基于數據挖掘的渤海灣水生態環境特性研究
2013-08-14 05:49:14向先全王海波路文海楊翼陶建華
海洋通報 2013年1期
向先全,王海波,路文海,楊翼,陶建華
(1.國家海洋信息中心,天津 300171;2.天津大學 環境科學與工程學院,天津 300072)
隨著包括遙感在內的現代化監測技術的發展和監測手段的多樣化,水生態環境數據的數量、覆蓋范圍和復雜性都在飛快地增長。如何科學、有效地利用這些數據,從中獲取潛在有用的信息,成為水生態環境研究的重要問題。因此,需要一種從大量數據中去粗存精、去偽存真的技術,數據挖掘技術就是人們長期對數據庫技術進行研究和開發的結果,是信息技術自然演化的結果(魏紅宇等,2008)。國內外關于數據挖掘技術在海洋領域的應用研究已經取得了許多實質性的進展。Bridges等(1999)利用海洋數據源開展了分類規則挖掘的研究;Kitamoto(2002)對海洋遙感圖像進行了聚類分析研究;馬超飛等(2003)針對遙感圖像的關聯規則挖掘進行了深入研究;夏登文等(2005)利用海洋數據倉庫開展了數據挖掘技術方法的研究;寧勇(2008)將數據挖掘技術應用于海洋環境在線監測及赤潮災害智能預警系統中,取得了較好的效果。
渤海灣是位于渤海西側的一個半封閉淤泥質淺水海灣,海水交換能力和自凈能力很弱,近岸海域水體的富營養化和赤潮頻繁發生(向先全 等,2011)。近年來,隨著衛星遙感技術的快速發展,其在近岸海域生態環境研究中應用廣泛(Takahiro et al,2007)。因此,本文以渤海灣為研究背景,利用海洋環境遙感數據,綜合采用多種數據挖掘技術對渤海灣的水生態環境特性進行研究。
1 研究方法
數據挖掘覆蓋的算法很廣,在特定的問題中,數據挖掘的分析方法有一定的區別,這主要取決于數據的類型和規模,以及問題求解的目標。常用的數據挖掘分析方法包括:聚類分析、關聯分析和決策樹分析等(廖芹等,2010)。
聚類分析是對一群不知道類別的觀察對象按照彼此相似程度進行分類,達到“物以類聚”的目的。主要是用數學的方法研究給定對象的分類,把一個沒有類別標記的樣本集按某種準則分成若干個子集(類),使相似的樣本盡可能歸為一類,而不相似的樣本盡量劃分到不同的類中。聚類分析的算法可分為:分裂法、層次法、基于密度方法、基于網格方法、基于模型方法等。
關聯分析就是要發現關聯規則,找出給定數據集中數據項之間的聯系,發現項目集或屬性之間的相關性、關聯關系。一個典型的關聯規則是“在購買面包和黃油的顧客中,有90%的人同時也買了牛奶”(面包+黃油=>牛奶)。一般用信任度和支持度來描述關聯規則的屬性。設D是一個事務數據庫,其中每一個事務由一些項目構成,項目的集合簡稱項目集,項目集X的支持度是指在事務數據庫D中包含項目集X的事務占整個事務的比例,即項目集X在總事務中出現的頻率,記為sup(X),一般定義為

可信度是指項目集X出現,使項目集Y也出現的事件在總事務中出現的頻率,記為conf(Y|X),一般定義為
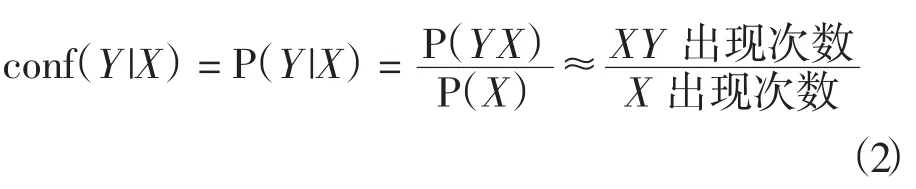
支持度可發現頻率出現較大的項目集,而可信度可發現頻率較大的關聯規則,體現項目集在另一項目集影響下相對總事務所占的比重。關聯分析的目的是從已知的事務集中產生數據項集之間的關聯規則,同時保證規則的支持度和信任度大于用戶預先指定的最小支持度和最小信任度。
決策樹學習算法是以一組樣本數據集為基礎的一種歸納學習算法,著眼于從一組無次序、無規則的樣本數據中推理出決策樹表示形式的分類規則。決策樹是類似于流程圖的一個樹狀結構,由一個根節點、一系列內部節點(分支節點)以及終極節點(葉節點)組成。每個非葉節點表示對一個屬性的測試,每個分支對應于一個輸出;每個葉節點表示一個判定的類別。決策樹學習算法最大的優點就在于它在學習過程中不需要了解很多的背景知識,只從樣本數據集提供的信息就能夠產生一棵決策樹。
2 研究區域及數據來源
本文采用的衛星遙感數據來源于國家衛星海洋應用中心,使用的是國家海洋一號衛星HY-1B的遙感數據。圖1為該衛星遙感水體葉綠素濃度的一個專題圖示例。通過遙感影像反演,提取出海洋生態環境的一些指標因子,其數據格式為HDF(Hierarchical Data Format)格式。
圖1 衛星遙感水體葉綠素濃度的專題圖示例
衛星遙感探測的生態環境指標主要有4個:葉綠素濃度(CHL)、懸浮泥沙濃度(Suspended Sediment Concentration,SSC)、海水透明度(Secchi Disk Depth,SDD)及海表溫度(Sea Surface Temperature,SST),單位分別為μg/L、mg/L、m和℃。利用美國資源系統研究所(ESRI)開發的ArcGIS軟件中的功能模塊,讀取HDF文件,然后轉化為柵格數據形式。HY-1B衛星圖像的分辨率為0.01°×0.01°,約為1 100 m×1 100 m。本文的研究中,渤海灣覆蓋的網格數為11 106個,如圖2所示。

圖2 渤海灣覆蓋的網格
通過HY-1B衛星,每日可獲取2幅生態環境因子的遙感影像。本文采用的水生態環境遙感數據,其時間范圍為2008-2009年。2008、2009年渤海灣各網格中水生態環境各指標的遙感數據采用該網格中該指標的年均值計算而來。由于陰雨等天氣原因,衛星遙感并不能實時地檢測到地面(海面)的信息,故在原始的遙感數據中,欠缺了某些空間位置或某些天的遙感值。本文對于圖像中未檢測的像素,采用剔除方式進行處理。
3 研究結果與討論
3.1 基于k-means算法的渤海灣水生態環境聚類分析
通過聚類分析可以把指標值大小相似的網格聚在一起,將渤海灣分成不同的區塊,通過研究各區塊的指標值可更清楚地了解渤海灣水生態環境的一些特性。本節利用聚類分析的k-means算法對2008和2009年渤海灣水生態環境特性進行研究,k-means算法是一種基于劃分的聚類方法,是最常用和最知名的聚類算法。利用k-means算法分別對2008和2009年的渤海灣遙感數據進行聚類分析。由于各指標的單位不同,而且各指標值的數量級也有差異,故聚類之前對各指標進行標準化處理。
原始的遙感數據為 Xi=(xi,1,…,xi,j,…,xi,m),通過公式(3)標準化為:Zi=(zi,1,…,zi,j,…,zi,m),其中i表示渤海灣網格數,i=1,2,…,n,n為11 106;j表示遙感指標數,j=1,2,…,m,m為4。

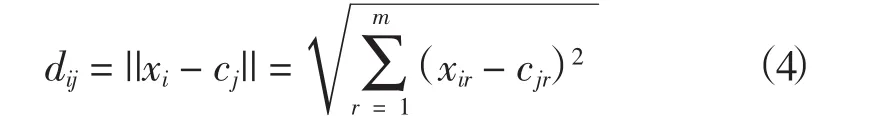
其中:dij表示xi到cj的歐氏距離,cj表示聚類中心。
通過計算發現當取k=3時,聚類的效果最好,此時將遙感數據在渤海灣空間上共聚成3類。2008和2009年的聚類結果如圖3所示,藍色為第Ⅰ類;綠色為第Ⅱ類;黃色為第Ⅲ類。表1給出了各聚類中心的指標值。第Ⅰ類主要分布在渤海灣東北部,表現出葉綠素濃度低、懸浮泥沙濃度低、透明度高和海表溫度較低的特征。第Ⅲ類主要分布在渤海灣西南部,表現出與第Ⅰ類相反的特征。第Ⅱ類的聚類中心各指標值在第Ⅰ和第Ⅲ類聚類中心值的中間,同時在空間上也處于中間過渡區域。

圖3 渤海灣遙感數據的聚類圖

表1 渤海灣遙感數據的聚類中心
第Ⅰ類區域的分布位置靠近渤海中部,離近岸較遠,受陸源影響較小,因此表現出懸浮泥沙濃度低、葉綠素濃度低等特征。對于第Ⅲ類區域,王勇智(2006)和于煒(2011)指出受風浪、潮流以及環流等影響,渤海灣南部始終維持懸浮物濃度高,同時由于懸浮物對氮、磷等營養鹽的吸附作用,促進浮游植物的生長(畢玲玲,2006),加上陸源營養鹽的作用,因此在渤海灣近岸西南部出現懸浮泥沙濃度高、葉綠素濃度高等特征。
3.2 基于Apriori算法的渤海灣水生態環境關聯分析
通過關聯分析,提取出大于最小支持度和最小可信度的指標之間的關聯規則,可以了解渤海灣各生態環境指標之間的聯系。Apriori關聯規則算法是一種最有影響的挖掘布爾型關聯規則頻繁項集的基本算法,貨籃分析就是采用這種算法進行的。
關聯規則挖掘通常適用于指標值為離散值的情況。由于生態環境遙感數據庫中的指標值是連續的數據,故在關聯規則挖掘之前應該進行適當的數據離散化(即把某個區間的值映射為某個值)。本文采用聚類離散化方法,利用3.1節分析的聚類中心對各指標的遙感數據進行離散處理,將每個指標按離中心的遠近分成三類,各指標值從小到大分別標記為“低”、“中”、“高”。
利用Apriori算法對離散化處理后的渤海灣遙感數據進行關聯分析。取最小支持度min_sup為0.08,最小可信度min_conf為0.5,關聯分析的結果見表2和表3。
表2顯示了從渤海灣遙感數據中提取的極大頻繁集,2008和2009年的極大頻繁集中都包括:高CHL、低 SDD、高 SSC及高 SST;中 CHL、中SDD、中SSC及中SST。表明它們在整個渤海灣遙感數據集中出現頻率較大,表現出較強的關聯性。需要指出的是,獲得的關聯規則并沒有包含各指標的內在機理性聯系,因此其是否具有因果關系還需進一步驗證。

表2 遙感數據關聯分析的極大頻繁集

表3 遙感數據的關聯規則及可信度
表3給出了Apriori算法計算的渤海灣遙感數據的關聯規則及其可信度情況。從大于0.9可信度的情況來看,2008年遙感數據有兩條關聯規則“高SSC,高SST,高CHL=>低SDD”和“高SSC,中SST,高CHL=>低SDD”,聯合這兩條規則(至少從數據上)可表明:高SSC、高CHL以及SST不低的時候SDD就會低。2009年遙感數據中關聯規則“高 SDD,低 SSC,低 SST=>低 CHL”和“低SDD,高SSC,高SST=>高CHL”的可信度也大于0.9。對2008年和2009年各指標因子的年均值進行相關性分析,兩年的相關性分析結果都表明了CHL與SSC和SST有較好的正相關關系,而與SDD有負相關關系。以上幾條關聯規則與相關性分析的結果相互吻合。
3.3 基于CART算法的渤海灣水生態環境決策樹分析
決策樹學習是當前應用最廣泛的歸納推理方法之一,對噪聲數據也有比較好的魯棒性,且能夠直接得到學習的析取表達式。由于CART算法只產生二叉,計算速度快,且適合于混合數據問題的處理,因此本文采用CART算法對渤海灣生態環境遙感數據進行分析。
由于葉綠素濃度是表征浮游植物生物量的重要指標之一,了解葉綠素濃度可掌握水體初級生產力情況和富營養化程度。因此,本文水生態環境的決策樹分析以葉綠素濃度為標簽向量,其它3個變量——SDD、SSC、SST為屬性向量對葉綠素濃度進行分類研究。葉綠素濃度采用3.2節的聚類離散化方法,離散為3個值:“低CHL”、“中CHL”、“高CHL”。而對其它3個指標不做離散化處理,仍為連續值。
利用CART算法對2008和2009年渤海灣生態環境遙感數據進行決策樹分析。在運算過程中,構建分類樹第一步驟時產生的最大樹Tmax時,分支有很多個,共有1千余個,其準確率也較大(2008年準確率為89.35%;2009年準確率為90.93%)。但是由于過多的分支使得分類較困難,也失去了決策樹快速分類的優勢,因此需要進行一定的修剪操作。通過一次修剪后所構建的決策樹如圖4所示。圖中決策樹各非葉節點右側的不等式表示該節點的測試準則,左分支表示滿足測試屬性,右分支表示不滿足測試屬性。SDD、SSC和SST的單位分別為m、mg/L和℃。
通過一次修剪后,2008和2009年渤海灣水生態環境數據的決策樹具有了一定的可讀性,葉綠素濃度的分類準確率分別為74.29%、79.18%。雖然其準確率有所降低,但分支數大大減少,也避免了“過擬合”的問題,可進行實際情況的分類操作。為進一步地提高決策樹的可讀性以及便于分析,對以上兩個決策樹進行了二次剪枝操作,剪枝后的決策樹如圖5所示。
從圖中可以看出,通過二次修剪后,得到的水生態環境數據決策樹分支較少,可讀性很強。這兩棵決策樹對2008和2009年渤海灣葉綠素濃度分類的準確率分別是72.01%、76.94%,準確率較高。與第一次修剪后決策樹的準確率相比,下降得并不明顯。
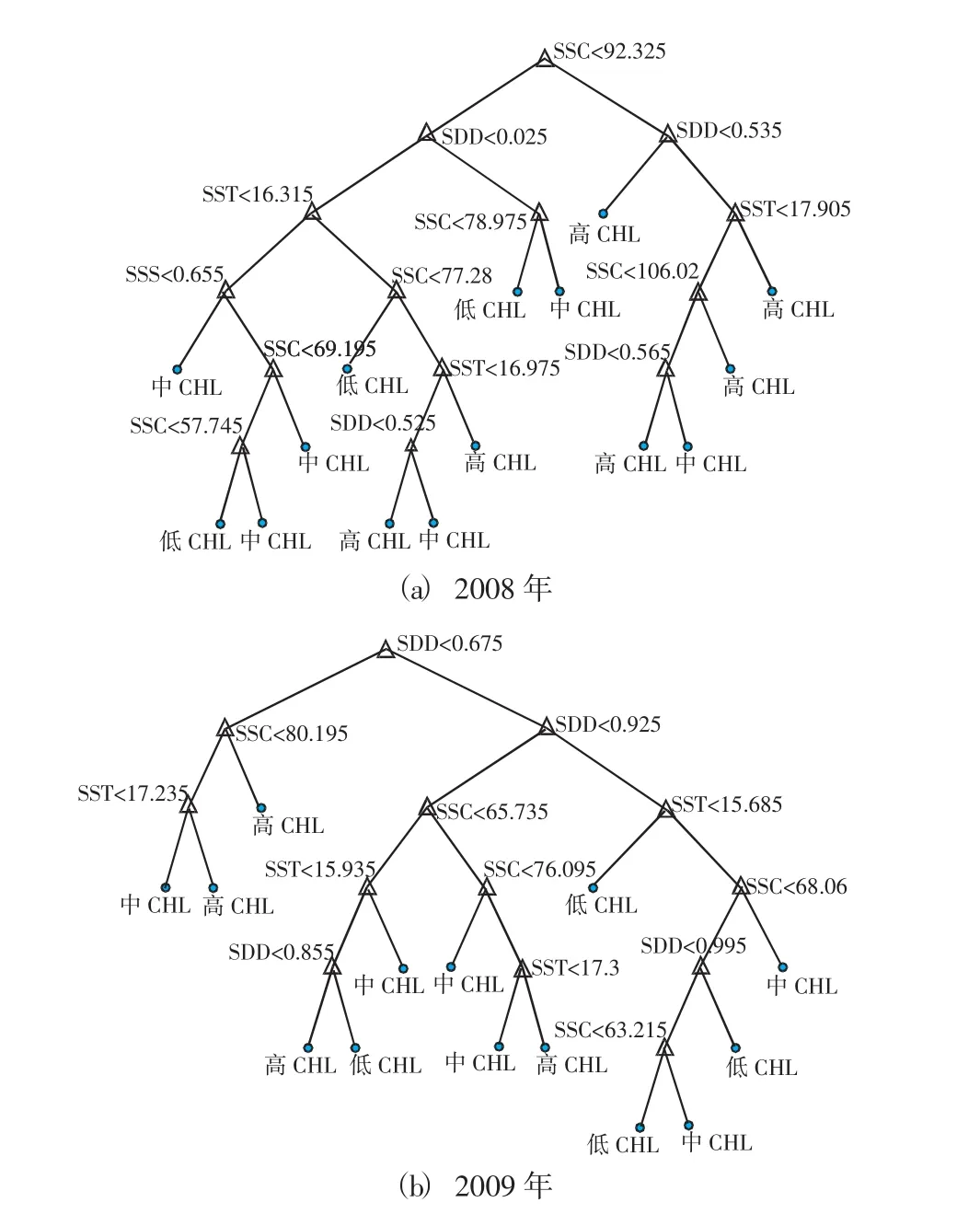
圖4 2008和2009年渤海灣水生態環境數據的決策樹(一次修剪)

圖5 2008和2009年渤海灣水生態環境數據的決策樹(二次修剪)
這兩棵決策樹都含有5個葉節點,可分別對應5個分類準則。如2008年的最簡潔的一個分類準則“SSC大于或等于92.325 mg/L時,葉綠素濃度較高”;2009年的一個分類準則“SDD小于0.675m,且SSC大于或等于80.195 mg/L時,葉綠素濃度較高”。其它的分類準則可類似地得到。通過這些分類準則可對渤海灣遙感葉綠素濃度進行快速地分類判別,以及進行相應的特性研究。
4 結論
本文對海洋數據挖掘的理論和方法進行了研究,以渤海灣為研究背景,利用海洋環境衛星遙感數據,對渤海灣水生態環境特性進行聚類分析、關聯分析和決策樹分析等一系列的數據挖掘研究,得出了如下的結論:
(1)利用k-means算法對2008和2009年渤海灣生態環境的年均遙感數據分別進行了聚類分析。將渤海灣遙感數據共聚成3類,聚類結果表現為較強的空間分布特征。第Ⅰ類主要分布在渤海灣東北部,表現出低CHL、低SSC、高SDD和低SST的特征。第Ⅲ類主要分布在渤海灣西南部,表現出與第Ⅰ類相反的特征。第Ⅱ類聚類中心的各指標值在第Ⅰ和第Ⅲ類聚類中心值的中間,同時在空間上也處于中間過渡區域。
(2)利用Apriori關聯規則算法對聚類離散化處理后的渤海灣生態環境遙感數據進行了關聯分析。2008和2009年的極大頻繁集里都包括了“高CHL、低SDD、高SSC、高SST”和“中CHL、中SDD、中SSC、中SST”。表明它們在整個渤海灣遙感數據中出現的頻率較大,表現出較強的關聯性。通過關聯分析還得出了渤海灣遙感數據的一些關聯規則及其可信度情況。
(3)利用CART算法對2008和2009年渤海灣生態環境遙感數據進行了決策樹分析。以聚類離散化處理后的葉綠素濃度為標簽向量,其它三個變量——SDD、SSC、SST為屬性向量對葉綠素濃度進行分類研究。通過兩次修剪后,分別得到了分支少、可讀性強的2008和2009年渤海灣生態環境遙感數據決策樹。這兩棵決策樹都含有5個葉節點,可分別對應5個分類準則。通過這些分類準則可對渤海灣遙感葉綠素濃度進行快速地分類判別,以及相應的特性研究。
需指出的是,數據挖掘得出的結論來源于數據本身,而其中內在聯系還需結合海洋生態環境的內部作用機理加以分析。本文將數據挖掘方法引入到海洋生態環境的研究中,可為日益增長的海洋生態環境海量數據分析提供新手段、新思路。
致謝:本文采用的衛星遙感數據是國家衛星海洋應用中心提供的海洋一號衛星HY-1B的遙感數據,在此對國家衛星海洋應用中心表示感謝。
Bridges S,Hodges J,Wooley B,et al,1999.Knowledge discovery in an oceanographic database.Applied Intelligence,11(2):135-148.
Kitamoto A,2002.Spatio-temporal data mining for typhoon image collection.Journal of Intelligent Information Systems,19(1):25-41.
Takahiro Iida,Sei-Ichi Saitoh,2007.Temporal and spatial variability of chlorophyll concentrations in the Bering Sea using empirical orthogonal function(EOF)analysis of remote sensing data.Deep Sea Research Part II:Topical Studies in Oceanography,54(23-26):2657-2671.
畢玲玲,2006.膠州灣懸浮物組成特征及對營養鹽的吸附解吸作用研究.學位論文,青島:中國海洋大學.
廖芹,郝志峰,陳志宏,2010.數據挖掘與數學建模.北京:國防工業出版社.
馬超飛,劉建強,2003.遙感圖像多維量化關聯規則挖掘.遙感技術與應用,18(4):243-247.
寧勇,2008.數據挖掘在海洋環境在線監測及赤潮災害智能預警系統中的應用.濟南:山東大學.
王勇智,2006.渤、黃、東海懸浮物濃度及輸運季節變化的數值模擬.學位論文,青島:中國海洋大學.
魏紅宇,張峰,李四海,2008.海洋數據挖掘技術應用研究.海洋通報,27(6):82-87.
夏登文,石綏祥,于戈,等,2005.海洋數據倉庫及數據挖掘技術方法研究.海洋通報,24(3):60-65.
向先全,陶建華,2011.基于GA-SVM的渤海灣富營養化模型,天津大學學報,44(3):215-220.
于煒,2011.渤海表層懸浮物分布變異規律的研究.學位論文,青島:中國科學院海洋研究所.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
