基于代理模型的分布式聚類算法
2013-06-23 09:42:06彭利標
電子設計工程 2013年17期
田 野,彭利標
(天津理工大學 中環信息學院,天津 300380)
聚類算法是大規模數據處理應用中的一個非常重要的研究領域,現階段聚類分析算法的應用的非常廣泛,其目標是在沒有先驗知識的前提下,以數據對象之間的相似程度為根據將數據聚合成若干不同的簇,使同一個簇中的數據對象盡可能相似,不同簇中的數據對象差別盡可能的大[1]。由于聚類算法可以應用于事先未知的情況,所以特別適合無需人工干預的挖掘過程。而且聚類算法作為數據挖掘系統中的一個重要部分,既可以作為一個單獨的工具挖掘數據庫元素分布的深層信息,也可以作為先進數據挖掘算法的一個預處理步驟[2]。
分布式數據挖掘的研究是近幾年提出的一個新的研究領域,旨在解決當前分布式的環境下,提供從數據的海洋中獲取感興趣的知識的有效的途徑,也是目前解決在Internet中發現知識的最佳方法之一,應用前景非常廣闊。從廣義上講,分布式環境中應用的數據挖掘都可稱為分布式數據挖掘[3]。實際上,很多研究人員都已經展開研究,對分布式的關聯規則算法,分布式分類算法,以及分布式聚類算法等的研究已經取得了一些成果。但必須注意到的是,無線和有線通信技術以及計算機技術的飛速發展,使分布式計算環境在各個領域廣泛存在,現有的大多數聚類方法在數據量小、集中的情況下是有效的,對于大規模數據的、分布式的數據處理不能很好的適應。分布式聚類技術的研究雖然已經有了發展,但現階段分布式聚類的研究還屬于數據挖掘領域里一個比較前沿的新方向,其研究還處于基礎性階段,有很多問題亟待解決。
1 基于代理的分布式聚類模型
從體系架構上來講,目前的分布式數據挖掘系統采用兩類模型[4]:C/S模型和基于代理(agent-based)模型。其中基于代理的挖掘模型的特點是分布式數據挖掘系統的局部數據聚類分析需要在每個數據站點使用一個或多個代理來進行,并與其他的代理進行通訊,在該過程中需要一個具有指導性代理的適配器來協助整個挖掘[5]。由于傳統的代理挖掘模型最終仍需要將局部的所有結果集中到一個中心站點執行,而中心站點的內存不一定能滿足龐大數據量的要求,即便是滿足足夠內存同時也會帶來較大的通訊開銷。 圖1描述了一個基于代理的分布式數據挖掘模型的結構。這種基于代理的結構能夠將龐大復雜的計算任務分配給代理系統,客戶端可以從復雜的邏輯處理中解放出來,只關心聚類的結果,而不必去關心聚類的具體細節,大大提高了模型的聚類效率和可移植性。
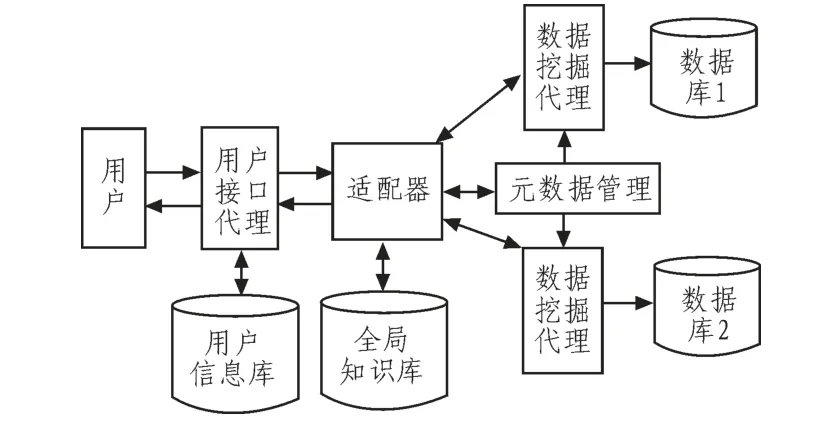
圖1 基于代理的分布式數據挖掘模Fig.1 Agent-based distributed data mining model
目前,在基于代理的聚類模型中存在一種增量集成的分布式數據挖掘模型(II DDM),這種模型的本質是通過利用增量學習的思想,集成兩個站點的聚類結果,根據得出的局部結果,集成他們的增量。II DDM模型的設計思想是基于模型伸縮性的考慮,此模型對于任何數量的數據源都具有較好的伸縮性。典型的模型結構如圖2所示,在該模型中使用多個移動代理知識集成器增量的組合,得出的每兩個站點的挖掘結果,一般而言將小的局部站點聚類結果遷移到更大的局部站點結果中去,從而優化結果集[6]。

圖2 典型的II DDM模型Fig.2 II DDM model
增量集成分布式數據挖掘模型工作過程一般可分為以下3個階段。1)準備階段,首先,客戶端向需要執行數據聚類任務的服務器廣播移動代理數據挖掘器和移動代理知識集成器;2)聚類分析階段,在每個局部站點的數據服務器上執行數據對象的聚類分析,生成該站點的局部聚類結果集;3)集成階段,在數據服務器上執行增量集成技術將小的局部站點聚類結果遷移到更大的局部站點結果中去,以此來減小局部站點間的結果遷移代價。
2 II DDM模型存在的問題
分析II DDM模型,可以知道,該模型不但繼承了一般多代理模型之間可以協作執行任務、彼此進行信息傳遞的特點,從而完成復雜的大規模數據挖掘任務。還繼承了移動代理系統的獨立自主性,這是由移動代理本身的特點決定的。移動代理系統可以在自己的生存周期中自行控制挖掘的起點和終點,實時掌握自身的運行狀態,并且能夠在新的節點中從掛起狀態自動恢復并繼續運行。
與傳統的基于移動代理模型不同的是,II DDM模型本質上并不是向集成代理傳遞所有獲得的數據服務器局部聚類結果,而是通過控制服務器聚類結果之間不斷的從小到大的遷移,來進行增量的集成,直到最后將一次集成得到的結果傳遞給客戶端。可以說這種方式克服基于傳統移動代理的挖掘模型的不足,它所具備對任意數量的數據站點具有伸縮性的優點。
正是由于II DDM模型上述的那些優點,使它非常適合應用于分布式聚類系統。但是,傳統的基于代理的分布式數據挖掘模型,仍然存在著需要將全部的局部站點聚類結果集中到一個服務器上進行聚類的缺點,服務器的性能成為整個系統的瓶頸。改進的II DDM模型雖然在某種程度上緩解了這個矛盾,但是其實質也是通過個體式合作方式來進行代理間的協作,且是串行集成的工作模式。客戶端要執行聚類任務的過程中不可避免的被要求與全部需要執行挖掘任務的服務器進行通信,還要將挖掘代理以及集成代理廣播給所有相應的數據服務器,對整個網絡的帶寬要求很高,時間開銷也很大。不僅如此,在挖掘任務執行之后,相應的服務器又需要將結果集全部反饋給客戶端。經過上面的分析,可以想象的到當站點數量非常龐大時,通訊開銷也會是難以接受的,而且存在響應效率大大降低的可能性,可見這種有賴于個體式的合作方式自身存在一定的不足。
沿著這個思路,在本章基于II DDM模型的,引入層次的設計思想,提出一種新的基于代理的層次式增量集成分布式數據挖掘模型,記作HII DDM。該模型是利用分治策略將復雜的大問題分解成小問題進行解決,以此來克服II DDM模型個體合作方式的不足。在實際應用中可以根據站點服務器的分布、局域網絡帶寬等來將整個系統劃分為若干子系統。每個子系統在利用II DDM模型進行學習之后,生成一個模型,新的模型將作為整個系統的數據節點,再利用II DDM模型進行學習生成最終的模型。用這種層次式的方法生成最終的模型較前面兩種傳統的模型而言具有更好的伸縮性,執行起來更加高效,并有效降低網絡通信。最后,基于本章提出的新模型提出一種新型的分布式聚類算法。為是解決站點數量龐大的數據挖掘問題提供了一個新的思路。
3 層次式增量集成分布式聚類模型的設計與實現
將分層的思想引入之后,可將層次式增量集成分布式聚類模型整體工作過程劃分為4個階段。
1)準備階段,在這個階段客戶端將移動代理數據挖掘器和移動代理知識集成器廣播給每個子系統,而不是直接分給數據服務器;2)聚類分析階段,在這個階段每個子系統選擇合適的聚類算法在節點間執行聚類任務,生成局部挖掘的結果;3)子系統集成階段,移動代理知識集成器利用增量集成技術在各個子系統上并行進行結果集成,生成子系統的挖掘結果;4)全局集成階段,移動代理知識集成器利用增量集成技術集成各個子系統生成的局部聚類結果,生成全局聚類模型并傳遞給知識集成器客戶端。其結構圖見圖3所示。

圖3 HII分布式數據挖掘模型整體結構圖Fig.3 HII distributed data mining models overall structure
在層次式增量集成分布式數據挖掘模型中,第一層為子系統層,該層為每個子系統設計一個適配器來充當子系統的客戶端,向相應的子系統中需要進行聚類任務的數據服務器分配數據挖掘器;在聚類任務執行完畢后,各個數據服務器再將得到的局部聚類結果反饋回適配器。第二層為由小系統組成的大系統層,即全局聚類層,在這一層適配器又充當集成服務器和通信代理的角色,傳遞和集成各子系統的局部聚類結果,最終將全局的聚類結果送回給整個系統的客戶端。
將分層的思想引入基于代理的分布式聚類模型中,是提高分布式聚類模型伸縮性,高效性的有效途徑。但是如何劃分系統的層次才能使整個系統運作更易實現、更加高效,是一個非常關鍵的問題。絕大多數實際應用中網絡節點的地理分布特征不是隨意的分布在不同地方,而是在幾個地方集中分布,節點間連接方式多樣化,連接帶寬差異化。例如,用高速的局域網連接在同一個地點或同一組織中分布的節點,會比用遠程網、互聯網甚至無線網連接的不同地點間或不同組織中分布的節點,在網絡傳輸的安全性、傳輸的速率方面高的多,而在通信代價方面卻低得多。因此,在設計分布式聚類模型時,應該盡量在局域網內完成聚類的通訊和計算,盡可能的減少廣域網間的網絡通訊。
沿著這個設計思路,將系統劃分的方式定為,分布在一個地點或若干個相近地點的節點作為一個子系統。這樣,各個子系統可以高效執行聚類運算,提高子系統數據挖掘的效率,將子系統之間的通信工作交給專業的、強大的代理系統執行,從而使整個系統的執行效率大大提高,通訊代價最大程度的降低,系統的安全性也得到明顯改善。
假設一個分布式系統由P個節點組成,全部的P個節點在g個站點間集中分布(這里有一個隱含的假設前提是每個站點內部的節點是由高速局域網連接的),設在第i個站點中的節點數目為ni,則有個節點按照所在站點進行劃分,并組成一個相應的子系統,記作S1,S2,…,Sg。基于網絡分布、帶寬和安全性方面的實際考慮,根據這個定義對分布式系統進行劃分旨在做到子系統內的節點緊耦合,子系統間是松耦合。當然這個劃分規則不是一成不變的,可以根據實際情況靈活選擇。如果某個子系統的節點數量達到了一定的程度,也可以根據實際情況將同一站點的節點再分為若干子系統;另一方面,如果幾個站點的節點數量足夠的小,且不同站點間的網絡連接速度足夠的快,也可以將相應的幾個站點的節點集成一個子系統。
根據規則劃分好子系統之后,采用II DDM模型進行聚類分析。模型中的數據挖掘算法可以采用DK-Dmeans算法,當然也可以根據實際情況選取其他的分布式聚類算法,此模型具有很好的靈活性。在各個子系統上通過一遍遍歷數據后根據增量集成規則建立子系統模型,如圖4所示。

圖4 HII子系統Sj聚類模型Fig.4 HII subsystem Sj clustering model
在子系統模型建立之前的準備是根據客戶端的數據挖掘請求來決定需要進行聚類的子系統。之后客戶端會將移動代理數據挖掘器和移動代理知識集成器發送給需要進行聚類分析的子系統的適配器,再由適配器分發給其所在系統的服務器。該子系統中,每個數據服務器執行挖掘任務,將得到的聚類結果的聚簇中心點以及相應簇的大小反饋給適配器,適配器會對得到的信息進行比較,然后發送控制命令,將較小的聚類結果遷移到更大聚類結果的服務器上,并在更大結果的服務器上執行集成。迭代執行上述步驟,直到所有的聚類結果被遷移到一個服務器上得到最終的聚類結果。最后這個服務器將聚類結果發送給適配器。
在本章提出的模型中,全局模型的建立并不是將局部模型的聚類結果進行簡單了累加,由于是分層的思想,所以在整個系統的第二層,即全局聚類層,也和子系統一樣,通過增量集成模型建立全局模型,與子系統模型不同的是在第二層的聚類模型中,子系統充當了數據源的角色。這樣就可以明顯的看出,引入分層的思想后,克服了II DDM模型串行的、個體協同合作執行方式的弊端,在全局聚類的這一層是并行的合作方式。全局聚類的模型如圖5所示。

圖5 HII全局聚類模型Fig.5 The HII global clustering model
全局模型和子系統模型的工作過程幾乎是一樣,只不過在這一層適配器是將將生成結果大小送給客戶端,由客戶端發送將小的聚類結果遷移到大的聚類結果的適配器上的控制命令,之后在駐留有大的聚類結果的適配器上執行子系統聚類結果的集成。上述步驟迭代執行,直到所有適配器聚類結果被集成到一個適配器中。此適配器將最后一次集成的結果發送給客戶端。在整個系統模型的聚類過程中,由于是并行的執行,各個子系統可能由于網絡帶寬,網絡延時等問題造成不能同步完成聚類計算。這是,整個系統的聚類就會出現協同問題,解決這個問題的方法是,可以在客戶端發送控制命令的同時也發送一個時間戳給各個子系統,這樣就可以保證是同一次迭代的結果被集成代理進行集成了。
4 基于HII模型的分布式聚類算法
在上一節中完成了HII DDM模型的設計和建立,現在在建立好的模型基礎上,來實現基于該模型的分布式聚類算法。根據模型的劃分規則,將分布在多個站點的數據庫劃分為若干子數據庫,并且在每個子數據庫中選擇一個性能好的服務器充當適配器,模型中可以應用多種分布式算法,在本節選擇上一章的DK-Dmeans算法,下面是新算法的描述。
基于HII DDM的分布式聚類算法:
第一層對子系統j:


實際上,基于HII DDM模型的分布式聚類算法由于采用了層次式增量集成的方式,其算法的開銷也應該分為兩層來計算。根據模型的工作過程,在子系統聚類層,時間的開銷包括以下幾個方面,1)適配器向數據服務器傳送挖掘器和集成器的時間;2)子系統各個站點執行K-means聚類算法的時間;3)服務器之間的通信時間;4)增量集成的時間;5)向適配器傳遞最后結果的時間。
同子系統時間開銷的分析過程一樣,全局聚類層的時間開銷包括以下幾個方面,1)客戶端發送挖掘器和集成器的時間;2)適配器之間的通信時間;3)增量集成時間;4)適配器向客戶端最后傳遞結果的時間。綜上所述,本算法的時間開銷=子系統聚類執行時間+全局聚類執行時間。
5 結束語
本章首先分析了基于代理的II DDM聚類模型的優勢與劣勢,在此基礎上將分層思想引入,提出了在基于代理的層次式增量集成的分布式數據挖掘模型HII DDM,其核心思想是,將整個系統劃分為兩層。在子系統層根據所有數據節點,用II DDM模型生成相應子系統的聚類結果;在全局聚類層,再用II DDM模型生成整個系統的聚類結果。分層后克服了原模型個體合作和串行工作方式的缺點。之后在HII DDM模型的基礎上提出了基于該模型的分布式聚類算法。基于此模型的算法不但繼承了傳統的基于代理模型算法在健壯性和高效性而且還很靈活,文章中是基于兩層模型的算法,但不僅限于兩層,在更大規模或數據庫更分布的情況下,還可以分為更多層。分層模型是改善超大規模數據集的伸縮性和效率問題的非常有效的途徑。
[1]HAN Jia-wei,Kamber M.數據挖掘概念與技術[M].范明,等譯.北京:機械工業出版社,2008.
[2]Hand D,Mannila H.數據挖掘原理[M].張銀奎,等譯.北京:機械工業出版社,2007
[3]Januzaj,Brecheisen S,Kriegel H P,et al.Visually mining through cluster hierarchies[C].Proc.Of SIAM Int’l Conf.on Data Mining Orlando,2011.
[4]Johnson E,Kargupta H.Collective Hierarchical clustering from distributed heterogeneous data[J].Computer Science,2010(1759):221-244,2010
[5]Kargupta H,Huang W Y,Sivakumar K,et al.Distributed clustering using collective principal component analysis[J].Knowledge and Information Systems,2011,3(4):422-448.
[6]Charu C,Agrawal,Philip S.Yu.Finding generalized project Clusters in High-dimensional spaces[C].SIGMOD Conference,2010:70-81.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
核科學與工程(2015年4期)2015-09-26 11:59:03
河南科技(2014年23期)2014-02-27 14:18:43
