示:
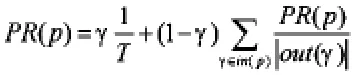
其中:T為所計(jì)算中頁(yè)面總量,γ<1為阻尼系數(shù),in(p)為所有指向頁(yè)面p的集合,out(γ)為頁(yè)面γ出鏈的集合。按照PageRank算法,爬蟲(chóng)在信息搜索過(guò)程中,通過(guò)計(jì)算已訪問(wèn)頁(yè)面的PageRank值來(lái)確定頁(yè)面的重要性,并確定訪問(wèn)次序。
2.Hits算法。1997年康奈爾大學(xué)(Cornell University)的Jon Kleinberg首次提出了Hits算法(Hyperlink-Induced Topic Search)。Hits算法也是Web結(jié)構(gòu)挖掘中最具有權(quán)威性和使用最廣泛的算法之一。該算法中引入了兩個(gè)重要的概念:內(nèi)容權(quán)威度(Authority Scores)和鏈接權(quán)威度(Hub Scores)來(lái)對(duì)網(wǎng)頁(yè)質(zhì)量進(jìn)行評(píng)估。其基本思想是利用頁(yè)面之間的引用鏈來(lái)挖掘隱含在其中的有用信息,具有計(jì)算簡(jiǎn)單且效率高的特點(diǎn)。
Hits算法中網(wǎng)頁(yè)的Authority值表示所有導(dǎo)入鏈接所在的頁(yè)面的Hub值之和,即一個(gè)頁(yè)面被其它頁(yè)面所引用的次數(shù),被其它頁(yè)面引用的次數(shù)越多,則這個(gè)頁(yè)面的Authority值就會(huì)越大;頁(yè)面的Hub值表示指的是頁(yè)面上所有導(dǎo)出鏈接指向頁(yè)面的Authority值之和,一個(gè)頁(yè)面指向其他頁(yè)面的次數(shù),指向其它頁(yè)面的次數(shù)越多,這個(gè)頁(yè)面的Hub值就會(huì)越大。由于在Hub值高的頁(yè)面中通常都包含了指向Authority頁(yè)面的鏈接,因而能夠起到說(shuō)明頁(yè)面權(quán)威性的作用。Hits算法正是利用這種相互關(guān)系來(lái)發(fā)現(xiàn)Authority頁(yè)面的。
(三)基于鞏固學(xué)習(xí)的搜索策略。相關(guān)研究表明,多數(shù)類似網(wǎng)站在設(shè)計(jì)方式上,同類網(wǎng)頁(yè)存在一定相似性,因而有人將鞏固學(xué)習(xí)(Reinforcement Learning)搜索策略引入到網(wǎng)絡(luò)爬蟲(chóng)的研究中以減小搜索空間,提高效率。在該模型中,將網(wǎng)絡(luò)爬蟲(chóng)遍歷無(wú)關(guān)頁(yè)面訪問(wèn)后才能獲得的主題頁(yè)面稱之為未來(lái)回報(bào),即搜索到隱含的結(jié)構(gòu)信息。在綜合考量計(jì)算立即回報(bào)價(jià)值和未來(lái)回報(bào)價(jià)值結(jié)合的前提下確定正確的搜索方向。
隨著互聯(lián)網(wǎng)技術(shù)的廣泛應(yīng)用,互聯(lián)網(wǎng)信息量的海量增長(zhǎng)使傳統(tǒng)的通用搜索引擎面臨著巨大的挑戰(zhàn),各類針對(duì)特定人群的“專業(yè)搜索引擎”便應(yīng)運(yùn)而生。網(wǎng)絡(luò)爬蟲(chóng)搜索就是典型代表。網(wǎng)絡(luò)爬蟲(chóng)各類搜索策略各有利弊,尚無(wú)單一標(biāo)準(zhǔn)去評(píng)價(jià)其優(yōu)劣。互聯(lián)網(wǎng)搜索問(wèn)題屬于“多目標(biāo)”規(guī)劃問(wèn)題。降低計(jì)算的復(fù)雜程度,提高搜索鏈接價(jià)值的準(zhǔn)確性,增加網(wǎng)絡(luò)爬蟲(chóng)的自適應(yīng)能力,是提高網(wǎng)絡(luò)爬蟲(chóng)效率的核心問(wèn)題。
[1]歐陽(yáng)柳波等.專業(yè)搜索引擎搜索策略綜述[J].計(jì)算機(jī)工程,2004,(30):32 -33.
[2]李勇,韓亮.主題搜索引擎中網(wǎng)絡(luò)爬蟲(chóng)的搜索策略研究[J].計(jì)算機(jī)工程與科學(xué),2008,(3):4 -6.
[3]歐陽(yáng)柳波等.網(wǎng)絡(luò)蜘蛛搜索策略進(jìn)展研究[J].小型微型計(jì)算機(jī)系統(tǒng),2005,(4):703 -703.
[4]劉世濤.簡(jiǎn)析搜索引擎中網(wǎng)絡(luò)爬蟲(chóng)的搜索策略[J].阜陽(yáng)師范學(xué)院學(xué)報(bào),2006,(3):59 -62.
[5]龔勇.搜索引擎中網(wǎng)絡(luò)爬蟲(chóng)的研究[D].武漢:武漢理工大學(xué),2010.
[6]李學(xué)勇.搜索引擎中網(wǎng)絡(luò)蜘蛛搜索策略比較研究[J].計(jì)算機(jī)技術(shù)與自動(dòng)化,2003,(4):63 -65.
[7]李學(xué)勇等.網(wǎng)絡(luò)蜘蛛搜索策略比較研究[J].計(jì)算機(jī)工程與應(yīng)用,2004,(4):63 -67.
[8]劉漢興,劉財(cái)興.主題爬蟲(chóng)的搜索策略研究[J].計(jì)算機(jī)工程與設(shè)計(jì),2008,(12):33 -38.
[9]劉偉.搜索引擎中網(wǎng)絡(luò)爬蟲(chóng)的設(shè)計(jì)與實(shí)現(xiàn)[J].科技傳播,2011,(20):178 -181.
猜你喜歡
大灰狼畫報(bào)·益智版(2024年3期)2024-12-09 00:00:00
保健醫(yī)苑(2022年1期)2022-08-30 08:39:14
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學(xué)生作文(低年級(jí)適用)(2019年9期)2019-10-08 08:37:10
數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
中國(guó)衛(wèi)生(2015年12期)2015-11-10 05:13:38
新疆大學(xué)學(xué)報(bào)(自然科學(xué)版)(中英文)(2014年2期)2014-11-06 07:49:12
時(shí)代英語(yǔ)·高三(2014年5期)2014-08-26 02:49:51
技術(shù)經(jīng)濟(jì)與管理研究(2014年11期)2014-03-11 17:02:44
電腦愛(ài)好者(2011年11期)2011-06-22 08:20:18
