翻譯過程的非線性與機輔翻譯的有限性
2013-07-18 06:20:21唐燁
大陸橋視野·下 2013年5期
唐燁
摘 要 本文從非線性這個概念入手,論述了翻譯過程的非線性過程的內涵,并舉例說明了由此而導致的機器翻譯存在的有限性,指出由于英漢兩種語言之間的差別,使得翻譯過程不是簡單地一一對應的過程,而是一種復雜的多因素影響的結果,如語境因素及文化差異。而這些問題在目前的機器翻譯中沒有得到有效地解決,致使機器翻譯的適用范圍有一定的局限性。
關鍵詞 非線性 機器翻譯 語料庫 文本類型
一、引言
隨著全球化的發展和科學技術的進步,翻譯工作也面臨著越來越大的挑戰。全球文化和科技的交流,極大地拓寬了翻譯市場。科技的迅猛發展,也使翻譯工作由傳統的人工作業逐漸向計算機作業轉變。然而機遇和挑戰并存,機器翻譯雖然方便快捷,但是目前來看還缺乏準確性,使用的范圍不夠廣,從質量上無法滿足時代的需求。為了分析計算機翻譯有限性的原因,本文先提出了一個非線性的概念,然后通過對漢英語言的對比,分析翻譯過程的非線性過程,并借以說明機器翻譯的有限性,并通過機器翻譯和筆者翻譯來進一步對比證明。
二、翻譯過程的非線性
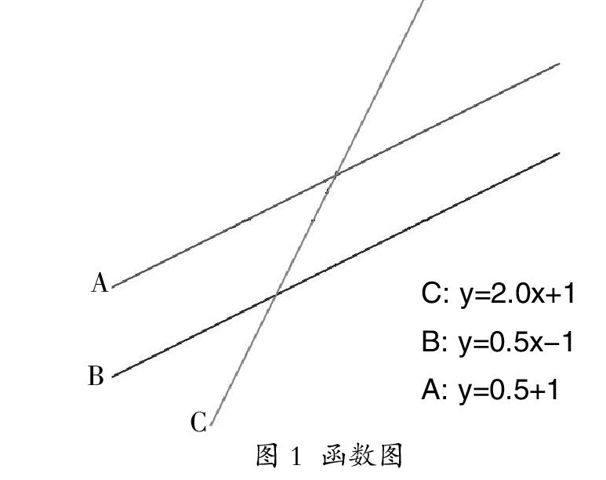
1.非線性的定義。非線性是一個數學的、物理的概念,要談非線性,首先要從線性這個概念說起。所謂線性即linear,是指量與量之間按比例、成直線的關系,在數學上可以理解為一階導數為常數的函數,其畫在函數圖上會呈現一條直線,見圖1。
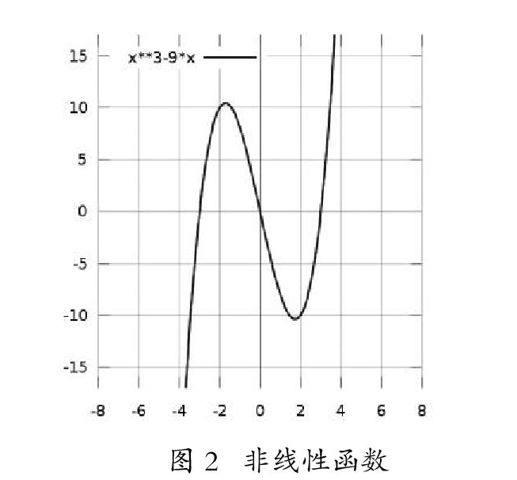
線性意味著方程的解與方程本身是一種一一對應的關系。以y=2x+1為例,x=1時,y只有唯一解,即y=3。線性也意味著系統的簡單性,但世間萬物的自然現象就其本質來說,都是復雜的,非線性的。非線性即non-linear,是指兩個變量間的關系,是不成簡單比例(即線性)關系的,也就是說其畫在函數圖上不會呈現單一一條直線,有可能會是折線或者呈曲線狀。如圖2所示為一個非線性函數,y=x3-9x。
非線性意味著一種非一一對應的關系,是復雜的、曲折性的。我們在處理非線性關系時,就要考慮到多方面的因素,翻譯活動即是如此。
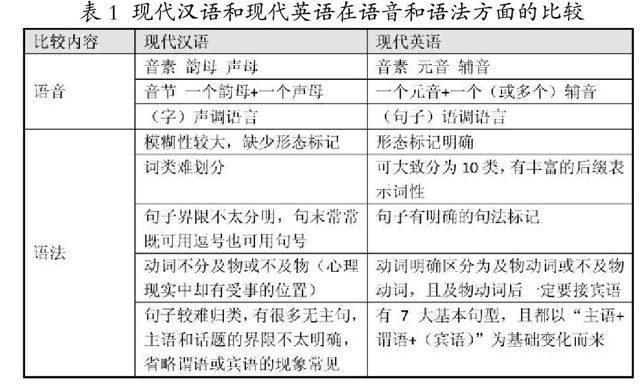
2.翻譯過程的非線性定義。“翻譯是以符號轉換為手段、意義再生為任務的一項的跨文化交際和活動”,而翻譯的過程即是解釋符號意義的過程。而英漢之間的翻譯就是解讀英語和漢語這兩種語言符號的過程。漢語是有別于英語的語言符號系統,因此兩者之間存在的巨大差別,是我們在翻譯過程中碰到的主要障礙。漢字是人類歷史上最古老的表意文字之一,它具有形象化、表意為主表音為輔較強的穩定性等特征。而漢字的這些特征,是英語這一拼音文字不可比擬的。下面我們從語音和語法方面對現代漢語和現代英語之間進行一個概略比較,見表1。
從上表1可以看出,漢語和英語的語音系統,尤其是語法系統,差別很大。由于漢語與英語之間相去甚遠,漢語和英語這兩種符號之間的翻譯就不可能做到一一對應,更不可能像一次線性函數方程一樣找到唯一解。也就是說,翻譯的過程是一種非線性的過程。要準確地進行翻譯,不僅要理解句義、理解詞義,更要理解語境,理解兩種語言之間存在的文化差異。而對于語境和文化之間的理解和解析,只能通過譯者的揣摩,這一點通過機器是無法做到的。
三、基于語料庫的機器翻譯
1.機器翻譯的概念。所謂機器翻譯(machine translation)是指把一種自然語言生成另一種自然語言的計算機系統,是在沒有人工干預的情況下,由機器進行語言之間的轉換。通常我們利用計算機的計算能力來分析源語中的話語結構,并將其分割成為易于翻譯的單元,從而在目標語中以相同的結構重新創建話語。而機器翻譯則是基于語料庫而建立起來的。
2.語料庫的概念。那什么是語料庫呢?語料庫的英文是corpus,有“集合”、“全集”之意。因此,在通俗意義上,語料庫就是語料收集的倉庫。而作為專業術語,不同的人對此有不同的說法,在這里我們采用《語言學和語音學詞典》中的定義。語料庫是“語言資料的收集,通常是經加工后帶有語言學信息標注的語料文本,可以被用作語言描述的起點或驗證語言假設的方式”。由此看來,語料庫作為語言樣本的集合,不僅僅包括一些文本文件,還包括電子文件。語料庫是真實的,譯為語料的收集取自于真實的語言材料,取自于正在“使用中”的語言,來自于我們的工作、生活,來自于各種正式的、非正式的環境,能夠反映語言變化的規律,代表和體現了無限真實的語言環境。因此,我們也可以說語料庫是人們長期生活積累下來的習慣性話語,翻譯的工作就是將一種語言迅速對應到另一種語言的習慣性話語上,譯出讓受眾都能理解的文本。
3.基于語料庫的機器翻譯。在本文中,我們主要討論的是基于語料庫的機器翻譯,因此分析基于語料庫的機器翻譯的模式,將更有利于我們了解機器翻譯的過程,以找出其局限性。基于語料庫的機器翻譯主要有以下兩種模式:基于統計的翻譯方法和基于實例的翻譯方法。基于統計的機器翻譯方法是把翻譯問題看作是一個噪音信道問題,源語言經過一個噪音信道而發生了扭曲變形,因而在信道的另一端展現為另一種目標語言,翻譯的問題實際上就是如何根據觀察到的目標語還原成為最可能的源語。實質上是采用了一種概率計算的方法,把源語和目標語看成兩種對應的模型,通過統計分析映射來解決翻譯問題。而基于實例的方法是把翻譯看成是一種解碼過程。系統根據已有的翻譯樣例分析源句和目標句,計算匹配程度,并查找出和源句詞匯和表達最相配的目標句。以此類推,直至生成完整的句子。
由此可以看出,基于語料庫的機器翻譯在翻譯過程中完全依賴于語料庫的健全程度,分析時是基于單個詞語或單個句子,并從語料庫中調用相應的對齊詞語或句子。然而翻譯時需要考慮的語境和文化因素是無法靠語料庫進行解讀的。由于翻譯過程經常依賴于超語言信息,這些信息用計算機術語很難捕捉,換言之,正確理解自然語言在很大程度上依賴于人類的語言直覺。從這個意義上來講,機器翻譯具有一定的有限性。
4.機器翻譯的有限性。由以上分析可以看出,翻譯的非線性過程意味著在翻譯時我們要更多地考慮到兩種語言之間的文化差異和語境,而機器翻譯則是基于一種規則,按照程序的指令進行翻譯,無法將文化因素考慮進去。因此,我們可以認為機器翻譯的可譯度應該與文本的體裁類型密切相關。文本的文學程度越高,即所包含文化的因素越多,機器翻譯的可譯度越低;相反,文本越偏向自然科學等陳述事實的文體,包含文化的因素越低,機器翻譯的可譯度越高。下面將分別以科技文體和文學文體為例,討論機器翻譯的可譯程度。
例1.As a technology bringing together several fields including physics, chemistry, biology and computer sciences, nanotechnology will, theoretically, enable you to make everything we can make today.
谷歌翻譯譯文:作為一個匯集多個領域,包括物理,化學,生物學和計算機科學技術,納米技術,從理論上說,讓你做的一切,我們今天可以。
有道詞典譯文:作為一項技術,召集幾個領域,包括物理、化學、生物學和計算機科學、納米技術,從理論上講,使你能夠讓一切,我們可以讓今天。
SYSTRAN譯文:作為帶來幾個領域包括物理的技術,化學、生物和計算機科學,納米技術,理論上,將使您做我們可以今天做的一切。
筆者修改譯文:納米技術,集多學科于一身。包括物理,化學,生物學和計算機科學技術。從理論上講,納米技術可以制造出現有的所有東西。
將三種機器翻譯的譯文進行對比發現,機器翻譯對專業名詞的翻譯不會出現錯誤,因為可以直接調用語料庫中的專業詞典信息,而無需考慮文化因素的影響。而機器翻譯時基本不會改變原文語序,導致句子的理解有不恰當的地方。但是筆者根據機器翻譯結果只需進行小部分調整語序即能完成。
例2. While the present century was in its teens, and on one sunshiny morning in June, there drove up to the great iron gate of Miss Pinkerton's academy for young ladies, on Chiswick Mall, a large family coach, with two fat horses in blazing harness, driven by a fat coachman in a three-cornered hat and wig, at the rate of four miles an hour.(W.M.Thackeray:Vanity Fair, Ch.1).
谷歌翻譯譯文:而在本世紀是在其十幾歲,和1六月,天氣晴朗早晨,有駕駛起來的偉大的鐵閘門的陸平克頓的年輕女士,奇西克購物中心,1大型家庭教練2熾烈線束脂肪馬,中國科學院,驅動由脂肪車夫在三個角的帽子和假發,在每小時4英里的速度。
有道詞典譯文:而現行的世紀的青少年,在一個早上吹拂在六月,那里開到大鐵門的平克頓小姐的年輕女子學院,句購物中心,一個大家庭的教練,有兩匹馬具脂肪燃燒,驅動在三角帽的語意連貫和假發,四英里每小時的速度。
SYSTRAN譯文:當前世紀是在它的十幾歲之內和在一個陽光照耀早晨在6月時,那里駕駛了到Pinkerton小姐的學院巨大鐵門小姐的, Chiswick購物中心,一位大家庭教練的,有二匹肥胖馬的在燃燒的鞔具,駕駛由一位肥胖馬車夫一頂三角帽子和假發的,以四英里每小時的率。
筆者修改譯文:當時我們處在這個世紀的前十幾年。六月里的一天早上,天氣晴朗,陽光明媚。契息克林蔭道上平克頓女子學院的大門前來了一輛寬大的私家馬車。拉車的兩匹肥馬套著雪亮的馬具,駕車的馬夫帶著假發和三角的帽子,趕車速度1小時4公里。
而機器翻譯的文學文體時,基本上只是翻譯出單個詞語的意思,脫離了整個語境,句子成為了詞語的簡單堆疊。筆者需要結合語境經過大量加工修改,才能完成。
通過以上對比可以看出,機器翻譯存在的有限性表現在:(1)對于句法復雜的句子處理時,過于簡單化,使句子失去了原有的語義關系。由于英語句法結構的復雜性,機器無法準確確定某一詞語在句子里的依附關系。如第一篇文本中“make everything we can make today”,機器翻譯時,無法分析出這句話中“we can make today”是“everything”的同位語,導致譯文將這一小句翻譯已成了兩個毫無關系的句子“讓你做的一切,我們今天可以”;(2)由于語義存在的模糊性,使翻譯出的句子脫離了語境意義。由于每個詞語放在不同的語境中都會產生不同的意義,因此在翻譯時需要結合語境考慮,而機器翻譯做不到這一點。如第二篇文本“Chiswick Mall”一詞中的“mall”不再是原意“百貨商場”而根據語境和上下文,這里指的是“林蔭道”。
由此可見,機器翻譯在處理文學類文本時難度相對較大,而對于非文學類文本的可譯度較高。主要原因在于后者所使用的語言具有句法結構相對簡單、詞性較為單一,形式較為規范等特點。因此,機器翻譯目前更適用于“科普文獻、金融商業交易、行政管理備忘錄、法律文書、說明書、農業及醫學資料、工業專利、宣傳冊、報紙等”。機器翻譯要克服這些局限性,實現全自動翻譯,譯文質量達到專家水平還需努力。雖然目前機器翻譯在一定的專業領域,尤其是科技領域中已經廣泛成功的使用,但是在大部分文學作品的翻譯中,機器翻譯的準確度是非常低的。目前的大部分機器翻譯還是基于孤立的句子為單位,因此機器翻譯未來的發展方向還是要努力考慮語境因素,將范圍擴大到句群甚至整個語篇,這樣語意間的轉換才會更為準確。這樣不僅能提高翻譯的速度,更重要的是能提高譯文的質量。
五、結束語
本文從介紹非線性這個數學概念出發,將這個概念引入翻譯中,由此討論了基于語料庫的機器翻譯,及由于翻譯過程的非線性而造成的機器翻譯的有限性,并通過科技文本和文學文本兩個例證對比證明了機器翻譯的適用范圍存在著一定的局限性。機器翻譯要實現真正意義上的全自動翻譯,必須跨過對語言的淺層次分析而進入深層次的分析領域,努力考慮語境、篇章因素。機器翻譯要達到高質量、高精確性的譯文,還有很長的路要走。
參考文獻
[1]Hutchins, W. J. & H. L. Somers. An Introduction to Machine Translation[M].London:Academic Press,1992,3.
[2]陳海東.計算機翻譯存在的困難及解決方法新探.廣東科技,2009,第219期:87-88.
[3]陳宏薇.高級漢英翻譯.北京:外語教學與研究出版社,2009.24-25.
[4]劉楊.語料庫與機器翻譯.大眾文藝,2009,第19期:23.
[5]許鈞.翻譯論.武漢:湖北教育出版社,2003,75.
[6]余國良.語料庫語言學與應用.成都:四川大學出版社,2009.
