Swift云存儲環境下基于I/O負載均衡的讀取策略
2013-09-10 01:18:34孫雪濤
計算機工程與設計 2013年9期
蔣 溢,孫雪濤,楊 川
(1.重慶郵電大學 計算機科學與技術學院,重慶400065;2.中國電信股份有限公司瀘州分公司,四川 瀘州646000)
0 引 言
云存儲通過集群技術、網格技術或分布式文件系統等,將網絡中不同類型的存儲設備協同起來,共同對外提供數據存儲和業務訪問服務。云存儲提出后,得到了眾多廠商的支持和關注。Amazon推出了EC2[1](彈性計算云)云存儲產品S3[2],旨在為用戶提供互聯網服務形式同時提供更強的存儲和計算功能。隨后微軟也已經推出了提供網絡移動 硬 盤 服 務 的 Windows Live SkyDrive[3]。Apache 根 據Google的 GFS[4]和 Bigtable[5]也 先 后 推 出 了 HDFS[6]和HBase[7],為云計算環境提供計算和存儲的支持。
本文基于開源Openstack[8]的對象存儲環境,首先分析了Openstack的Swift[9]對象存儲架構,針對其對象存儲沒有元數據中心節點、系統數據讀寫通過哈希一致性算法[10]完成,并沒有充分利用對象存儲系統的備份機制來改善系統數據讀取速度的現狀,給出了一種能夠均衡存儲設備I/O負載的策略,并在文章最后給出了相關實驗過程,實驗結果驗證了本文給出的策略的有效性。
1 Swift對象存儲架構
1.1 swift簡介
OpenStack Object Storage (Swift)是 OpenStack開 源云計算項目的子項目之一,被稱為對象存儲。Swift適用于永久類型的靜態數據的長期存儲,尤其適合存儲虛擬機鏡像、圖片存儲、郵件存儲和存檔備份等類型的數據。
1.2 Swift架構概述
Swift主要有4個組成部分:Proxy Server(代理服務)、Storage Server (存儲服 務)、Consistency Server (一致性服務)、Ring(環狀結構)文件,結構如圖1所示。

圖1 Swift組件結構
其中,Proxy Server是提供Swift API的服務器進程,負責Swift其余組件間的相互通信;Storage Server提供了磁盤設備上的存儲服務;Consistency Servers是保持一致性的服務器,其目標是查找并解決由數據損壞和硬件故障引起的不一致性;Ring文件是它整個Swift中最重要的組件,其主要作用是用于記錄存儲對象與物理位置間的映射關系,Ring使用域 (Zone)、設備 (Device)、分區 (Partition)和副本 (Replica)來維護這些映射信息。
2 Swift對象存儲文件讀取策略
Swift中存儲對象通過3個邏輯層次來實現的,分別是Account(賬戶)、Container(容器)、Object(對象)。一個Account包含多個Container,而一個Container又包含多個Object。所有每個對象的邏輯路徑都是/Account name/Container name/Object name。Swift中對對象 (Object)的讀寫是通過Ring文件來完成的。Ring文件的作用就是將上面的對象邏輯路徑和實際對象存儲的物理位置的映射。
2.1 哈希一致性算法
哈希一致性算法是1997年由麻省理工學院提出的一種分布式哈希 (DHT)實現算法,其基本原理是將機器節點和key值都按照一樣的hash算法映射到一個0~2^32的圓環上。當有一個寫/讀的請求到來時,計算Key值k對應的哈希值Hash(k),如果該值正好對應之前某個機器節點的Hash值,則直接寫/讀該機器節點,如果沒有對應的機器節點,則順時針查找下一個節點,進行寫/讀,如果超過2^32還沒找到對應節點,則從0開始查找 (因為是環狀結構)。如圖2所示。
在Swift中為了系統的擴展性在哈希環上對應的不再是真實的硬盤或者分區,而是采用了虛擬節點,然后再由虛擬節點對應到真實的節點 (多對一)。這里的虛擬節點即是上文中提到的Ring中的Partition,Device則對應真實的節點。
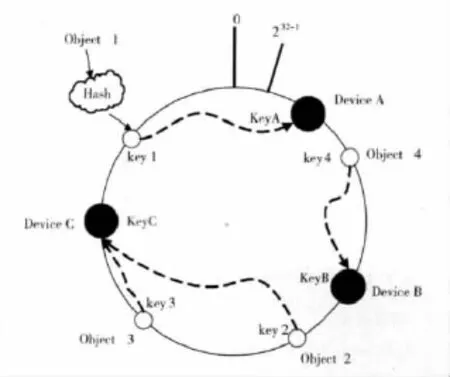
圖2 哈希一致性算法
2.2 Swift中基于哈希一致性算法的讀取策略
首先,當系統接受到客戶發來的請求,先進行用戶身份的驗證,當驗證成功后,再將請求傳給Proxy Server。其次,Proxy Server通過Ring來將對象的邏輯路徑通過哈希一致性算法進行處理,將生成的哈希字符串的前一部分與Ring文件中的partition列表中的partition哈希值進行對比,如果值相等,則該對象在這個partition中。再通過Devices表讀取該Partition所存在的物理位置,最后讀取數據對象本身,并將讀取數據通過Proxy Server返回給用戶。其讀取流程如圖3所示。
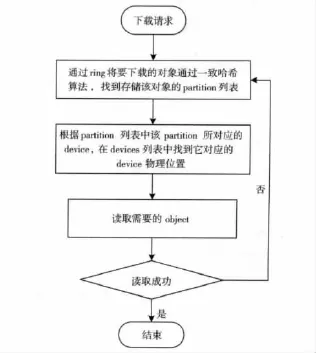
圖3 讀策略流程
由此可見,文件讀取的時候非常容易出現磁盤利用率不平衡的情況,如果某一個磁盤I/O請求隊列中有大量請求,而受硬盤串行工作機制的限制,讀寫文件的速度會大幅降低,這是由于磁盤臂會頻繁地尋道。并且當并發請求量越大,讀寫的速度會越低。例如IDE 7200轉的硬盤讀寫速度一般能達到30M/S左右,但是當同時讀取兩個文件時,硬盤讀寫速度只有10M/s左右。
由于讀取負載不均衡問題極大地限制了系統整體I/O性能,所以設法均衡各個磁盤的I/O請求,實現并行的讀取成為必要。
3 基于I/O負載均衡的讀取策略
3.1 策略分析
由于Swift為了數據的存儲安全每個partition都有2個副本,也就是說一個系統中將有3份同樣的數據存在。這兩個副本的作用是用來做數據安全備份的,一旦當swift數據損壞時,可以用這兩個副本進行恢復。但是當進行文件讀取的時候,這兩個備份文件一般情況下去沒有起到作用。Swift還有一個特性,那就是為了數據的安全,這3份數據每兩份都不能存在于系統的同一個Zone中。(zone可以是一個硬盤,一個服務器,一個機架,一個交換機,甚至是一個數據中心)。所以可以得出不同的Zone肯定不在同一塊硬盤上,如果能利用3個備份在不同硬盤上的特點,使讀取的請求更加平均的分布在不同的硬盤上,將提高swift的讀取效率。本文仍然基于原有的哈希一致性算法實現數據的讀寫,采用添加加權法來使讀取負載更加均衡。
本文策略的核心在于使文件讀取的請求盡可能平均地分布在各個硬盤上,并為每個存儲的partition維護一個權值,文件讀取的時候總是選擇權值最小的硬盤中的那個partition去讀取。
策略實現通過在Ring的Devices列表中添加相應字段,并記錄每一個Device當前的讀寫請求量。當proxy收到客戶已驗證過的請求后,先在Ring中通過哈希一致性算法找到存儲該對象的partition。然后再通過Ring查找該partition的備份,根據這三份數據在Devices列表中找到設備表中對應的設備。最后,根據存儲設備的負載按照一定的方法計算權值,并按權值進行排序,實現負載小的device中的partition優先被選擇。如果3個備份的負載量相同那么就選取列表中的第一個,當選擇完成后,更新List of Devices中的負載權值。
基于I/O負載均衡的讀取策略理論分析如下:
設系統的平均讀取速率為P,Rs為系統讀取請求的數量,Ci為某硬盤的I/O讀取極限速率,Rci為某塊硬盤上的請求數量,θci為該塊硬盤I/O極限速率和多個并行讀取請求時的速率之比
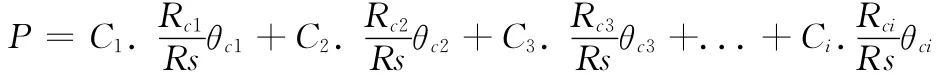
假如我們所有使用的硬盤都是同樣的,在Ci是相同的。則該式可簡化為
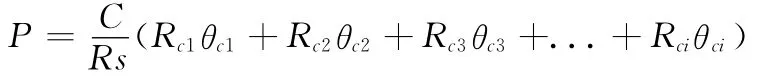
因為硬盤的串行工作機制的限制,當我們并行讀寫多個文件時,速度比串行讀寫多個文件還要慢,多文件并行操作時,時間都花在磁頭擺動上了,所以θci隨著Rci的增加會迅速下降。由上面的公式中可以得出,當Rci之間的值越接近,則P的值越大。
3.2 策略實現
對3.1描述的策略采用如圖4所示的實現流程:
首先當系統接收到用戶的讀請求后。根據邏輯路徑的哈希值在列表中找到對應的partition,然后在通過partition,找到該partition的備份replica。接著從一個partition和兩個replica所對應的Device中找到負載最小的一個進行讀操作,并將對應的Device的Load值加1。讀操作執行完畢之后將該Device的Load值在減1。
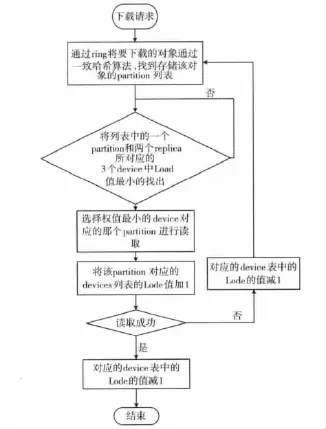
圖4 策略流程
4 仿真實驗
4.1 實驗環境及方法
實驗采用Unix/Linux下提供的iostat來觀察物理磁盤的活動時間及其平均傳輸速度,并將結果寫入到監測文件中。選擇1G字節大小的文件進行讀取實驗,原因在于大文件有利于查看測試數據并進行比對,便于對平均硬盤I/O數據進行分析。
實驗分為兩組。第一組是采用原有策略進行讀取實驗,第二組是采用基于I/O負載均衡的讀取策略進行實驗。兩組實驗中都分別對,1個、10個、50個、100個、500個、1000個、2000個文件同時讀取進行測試。
測試環境的物理架構圖如圖5所示,Auth Node作為身份驗證主機Proxy Node作為接收和轉發客戶的讀寫請求,3個Storage Node作為3個Zone。
系統配置見表1。
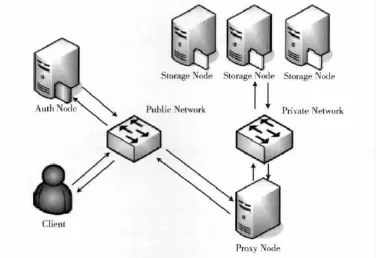
圖5 實驗物理架構
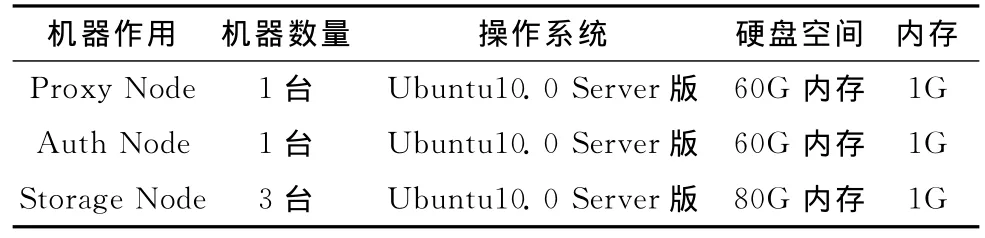
表1 系統配置
4.2 實驗結果
通過iostat監測原有策略及本文基于I/O負載均衡策略的數據讀取速率,見表2。
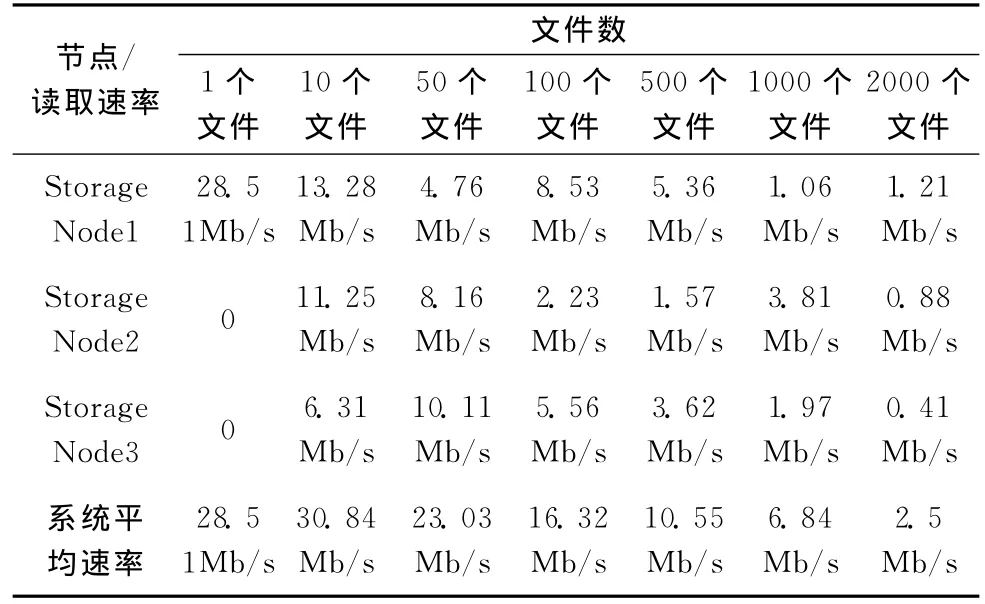
表2 改進前策略數據平均讀取速率
通過iostat監測更改算法后的讀取速率數據見表3。
將監測到的數據在兩種策略下對比,并繪制成圖表如圖6所示。
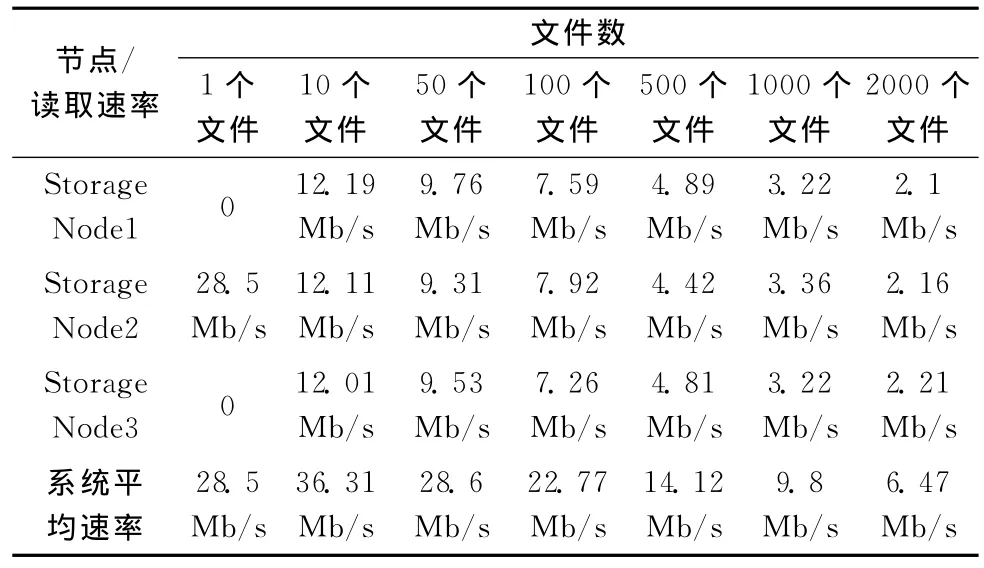
表3 改進后策略數據平均讀取速率
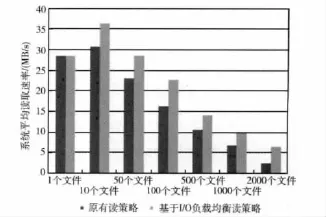
圖6 數據平均速率對比
4.3 結果分析
由圖6可見,對單個文件進行讀取時,不存在并行讀取多文件,所以兩種算法速率一樣,且都接近硬盤的極限I/O速率。當文件的讀取任務請求為10時。此時原有策略不會將讀取請求負載均衡到各個存儲設備上,所以整體讀取效率比較基于I/O負載均衡的讀取策略低。
隨后的兩組數據隨著讀取文件的數量逐漸上升,基于I/O負載均衡的讀取策略由于更好地均衡了讀取請求,所以速度下降的較慢。
實驗結果表明,原有策略隨著讀取請求負載的上升,讀取請求分配不均的現象會變得比較明顯,從而導致系統整體吞吐量下降。而改進后的算法,由于更好地分散了負載,所以能夠獲取更好的系統吞吐量。
5 結束語
云存儲集群具有即時并行讀取量大的特點,因此如何能將這些請求更加合理地平均的分配到各個硬盤上,對于提高整個系統的吞吐量尤為重要。本文主要通過改進數據讀取策略,均衡系統讀取負載,將讀取請求平均分配到各個存儲設備上,使得各個設備之間的I/O負載更加均衡,實現了并行讀取,提高了存儲平臺的整體讀取性能,文章通過實驗驗證了本文策略的有效性。
[1]Amazon Elastic Compute Cloud(Amazon EC2)[EB/OL].[2012-11-18].http://aws.amazon.com/cn/ec2/.
[2]Amazon Simple Storage Service (Amazon S3)[EB/OL].[2012-11-18].http://aws.amazon.com/cn/s3/.
[3]MicrosoftSkyDrive [EB/OL].[2012-11-18].http://zh.wikipedia.org/zh-cn/Microsoft_SkyDrive.
[4]Ghemawat S,Gobioff H,Leung S T.The Google file system[J].ACM SIGOPS Operating Systems Review.ACM,2003,37 (5):29-43.
[5]Hall K B,Gilpin S,Mann G.MapReduce/Bigtable for distributed optimization [C]//NIPS LCCC Workshop,2010.
[6]Tom Wbite.Hadoop the definitive guide [M].Tsang Tairan,ZHOU Aoying,transl.Beijing:Tsinghua University Press,2010 (in Chinese).[Tom Wbite.Hadoop權威指南 [M].曾大冉,周傲英,譯.北京:清華大學出版社,2010.]
[7]Hbase Development Team.HBase:Bigtable-like structured storage for Hadoop HDFS [EB/OL].[2012-11-18].http://wiki.a-pache.orglhadoop/Hbase.
[8]Open source software for building private and public clouds[EB/OL].[2012-11-18]. http://www.openstack.org/http://www.chinacloud.cn/show.aspx?id=766&cid=30.
[9]Swift1.7.6-dev documentation [EB/OL]. [2012-11-18].http://docs.openstack.org/developer/swift/.
[10]Lewin D.Consistent hashing and random trees: Algorithms for caching in distributed networks [D].Cambridge, Massachusetts: Massachusetts Institute of Technology,Department of Electrical Engineering and Computer Science,1998.
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
中國公共安全(2017年11期)2017-02-06 05:28:08
