基于最小二乘向量機的厭氧發酵沼氣產量建模研究
2013-09-03 10:50:54秦國輝劉旭丹
黑龍江科學 2013年2期
秦國輝,劉 偉,劉旭丹
(黑龍江省科學院科技孵化中心,哈爾濱 150090)
大型沼氣工程日漸成為利用厭氧發酵技術開發綠色生物質能源的熱點和重點,是消除畜禽養殖廢棄物污染的重要手段之一,其經濟及環境效益顯著[1]。然而,目前尚無精確的在線測量手段來測量發酵過程中關鍵生物參量,因此無法建立發酵過程模型來預測沼氣產量。這直接影響發酵過程控制和優化水平的提高,制約了沼氣工程的發展[2]。因此,通過實時可測量變量進行建模,對沼氣產量進行預估就顯得非常重要。
針對牛糞高溫厭氧發酵過程的特點,本文主要研究了將最小二乘支持向量機(Least Squares Support Vector Machines,LS—SVM)這種基于支持向量機(Support Vector Machine,SVM)改進后的快速算法,應用到牛糞高溫厭氧發酵這一生化過程中來。基于實驗數據的仿真結果表明,該方法能夠通過多批次的樣本數據的學習,建立沼氣產量的在線預估模型。
1 最小二乘支持向量機建模方法
眾所周知,最小二乘法(Least Squares,LS)是解決多元函數回歸的經典方法。Suykens等人[3-4]在SVM的基礎上引進了LS,將不等式約束改為等式約束,避免了求解耗時的QP問題,并將求解優化問題轉化為求解線性方程,從而很大程度上降低了運算時間,為在線估計創造了有利條件。而且相對于常用的線性不敏感損失函數,LS-SVM不再需要指定逼近精度ε,只是LS-SVM的解不具有稀疏性。
用于函數估計最小二乘支持向量機的算法推導如下:
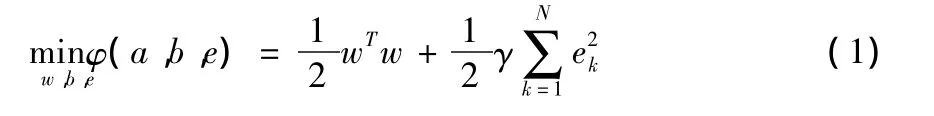
根據式(1),定義拉格朗日函數:

其中,拉格朗日乘子αk∈R。對上式進行優化,即對w,b,ek,αk的偏導數等于 0,可以得到矩陣方程:

同時將Mercer條件代入到Ω =ZZT,可得:
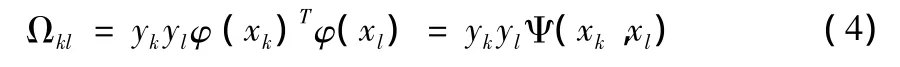
因此,式(1)的分解可以通過解式(4)和式(5)獲得最小二乘支持向量機函數為:

其中:Ψ(x,xk)是核函數,目的是從原始空間抽取特征,將原始空間中的樣本映射為高維特征空間中的一個向量,以解決原始空間中線性不可分的問題。
2 厭氧發酵沼氣產量預估模型
本文用于建模分析的數據來自牛糞高溫厭氧發酵工程,采集發酵溫度、PH值、固體濃度、進料量和出料量等數據,將其中一部分樣本數據作為訓練集,剩余的樣本作為測試集。所有的仿真計算實驗在1臺Pentium850MHz內存2GB的計算機上進行,編程語言使用Matlab7.0。
2.1 參數調整與分析
LS-SVM方法中有兩個重要的參數γ和σ2需要調整[5]。γ為正則化參數即懲罰系數,用于控制函數的擬合誤差,γ值越大,擬合誤差越小,相應的訓練時間也就越多,但γ過大會導致過擬合;σ2是核函數參數,代表著帶寬,隨著σ2的變小,擬合誤差會變小,相應的訓練時間也就變長,但σ2過小會導致過擬合[6]。目前關于對參數的選擇還沒有一套系統有效的方法,本文以牛糞高溫厭氧發酵這一具體過程,對擬合誤差、預測誤差及訓練時間隨γ和σ2的變化趨勢進行了仿真,仿真實驗結果如圖1、2所示。
從圖1、2中我們可以很清楚地得到其基本方法,首先將σ2固定,讓γ不斷增大,因為隨著γ的增大,擬合誤差和預測誤差都會先變小,當預測誤差首次出現極小值時即停止訓練,相應的γ值作為選定值。然后將此γ值作為初值,用同樣的方法訓練得到σ2,于是LS-SVM的參數(γ,σ2)即可確定。這樣得到的(γ,σ2)不僅保證了預測誤差小即模型的推廣能力好,而且訓練時間短,可以適應實時在線預報的要求。
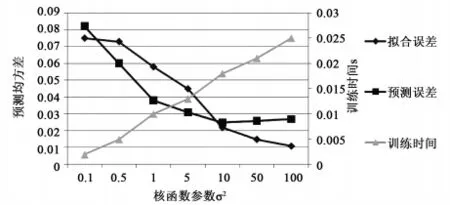
圖2 核函數參數σ2對擬合誤差,預測誤差和訓練時間的影響Fig.2 Effect of kernel function parameterσ2 on fitting error,prediction error and training time
2.2 預估結果與分析
選取4批次數據,對其中2-4批次的樣本數據分別建立沼氣產量在線預報模型。當一共有i批次的樣本時,取前i-1批次進行訓練并計算擬合誤差,第i批次用來檢驗模型的推廣能力并計算預測誤差。表1列出了所建預報模型的預測誤差。
從表1中可以看出預報模型的精度很高,而且通過批次的增加預測誤差還將慢慢變小,說明模型還有一定的自學習能力。為了全面檢驗模型的推廣能力,再采用交叉驗證法進行仿真,即任取4批數據中的3批按上述方式訓練預報模型,第4批次作為檢驗,分別計算每次的擬合誤差、預測誤差和訓練時間,列于表2。

表1 沼氣產量模型的預報誤差Tab.1 Predictive error of biogas output
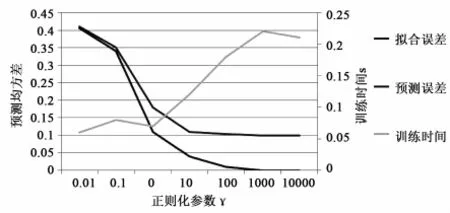
圖1 正則化參數γ對擬合誤差,預測誤差和訓練時間的影響Fig.1 Effect of regularization parameterγ on fitting error,prediction error and training time

表2 交叉驗證法建立4批次的沼氣產量在線預報模型的性能比較Tab.2 Performance comparison of predictive biogas output using cross-validation of 4 batches
從表2得知雖然訓練樣本改變,但所建預報模型的預測誤差變化并不大,說明此方法有一定的魯棒性,而且訓練時間都很短,可以對相關變量進行實時預報。圖3列出了對樣本數據的在線預報沼氣產量模型和實際生產數據的比較結果。
由圖3可知,所建立的預報模型有較高的精度,這表明在發酵過程操作條件下,僅通過幾個輸入變量就可以實現對沼氣產量進行準確的在線預報。

圖3 沼氣產量在線預測模型數據與實際數據對比Fig.3 Comparison of predictive biogas output with the actual results
需要指出的是,實際生產中一般是無法得到沼氣產量的準確估計的,必須考慮更多的過程因素。但本文所提出的方法仍舊適用,在實際應用中,只需將輸入實際工況所要估計的相關數據,而且可以選取多個可測變量作為LSSVM的輸入來實現對沼氣產量的估計。
3 結論
牛糞發酵過程是一個復雜的生化工程,建立其沼氣產量精確預測模型對生化過程的優化控制具有十分重要的作用。本文采用LS-SVM建模方法,建立了牛糞厭氧發酵過程變量在線預報模型,在對數據的要求方面遠遠低于神經網絡和多元回歸等傳統方法。通過仿真實驗獲得了LS-SVM參數調整策略。仿真結果表明此模型具有很強的擬合、泛化能力和學習能力,對樣本依賴程度低,可以較合適地描述時變和非線性的特性,適合復雜的發酵預估,具有廣泛的應用前景。本研究是具有實用價值的預測方法,進一步指導大型沼氣工程的智能控制,是我們下一步研究的工作。
[1]張智煥.復雜系統預測控制算法及其應用研究[D].浙江大學,2002:17-20.
[2]王建林,于濤.發酵過程生物量軟測量技術的研究進展[J].現代化工,2005,25(6):22 -25.
[3]Xiong ZH,Zhang J.Neural network model based on-line re-optimization control of fed-hatch processes using a modified iterative dynamic programming algorithm[J].Chemical Engineering and Processing,2005,44(4):477 -484.
[4]Hamrita T.K and Wang S.Patten recognition for modeling and online diagnosis of bioprocesses,IEEE Trails,On Industry Applications,2000,36(5),1295 -1299.
[5]劉國海,周大為,徐海霞,等.基于SVM的微生物發酵過程軟測量建模研究[J].儀器儀表學報,2009,30(6):1228 -1232.
[6]張學工.關于統計學習理論與支持向量機[J].自動化學報,2000,26(1):34-42.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
礦山安全信息(2022年40期)2022-04-07 02:16:52
今日農業(2021年14期)2021-11-25 23:57:29
石油與天然氣地質(2021年1期)2021-02-22 14:14:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
今日農業(2020年20期)2020-11-26 06:09:10
數學物理學報(2020年2期)2020-06-02 11:29:24
中國果業信息(2019年10期)2019-11-13 01:21:34
聚氯乙烯(2018年9期)2018-02-18 01:11:34
光學精密工程(2016年6期)2016-11-07 09:07:19
